我们来看下《AutoRec: Autoencoders Meet Collaborative Filtering》,它提出的autorec,会使用新的autoencoder框架来进行CF:
1.介绍
CF模型的目的是,根据用户对items(评分)的偏好进行探索,从而来提供个性化推荐。Netflix竞赛提出了一全套不同的CF模型,比较流行的方法有:矩阵分解[1,2]以及邻近模型[5]。该paper提出了AutoRec,一种新的基于autoencoder范式的CF模型。它的灵感原自于最近在视觉和语音任务上的深度学习上获得的成功。AutoRec对于已经存在的CF上的神经网络方法[4]在表征和计算上均有优势,我们会展示它的效果要好于state-of-art方法。
2.AutoRec模型
在基于评分(rating)的CF中,我们有m个用户,n个items,以及:
- 一个部分可观察(相对的,有一部分missing)到的user-item评分矩阵\(R \in R^{m \times n}\)
- 每个用户\(u \in U = \lbrace 1, ..., m \rbrace\),可以被表示成一个部分可观察向量(partially observed vector):\(r^{(u)} = (R_{u1}, ..., R_{un}) \in R^n\)
相似的,每个item \(i \in I = \lbrace 1, ..., n \rbrace\),可以被表示成:
- \[r^{(i)}=(R_{1i}, ..., R_{mi}) \in R^m\]
我们的目标是,设计一个item-based(user-based)的autoencoder,它可以将输入看成是每个部分可观测的\(r^{(i)} (r^{u})\),将它投影到一个低维的隐空间(hidden/latent space),接着,在输出空间将\(r^{(i)} (r^{(u)})\)进行重构来预测缺失的ratings。
正式的,给定在\(R^d\)中的一个S集合,\(k \in N_{+}\),一个autoencoder可以求解:
\[min_{\theta} \sum_{r \in S} \| r - h(r;\theta) \|_2^2\]…(1)
其中,\(h(r;\theta)\)是对输入\(r \in R^d\)的重构(reconstruction):
\[h(r;\theta) = f(W \cdot g(Vr + \mu) +b)\]对于激活函数 \(f(\cdot), g(\cdot)\)。这里,\(\theta = \lbrace W, V, \mu, b \rbrace\)对于转换(transformations): \(W \in R^{d \times k}, V \in R^{k \times d}\),其中biases为: \(\mu \in R^k, b \in R^d\)。该目标函数对应于一个自关联的神经网络(auto-associative neural network),它使用单个k维的hidden layer。参数\(\theta\)可以通过backpropagation进行学习。
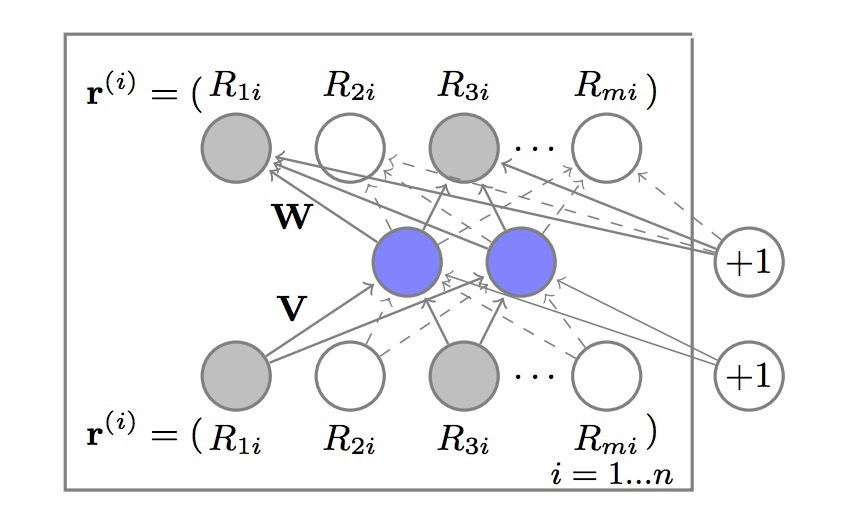
图1: Item-based AutoRec模型。我们使用plate notation来表示,该网络存在n个拷贝(每个item一个),W和V跨多个拷贝绑定。
item-based AutoRec模型,如图1所示,使用一个autoencoder作为等式(1)到向量集合\({r^{(i)}}_{i=1}^n\)中,有两个重要变化。第一,我们会解释:每个\(r^{(i)}\)通过在BP期间的更新上关权重来被部分观测,这一点与矩阵分解和RBM方法相同。第二,我们会对学习参数进行正则化,以便防止在观测到的ratings上overfitting。正式的,Item-based AutoRec (I-AutoRec)模型的目标函数是:
\[min_{\theta} \sum_{i=1}^{n} \| r^{(i)} - h(r^{(i)};\theta)) \| _O^2 + \frac{\lambda}{2} \cdot ( \| W\|_{F}^2 + \| V \| _{F}^2)\]…(2)
其中,\(\|\cdot \|_O^2\)意味着,我们只需考虑可观测评分的贡献即可。User-based AutoRec (U-AutoRec)则由 \(\lbrace R^{(u)} \rbrace_{u=1}^m\)而来。总之,I-AutoRec 需要估计 \(2 mk + m + k\)个参数。给定要学习的参数\(\hat{\theta}\),I-AutoRec会为用户u和item i预测相应的评分:
\[\hat{R}_{ui} = (h(r^{i}; \hat{\theta}))_u\]…(3)
图一展示了该模型,阴暗色节点表示观测到的评分,实线连接对应于权重(对于输入\(r^{(i)}\)要更新的权重)
AutoRec与已经存在的CF方法不同。对比RBM-based CF模型,有一些不同之处:
- 1.RBM-CF提出了一种通用的概率模型,它基于Boltzmann机;而AutoRec是一个判别模型(discriminative model),它基于autoencoders
- 2.RBM-CF通过最大化log似然来估计参数,而AutoRec直接最小化RMSE(在评分预测上的标准评判指标)。
- 3.训练RBM-CF需要使用对比散度( contrastive divergence),而训练AutoRec需要比较快的基于梯度的BP算法。
- 4.RBM-CF也用于离散评分,并每个评分值估计一个独立的参数集合
对于r个可能的评分,这意味着对于user-based RBM有nkr个参数;对于item-based RBM有mkr个参数。AutoRec对于r是不可知的,因而需要更少的参数。更少参数能让AutoRec具有更少的内存占用,不容易overfitting。对于MF(矩阵分解)方法,会将users和items嵌入到一个共享的隐空间中;而item-based AutoRec模型只会将items嵌入到隐空间中。再者,MF会学到一个线性隐表示,AutoRec可以通过激活函数\(g(\cdot)\)学到一个非线性隐表示。
3.实验评估
在本部分,在数据集:Movielens 1M, 10M and Netflix datasets上评估了AutoRec、RBM-CF、BiasedMF、以及LLORMA。接着,我们使用一个缺省的评分3用于测试users或items,没有训练观察。我们将数据划分为:随机的90%-10%的train-test集合,并留下10%的训练集数据进行超参数调节。我们会重复5次的splitting过程,并上报平均的RMSE。在RMSE上的95%置信区间是\(\pm 0.003\),或者更小。对于所有baselines,我们会将正则参数\(\lambda \in {0.001, 0.01, 0.1, 1, 100, 1000}\)以及合理的隐维度\(k \in {10, 20, 40, 80, 100, 200, 300, 400, 500}\)
训练autoencoders的一个挑战是,目标函数的非凸性。我们发现RProp与L-BFGS对比来说会更快。因此,我们在所有实验中使用RProp:在item-based和user-based方法上,对于RBM或AutoRec autoencoding哪个更好?表1a展示了item-based(I-)方法上,RBM和AutoRec通常会更好;这很可能是因为每个item的评分平均数,比单用户的要多;对于user-based方法,user ratings的数目的高偏差会导致更低可靠性的预测。I-AutoRec的效果要比所有RBM变种要好。
AutoRec的效果随线性和非线性激活函数\(f(\cdot)\)是如何变化的?表1b展示了在hidden layer中的非线性(通过\(g(\cdot)\))对于I-AutoRec上取得好效果是很重要的,它比MF更好。将sigmoid替换为Relu效果会差些。所有AutoRec实验使用标准的\(f(\cdot)\)和sigmoid \(g(\cdot)\)函数。
AutoRec的hidden units数目与效果是啥关系?在图2中,我们评估了AutoRec模型的效果,AutoRec会随着hidden units数目变化,并且收益递减。所有AutoRec实验使用k=500.
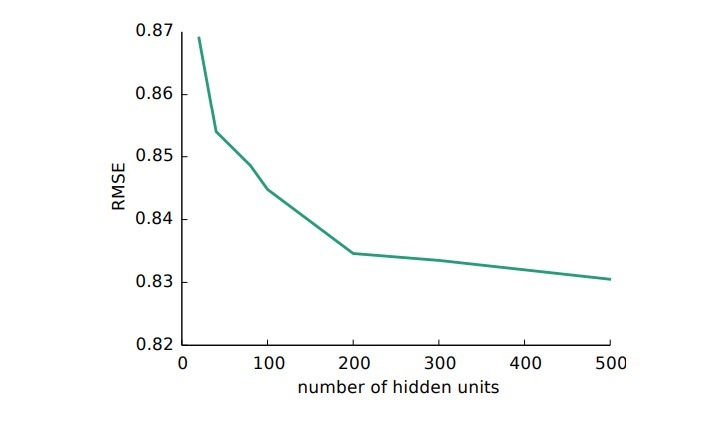
图2: I-AutoRec在Movielens 1M上的RMSE,随hidden units数目k而变化
AutoRec的效果与所有baseline相比如何?表1c展示了AutoRec会一直好于所有baseline。

表1: a) I/U-AutoRec与RBM模型的比较 b) I-AutoRec中线性与非线性选择 c) I-AutoRec与其它baseline模型的比较
对autoRec的深度做扩展如何?我们开发了一个深度版本的I-AutoRec,它有三个hidden layers(500, 250, 500),每个使用sigmoid激活。我们使用贪婪预训练,接着通过梯度下降调参。在Movielens 1M上,RMSE会从0.831降至0.827, 表示有提升。