介绍
《BPR: Bayesian Personalized Ranking from Implicit Feedback》讨论了个性化排序学习模型的一个通用方法:Bayesian Personalized Ranking。主要贡献有:
- 1.描述了通用的优化方法:BPR-OPT,它来自于对最优个性化排序的最大后验估计。我们展示了BPR-OPT在AUC上的分析。
- 2.对于最大化BPR-OPT,我们提出了通用学习算法LearnBPR,它基于SGD,在训练过程使用bootstrap sampling。我们展示了该算法会优于最优化BPR-OPT时的SGD。
- 3.我们展示了如何应用learnBPR到两个state-of-art推荐模型中
- 4.我们的实验经验上展示了个性化排序任务,使用BPR的模型效果要好于其它学习算法
2.相关工作
推荐系统中最流行的模型是kNN CF。传统上,kNN的相似矩阵通过启发法(heuristics)进行计算(例如:Pearson相关度),但在最近的工作中,相似矩阵可以看成是模型参数,可以学到。最近,矩阵分解(MF)在推荐系统中非常流行,可以使用隐式和显式反馈。在最近工作中,SVD也被证明是可以学习特征矩阵。通过SVD学习得到的MF模型,被证明是很容易overfitting。因而提出了正则化学习方法。对于item的预测,Hu等人提出了一个带case weights的正则的最小二乘优化(WR-MF)。case weights可以被用于减小负样本的影响。Hofmann提出了一个概率隐语义模型来进行item推荐。Schmidt-Thieme将该问题转成一个multi-class问题,并使用一个二分类集合来求解它。即使在item预测上的上述所有工作。。。
本文中,我们主要关注模型参数的离线学习。将学习方法扩展到在线学习情况——例如:添加一个新用户,它的历史增加从0到1,2,… feedback事件——对于MF的排序预测已经被学到。相同的fold-in策略可以被用于BPR。
。。。
3.个性化排序(Personalized Ranking)
个性化排序的任务,会为一个用户提供一个items排序列表。这也被称为item推荐。一个示例是,在线电商希望推荐一个个性化的items排序列表,用户会从中购买。在本paper中,我们会研究以下情形:ranking必须从用户的隐式行为(例如:过去的购买)进行infer得到。隐式反馈系统只提供正例数据(正样本)。未被观察到(non-observed)的user-item pairs(例如:一个用户没有购买一个item)会是一个真实负反馈(用户对购买该item不敢兴趣)以及缺失值(用户可能会在将来购买该item)的混合。
3.1 公式化
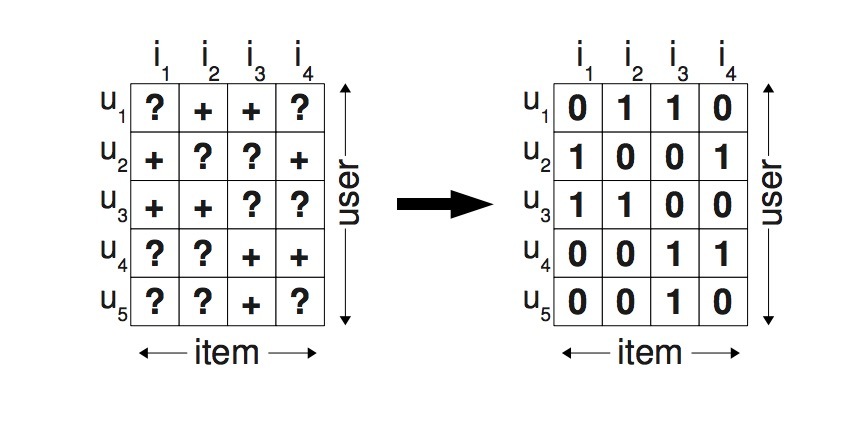
图1: 在左侧,为已观察到的数据S。直接从S中学习是不可行的,因为只有正反馈被观察到。通常负例数据通过使用0值填充矩阵来生成
假设U是所有users的集合,I是所有items的集合。在我们的场景下,隐式反馈\(S \subseteq U \times I\)(见图1左侧)。类似这种反馈方式有:电商中的购买行为,视频观看 或者 网页上的点击。推荐系统的任务是提供给用户一个个性化总排序(personlaized total ranking): \(>_u \subset I^2\),其中\(>_u\)必须满足一个总顺序属性:
\[\begin{aligned} & \forall i,j \in I: i \neq j \Rightarrow i >_u j \vee j >_u i \ \ (totality) \\ & \forall i,j \in I: i >_u j \wedge j >_u i \Rightarrow i = j \ \ (antisymmetry) \\ & \forall i,j \in I: i >_u j \wedge j >_u k \Rightarrow i >_u k \ \ (transitivity) \end{aligned}\]- totallity: 总体性
- antisymmetry: 反对称性
- transitivity: 传递性
出于便利,我们也定义了:
\[I_u^+ := {i \in I: (u,i) \in S} \\ U_i^+ := {u \in U: (u,i) \in S}\]3.2 问题分析
前面提到,在隐式反馈系统中只有正例(positive classes)被观察到。剩余数据其实是实际负例(negative)与缺失值(missing value)的一个混合。对于应付缺失值问题,最常见的方法是:忽略所有缺失值。通常典型的机器学习模型不能学习任何东西,因为他们两者间不能进行区分这两者(负例和缺失值)。
对于item推荐,常用的方法是,对一个item预测一个个性化分\(\hat{x}_{ui}\),它可以影响用户对该item的偏好。接着,该items会根据该分值进行排序。对于item推荐的机器学习方法,通常会从S中创建训练数据:给定:
- 正例:\((u, i) \in S\) pairs
- 负例:所有在\((U \times I) \backslash S\)中的其它组合
如图1所示。接着,模型会拟合该数据。这意味着模型的最优化是为在S中的元素预测value是1, 其余为0。该方法的问题是,在模型中将来进行排序的所有元素(\(U \times I \backslash S\))在训练期间都会作为负反馈被表示给机器学习算法。这意味着:如果一个模型具有足够表现力(它可以精准拟合训练数据),它根本不能进行排序,因为它的预测值基本为全0(很稀疏,大部分为0, 全预测对)。为什么这样的机器学习方法可以预测rankings?唯一原因是,有策略阻止overfitting,比如:正则化。
我们使用一种不同的方法:通过使用item pairs作为训练数据,然后为正确(correctly)的ranking item进行最优化(而非对单个items进行打分),因为这比使用负例来替代缺失值要更好。从S中,我们可以尝试为每个user parts(\(>_u\))进行重构。如果一个item i被user u观看过,(例如:\((u,i) \in S\))——那么,我们假设该user喜欢该item要胜过其它未观察到的items。
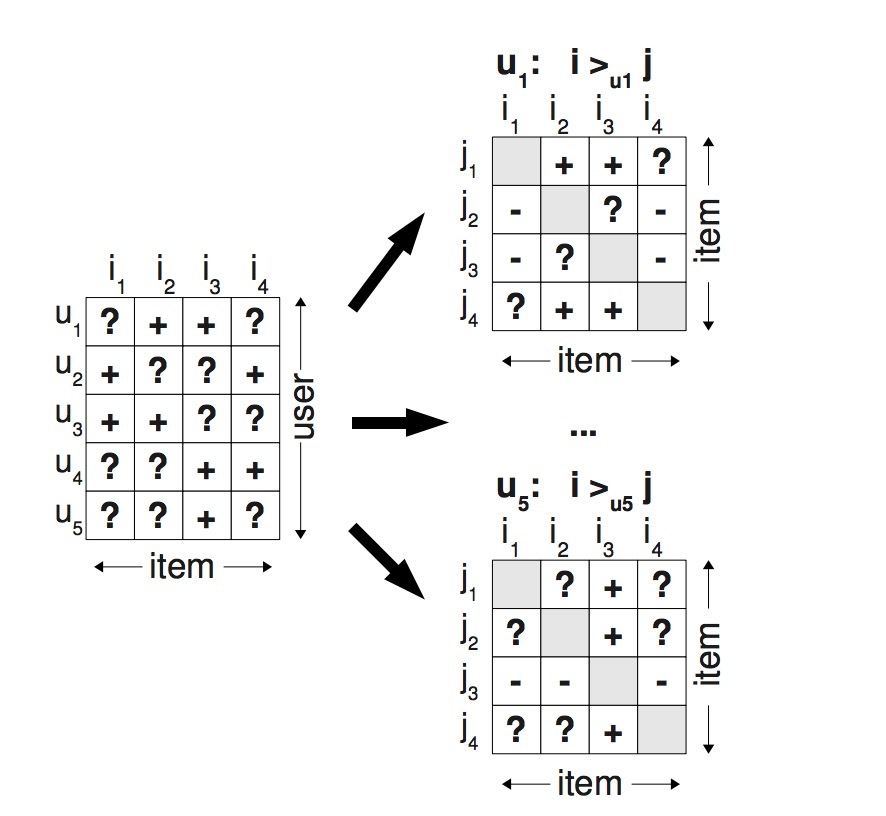
图2: 在左侧,已观察到的数据S。我们的方法会在一个items pair间创建特定用户的pairwise偏好\(i >_u j\)。在右侧,加号(+)表示一个用户偏爱item i胜过item j;减号(-)表示他偏爱j胜过i。
例如,在图2中,user \(u_1\)已经观看过item \(i_2\),但没看过item \(i_1\),因此我们假设,该用户喜欢\(i_2\)要胜过\(i_1\):\(i_2 >_u i_1\)。对于被一个用户同时观看过的两个items,我们不能推断更偏好哪个。对于用户未观看过的两个items来说(比如:对于user \(u_1\), item \(i_1\)和\(i_4\)),相类似,也不能推断哪个更好。为了将这种现象公式化,我们创建训练数据 \(D_S : U \times I \times I\):
\[D_S := \lbrace (u, i, j) | i \in I_u^+ \wedge j \in I \backslash I_u^+ \rbrace\]\((u,i,j) \in D_S\)的语义是,user \(u\)被假设成:喜欢i,胜过j。由于\(>_u\)是非对称的,负例会被隐式对待。
我们的方法有两个优点:
- 1.我们的训练数据同时包含了正负例pairs以及缺失值。介于两个未观察到的items间的缺失值是将来必须排序的item pairs。这意味着,从pairwise的角度看,训练数据\(D_S\)和测试数据是不相交的。
- 2.为排序的实际目标函数创建训练数据,例如:观察到\(>_u\)的子集\(D_S\)被用成训练数据。
4.BPR
在这部分,我们为解决个性化排序任务生成了一种通用方法。对于个性化排序,它包含了通用优化准则:BPR-OPT,它源自对该问题的Bayesian分析,会使用似然函数来为\(p(i >_u j \mid \Theta)\)以及模型参数\(p(\Theta)\)的先验概率。我们展示了排序统计AUC的分析。对于遵循BPR-OPT的学习模型,我们提出了算法learnBPR。最后,我们会展示BPR-OPT和LearnBPR是如何应用到两个state-of-art的推荐算法(MF和adaptive kNN)上。比起常用的训练方法,使用BPR来优化这些模型可以生成更好的rankings。
4.1 BPR优化原则
为所有items \(i \in I\)寻找正确的个性化排序的Bayesian公式,是为了最大化以下后验概率,其中\(\Theta\)表示一个指定模型类别(比如:MF)的参数向量。贝叶斯公式为:
\[P(\Theta | >_u) \propto p(>_u | \Theta) p(\Theta)\]这里,\(>_u\)是对于user u希望但隐含的偏好结构。所有用户都假设行为间相互独立。我们也假设:对于一个指定用户,每个items \((i,j)\) pair的顺序,与每一个其它pair相互独立。因而,对于所有用户\(u \in U\),以上的特定用户的似然函数\(p(>_u \mid \Theta)\)可以首先被重写成:单个密度(densities)和第二个的乘积的组合。
\[\prod\limits_{u \in U} p(>_u | \Theta) = \prod\limits_{(u,i,j) \in U \times I \times I} p(i >_u j | \Theta)^{\delta((u,i,j) \in D_S)} \cdot(1-p(i >_u j | \Theta))^{\delta((u,j,i) \notin D_S}\]其中\(\delta\)是指示函数:
\[\delta(b) := \begin{cases} 1 & \text{if b is true,} \\ 0 & \text{else} \end{cases}\]归因于合理的pairwise ordering scheme的总体(totality)和非对称性(antisymmetry),上述公式可以简化为:
\[\prod\limits_{u \in U} p(>_u | \Theta) = \prod\limits_{(u,i,j) \in D_S} p(i >_u j | \Theta)\]到目前为止,通常不会保证获得一个个性化的总顺序。为了得到它,必须满足之前提到过的合理性质(totality、antisymmetry、transitivity)。为了这样做,我们定义了一个用户喜欢item i胜过item j的独立概率:
\[p(i >_u j | \Theta) = \sigma( \hat{x}_{uij} (\Theta))\]其中:
- \(\sigma\)是logistic sigmoid:\(\sigma(x) := \frac{1}{1+e^{-x}}\)
- \(\hat{x}_{uij}(\Theta)\)是一个特定的关于模型参数向量\(\Theta\)的real-valued函数,它会捕获user u、item i、item j间的特殊关系。
换句话说,我们的通用框架会将建模在u、i、j间的关系的任务表示到一个底层模型类(比如:MF或adaptive kNN)上,它们负责估计\(\hat{x}_{uij}(\Theta)\)。因而,统计方式建模一个个性化总顺序\(>_u\)变得可行。出于便利,后续章节我们会跳过介绍来自\(\hat{x}_{xij}\)的参数\(\Theta\)。
至今,我们已经讨论了似然函数。为了补全个性化排序任务的Bayesian建模方法,我们引入了一个通用的先验密度\(p(\Theta)\),它是一个零均值、协方差矩阵\(\sum_{\Theta}\)的正态分布。
\[p(\Theta) \sim N(0, \sum_{\Theta})\]下面,为了减小未知超参数的数目,我们设置\(\sum_{\Theta} = \lambda_{\Theta} I\)。现在,我们可以将最大后验估计进行公式化,来生成我们为个性化排序BPR-OPT的通用最优化准则:
\[\begin{aligned} BPR-OPT &:= ln \ p(\Theta | >_u) \\ & = ln \ p(>_u | \Theta) p(\Theta) \\ & = ln \ \prod\limits_{(u,i,j) \in D_S} \sigma(\hat{x}_{uij}) p(\Theta) \\ & = \sum\limits_{(u,i,j) \in D_S} ln \ \sigma(\hat{x}_{uij}) + ln \ p(\Theta) \\ & = \sum\limits_{(u,i,j) \in D_S} ln \ \sigma(\hat{x}_{uij}) - \lambda_{\Theta} \|\Theta \|^2 \end{aligned}\]其中\(\lambda_{\Theta}\)是模型特定的正则化参数。
4.1.1 AUC最优化分析
有了Bayesian Personalized Ranking(BPR) scheme的公式,很容易理解BPR和AUC间的分析。每个用户的AUC通常被定义为:
\[AUC(u) := \frac{1}{ | I_u^+ | |I \backslash I_u^+ |} \sum\limits_{i \in I_u^+} \sum\limits_{j \in | I \backslash I_u^+|} \sigma(\hat{x}_{uij} > 0)\]这里,平均AUC是:
\[AUC := \frac{1}{|U|} \sum\limits_{u \in U} AUC(u)\]…(1)
其中, \(z_u\)是归一化常数:
\[z_u = \frac{1} { | U | | I_u^+ | | I \backslash I_u^+|}\]在(1)和BPR-OPT间的分析是很明显的。除了归一化常数\(z_u\)外,他们只在loss function上有区别。AUC会使用不可微(non-differentiable)的loss \(\sigma(x>0)\),它等同于Heaviside function:
\[\sigma(x > 0) = H(x) := begin{cases} 1, & \text{ x > 0 } \\ 0, & \text{ else } end{cases}\]作为替代,我们会使用可微loss \(ln \sigma(x)\)。惯例上,当为AUC进行最优化时【3】,替代不可微的Heaviside函数。通常,替代选择是启发式的(heuristic),并且有一个与\(\sigma\)相类似的相似形状函数(similarly shaped function)(见图3)。在本paper中,受MLE的启发,我们已经已经生成了替代法 \(ln \sigma(x)\)。
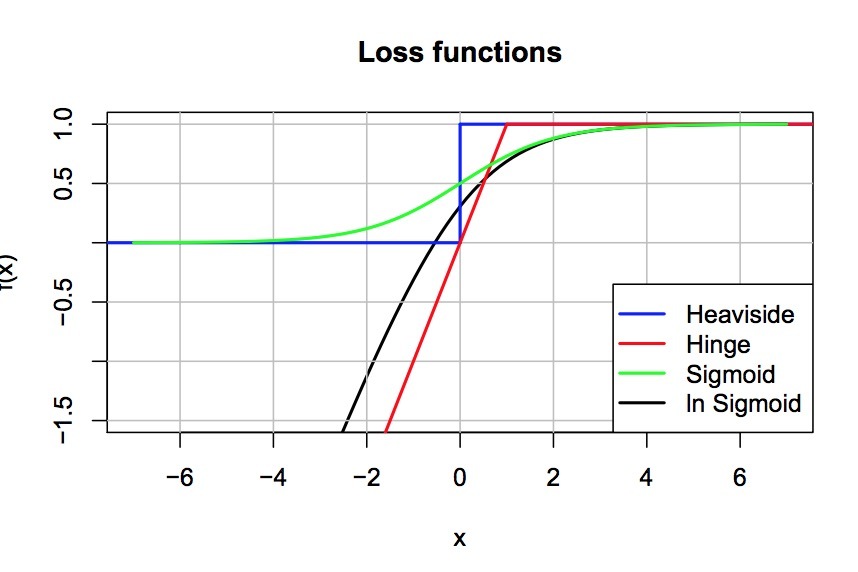
图3: 用于最优化AUC的loss function。不可微的Heaviside H(x)通常使用sigmoid \(\sigma(x)\)来近似。我们的MLE导数建议使用\(ln \sigma(x)\)来替代
4.2 BPR learning算法
在最后一节,我们已经为个性化排序生成了一个最优化原则(optimization criterion)。由于criterion函数是可微的,基于梯度下降(gradient descent)的算法是一个用于最大化的很明智的选择。但正如我们所见,对于我们的问题,标准梯度下降并不适合。为了解决该问题,我们提出了LearnBPR,一个基于SGD的、在训练的三元组上进行bootstrap sampling的算法(见图4)。

图4:基于SGD的boostrapping BRP最优化模型。学习率\(\alpha\),正则参数\(\lambda_{\Theta}\)
首先,BPR-OPT的梯度会各自按模型参数求导:
\[\begin{aligned} \frac{\partial {BPR-OPT}}{\partial \Theta} & = \sum_{(u,i,j) \in D_S} \frac{\partial}{\partial \Theta} ln \sigma(\hat{x}_{uij}) - \lambda_{\Theta} \frac{\partial}{\partial \Theta} \| \Theta \|^2 \\ & \propto \sum\limits_{(u,i,j) \in D_S} \frac{-e^{-\hat{x}_{uij}}}{1+e^{-\hat{x}_{uij}}} \cdot \frac{\partial}{\partial \Theta} \hat{x}_{uij} - \lambda_{\Theta} \Theta \end{aligned}\]对于梯度下降,两种常用算法是full GD或SGD。在第一种方法中,每一step,会在所有训练数据上进行计算,接着模型参数会使用learning rate \(\alpha\)进行更新:
\[\theta \leftarrow \Theta - \alpha \frac{\partial BPR-OPT} {\partial \Theta}\]总之,该方法会在“正确”方向上产生一个下降,但收敛很慢。因此,我们在\(D_S\)上有\(O(\mid S \mid \mid I \mid)\)条训练三元组(triples),在每个update step上计算full gradient是不可行的。再者,对于使用full DG进行BPR-OPT的最优化、以及在训练pairs上的数据倾斜,会导致很差的收敛。想象下,一个item i,通常是positive的。接着我们在loss中的\(\hat{x}_{uij}\)上有许多项(terms),因为对于许多用户u、item i,会与所有负例items j进行对比(占主导的分类)。因而,模型参数的梯度依赖于i是否在梯度上占据主导地位。这意味着必须选择非常小的learning rates。第二,由于梯度的不同,正则化很难。
另一个流行的方法是SGD。在这种情况下,对于每个triple \((u,i,j) \in D_S\),只会执行一个更新。
\[\Theta \leftarrow \Theta + \alpha ( \frac{e^{-\hat{x}_{uij}}}{1+e^{\hat{x}_{uij}}} \cdot \frac{\partial}{\partial \Theta} \hat{x}_{uij} + \lambda_{\Theta} \Theta)\]总之,对于我们的倾斜问题,这是一个好方法。但training pairs遍历的顺序是很严格的。一个常用的方法是,以item-wise或user-wise的方式遍历数据,会产生很差的收敛,因为在相同的user-item pair上有许多连续的更新——例如:对于一个user-item pair (u,i),有许多j 满足\((u,i,j) \in D_S\)。
为了解决这个问题,我们建议使用一个SGD算法来随机选择triples(非均匀分布)。该方法在连续更新steps很小时,会选择相同的user-item组合。我们建议使用一个有放回的bootstrap sampling方法,因为在任意step上都可能执行stopping。放弃通过该数据进行full cycles的思想,在我们的case中特别有用,因为样本数目会非常大,为了收敛通常一个full cycle的一部分就足够了。在我们的评估中,我们选择了单个steps的数目,它线性依赖于观察到的正反馈S的数目。
图5展示了一个常用的user-wise SGD、与我们的带bootstrapping的LearnBPR的比较。该模型是16维的BPR-MF。正如你看到的,LearnBPR比user-wise GD收敛更快。
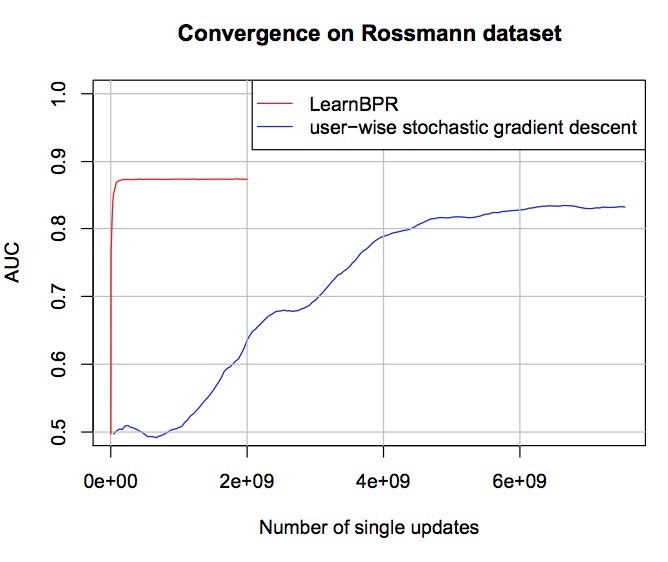
图5: 常见的user-wise SGD与我们的基于bootstrapp sampling的learnBPR算法收敛率的经验比较
4.3 使用BPR来学习模型
对于item推荐,下面我们描述了两个state-of-the-art的模型,以及如何使用我们提出的BPR方法来学习它们。我们已经选择两个不同的模型:MF[5,12]和learned kNN[8]。这两个模型都尝试建模一个用户在一个item上的隐式偏好。它们的预测是对于每个user-item-pair (u,l)的一个实数 \(\hat{x}_{ul}\)。
由于在我们的optimization中,我们有triples \((u,i,j) \in D_S\),我们首先对estimator \(\hat{x}_{uij}\)进行解耦,并将它定义为:
\[\hat{x}_{uij} := \hat{x}_{ui} - \hat{x}_{uj}\]现在,我们可以应用任意标准的CF模型来预测\(\hat{x}_{ul}\)。
需要重点注意的是,尽管在其它工作中我们使用相同的模型,我们会使用不同的准则(criterion)对它们进行最优化。这会产生一个更好的排序,因为我们的准则对于排序任务是最优的。我们的准则不会尝试将单个predictor \(\hat{x}_{ul}\)看成是单个数字,但作为替换,尝试对两个预测的差\(\hat{x}_{ui} - \hat{x}_{uj}\)进行分类。
4.3.1 MF
预测\(\hat{x}_{ui}\)的问题可以看成是估计一个矩阵:\(X: U \times I\)。对目标矩阵X使用MF,可以通过两个低秩矩阵\(W: \mid U \mid \times k\)和\(H: \mid I \mid \times k\):
\[\hat{X} := W H^t\]其中k是维度/秩 (dimensionality/rank)的近似。在W中的每行 \(w_u\)可以被看成是描述一个user u的一个feature vector,相似的,H中的每行\(h_i\)描述了一个item i。因而,预测公式可以被写为:
\[\hat{x}_{ui} = \langle w_u, h_i \rangle = \sum\limits_{f=1}^{k} w_{uf} \cdot h_{if}\]除了点乘\(\langle \cdot, \cdot \rangle\)外,总之类似于[11]的任意kernel都可以被使用。对于MF的模型参数是\(\Theta = (W, H)\)。该模型参数可以被看成是隐变量(latent variables),会建模一个用户的未观察到的品味(taste)、以及一个item未观察到的属性(properties)。
通常,通过SVD根据最小二乘获得的X的的最佳近似\(\hat{X}\)。对于机器学习任务,SVD会overfits,因此提出了许多其它的MF方法,包含正则化最小二乘最优化,非负因子分解,最大间隔因子分解,等。
对于排序任务,例如:估计一个用户是否偏爱一个item胜过其它item,一个更好的方法是根据BPR-OPT准则来最优化。这可以通过使用提出的LearnBPR来达到。正如之前所述,对于使用LearnBPR的最优化,每个模型参数\(\theta\)的梯度\(\hat{x}_{uij}\)是已知的。对于MF模型,导数为:
\[\frac{\partial}{\partial \theta} \hat{x}_{uij} = \begin{cases} (h_{if} - h_{jf}) & \text{if $\theta = w_{uf}$ } \\ w_{uf} & \text{if $\theta = h_{if}$} \\ -w_{uf} & \text{if $\theta = h_{jf}$} \\ 0 & \text{else} \end{cases}\]另外,我们使用三个正则化常数:
- \(\lambda_W\)对应用户特征W;
item features H有两个正则常数:
- \(\lambda_{H^+}\)被用于只在\(h_{if}\)上用于positive更新;
- \(\lambda_{H^-}\)用于在\(h_{jf}\)上的negative更新
4.3.2 Adaptive KNN
最近邻方法在CF中很流行。它依赖items间(item-based)或users间(user-based)的相似度衡量。以下我们描述了item-based方法,通常他们会提供更好的结果,但user-based方法也类似。该思想是:为一个user u预测一个item i,它依赖于item i与该用户过往看过的其它所有items(例如:\(I_u^+\))间的相似度。通常,\(I_u^+\)中只有k个最相似的items会被看成是K个最近邻。如果items间的相似度被选中,你可以比较在\(I_u^+\)上的所有items。对于item-based KNN的item预测:
\[\hat{x}_{ui} = \sum\limits_{l \in I_u^+ \wedge l \neq i} c_{il}\]其中:\(C: I \times I\)是对称的(item-correlation / item-similarity)矩阵。这里,kNN的模型参数为\(\Theta = C\)。
最常用的选择C的方法是,通过应用一个启发式相似度来衡量,比如:cosine向量相似度:
\[c_{i,j}^{cosine} := \frac{|U_i^+ \cap U_j^+|} {\sqrt{ |U_i^+ | \cdot |U_j^+|}}\]一个更好的策略是,通过学习来将相似度 C适配该问题。这可以通过直接使用C作为参数,或者如果items数很大,你可以学习一个C的因子分解\(H H^t\),其中:\(H: I \times k\)。下面,在我们的评估中,我们会使用第一种方法来直接学习C,无需因子分解。
为了对kNN模型最优化来进行ranking,我们使用BPR-OPT准则,并使用LearnBPR算法。为了应用该算法,\(\hat{x_{uij}}\)对应模型参数C的梯度为:
\[\frac{\partial}{\partial \Theta} \hat{x}_{uij} = \begin{cases} +1 & \text{if $\theta \in \lbrace c_{il}, c_{li} \rbrace \wedge l \in I_u^+ \wedge l \neq i,$} \\ -1 & \text{if $\theta \in \lbrace c_{jl}, c_{lj} \rbrace \wedge l \in I_u^+ \wedge l \neq j,$} \\ 0 & \text{else} \end{cases}\]我们有两个正则常数,\(\lambda_+\)用于在\(c_{il}\)上更新,\(\lambda_{-}\)用于在\(c_{jl}\)上更新。
5.与其它方法的关系
- WR-MF: Weighted Regularized Matrix Factorization
- MMMF: Maximum Margin Matrix Factorization
略
6.评估
在我们的评估中,我们比较了BPR学习与其它学习方法。我们选择两个流行的模型:MF和kNN。MF模型的效果要好于其它模型(比如:Bayesian模型URP、PLSA等 )。在我们的评估中,MF模型使用三种不同方法学到:SVD-MF, WR-MF, BPR-MF。对于kNN,我们比较了Cosine-kNN,以及一个使用BPR方法优化的模型(BPR-kNN)。另外,我们也上报了baseline(most-polular)的结果,它会按用户独立的方式来加权每个item:比如:\(\hat{x}_{ui}^{most-pop} := \mid U_i^+ \mid\)。另外,我们给出了对于任意非个性化排序方法在AUC (\(np_{max}\))的理论上界。
6.1 datasets
我们使用两个来自不同应用的数据集。
- Rossmann dataset:来自在线电商。它包含了1w用户在4k items上的购买历史。总共有426612个购买记录。该任务是预测用户希望在下次购买的一个个性化items列表.
- Netflix DVD rental dataset: 该数据集包含了用户行为的打分,其中一个用户对电影提供了1-5星的显式评分。如果我们希望以隐式反馈的方式求解,我们可以移除rating。该任务是预测用户是否可能对一个电影进行评分。我们会为用户提供一个最可能打分的个性化排序列表。对于Netflix我们创建了一个subsample: 1w用户,5000 items,包含了565738个rating动作。我们会做子抽样:每个用户至少包含10个items,每个item至少有10个用户。
6.2 评估方法
我们使用留一法(leave-one-out)来进行评估,训练集\(S_{train}\),测试集\(S_{test}\)。该模型会在\(S_{train}\)上学习,并在\(S_{test}\)上通过平均AUC统计进行评估:
\[AUC = \frac{1}{|U|} \sum\limits_{u} \frac{1}{|E(u)|} \sum\limits_{(i,j) \in E(u)} \sigma(\hat{x}_{ui} > \hat{x}_{uj}\]…(2)
其中,每个用户u评估的pairs为:
\[E(u) := \lbrace (i,j) | (u,i) \in S_{test} \wedge (u,j) \notin (S_{test} \cup S_{train})rbrace\]…(2)
AUC越高表示效果越好。随机猜测法的AUC是0.5,最好为1。
我们会重复10次实验,每次抽取新的train/test splits。超参数通过grid search进行最优化。
6.3 结果
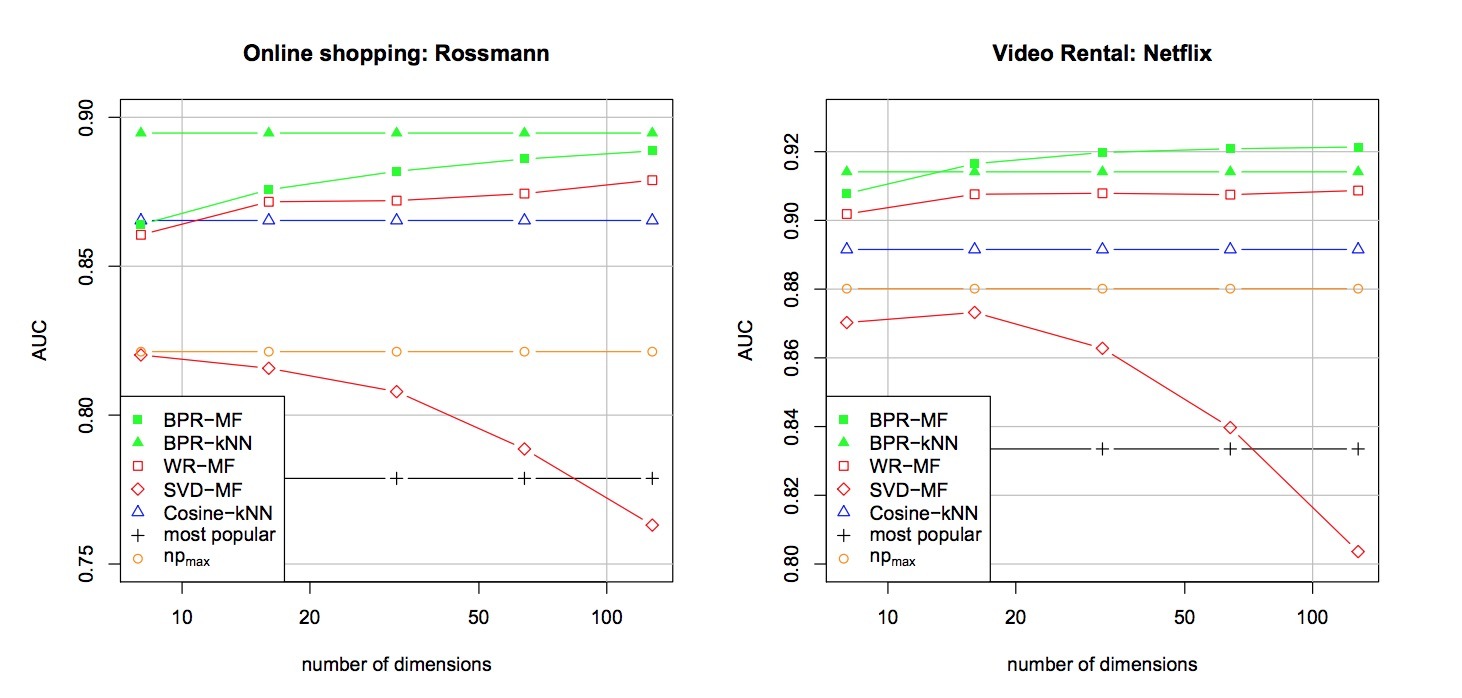
图6