attention机制在2014年被引入到NLP中:《NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE》,我们可以看下具体实现:
2.背景:神经机器翻译
从概率角度,翻译等同于:给定一个源句子(source sentence)x,发现这样一个目标句子y(target sentence),使得它的条件概率最大化: \(arg max_y p(y \mid x)\)。在神经机器翻译中,会拟合一个参数化模型,使用一个并行训练语料,来最大化关于句子对(sentence pairs)的条件概率。一旦通过一个翻译模型学到了条件分布后,对于给定一个源句子,对应的翻译可以通过搜索使条件概率最大的句子来生成。
最近,许多paper已经提出使用神经网络来直接学习该条件概率。 这些神经机器翻译方法通常包含两个组件:第1个组件会编码(encode)一个源句子x,第2个组件会解码(decode)成一个目标句子y。例如,(Cho.2014a)使用两个RNN来将一个变长的源句子编码到一个固定长度的vector上,然后将该vector解码到一个变长的目标句子上。
神经机器翻译已经成为相当新的方法,并展示了很好的结果。Sutskever 2014, 在English-to-Frech翻译任务上,使用基于RNN与LSTM units的神经机器翻译已经达到了接近state-of-the-art的效果。。。
2.1 RNN encoder-decoder
这里,我们描述了下述框架,称为RNN Encoder-Decoder,由Cho 2014a和Sutskever 2014提出。 在此基础上我们构建了一个新结构,它可以同时学到对齐(align)和翻译(translate)。
在Encoder-Decoder框架中,encoder会读取输入句子(input sentence),一个向量序列:\(x=(x_1, \cdots, x_{T_x})\),将它映射到一个向量c上。使用RNN时最常用的方法是:
\[h_t = f(x_t, h_{t-1})\]…(1)
\[c = q(\lbrace h_1, \cdots, h_{T_x}\rbrace)\]…(2)
其中:
- \(h_t \in R^n\)是一个在时间t时的hidden state
- **c是一个从hidden states序列生成的vector。
- f和q是一些非线性函数。例如:Suskever 2014使用一个LSTM作为f,\(q(\lbrace h_1, \cdots, h_{T_x}\rbrace)=h_T\)。
decoder通常被训练成:在给定上下文向量(context vector)c、以及之前预测过的词\(\lbrace y_1, \cdots, y_{t'-1}\rbrace\)的情况下,用来预测下一个词\(y_{t'}\)。换句话说,decoder定义了一个在翻译y上的概率,它通过将联合概率(joint probability)解耦成顺序条件(ordered conditionals):
\[p(y) = \prod\limits_{t=1}^T p(y_t | \lbrace y_1, \cdots, y_{t-1} \rbrace, c)\]…(2)
其中,\(y=(y_1, \cdots, y_{T_y})\)。在一个RNN中,每个条件概率被建模成:
\[p(y_t | \lbrace y_1, \cdots, y_{t-1}\rbrace, c) = g(y_{t-1}, s_t, c)\]…(3)
其中:
- g是一个非线性、可能多层的函数,会输出概率\(y_t\),
- \(s_t\)是RNN的hidden state。
需要注意的是,其它结构(比如:一个RNN与一个de-convolutional网络进行混合的结构)可以被使用。
3.学习align和translate
在本节中,我们提出了一个新的神经机器翻译结构。新结构包含了一个Bidirectional RNN作为一个encoder(3.2节),以及一个decoder,它在对一个翻译进行decoding期间,通过一个源句子进行模拟搜索来完成。
3.1 Decoder: 通用描述
在新模型结构中,我们定义了等式(2)中的每个条件概率:
\[p(y_i | y_1, \cdots, y_{i-1}, x) = g(y_{i-1}, s_i, c_i)\]…(4)
其中,\(s_i\)是一个在时间i上的RNN hidden state,可以通过下述公式计算得到:
\[s_i = f(s_{i-1}, y_{i-1}, c_i)\]需要注意的是,不同于已经存在的encoder-decoder方法(等式(2)),这里的概率是条件概率,它基于对于每个目标词(target word)\(y_i\)上一个不同的上下文向量(context vector) \(c_i\)得到。
上下文向量\(c_i\)依赖于一个annotation序列:\((h_1, \cdots, h_{T_x})\),一个encoder会将输入句子(input sentence)映射到它上。每个annotation \(h_i\)包含了整个输入序列相关的信息,它会强烈关注围绕在输入序列第i个词周围的部分。后续我们会解释 annotation是如何被计算的。
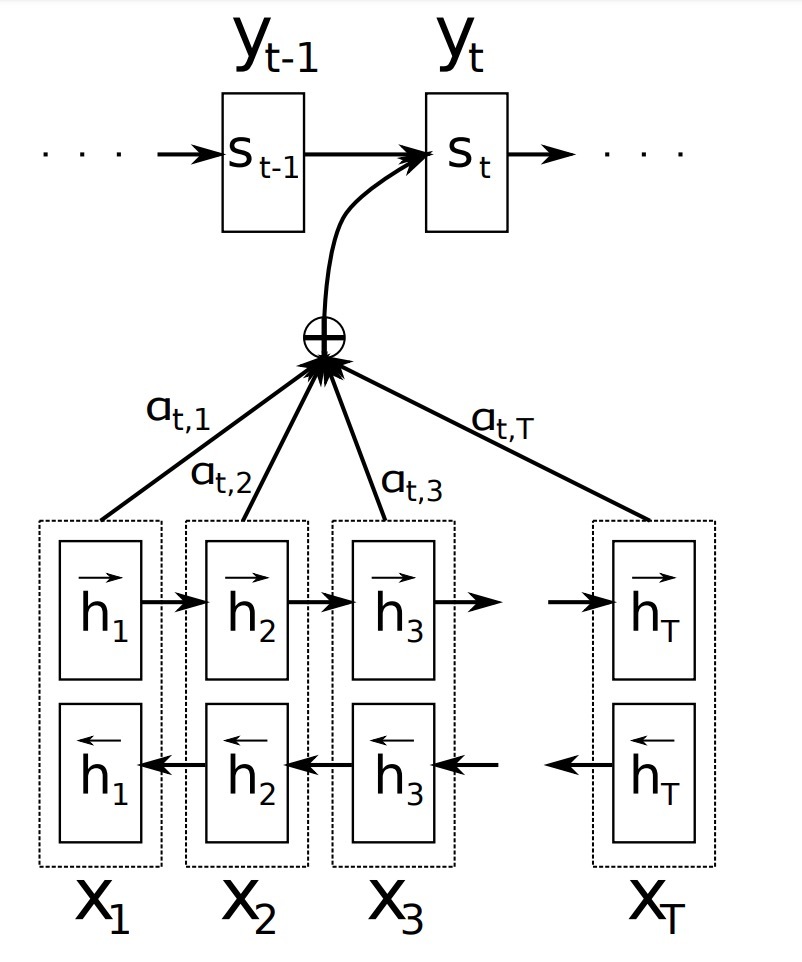
图1: 给定一个源句子\((x_1, x_2, \cdots, x_T)\),提出的模型尝试生成第t个目标词\(y_t\)图示
上下文向量\(c_i\)通过对这些 annotations \(h_i\)进行加权求和得到:
\[c_i = \sum\limits_{j=1}^{T_x} \alpha_{ij} h_j\]…(5)
每个annotation \(h_j\)的权重\(\alpha_{ij}\)通过计算下述公式得到:
\[\alpha_{ij} = \frac{exp(e_{ij})}{ \sum\limits_{k=1}^{T_x} exp(e_{ik})}\]其中:
\[e_{ij} = a(s_{i-1}, h_j)\]是一个对齐模型(alignment model),它会对围绕位置j的输入与位置i的输出间的匹配度进行打分。该得分基于RNN hidden state \(s_{i-1}\) (等式(4))和关于输入句子的第j个 annotation \(h_j\)计算得到。
我们将对齐模型(alignment model)a参数化成一个前馈神经网络,它会与系统的所有其它组件一起进行jointly train。注意,这与在传统的机器翻译不同,对齐(alignment)不会被当成一个隐变量来考虑。相反的,对齐模型(alignment model)会直接计算一个软对齐(soft alignment),它允许cost函数的梯度可以进行BP。该梯度可以被用于联合训练alignment model与translation model。
我们可以理解,采用对所有annotations进行加权求和的方法来计算一个期望注解(expected annotation),其中期望是对所有alignments进行的。假设\(\alpha_{ij}\)是目标词\(y_i\)与源词\(x_j\)对齐的概率、或从源词进行翻译的概率。接着,第i个上下文向量\(c_i\)是使用概率\(\alpha_{ij}\)在所有annotations上的expected annotation。
概率\(\alpha_{ij}\),或者它相关的能量\(e_{ij}\),会影响annotation \(h_j\)在关于前一hidden state \(s_{i-1}\)在决定下一state \(s_i\)和生成\(y_i\)的重要性。直觉上,这实现了在decoder中的attention机制。该decoder决定着源句子中要关注(pay attention to)的部分。通过让decoder具有一个attention机制,我们会减轻encoder将源句子中的所有信息编码成一个固定长度向量的负担。使用这种新方法,可以通过annotations序列进行传播信息,这些annotations可以根据相应的decoder进行选择性检索。
3.2 Encoder:对annotating序列使用Bi-RNN
常用的RNN,如等式(1)所描述,会以从\(x_1\)到\(x_{T_x}\)的顺序读取一个输入序列x。然而,在提出的scheme中,我们希望每个词的annotation可以归纳不仅仅是前面出现的词,也可以归纳后续跟着的词。因而,我们提出使用一个BiRNN。
BiRNN包含forward和backward RNN两部分。forward RNN \(\overrightarrow{f}\)会按从\(x_1\)到\(x_{T_x}\)的顺序读取输入序列,并计算一个forward hidden states序列\((\overrightarrow{h}_1, \cdots, \overrightarrow{h}_{T_x})\)。backward RNN \(\overleftarrow{f}\)会以逆序 (即:从\(x_{T_x}\)到\(x_1\)的顺序)来读取序列,产生backward hidden state序列\((\overleftarrow{h}_1, \cdots, \overleftarrow{h}_{T_x})\)。
我们通过将forward hidden state \(\overrightarrow{h}_j\) 和backward \(\overleftarrow{h}_j\)进行拼接(concatenate)(如:\([\overrightarrow{h}_j^T; \overleftarrow{h}_j^T]\)),来为每个词\(x_j\)获得一个annotation。这种方式下,annotation \(h_j\)包含了前面词和后续词的总结信息(summaries)。由于RNN可以更好地表示最近输入,annotation \(h_j\)将关注\(x_j\)周围的词。该annotations序列被用在decoder上,alignment model后续会计算该上下文向量(等式(5)-(6))。
4.实验
略