CRNN( Convolutional Recurrent Neural Network)由华科白翔等人提出。
介绍
crnn主要关注CV中的一个经典难题:基于图片的序列识别。现实世界中,一大群视频对象,比如场景文字(scene text)、手写、音阶符,以序列方式出现。不同于通用目标识别,识别这样的序列对象通常需要系统去预测一串对象labels,而非单个label。因而,识别这样的目标很自然地转化成一个序列识别问题。序列化目标的另一个独特属性是,它们的长度变化很大。例如,英文词汇可以包含2个字符“OK”,也可以包含15个符如“congratulations”。因而,大多数流行的deep模型(比如DCNN)不能直接应用于序列预测,因为DCNN模型经常在固定维度的inputs和outputs上操作,不能产生变长的label sequence。
对于一个特定的序列对象(比如:场景文字),已经有一些方法来解决该问题。例如,在[35,8]中的算法首先对单个字符进行检测,接着对这些被检测的字符使用DCNN进行识别,可以使用带标注的字符图片进行训练。这样的方法通常需要训练一个很强的字符检测器,来从原始图片中精准地检测和裁减每个字符。一些其它方法[22]会将场景文字识别看成是一个分类问题,为每个英文词汇(总共90K words)分配一个class label。将它看成是一个带有大量分类的训练模型,它很难泛化到其它类型的目标上,比如:中文文字、音阶等,因为这种类型序列的基本组合远超100w。总之,当前基于DCNN的系统不能直接用于基于图片的序列识别。
RNN模型是Deep模型的另一分支,主要用于处理序列。RNN的一个好处是,它不需要知道在训练和测试时一个序列目标图片中每个元素的位置。然而,需要有一个预处理step来将一个输入目标图片转化成一个图片特征序列。例如,Graves et al.[16]从手写文本中抽取一个几何集合 或者 图片特征,而paper[33]将word images转化成顺序化的HOG特征。这些预处理step与pipeline中的子任何组件相互独立,因而,基于RNN的系统不能以一种end-to-end的方法地直接被训练和优化。
一些传统的场景文字识别方法,它们不基于神经网络,也能在该领域带来重大启发和新颖的表示。paper[5]和paper[30]提出来将word images和text strings嵌入到一个公共的向量子空间中,将文字识别转换成一个检索问题(retrieval problem)。paper[36]和paper[14]使用中间级别的特征来进行场景文字识别。尽管在标准的benchmarks上取得了效果提升,这些方法总体上好于之前的神经网络方法,本文方法也能做到。
该paper的主要贡献是一个新的NN模型,它的网络架构是专门为识别图片中的序列化对象而设计的。提出的NN模型被命名为“CRNN ( Convolutional Recurrent Neural Network)”,因为它是一个DCNN和RNN的组合。对于序列化对象,比起CNN模型,CRNN具有着一些明显的优点:
- 1) 它可以直接从sequence labels(例如:words)中学习,无需详细注解(例如:characters)
- 2) 在从图片数据中直接学习有信息表示时,它具有DCNN的相同特性,即不用手工特征,也不用预处理steps(包括:二值化/分割,成分定位等)
- 3) 它具有RNN的相同属性,可以产生一个labels序列
- 4) 它不限制序列化对象的长度,在训练和测试阶段只需要高度归一化
- 5) 它在场景文字识别上,比之前的方法要好
- 6) 比起标准的DCNN,它包含了更少的参数,消耗更少的存储空间
2.网络结构
CRNN的网络结构如图1所示,自底向上,包含了三个组成部分:
- 卷积层(conv layers)
- 递归层(recurrent layers)
- 一个合成层(transcription layer)

图1
在CRNN的底部,conv layers从每一张输入图片中自动抽取一个特征序列。在卷积网络的顶部,构建一个recurrent网络来对通过conv layers输出的每一帧的特征序列做预测。transcription layer将每一帧的预测翻译成一个label sequence。尽管CRNN由不同的网络结构组成,它可以使用一个loss function进行jointly training。
2.1 特征序列抽取
在CRNN模型中,conv layers的组件通过从一个标准的CNN模型所使用的conv layers和max-pooling layers进行构建(移除FC layers)。这样的组件被用于从一个输入图片中抽取一个序列化特征表示。在feed给网络之前,所有的图片需要被归一化成相同的高度。接着,一个特征向量的序列会从feature maps中被抽取出来。特别的,一个特征序列的每个feature vector通过在feature maps上按列从左到右来生成。这意味着,第i个feature vector是所有maps中的第i列的拼接(concatenation)。在我们的设置中,每一列的宽度寄存定为单个pixel。
由于有conv layers、max-pooling layers、以及element-wise激活函数在局部区域上操作。它们是平移不变的(translation invariant)。因而,feature maps的每列对应于原始图片的一个矩形区域(术语称为“receptive field”),这样的矩形区域与在feature maps中相应的从左到右的相对应的列具有相同的顺序。如图2所示,在特征序列中的每个vector与一个receptive field相关联,可以被看成是该区域的图片描述符。

图2: receptive field. 在被抽取的特征序列中,每个向量都与输入图片上的一个receptive field相关,可以被认为是该区域的特征向量
对于不同类型的视觉识别任务,健壮的、丰富的、可训练的卷积特征被广泛使用。一些之前的方法采用CNN来学习一个关于序列目标(比如:场景文字)的健壮表示。然而,这些方法通常会通过CNN来抽取整个图片的全局表示,接着收集局部深度特征来识别该序列目标。由于CNN需要输入图片缩放到一个固定size,以满足固定的输入维度,不适合变长的序列化目标识别。在CRNN中,我们将deep features转成顺序表示,以便能表示不同长度的序列化目标。
2.2 Sequence Labeling
在conv layers之上,构建了一个deep bi-RNN网络。该recurrent layers可以为在特征序列\(x = x_1, ..., x_T\)中的每一帧\(x_t\)预测一个label分布\(y_t\)。该recurrent layer的优点有三个。
- 首先,RNN具有很强的能力来捕获在序列中的上下文信息。对于基于图片的序列识别使用上下文信息,比将每个符号单独对待的方式更稳定更有用。将场景文本识别看成一个示例,宽字符可能需要许多个连续帧才能完整描述(如图2所示)。另外,当观察它们的上下文时,一些模糊的字符很容易区分;例如,很容易识别“il”,通过区别该字符高度而非单个字符单独识别。
- 第二,RNN可以对error微分进行反向传播至它的输入(例如:conv layer),从而允许我们在同一网络中对recurrent layers和conv layers进行jointly training。
- 第三,RNN能在特有长度的序列上操作,从头到尾进行遍历。
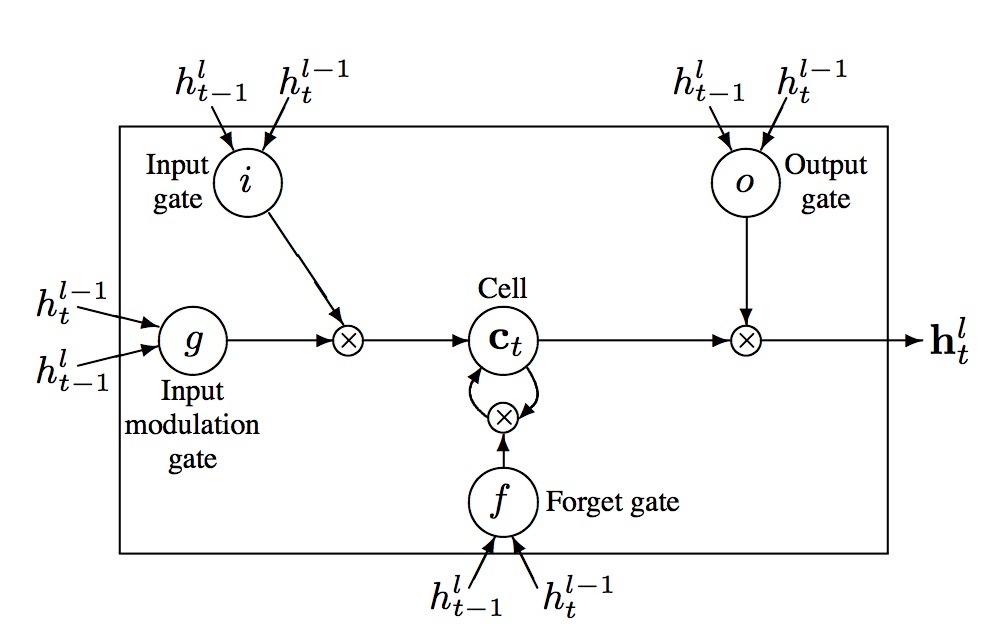
一个典型的RNN unit在它的input layers和output layers间具有自连接的hidden layer。每次它接受序列中的一帧\(x_t\)时,它会使用一个带有当前输入\(x_t\)和过去状态\(h_{t-1}\)作为输入的非线性函数(\(h_t = g(x_t, h_{t-1})\))来更新它的内部状态\(h_t\)。接着,基于\(h_t\)做出预测\(y_t\)。在这种方式下,过去的上下文 \(\{x_{t'} \}_{t'<t}\)可以被捕获并用来进行预测。然而,传统的RNN unit,存在着梯度消失问题,这限制了它可存储的上下文范围,增加了训练过程的负担。LSTM是一种特殊的RNN unit,可以用来解决该问题。一个LSTM(如图3所示)包含了一个memory cell和三个乘法门,称为:input gates, output gates和forget gates。概念上,memory cell会存储过去的上下文,input gates和output gates允许cell存储一段时间的上下文。同时,在cell中的memory可以被forget gate清除。LSTM的这种特殊设计允许它捕获长范围依赖,这通常发生在基于图片的序列上。
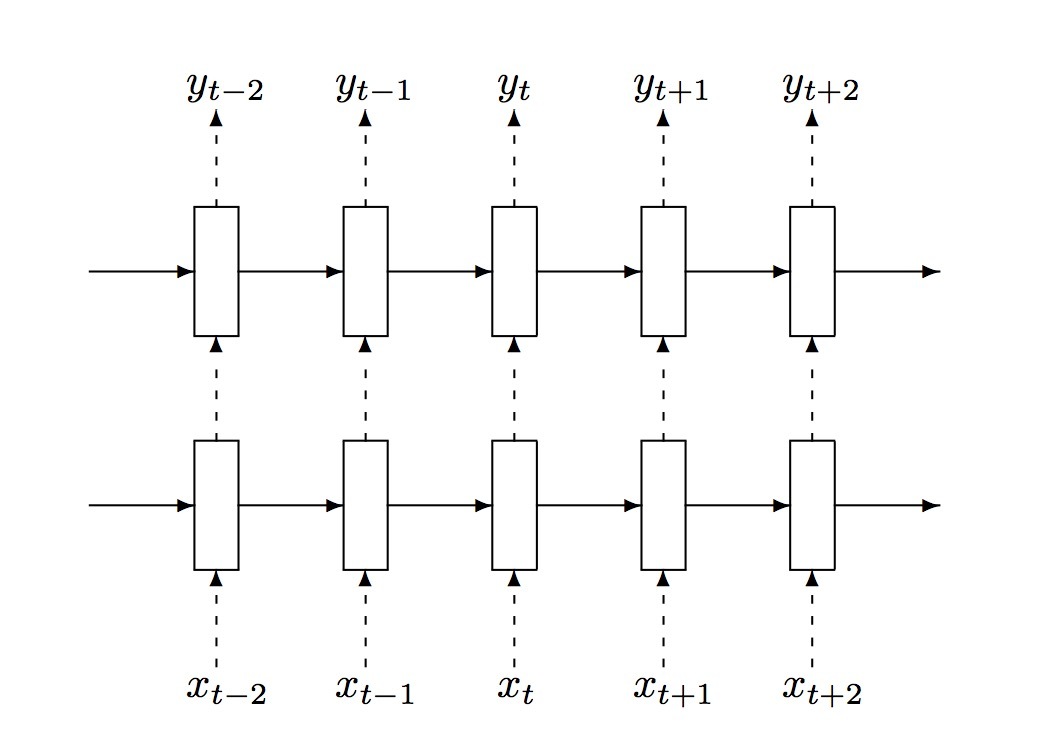
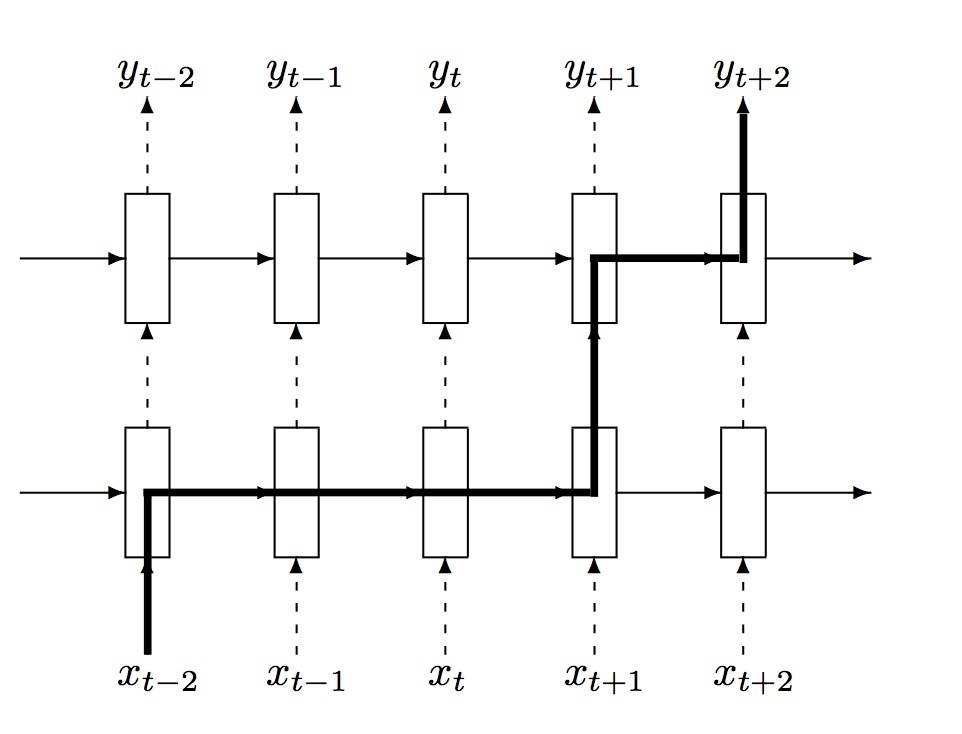
LSTM是有向的,它只使用过去的上下文。然而,在基于图片的序列中,两个方向的上下文都是有用的。因而,我们使用了两个LSTMs来组成双向LSTM:一个向前,一个向后。另外,多个bi-LSTMs可以进行stack,产生一个如图3.b所示的deep bi-LSTM。deep结构比shallow结构允许更高级的抽象,在语音识别上可以达到极大的效果提升[17]。

图3: LSTM. (a) 单个LSTM unit (b)paper中所使用的bi-LSTM结构。它会将一个forward LSTMs和一个backward LSTMs组合产生一个bi-LSTM。将多个bi-LSTM进行Stacking可以产生一个deep bi-LSTM。
在recurrent layers上,error微分(differentials)沿如图3.b所示的箭头反向传播,例如:Back-Propagation Through Time(BPTT)。在recurrent layers的底部,传播的微分序列被级联成maps,将feature maps转换成feature sequences的操作进行反向,fed back到conv layers。实际上,我们创建了一个定制的network layer,称为“Map-to-Sequence”,来作为在conv layers和recurrent layers间的桥梁。
2.3.1 label序列的概率
我们采用了由Graves et al.[15]提出的Conectionist Temporal Classifcation(CTC) layer中所定义的条件概率。该概率被定义成,对于label sequence (l) ,在每帧预测\(y = y_1, ..., y_T\)上的条件概率,它会忽略在l中每个label所处的位置。因此,当我们使用该概率的负log-likelihood作为目标来训练该网络时,我们只需要图片和它们相应的label序列,从而避免为单独的字符标注位置。
条件概率的公式可以如下简短描述:
输入是一个序列\(y=y_1, ..., y_T\),其中T是序列长度。接着,每个\(y_t \in R^{\|L'\|}\)是一个在集合\(L'=L U\)上的概率分布。其中L包含了任务中的所有labels(例如:所有英文字符),以及空白(blank)label。一个seq-to-seq的映射函数B被定义在序列\(\pi \in L'^{T}\)上,其中T为长度。B将\(\pi\)映射到l上,通过首先移除重复的labels,接着移除空白。例如,B将“–hh-e-l-ll-oo–”(其中’-‘表示空白)映射到”hello”。接着,条件概率被定义成通过B将所有\(\pi\)映射到l上概率求和:
\(p(l|y) = \sum_{\pi : B(\pi) = 1} p(\pi | y)\) …(1)
其中\(\pi\)的概率被定义成\(p(\pi \| y) = \prod_{t=1}^{T} y_{\pi_t}^t\),其中\(y_{\pi_t}^t\)是在时间t时具有label \(\pi_t\)的概率。直接计算等式(1)在计算上是不可行的,因为求和项是指数级别的。然而,等式(1)可以通过paper[15]中提到forward-backward算法进行有效计算。
2.3.2 Lexicon-free transcription
在该模式下,序列 \(l^{*}\)表示等式(1)的最高概率。由于不存在可训练的算法来精准求解,我们使用paper[15]的策略进行。序列\(l^{*}\)可以通过\(I^{*} = B(arg max_{\pi} p(\pi \| y))\)进行近似。例如,在每一时刻t上采用最可能的label \(\pi_t\),将产生的序列映射到\(l^{*}\)上。
2.3.3 Lexicon-based transcription
在lexicon-based模式下,每个测试样本会与一个词典D相关系。通常,label序列通过选择在词典中具有等式(1)的最高条件概率的序列被识别。例如,\(l^{*} = arg max_{I \in D} p(l \|y)\)。然而,对于大词典,例如,50k-words的Hunspell spell-checking dictionary,在词典上执行搜索是一个非常耗时的开销。例如,为在词典中的所有的sequence计算等式(1)的概率,并选择最高的概率。为了解决该问题,我们观察到,label sequences通过lexicon-free transcription方式进行预测,通常会在编辑距离(edit distance metric)上更接近ground truth。这意味着,我们可以将我们的搜索限制在最近邻候选\(N_{\delta}(l')\)上,其中\(\delta\)是最大编辑距离,I’是在lexicon-free模式下从y转录得到的序列:
\(I^{*} = arg max_{I \in N_{\delta}(I')} p(l | y)\)…(2)
候选\(N_{\delta}(l')\)可以通过BK-tree结构有效发现,它是一种metric tree用来离散化metric空间。BK-tree的搜索时间复杂度为\(O(log \| D \|)\),其中\(\|D\|\)是lexicon size。因此,该scheme可以扩展到非常大的词典上。在我们的方法中,为一个词典离线构建了一个BK-tree。接着,我们使用该tree执行了最快的在线搜索,通过小于或等于到query sequence的\(\delta\)编辑距离来发现序列。
2.4 网络训练
训练数据集通过\(X = \{I_i, l_i \}_i\)的定义,其中\(I_i\)是训练图片,\(l_i\)是ground truth的label sequence。目标函数是最小化ground truth的条件概率的-log-likelihood:
\(O = - \sum_{I_i, l_i \in X} log p(l_i | y_i)\) …(3)
其中,\(y_i\)是由\(I_i\)经过recurrent layers和conv layers所产生的序列。该目标函数会从一张图片和它的ground truth的label序列间计算一个cost value。因此,该网络可以在(images, sequences) pairs上进行端到端训练,消除训练图片中由人工标注所有独立components的过程。
该网络使用SGD进行训练。Gradients的计算通过BP算法进行。特别的,在transcription layer,error微分通过back-propagated结合forward-backward算法计算。在recurrent layers,会使用Back-Propagation Through Time (BPTT) 来计算error微分。
对于optimization,我们使用AdaDelta来自动计算每个维度的learning rates。对比常用的momentum方法,AdaDelta无需人工设置一个learning rate。更重要的,我们发现,使用AdaDelta的optimization比momentum方法收敛更快。
3.试验
为了评估CRNN模型的有效性,我们在场景文识别和音阶识别的标准benchmarks上进行试验。
3.1 Datasets
对于场景文本识别的所有试验,我们使用Jaderberg【20】的synthetic dataset (Synth)作为试验。该dataset包含了800w的训练图片,以及相应的ground truth的words。这样的图片通过一个人造文本引擎(synthetic text engine)生成,高度与现实相近。我们的网络在synthetic data上训练一次,并在其实真实世界的测试数据集上进行测试,无需在其它训练数据上做任何的fine-tuning。即使用CRNN模型是纯粹使用synthetic text data训练的,它也能在标准的文本识别becnmarks上工作良好。
目前在效果评测方面,使用了4种流行的场景文本识别benchmarks:
- ICDAR 2003(IC03):该测试数据集包含了带标注文本边框的251张场景图片。根据paper[34],我们忽略了那些包含非字母数字字符、以及那些小于三个字符的图片,获得的测试集包含了860个裁减过的文本图片。每张测试图片与一个50-words的词典相关联(由paper[34]定义)。一个完整的词典可以通过组合所有单张图片的词典来构成。另外,我们使用了一个50k个词的词典,它包含了在Hunspell spell-checking dictionary字典中的所有词。
- ICDAR 2013 (IC13):测试数据集继承了IC03上的大多数数据,它包含了1015张ground truth的裁减word images。
- IIIT 5k-word (IIIT5k):包含了3000张来自互联网上的word test images。每张图都与一个50词的词典和1k-words词典相关。
- Street View Text (SVT):该测试数据集包含了来自Google Street View的249张街景门牌图片。从它们中裁减出647张word images。每张word images具有一个由paper[34]定义的50 words的词典。
3.2 实现细节
在我们的实验中,所使用的配置如表1所示:

表1:
conv layers基于一个VGG-VeryDeep架构(paper[32])。为了让它更适合识别英文字符,会做一定调整。在第3和第4个max-pooling layers中,我们采用了1x2 的rectangular pooling window来替代常见的squared方法。该tweak yields的feature maps具有更大的宽度,更长的feature序列。例如,一张包含了10字符的图片,通常size=100x32, 其中一个feature sequence可以生成25帧。该长度超过了最大英文词汇的长度。在那之上,rectangluar pooling windows会生成rectangular receptive fields(如图2),它有益于识别具有narrow shapes的一些字符,比如’i’和’l’。
该网络不只具有deep conv layers,但也具有recurrent layers。两者很难训练。我们发现使用batch-normalization技术来训练这样深度的网络很有用。两个batch-normalization layers,训练过程可以极大加速。
我们使用torch7来实现该网络框架,定制实现了LSTM units(Torch7/CUDA),transcription layer(c++)和BK-tree数据结构(c++)。实验在工作站(2.50 GHz Intel(R) Xeon(R) E5- 2609 CPU, 64GB RAM 以及NVIDIA(R) Tesla(TM) K40 GPU)上进行训练。该网络的训练使用AdaDelta进行训练,相应的\(\rho\)为0.9. 在训练期间,所有图片被归一化到100 x 32,以加速训练过程。训练过程大概达到50个小时后收敛。测试图片的高度被归一化到32. 宽度按高度的比例进行缩放,但至少是100个像素。平均测试时间是0.16s/sample,在IC03上进行评测,没有词典。合适的词典搜索被应用于IC03的50k词典上,参数\(\delta\)设置为3.每个测试样本平均花费0.53s。
评测
略,详见paper.