Amazon在hogwild、hogbatch之后,提出了《BlazingText: Scaling and Accelerating Word2Vec using Multiple GPUs 》,利用多GPU来加速word2vec的训练。
介绍
Word2vec是流行的算法。原始google c实现、以及facebook fastText可以利用多核cpu架构来并行化。还有一少部分实现方式则利用GPU并行化,但会牺牲accuracy和可扩展性。本paper提出了BlazingText,一个使用CUDA高度优化的word2vec实现,可以利用多GPU进行训练。BlazingText可以在8GPU上达到43M words/sec的训练速度,达到了8线程CPU实现的9倍,并且对embeddings的质量影响很小。
word2vec的最优化通过SGD完成,它会进行迭代式求解;在每一个step,会选取一个词对(pair of words):一个输入词和一个目标词,它们来自于window或一个随机负样本。接着根据选中的两个词来计算目标函数的梯度,然后基于该梯度值更新两个词的词表示(word representations)。该算法接着使用不同的word pair来处理下一次迭代。
SGD的一个主要问题是,它的顺序性;这是因为它在这一轮迭代的更新、与下一轮迭代的计算之间存在着依赖关系(他们可能遇到相同的词表示),每一轮迭代必须潜在等待前一轮迭代的更新完成。这不允许我们使用硬件并行资源。
然而,为了解决上述问题,word2vec使用Hogwild,它使用不同线程来并行处理不同的word pairs,并忽略任何在模型更新阶段中发生的冲突。理论上,对比起顺序运行,这会让算法的收敛率下降。然而,对于跨多线程更新不可能会是相同的词的这种情况,Hogwild方法已经得到验证能运行良好;对于大词汇表size,冲突相对较少发生,收敛通常不受影响。
Hogwild方法在多核架构上的成功,使得该算法利用GPU成为可能,GPU比CPU提供更强的并行化。在该paper中,我们提出了一种有效的并行化技术来使用GPU加速word2vec。
在深度学习框架中使用GPU加速,对于加速word2vec来说并不是好选择[6]。这些框架通常更适合于“深度网络(deep networks)”,它们的计算量主要由像卷积(conv)以及大矩阵乘法(large matrix multiplications)等重型操作主宰。而word2vec则是一个相对浅层的网络(shallow network),每一个training step包含了一个embedding lookup、梯度计算(gradient computation)、以及最终为word pair进行权重更新(weight updates)。梯度计算和更新涉及很小的点乘操作,使用cuDNN[7]或cuBLAS[8]并不能受益。
深度学习框架的限制导致我们探索CUDA C++ API。我们从头设计了训练算法,以便最优利用CUDA多线程能力,并且防止对GPU并行化的过度利用,从而不伤害输出的accuracy。
最终,我们开发了BlazingText,它处理文本语料的速率能达到数百万 words/sec,我们演示了使用多GPU来执行数据并行训练的可能性。我们对比了开源的工具与BlazingText之间的benchmark。
2.word2vec模型
word2vec有两种不同的模型架构:Contextual Bag-Of-Words (CBOW)以及Skip-Gram with Negative Sampling (SGNS) 。CBOW的目标函数是由给定上下文去预测一个词,而Skipgram则给定一个词去预测它的上下文。实际上,Skipgram会给出更好的效果,我们会在下面描述它。
给定一个大型训练语料,它由一个words序列\(w_1, w_2, ..., w_T\)组成。skipgram模型的目标是最大化log似然:
\[\sum_{t=1}^T \sum_{c \in C_t} log p(w_c | w_t)\]其中,T是词汇表size,上下文\(C_t\)是围绕\(w_t\)的词的集合。给定\(w_t\)所观察到的一个上下文词\(w_c\)的概率可以使用上述的词向量进行参数化。假设我们给定一个得分函数s,它将(word, context)的pairs映射到得分\(s \in R\)。定义一个上下文词的概率的一个可能的选择是:
\[p(w_c|w_t) = \frac{exp(s(w_t,w_c))}{\sum_{j=1}^W exp(s(w_t,j))}\]然而,这样的模型不适合我们的case中,因为它意味着,给定一个词\(w_t\),我们只能预测一个上下文词\(w_c\)。
预测上下文词(context words)的问题可以通过构建独立的二分类任务集合来替代。接着,该目标是独立地预测上下文词是否出现。对于在位置t处的词,我们会考虑所有的上下文词作为正例,并从字典中随机抽样负样本。对于一个选中的上下文位置c,使用binary logistic loss,我们可以获取以下的negative log-likelihood:
\[log(1 + e^{-s(w_t,w_c)}) + \sum_{n \in N_{t,c}} log(1 + e^{s(w_t,n)})\]其中\(N_{t,c}\)是从词汇表中抽取的负样本的一个集合。通过表示logistic loss function l:\(x \rightarrow log(1+e^{-x})\),我们可以重写目标函数:
\[\sum_{t=1}^T \sum_{c \in C_t} [l(s(w_t,w_c)) + \sum_{n \in N_{t,c}} l(-s(w_t,n))]\]对于在词\(w_t\)和它的一个上下文词\(w_c\)之间的scoring function s的一个天然参数化方案是,使用词向量(word vectors)。假设在词汇表中的每个词w,定义两个向量\(u_w in R^D\)和\(v_w \in R^D\)。这两个向量有时被称为是输入向量(input vector)和输出向量(output vector)。特别的,我们的向量\(u_{w_t}\)和\(u_{w_c}\)分别对应于词\(w_t\)和\(w_c\)。接着,score可以使用在该词与上下文向量间的点乘(dot product)来表示:\(s(w_t,w_c) = u_{w_t}^T v_{w_c}\)。
3.相关工作
一些已经存在的word2vec系统被限制在只能在单机CPU上运行,而一些使用多核cpu多节点来加速word2vec的方式则进行分布式数据并行训练。这些方法包含了Spark MLLib和Deeplearning4j。这些系统在每轮iteration后依赖reduce操作在所有executors间同步模型。将所有的word vectors跨节点广播(broadcast)的这种方式限制了可扩展性,因为通常网络带宽只比CPU内存要低一阶。另外,模型的accuracy会大幅下降,因为使用了更多节点来增加吞吐。
Intel的工作[11]展示了通过基于minibatching和shared negative samples的scheme可在多CPU节点上进行极强地扩展。该方法将level-1 BLAS操作转换成level-3 BLAS矩阵乘法操作,从而有效地利用现代架构的向量乘法/加法指令(vectorized multiply-add instructions)。然而,该方法仍不能利用GPUs,而且他们的实现只能在Intel BDW和KNL处理器上扩展良好,而这些处理器比GPU要昂贵,不会被主流的云服务平台所提供。借鉴他们提出的思想,我们可以通过一个minibatch共享negative samples,并使用高度优化的cuBLAS level-3矩阵乘法核(matrix multiplication kernels),但由于要进行乘法操作的矩阵size很小,CUDA核启动(kernel-launches)的开销会剧烈降低性能和可扩展性。
其它一些工作[12,13]已经利用像tensorflow, keras, theano等深度学习库,但展示出的性能要比fasttext的CPU实现要慢。由于word2vec的一轮迭代计算并不非常密集,需要使用一个很大的batch size来完全利用GPU。然而,对训练数据进行mini-batching会急剧降低收敛率,而如果batch size=1, 训练又会非常慢。
4. 使用CUDA进行GPU并行化
由于GPU架构比CPU cores提供了更强的(多好多阶)并行机制,word2vec看起来能很好地使用GPU进行加速,算法本身展示了可以通过异步SGD(asynchronous SGD)或Hogwild进行很好的并行化。然而,如果使用更多的并行化,不同线程之间在读取和更新词向量时可能会发生冲突,从而对accuracy产生大幅下降。因而,必须仔细考虑,如何在并行化级别上和同步机制间做好权衡。
深度学习框架没有像CUDA C++ API那样,提供在GPU的可扩展性与并行化之间的细粒度控制。有必要对算法设计进行大幅重构,从而允许最大化并行吞吐,而强制同步会阻止accuracy的降低。我们控制了以下两种方法来基于CUDA实现。
4.1 每个词一个线程块(one thread block per word)
原始的word2vec实现按顺序处理一个句子,例如:对于中心词\(w_t\),它会考虑围绕中心词作为目标词的window size(ws)中的所有词,这意味着在\([w_{t-ws}, w_{t+ws}]\)所有的词向量,会在一个step中获得更新。相似的在下一step中,对于中心词\(w_t + 1\),在范围\([w_{t-ws+1}, w_{t+ws+1}]\)内的所有向量都将被更新。这意味着,当处理一个句子时,一个词向量可以被修改2ws+1次,理想的,每个连续的step都应使用被前一step修改更新后的向量(updated vectors)。
从头设计一个CUDA程序需要我们对网格结构(grid)和线程块(thread blocks)做总体规划。在相同线程块中的线程可以相互进行同步,但如果属于不同线程块的线程不能相互通信,使得线程块相互独立。在该方法中,我们选择为每个词分配一个线程块,在一个块内的线程数可以是乘以32, 相当有效。随着在一个块内的线程数与向量维度(通常100)越来越接近,每个线程会映射到一个向量维度上,并做element-wise乘法操作。这种单独的乘法接着使用一个reduce kernel来计算任意2个给定向量间的点乘来进行有效求和。我们探索了一些并行reduction技术,最终使用采用一个高度优化过的completely unrolled reduce kernel。该算法设计采用并行机制能达到峰值,因为每个词会通过一个线程块进行独立处理,在线程块中的线程只有当执行reduce操作时会进行同步(synchronize)。然而,该方法会有一个主要缺点,它能极大地破坏embeddings的质量。不同的线程块可以独立的修改词向量,没有同步机制,它对于accuracy是有害的,因为随着窗口沿着句子进行滑动,每个向量可以更新2w+1次。这会产生大量线程覆盖写(overwrites)和非最新读取(stale reads)。
4.2 每个句子一个线程块
在之前章节讨论过,没有任何同步机制的词向量更新,可以充分利用CUDA并行机制,但是会由于竞争条件(race conditions),会降低embeddings的accurary。随着窗口沿着句子滑动,当处理后一个词时,应使用前面已经更新(updated)的词向量。因而,为了解决顺序依赖(sequential dependency),与前面的方法类似,该方法会将每个句子映射到一个CUDA线程块上,它会将该向量的每一维映射到一个线程上。因此,不同线程块相互并行处理句子,而在一个句子中,线程块会根据词进行循环来顺序更新向量。该方法仍会导致一些竞争条件(race conditions),但由于不同句子通常不会有许多词相同,它实际上不会造成收敛问题。
由于文本语料对于驻在GPU内存中来说可能很大,数据从磁盘到GPU中会流式化(streamed),并且许多句子会进行batch化,以分摊数据在CPU和GPU间传输的开销。为了评估accuracy和throughput间进行平衡,线程块、或者句子被并行处理的最优化数目,通过经验选择。并发处理越多勉励子,会增加throughput,但会产生accuracy的降低,因为不同线程块更新相同的词向量的机率会增加。
一些其它的最优化(optimizations),可以使该方法更有效。如果kernel的执行时间比数据传输时间要少,那么GPU会空闲等待下一batch的句子。为了避免这种情况,我们尝试通过使用多CPU线程和CUDA streams,将数据传输和在GPU上进行kernel execution的过程进行重叠(overlap),它允许数据传输到GPU时仍在忙着运行kernels,这样GPU时间不会空闲。我们使用多CPU线程来从磁盘读取数据,并准备下一batch的句子,它可以使用多个CUDA streams来并发传输数据给GPU。
我们将在第5节描述上述方法的实验。
4.3 在多GPU上的分布式训练
在多GPU分布式系统上扩展BlazingText是很关键的,因为在单GPU上训练一些工业界特别大的数据集时(数T),它仍可能花费数天时间。为了扩展BlazingText,我们探索了不同的分布式训练范式——模型并行化(model parallelism) 和 数据并行化(data parallelism)。由于向量维度通常很小,点乘的规模也不会很大,因而将向量的不同维量进行分布式,不会带来很多的性能增益。因而,我们使用数据并行化,当使用N个GPU时,我们将数据集等分为N份相等的shards。对于词汇表中的所有词,输入向量和输出向量的模型参数,会被复制到每个GPU上;每个设备接着独立处理它所拥有的数据分区,并更新它的局部模型(local model),然后与其它N-1个GPU周期性同步局部模型(local model)。
数据并行化要解决的主要问题是,如何在GPU间有效进行模型同步。它可以使用NVIDIA的NCCL库[15]来有效解决,该库提供了AllReduce方法,它可以基于GPU网络拓朴以一种最优的方法,来处理在GPU间的peer-to-peer数据传输。如果GPU没有通过相同的PCIe swith或者相同的IOH chip进行连接,那么数据会通过host CPU进行传输。由于模型参数的size可能是数百MB,同步机制可能开销很大,因而决定合理的同步间隔十分重要。频繁的同步将产生更好的收敛,但会减慢训练,反之亦然。出于简洁性,我们选择在每轮迭代后进行同步,并在后续会继续探索更有效的同步机制。
5.实验
我们使用上述提到的方法,为单GPU和多GPU系统进行最优化BlazingText。在本节中,我们会展示throughput(单位:百万 words/sec)和所学到的embeddings的accuracy(在标准word similarity和word analogy test上)。我们会对BlazingText和FastText CPU(没有subword embeddings的版本)实现进行benchmark。
硬件:所有的实验都在AWS p2.8xlarge GPU实例上运行,它具有8个NVIDIA K80 GPU卡,以及Intel Xeon CPU E5-2684 v4@2.3GHz 16核(32线程)。
软件:BlazingText使用C++编写,使用CUDA compiler:NVCC v8.0编译。
训练语料:我们使用两个不同语料进行训练:(1) 来自Wikipedia的包含1700w个词的Text8数据集[16],(2) 一个十亿词的benchmark dataset[17]。
测试集:学到的embedding会在word similarity和word analogy任务上进行评估。对于word similarity,我们使用WS-353[18],它是最流行的测试数据集。它包含了人工审核过的相似word pairs。词表示的评估通过根据cosine相似度对这些pairs进行排序,并使用Spearman’s rank相关系数进行评估。我们使用google analogy dataset来进行word analogy评估。
超参数:对于所有的实验,我们展示了使用CBOW和Skipgram算法(negative sampling)和FastText的缺省参数设置(dim=100,window size=5, sampling threold=1e-4, inital learning rate=0.05)。我们为Text8数据集使用20个epochs,One Billion Words Benchmark则使用10个epochs。
5.1 Throughput
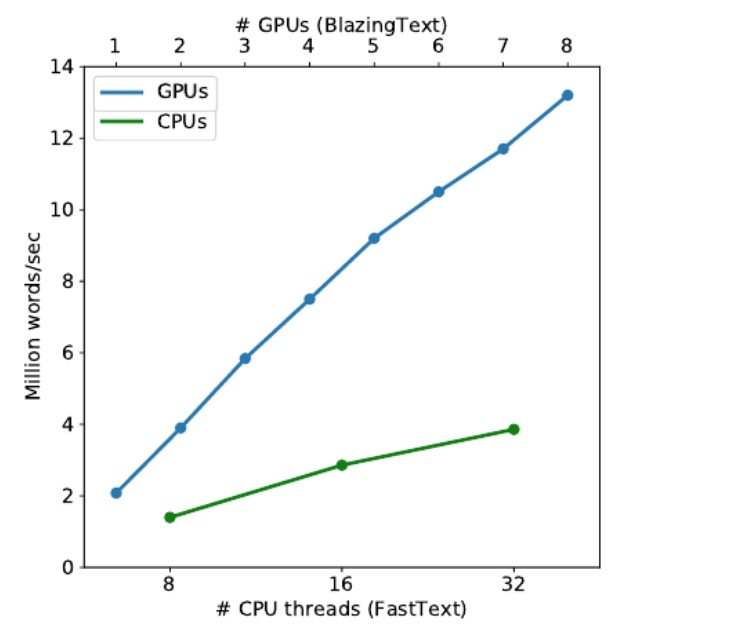
图1
图1和图2展示了BlazingText on GPU和FastText on CPU的throughput以百万 words/sec测量。分别跨多GPU和多CPU运行,分别跑SKipgram和CBOW。当扩展到多GPU时,我们的实现达到了接近线性的加速。使用8个GPU,Skipgram可以达到1.32 亿 words/sec,而CBOW可以达到4.25 亿 words/sec,它比32线程的FastText要快3倍。如表1所示,跨多GPU扩展在accuracy上影响很小,因为我们的实现可以有效利用多GPU架构。随着在throughput和accuracy间进行平衡,我们进一步通过降低同步频率来增加throughput,只要accuracy的下降是可接受的。
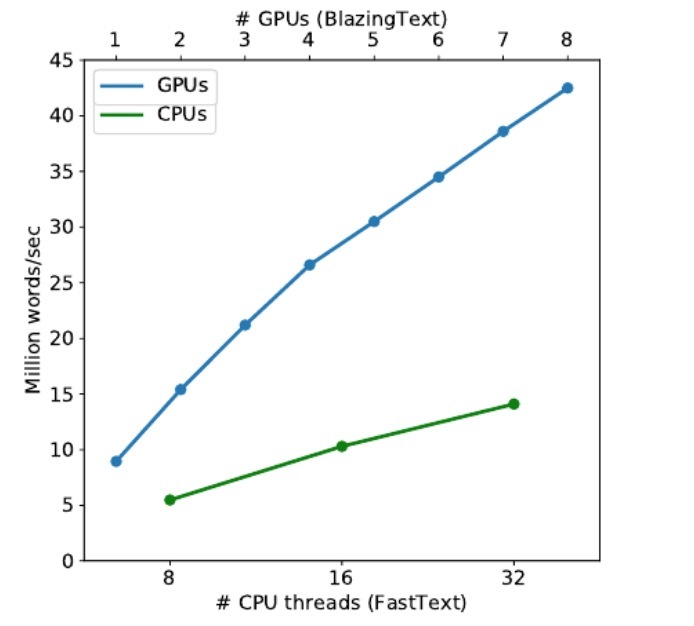
图2
5.2 Accuracy
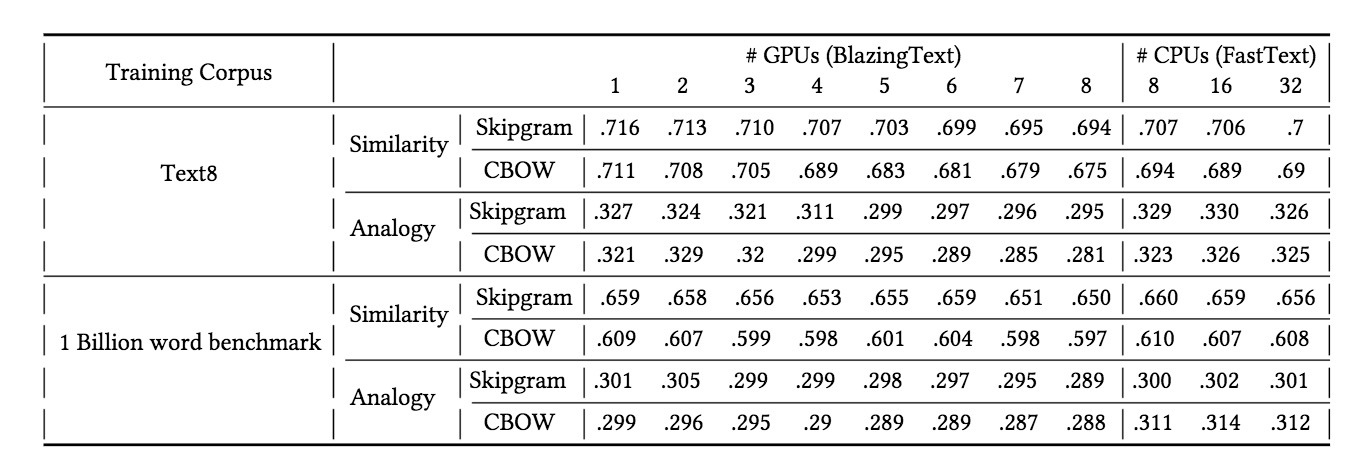
表1
我们评估了从fasttext实现以及我们的实现(随GPU数目不同)中训练得到的该模型,并在表1中展示了他们在word similarity和word analogy任务上的预测效果。为了确保我们的实现可以很好泛化,我们会使用2个不同的语料来训练模型——text8和1B words benchmark。
由于GPU并行化,为了消除随机性,我们运行每个实验多次(n=10),并展示了平均结果。如表1所示,BlazingText展示了在多GPU上的效果与FastText CPU上的效果相近。当使用4GPU时,性能几乎相同,在一些情况下比CPU版本要好。如你所料,预测的效果会随着使用更多GPU而减少,但在可接受范围内。对于相似度评估,使用8 GPUs会达到2%更差的accurary,但会比32 CPU线程超过3倍加速。
对于analogy评估,在多GPU和CPU上的不同更显著。在我们的实验中,我们主要关注可扩展性,因而当扩展到更多GPU时,我们不会增加同步频率。增量同步频率可以维持一个可接受的accuracy,但会在扩展性上可降,导致一个sub-linear scaling。然而,取决于终端应用,可以调整同步频率。