前几天微软提出了一个xDeepFM算法:
介绍
传统交叉特征工程主要有三个缺点,以下部分来自paper:
- 1.获取高质量特征代价高昂
- 2.大规模预测系统(比如:推荐系统),存在大量原始特征(raw features),很难人工抽取所有交叉特征
- 3.人工交叉特征不能泛化到在训练数据中未见过的交叉上
FM会将每个特征i嵌入到一个隐因子向量 \(v_i = [v_{i1}, v_{i2}, ..., v_{iD}]\)上,pairwise型特征交叉可以被建模成隐向量的内积:\(f^{(2)}(i,j)=\langle v_i, v_j \rangle x_i x_j\)。在本paper中,我们使用术语bit来表示在隐向量中的一个元素(比如:\(v_{i1}\))。经典的FM可以被扩展到专门的高阶特征交叉上,但一个主要缺点是:会建模所有的特征交叉,包括有用组合和无用组合。无用组合会引入噪声、以及效果的下降。最近几年,DNNs越来越流行。利用DNNs可以学习复杂和可选择的特征交叉。[46]提出来FNN用于学习高阶特征交叉。它会使用对于field embedding的预训练FM,然后应用于DNN。[31]提出了PNN,它不依赖预训练的FM,而是在embedding layer和DNN layer之间引入了一个product layer。FNN和PNN的主要缺点是,它们主要更多关注高阶特征交叉,而非低阶交叉。Wide&Deep模型和DeepFM模型通过引入混合结构克服了上面的缺点,它包含了一个shallow组件以及一个deep组件,可以学到memorization和generalization。因而可以联合学习低阶和高阶特征交叉。
上面的所有模型都使用DNN来学习高阶特征交叉。然而,DNN可以以一个隐式的方式建模高阶特征交叉。由DNN学到的最终函数可以是任意形式,关于特征交叉的最大阶数(maximum degree)没有理论上的结论。另外,DNNs在bit-wise级别建模征交叉,这与FM框架不同(它会在vector-wise级别建模)。这样,在推荐系统的领域,其中DNN是否是用于表示高阶特征交叉的最有效模型,仍然是一个开放问题。在本paper中,我们提供了一个基于NN的模型,以显式、vector-wise的方式来学习特征交叉。我们的方法基于DCN(Deep&Cross Network)之上,该方法能有效捕获有限阶数(bounded degree)的特征交叉。然而,我们会在第2.3节讨论,DCN将带来一种特殊形式的交叉。我们设计了一种新的压缩交叉网络CIN(compressed interaction network)来替换在DCN中的cross network。CIN可以显式地学到特征交叉,交叉的阶数会随着网络depth增长。根据Wide&Deep模型和DeepFM模型的精神,我们会结合显式高阶交叉模块和隐式交叉模型,以及传统的FM模块,并将该联合模型命名为“eXtreme Deep Factorization Machine (xDeepFM)”。这种新模型无需人工特征工程,可以让数据科学家们从无聊的特征搜索中解放出来。总结一下,主要有三个贡献:
- 提出了一种新模型xDeepFM,可以联合训练显式和隐式高阶特征交叉,无需人工特征工程
- 设计了CIN来显式学习高阶特征交叉。我们展示了特征交叉的阶(degree)会在每一层增加,特征会在vector-wise级别进行交叉。
- 我们在三个数据集中进行了实验,结果展示xDeepFM效果好于其它state-of-art模型
2.PRELIMINARIES
2.1 Embedding Layer
在CV或NLP领域,输入数据通常是图片或文本信号,它们空间相关(spatially correlated)或时序相关(temporally correlated),因而DNN可以被直接应用到dense结构的原始特征上。然而,在推荐系统中,输入特征是sparse、高维、没有明显地空间相关或时序相关。因此,multi-field类别形式被广泛使用。例如,一个输入实例为:
[user_id=s02,gender=male,organization=msra,interests=comedy&rock]
通过field-aware one-hot进行编码成高维稀疏特征:
\[[\underbrace{0, 1, 0, 0, ..., 0}_{userid}]
[\underbrace{1, 0}_{gender}]
[\underbrace{0, 1, 0, 0, ..., 0}_{organization}]
[\underbrace{0, 1, 0, 1, ..., 0}_{interests}]\]
在原始特征输入上使用一个embedding layer,可以将它压缩到一个低维、dense、real-value vector上。如果field是一阶的(univalent),feature embedding被当成field embedding使用。以上述实例为例,特征(male)的embedding被当成field gender的embedding。如果field是多阶的(multivalent),feature embedding的求和被用于field embedding。embedding layer如图1所示。embedding layer的结果是一个wide concatenated vector:
\[e = [e_1, e_2, ..., e_m]\]
其中,m表示fields的数目,\(e_i \in R^D\)表示一个field的embedding。尽管实例的feature长度可以是多变的,它们的embedding具有相同的长度 m x D, 其中D是field embedding的维数。

图1: field embedding layer。本例中embedding的维度是4
2.2 隐式高阶交叉
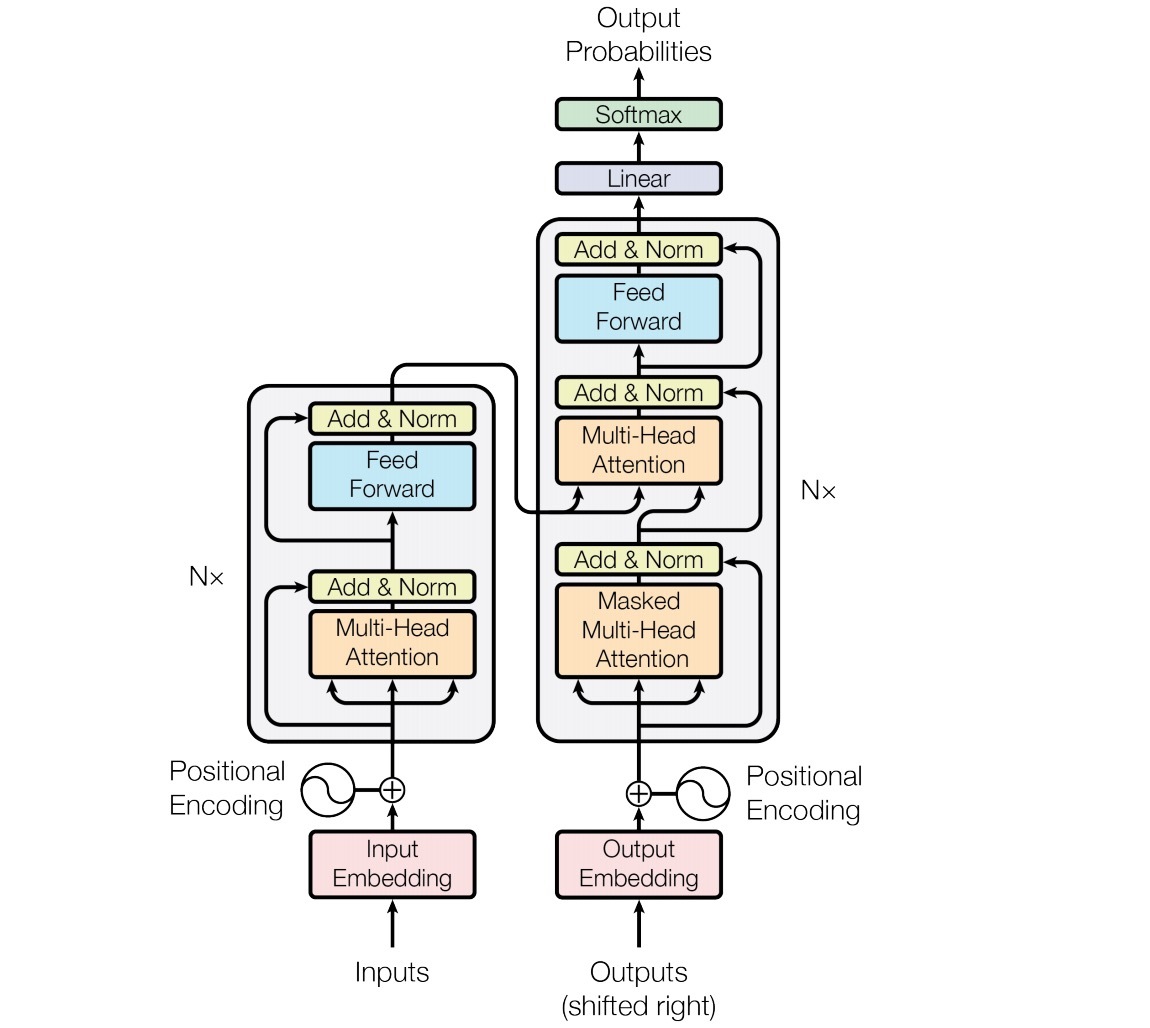
FNN, Deep&Cross,以及Wide&Deep的deep part会使用一个在field embedding vector e上的feed-forward神经网络来学习高阶特征交叉。forward process是:
\[x^1 = \delta(W^{(1)} e + b^1)\]
…(1)
\[x^k = \delta(W^{(k)} x^{(k-1)} + b^k)\]
…(2)
其中,k是layer depth,\(\delta\)是激活函数,\(x^k\)是第k层的output。可视化结构与图2展示的非常像,但不包括FM layer或Product layer。该结构会以bit-wise的方式建模交叉。也就是说,相同field embedding vector中的元素也会相互影响。
PNN和DeepFM在上述结构上做了小修改。除了在embedding vector e上应用了DNNs外,它们在网络中添加了一个2-way interaction layer。因而,bit-wise和vector-wise的交叉都能在模型中包含。PNN和DeepFM中主要不同是,PNN会将product layer的输出连接到DNNs中,而DeepFM会直接将FM layer连接给output unit。

图2: DeepFM和PNN的架构。我们复用了符号,其中红色边表示weight-1 connections(没有参数),灰色边表示normal connections(网络参数)
2.3 显式高阶交叉
[40]提出的Cross Network(CrossNet)它的结构如图3所示:

图3:
它可以显式建模高阶特征交叉。不同于经典的fully-connected feed-forward network,它的hidden layers通过以下的cross操作进行计算:
\[x_k = x_0 x_{k-1}^T w_k + b_k + x_{k-1}\]
…(3)
其中,\(w_k, b_k, x_k \in R^{mD}\)是第k层的weights,bias以及output。对于CrossNet能学到一个特殊类型的高阶交叉这一点我们有争论,其中,CrossNet中的每个hidden layer是一个关于\(x_0\)的标量乘积。
theorem 2.1: 考虑到一个k层cross network,第i+1层的定义为:\(x_{i+1} = x_0 x_i^T w_{i+1} + x_i\)。接着,cross network的output \(x_k\)是一个关于\(x_0\)的标量乘积。
证明如下:
k=1时,根据矩阵乘法的结合律和分配律,我们具有:
\[x_1 = x_0 (x_0^T w_1) + x_0 = x_0 (x_0^T w_1 +1) = \alpha^1 x_0\]
…(4)
其中,标量\(\alpha^1 = x_0^T w_1 + 1\)实际上是关于\(x_0\)的线性回归。其中,\(x_1\)是关于\(x_0\)的一个标量乘。假设标量乘适用于k=i。对于k=i+1, 我们可以有:
\[x_{i+1} = x_0 x_i^T w_{i+1} + x_i = x_0 (( \alpha^i x_0)^T w_{i+1}) + \alpha^i x_0 = \alpha^{i+1} x_0\]
…(5)
其中,\(\alpha^{i+1} = \alpha^i (x_0^T w_{i+1} + 1)\)是一个标量。其中,\(x_{i+1}\)仍是一个关于\(x_0\)的标量乘。通过引入hypothesis,cross network的output \(x_k\)是一个关于\(x_0\)的标量乘。
注意,\(标量乘(scalar multiple)\)并不意味着\(x_k\)是与\(x_0\)是线性关系的。系数\(\alpha^{i+1}\)是与\(x_0\)敏感的。CrossNet可以非常有效地学到特征交叉(复杂度与一个DNN模型对比是微不足道的),然而,缺点是:
- (1) CrossNet的输出受限于一个特定的形式,每个hidden layer是关于\(x_0\)的一个标量乘
- (2) 交叉是以bit-wise的方式进行
3.新模型
3.1 CIN
我们设计了一个新的cross network,命名为CIN(Compressed Interaction Network),具有如下注意事项:
- (1) 交叉是在vector-wise级别上进行,而非bit-wise级别
- (2) 高阶特征的交叉显式衡量
- (3) 网络的复杂度不会随着交叉阶数进行指数增长
由于一个embedding vector被看成是一个关于vector-wise 交叉的unit,后续我们会将field embedding公式化为一个矩阵:\(X^0 \in R^{m \times D}\),其中,假设\(H_0=m\),\(H_k\)表示在第k层的(embedding)feature vectors的数量。对于每一层,\(X^k\)通过以下方式计算:
\[x_{h,*}^k = \sum_{i=1}^{H_{k-1}} \sum_{j=1}^{m} W_{ij}^{k,h} (x_{i,*}^{k-1} \circ x_{j,*}^{0})\]
…(6)
其中\(1 \le h \le H_i\),\(W^{k,h} \in R^{H_{k-1} \times m}\)是第h个feature vector的参数矩阵,\(\circ\)表示Hadamard product,例如:\(\langle a_1,a_2,a_3 \rangle \circ \langle b_1,b_2,b_3 \rangle = \langle a_1 b_1, a_2 b_2, a_3 b_3 \rangle\)。注意,\(X^k\)通过在\(X^{k-1}\)和\(X^0\)间的交叉产生,其中,特征交叉会被显式衡量,交叉的阶数会随着layer depth增长。CIN的结构与RNN非常相似,其中下一个hidden layer的outputs取决于最近一个(the last)的hidden layer和一个额外的input。我们在所有layers上都持有embedding vectors的结构,这样,即可在vector-wise级别上使用交叉。

图4
有意思的是,等式(6)与CNN具有很强的关联。如图4a所示,我们引入了一个内部张量(intermediate tensor) \(Z^{k+1}\),其中,它是hidden layer\(X^k\)和原始特征矩阵\(X^0\)的外积(outer products:沿着每个embedding维度)。\(Z^{k+1}\)被看成是一个特殊类型的图片,\(W^{k,h}\)看成是一个filter。我们如图4b所示跨\(Z^{k+1}\)沿着该embedding dimension(D)滑动该filter,获得一个hidden vector \(X_{i,*}^{k+1}\),这在CV中通常被称为一个feature map。在CIN命名中所使用的术语”compressed”表示了第k个hidden layer会将 \(H_{k-1} \times m\)向量的隐空间压缩到\(H_k\)向量中。
图4c提供了CIN的一个总览。假设T表示网络的深度。每个hidden layer \(X^k, k \in [1,T]\)具有一个与output units的连接。我们首先在hidden layer的每个feature map上使用sum pooling:
\[p_i^k = \sum_{j=1}^D X_{i,j}^k\]
…(7)
其中,\(i \in [1, H_k]\)。这样,我们就得到一个pooling vector:\(p^k = [p_1^k, p_2^k, ..., p_{H_k}^k]\),对于第k个hidden layer相应的长度为\(H_k\)。hidden layers的所有polling vectors在连接到output units之前会被concatenated:\(p^{+} = [p^1, p^2, ..., p^T] \in R^{\sum_{i=1}^T H_i}\)。如果我们直接使用CIN进行分类,output unit是在\(p^+\)上的一个sigmoid节点:
\[y = \frac{1} {1 + exp(p^{+^T} w_o)}\]
…(8)
其中,\(w^o\)是回归参数。
3.2 CIN详解
我们对CIN进行分析,研究了模型复杂度以及潜在的效果。
3.2.1 空间复杂度
在第k层的第h个feature map,包含了\(H_{k-1} \times m\)个参数,它与\(W^{k,h}\)具有相同的size。因而,在第k层上具有\(H_k \times H_{k-1} \times m\)个参数。考虑到对于output unit的当前最近(the last)的regression layer,它具有\(\sum_{k=1}^T H_k\)个参数,CIN的参数总数是 \(\sum_{k=1}^T H_k \times (1 + H_{k-1} \times m )\)。注意,CIN与embedding dimension D相互独立。相反的,一个普通的T-layers DNN包含了\(m \times D \times H_1 + H_T + \sum_{k=2}^T H_k \times H_{k-1}\)个参数,参数的数目会随着embedding dimension D而增长。
通常,m和\(H_k\)不会非常大,因而,\(W^{k,h}\)的规模是可接受的。当有必要时,我们可以利用一个L阶的分解,使用两个小的矩阵\(U^{k,h} \in R^{H_{k-1} \times L}\)以及\(V^{k,h} \in R^{m \times L}\)来替换\(W^{k,h}\):
\[W^{k,h} = U^{k,h} (V^{k,h})^T\]
…(9)
其中\(L \ll H\)以及\(L \ll m\)。出于简洁性,我们假设每个hidden layer都具有相同数目(为H)的feature maps。尽管L阶分解,CIN的空间复杂度从\(O(mTH^2)\)下降到\(O(mTHL + TH^2L)\)。相反的,普通DNN的空间复杂度是\(O(m D H + TH^2)\),它对于field embedding的维度D是敏感的。
3.2.2 时间复杂度
计算tensor \(Z^{k+1}\)的开销是O(mHD)。由于我们在第一个hidden layer上具有H个feature maps,计算一个T-layers CIN会花费\(O(m H^2 DT)\)时间。相反的,一个T-layer plain DNN,会花费\(O(m H D + H^2 T)\)时间。因此,CIN的主要缺点是在时间复杂度上。
3.2.3 多项式近似(Polynomial Approximation)
接下来,我们检查了CIN的高阶交叉属性。出于简洁性,我们假设,在hidden layers上的feature maps数目,等于fields m的数目。假设[m]表示小于或等于m的正整数集。在第1层上的第h个feature map,表示为\(x_h^1 \in R^D\),通过下式计算:
\[x_h^1 = \sum_{i \in [m], j \in [m]} W_{i,j}^{1,h} (x_i^0 \circ x_i^0)\]
…(10)
因此,在第1层的每个feature map会使用\(O(m^2)\)个系数来建模pair-wise特征交叉。相似的,在第2层的第h个feature map为:
\[x_h^2 = \sum_{i \in [m], j \in [m]} W_{i,j}^{2,h} (x_i^1 \circ x_j^0) \\ = \sum_{i \in [m], j \in [m]} \sum_{l \in [m], k \in [m]} W_{i,j}^{2,h} W_{l,k}^{1,i} (x_j^0 \circ x_k^0 \circ x_l^0\]
…(11)
注意,l和k相关的所有计算在前一个hidden layer已经完成。我们在等式(11)扩展的因子是为了清晰。我们可以观察到,在第二层的每个feature map会使用\(O(m^2)\)新参数来建模3-way交叉。
一个经典的k阶多项式具有\(O(m^k)\)系数。我们展示了CIN会逼近这类型多项式,根据一个feature maps链,只需要\(O(k m^3)\)个参数。通过引入hypothesis,我们可以证明,在第k层的第h个feature map为:
\[x_h^k = \sum_{i \in [m], j \in [m]} W_{i,j}^{k,h} (x_i^{k-1} \circ x_j^0) \\ = \sum_{i \in [m], j \in [m]} ... \sum_{r \in [m], t \in [m]} \sum_{l \in [m], s\in [m]} W_{i,j}^{k,h} ... W_{l,s}^{1,r} (x_j^0 \circ ... \circ x_s^0 \circ x_l^0)\]
…(12)
为了更好地演示,我们参考了[40]的注解。假设\(\alpha = [\alpha_1, ..., \alpha_m] \in N^d\)表示一个multi-index,其中\(\| \alpha \| = \sum_{i=1}^m \alpha_i\)。我们会从\(x_i^0\)中忽略原始的上标,使用\(x_i\)来表示它,因为对于最终展开的表达式,我们只关心来自第0层(等同于field embedding)的feature maps。现在,使用一个上标来表示向量操作,比如\(x_i^3 = x_i \circ x_i \circ x_i\)。假设\(V P_k(X)\)表示一个multi-vector 多项式的阶数k:
\[V P_k(X) = \{ \sum_{\alpha} w_{\alpha} x_1^{\alpha_1} \circ x_2^{\alpha_2} \circ ... \circ x_m^{\alpha_m} | 2 \le | \alpha | \le k \}\]
…(13)
在该类中的每个向量多项式都具有\(O(m^k)\)个系数。接着,我们的CIN接似系数\(w_{\alpha}\):
\[\hat{w}_{\alpha} = \sum_{i=1}^m \sum_{j=1}^m \sum_{B \in P_{\alpha}} \prod_{t=2}^{|\alpha|} W_{i, B_t}^{t,j}\]
…(14)
其中,\(B=[B_1, B_2, ..., B_{\| \alpha \|}]\) 是一个multi-index,\(P_\alpha\)是索引(\(1, ..., 1, ..., m, ..., m\))的所有排列。
3.3 与隐式网络的组合
在第2.2节,plain DNNs可以学到隐式高阶特征交叉。由于CIN和plain DNNs可以互补,一个直观的做法是,将这两种结构进行组合使模型更强。产生的模型与Wide&Deep和DeepFM非常像。结构如图5所示,我们将新模型命名为eXtreme Deep Factorization Machine(xDeepFM),一方面,它同时包含了低阶和高阶特征交叉;另一方面,它包含了隐式特征交叉和显式特征交叉。它产生的output unit如下:
\[\hat{y} = \sigma(w_{linear}^T a + w_{dnn}^T x_{dnn}^k + w_{cin}^T p^{+} + b)\]
…(15)
其中,\sigma为sigmoid函数,a是原始特征。\(x_{dnn}^k, p^{+}\)分别是是plain DNN和CIN的outputs。\(w_*\)和b是可学习的参数。对于二分类,loss函数为log loss:
\[L = - \frac{1}{N} \sum_{i=1}^N y_i log \hat{y}_i + (1-y_i) log(1-\hat{y}_i)\]
…(16)
其中,N是训练实例的总数。Optimization过程是最小化下面的目标函数:
\[J = L + \lambda_{*} \| \theta \|\]
…(17)
其中\(\lambda_{*}\)表示正则项,\(\theta\)表示参数集,包含linear part,CIN part,DNN part。

图5: xDeepFM的结构
3.3.1 与FM和DeepFM的关系
假设所有field是一阶的(univalent)。如图5所示,当depth和CIN part的feature maps同时设为1时,xDeepFM就是DeepFM的一个泛化,通过为FM layer学习线性回归权重实现(注意,在DeepFM中,FM layer的units直接与output unit相连,没有任何系数)。当我们进一步移去DNN part,并同时为该feature map使用一个constant sum filter(它简单采用输入求和,无需任何参数学习),接着xDeepFM就变成了传统的FM模型。
4.实验
实验主要回答下述问题:
- (Q1) CIN在高阶特征交叉学习上是如何进行的?
- (Q2) 对于推荐系统来说,将显式和隐式高阶特征交叉相组合是否是必要的?
- (Q3) xDeepFM的网络设置如何影响效果?
4.1 实验设置
4.1.1 数据集
1. Criteo Dataset:ctr预测的benchmarking dataset,对外开放。给定一个用户和他访问的页面,目标是预测它点击一个给定广告的概率。
2. Dianping Dataset:收集了6个月的关于大众点评的用户check-in活动用于餐厅推荐实验。给定一个用户的profile,一个餐厅的相应属性,该用户最近三次访问POIs(point of interest),我们希望预测它访问该餐厅的概率。对于在一个用户的check-in样本中的每个餐厅,我们会通过POI流行度抽样出在3公里内的4个餐厅作为负样本。
3.Bing News Dataset.:Bing News是微软Bing搜索引擎的一部分。我们收集了在新闻阅读服务上连续5天的曝光日志。使用前3天数据用于训练和验证,后两天数据用于测试。
对于Criteo dataset和Dianping dataset,随机将样本划分为8:1:1进行训练、验证、测试。三个数据集的特性如表1所示。

表1:评估数据计的统计。
4.1.2 评估metrics
我们使用两种metrics:AUC和LogLoss。有时更依赖logloss,因为我们需要使用预测概率来估计一个排序系统带来的收益(比如常见的CTR x bid)
4.1.3 Baselines
我们比较了xDeepFM, LR, FM, DNN, PNN, Wide&Deep, DCN, DeepFM.
4.1.4 Reproducibility
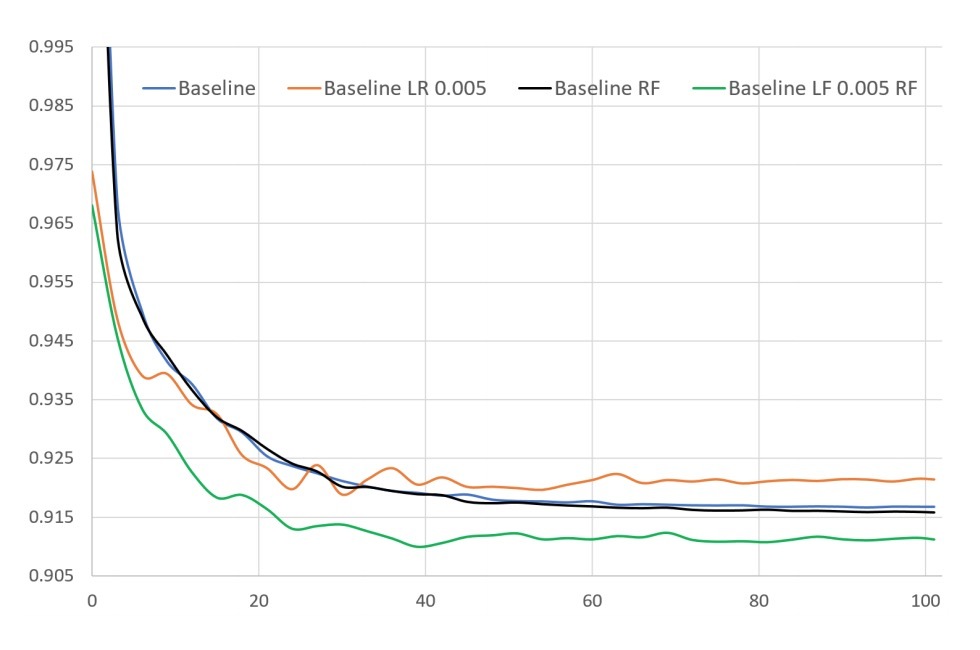
使用tensorflow来实现模型。每个模型的超参数通过在validation set上进行grid-searching调参,然后选择最好的settings。
- learning rate设置为0.001.
- optimization方法使用Adam。
- mini-batch size=4096.
- 对于DNN, DCN, Wide&Deep, DeepFM和xDeepFM,使用L2正则,对应的\(\lambda=0.0001\)
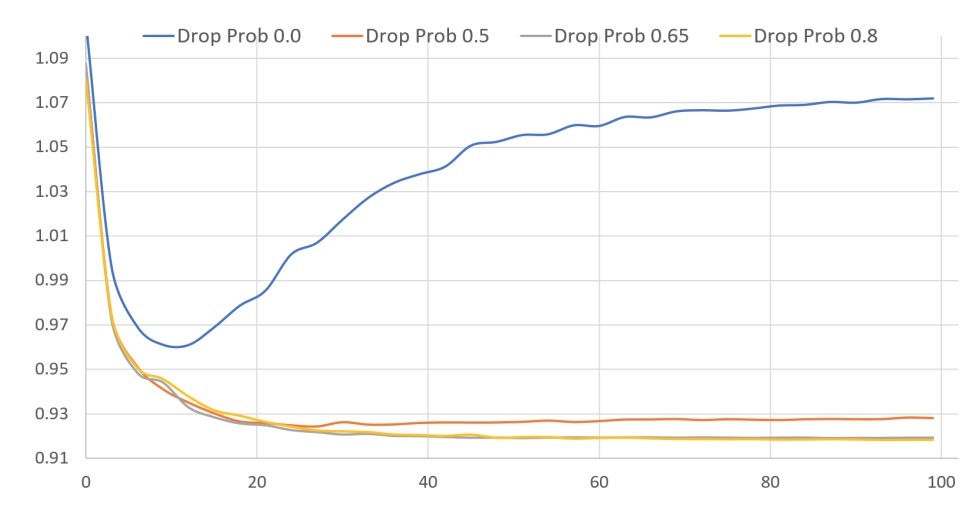
- 对于PNN,使用dropout=0.5
- 每层neurons数目的缺省setting为:
- (1) DNN layers为400
- (2) 对于Criteo dataset,CIN layers为200; 对于DIanping和Bing News datasets,CIN layers=100
- 由于本文主要关注网络结构,所有field embedding的维度统一设为固定值=10.
- 本试验在并行化在5块tesla K80 GPUs上跑.
- 源码为: https://github.com/ Leavingseason/
xDeepFM
效果展示部分:

表3: depth列表示单模型中的最佳深度,分别表示(cross layers, DNN layers)
4.2 Q1: 单一Neural组件间的效果比较
我们想知道CIN单独是如何执行的。注意FM会显式衡量2阶特征交叉,DNN模型可以隐式衡量高阶特征交叉,CrossNet尝试使用较少参数来建模高阶特征交叉,CIN则会显式建模高阶特征交叉。由于它实际依赖于数据集,单一模型(individual model)间的比较优势没有理论保证。例如,如果实际数据集不需要高阶特征交叉,FM可能是最好的单一模型。对于该实验,我们并不期望哪个模型表现最好。
表2展示了单一模型在三个实际数据集上的效果。令人惊讶的是,CIN的表现都要好些。另一方面,结果表明,对于实际数据集,稀疏特征上的高阶交叉是必要的,可以证实:DNN,CrossNet, CIN的效果要远好于FM。另一方面,CIN是最好的单一模型,图中展示了CIN在建模高阶特征交叉上的效果。注意,一个k-layer的CIN可以建模k阶的特征交叉。有趣的是,在Bing News dataset上,它会采用5 layers的CIN来达到最佳结果。

表2: 不同数据集下的模型表现。Depth列表示每个模型最好的网络深度
4.3 Q2: 集成模型的效果
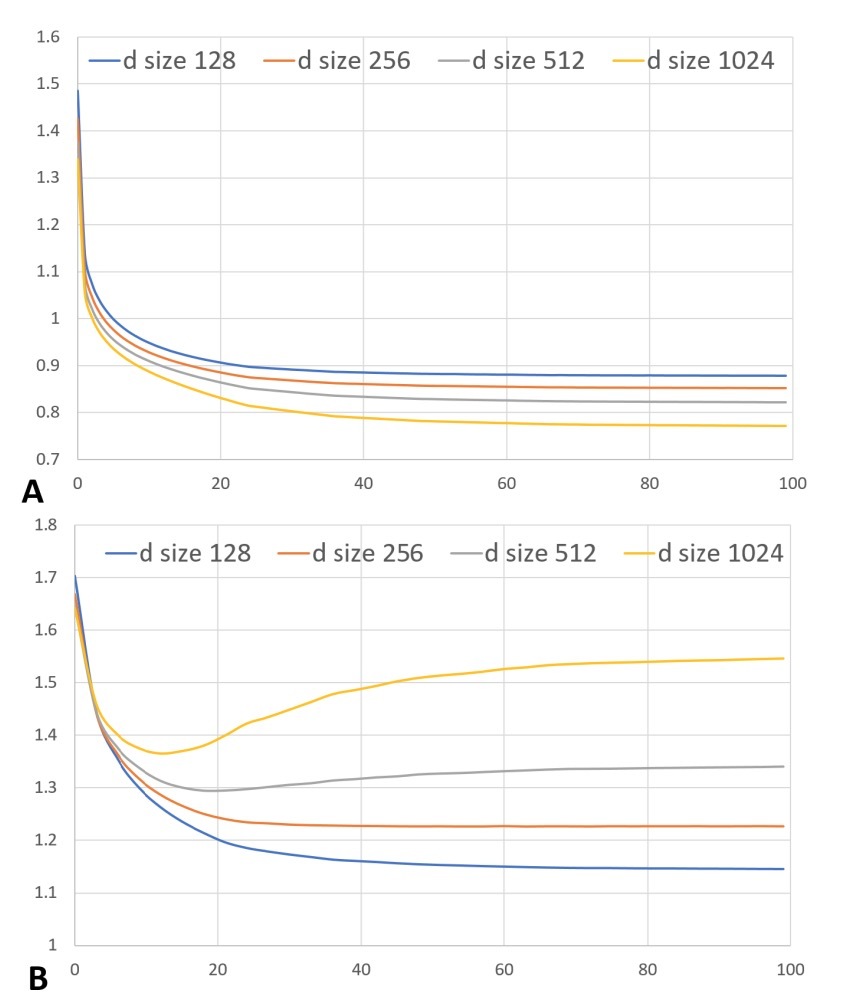
xDeepFM会将CIN和DNN集成一个end-to-end模型。而CIN和DNN能cover在特征交叉学习上两种不同的属性,我们感兴趣的是,是否确实有必要将两者组合在一起进行explicit和implicit的joint learning。这里,我们比较了一些比较强的baselines,如表3所示。另一个有意思的观察是,所有基于neural的模型并不需要非常深的网络结构来达到最佳效果。常见的depth超参数设置为2或3, xDeepFM的最佳深度是3,可以表示最多学习4阶的交叉。
4.4 Q3: 超参数学习
- 1.hidden layers的数目
- 2.每层的neurons数目
- 3.激活函数

参考