阿里在2019又发布了一篇关于tdm(新的称为JTM)的paper:《Joint Optimization of Tree-based Index and Deep Model for Recommender Systems》, 我们来看下:
介绍
为了打破内积形式的限制,并使得任意的关于用户偏好的高级模型对于从整个语料中检索候选的方式在计算上变得可行,之前提出的TDM使用树结构作为index,可以极大提升推荐的accuracy。TDM使用一个树结构来组织items,树中的每个leaf node对应于一个item。TDM假设:每个user-node偏好是指在所有子节点的偏好中具有最大值的节点,就如同一个max-heap一样。在训练阶段,每个user-node偏好的预测模型用于拟合这种类max-heap的偏好分布。与vector kNN-based搜索(index结构需要内积形式)不同的是,在TDM中对偏好建模的形式没有任何限制。在预测时,由训练模型给出的偏好得分,会被用于在tree index中执行layer-wise beam search来检索候选items。在树索引中的beam search的复杂度是log(corpus size),在模型结构上没有限制,这使得高级用户偏好模型在推荐中检索候选变得可行。
index结构在kNN-based搜索、tree-based方法中扮演着不同的角色。在kNN搜索中,user和item的向量表示会首先通过学习得到,接着建立vector search index。而在tree-based方法中,tree-index的结构(hierarchy)也会影响检索模型的训练。因此,如果对tree index和用户偏好模型进行联合训练是一个重要的问题。tree-based方法在学术上也是一个活跃的话题。在已经存在的tree-based方法中,会学到tree结构,以便在在样本/标签空间(sample/label space)中得到一个更好的结构(hierarchy)。然而,在tree-learning阶段,sample/label划分任务的目标与最终目标(比如:精准推荐)并不完全一致。index learning与prediction模型训练间的不一致,会导致整个系统达到一个次优的状态。为了解决该挑战,更好地将tree index和用户偏好预测相协调,我们的工作聚焦于:通过对一个统一的偏好measure进行最优化,来开发一种同时学习树层级结构(tree hierearchy)和用户偏好预测模型。该paper的主要贡献可以归纳为:
- 我们提出了一种joint optimization框架,为tree-based推荐学习树结构和用户偏好预测模型,其中,会对一个统一的performance measure(比如:用户偏好的accuracy)进行最优化
- 我们演示了提出的树结构学习算法,它等同于二分图(bipartite graph)的最大权匹配(max weighted matching)问题,并给出了一个近似算法来学习树结构
- 我们提出了一种新方法,它可以更好利用tree index来生成层次化用户偏好(hierarchical user representation),它可以帮助学到更精准的用户偏好预测模型。
- 我们展示了树结构学习和层次化用户表示两者可以同时提升推荐accuracy。这两个模块可以相互提升,来达到更大的效果提升。
本paper的其余部分如下方式组织:
- 在第2节,我们会比较一些大规模推荐方法来展示不同
- 在第3节,我们首先给出一个TDM之前工作的简短介绍,接着详细描述joint learning
- 在第4节,离线对比和在线A/B test实验结果对比
- 在第5节,结论
2.相关工作
- Youtube DNN
- Yahoo news RNN
- Label Partitioning for Sublinear Ranking (LPSR)
- Partitioned Label Trees (Parabel)
- Multi-label Random Forest (MLRF)
- FastXML
3.joint optimization
在本节中,我们首先给出了一个TDM的简单回顾。TDM使用一个tree hierarchy作为index,并允许高级深度模型作为用户偏好预测模型。接着,我们提出了关于tree-based index和deep模型的joint learning框架。它会选择性在一个全局loss function下最优化index和预测模型。提出了一个greedy-based tree learning算法来最优化index。在最后一个子节,我们会指定用于模型训练中的层次化用户偏好表示。
3.1 tree-based深度推荐模型
推荐系统需要返回给用户感兴趣的一个items候选集合。实际上,如何从一个大的item库中有效做出检索是个大挑战。TDM使用一棵树作为index,并提出了在该tree上的一个类max-heap的概率公式,其中对于每个非叶子节点n在level l上的用户偏好为:
\[p^{(l)}(n | u) = \frac{ \underset{n_c \in \lbrace n's \ children \ in \ level \ l+1 \rbrace}{max} {p^{(l+1)}(n_c | u)} }{\alpha^{(l)}}\]…(1)
其中:
- \(p^{(l)}(n \mid u)\)是用户u喜欢节点n的ground truth概率。
- \(\alpha^{(l)}\)是一个layer归一化项
上述公式意味着:在一个节点上的ground truth的user-node概率,等于它的子节点的最大user-node概率除以一个归一化项。因此,在level l上的top-k节点,必须被包含在在level(l-1)的top-k节点的子节点中,在不损失accuracy的前提下,top-k的leaf items的检索必须被限制在每个layer的top-k节点上。基于这一点,TDM将推荐任务转换成一个层次化检索问题(hierarchical retrieval problem)。通过一个自顶向下的过程,候选items可以从粗到细被逐渐选中。TDM的候选生成过程如图1所示。
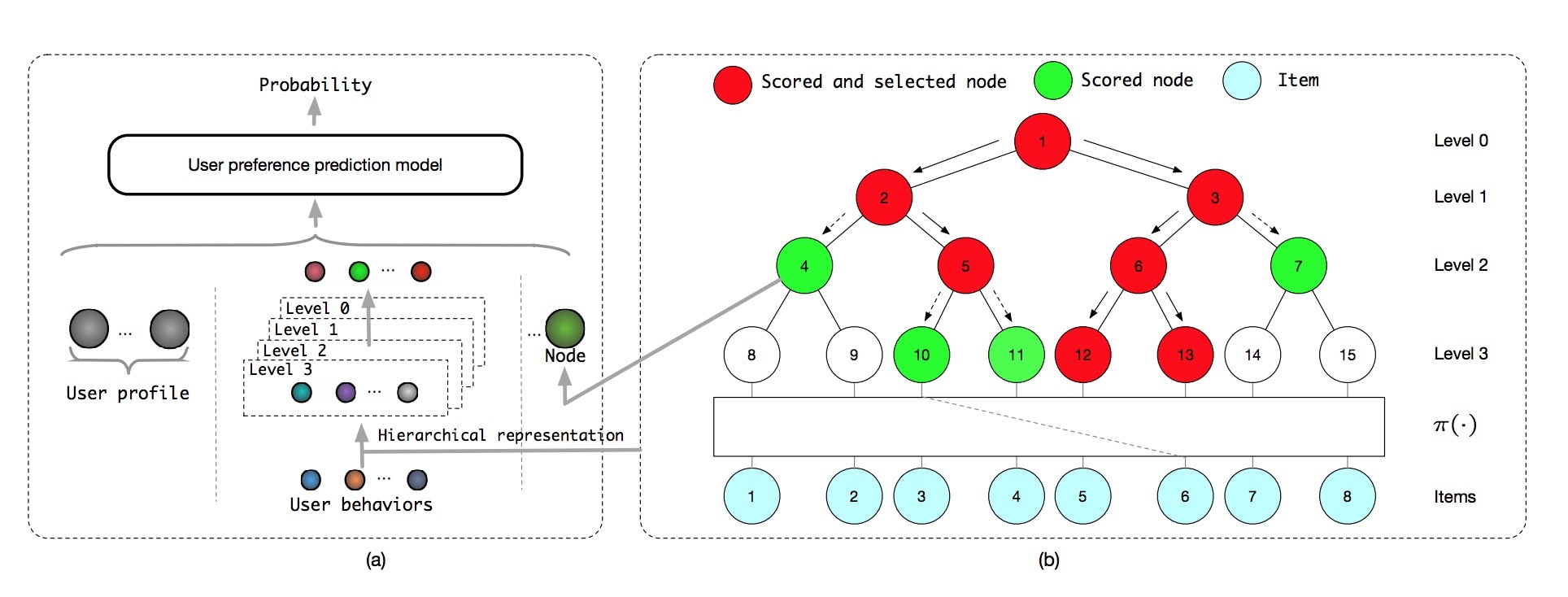
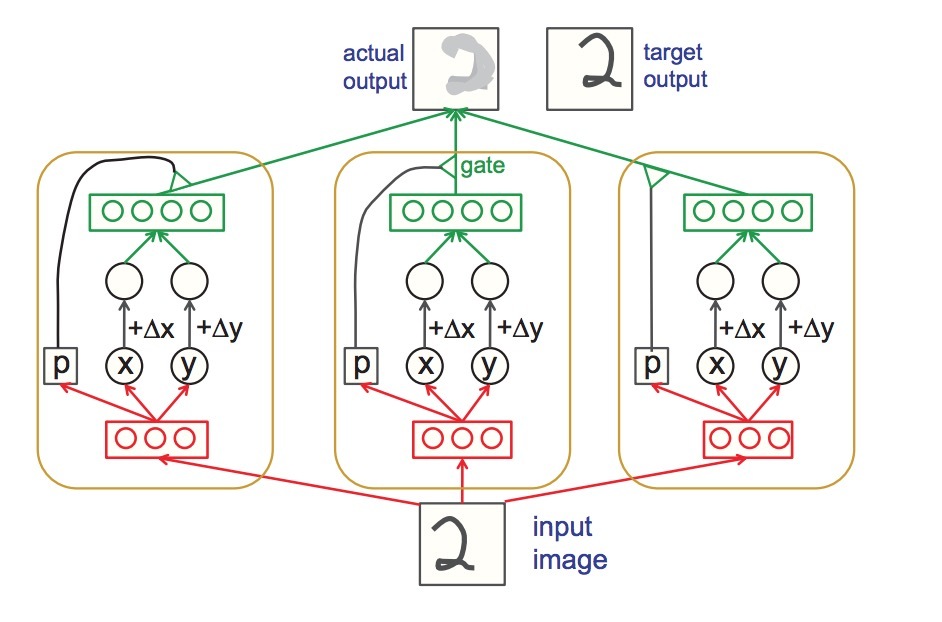
图1: Tree-based deep推荐模型 (a) 用户偏好预测模型。我们首先以层次化的方式在对应的layers上的节点上对用户行为进行抽象。接着,用户行为抽象和目标节点(target node)、以及与其它特征(比如:user profile)一起被用于模型的输入。 (b) 树结构(tree hierarchy)。每个item首先会通过一个投影函数\(\pi(\cdot)\)分配到一个不同的leaf node上。在leaf level上的红色节点(items)会被选中作为候选集
在corpus中的每个item被分配到树层次结构(tree hierarchy)上的一个\(\tau\)的leaf node上。non-leaf nodes可以被看成是一个关于子节点的更粗粒度的抽象。在检索时,为了进行打分,用户信息与节点组合在一起,首先会被向量化成一个用户偏好表示,作为深度神经网络M(例如:FC networks)的输入。接着,用户对该节点感兴趣的概率值通过模型M返回,如图1(a)所示。而对于检索top-k个items(leaf nodes)来说,会以level-by-level的方式执行一个自顶向下的(top-down)beam search策略,如图1(b)所示。在level l中,只有在level l-1上带有top-k概率的子节点被打分和排序来选择k个候选节点。该过程会一直持续,直到达到k个leaf items。
有了tree index,一个用户请求的整体检索复杂度,会从线性降到log(corpus size),而对于偏好模型结构没有任何限制。这使得TDM会打破用户偏好建模的内积形式的限制(它通过引入vector kNN search index和特有的高级深度模型来检索整个corpus的候选),这可以极大提升推荐的accuracy。
3.2 Joint Optimization框架
根据检索过程,TDM的推荐accuracy会通过用户偏好模型M和tree index T的质量(quality)来决定。给定n个关于正例训练数据\((u_i, c_i)\) pairs(它表示user \(u_i\)对target item \(c_i\)感兴趣),\(T\)决定着模型M会为用户\(u_i\)选择哪些non-leaf nodes来达到\(c_i\)。为了替换之前单独学习M和T的方式,我们提出了一个全局loss函数来对M和T进行jointly learn。正如我们在实验中所见,对M和T进行jointly optimizing可以提升最终的推荐accuracy。
\(p(\pi(c_i) \mid u_i; \pi)\)表示:给定一个user-item pair \((u_i,c_i)\),用户u在leaf node \(\pi(c_i)\)上的偏好概率。其中:\(\pi(\cdot)\)是一个投影函数,它将一个item投影到在T上的一个leaf node上。注意,投影函数\(\pi(\cdot)\)实际决定着在树中的item的层次结构,如图1(b)所示。模型M被用于估计和输出user-node偏好\(\hat{p}(\pi(c_i) \mid u_i; \theta, \pi)\),其中\(\theta\)为模型参数。如果pair \((u_i, c_i)\)是一个正样本,根据多分类设置,我们具有ground truth偏好 \(p(\pi(c_i) \mid u_i; \pi) = 1\)。
根据max-heap特性,所有\(\pi(c_i)\)的祖先节点(ancestor nodes)的用户偏好概率(注:每一层都有,构成一条路径),例如 \(\lbrace p(b_j(\pi(c_i)) \mid u_i; \pi)\rbrace_{j=0}^{l_{max}}\)应该为1,在其中\(b_j(\cdot)\)是在level j上从一个节点到它的祖先节点(ancestor node)投影,\(l_{max}\)是在T上的最大level。为了拟合这样一个user-node偏好分布,全局loss函数被公式化成:
\[L(\theta, \pi) = - \sum_{i=1}^n \sum_{j=0}^{l_{max}} log \hat{p} (b_j(\pi(c_i)) | u_i; \theta, \pi)\]…(2)
其中:n为训练样本正例数,我们将在所有正训练样本上对预测的user-node偏好的负log概率进行求和,它们的祖先user-node pairs作为global empirical loss。

算法1
由于对投影函数\(\pi(\cdot)\)最优化是一个组合优化问题(combinational optimization),它几乎不可能使用基于梯度的算法来同时优化\(\theta\)。为了解决它,我们提出了如算法1所示的joint learning framework。它可以根据用户偏好模型和tree hierarchy交替(alternativel)对loss function (2)进行最优化。在模型训练和树学习中,training loss的一致性,可以促进框架的收敛。实际上,如果模型训练和树学习两者可以同时减小(2)的值,算法1确实会收敛,因为\(\lbrace L(\theta_t, \pi_t)\rbrace\)是一个递减序列,最低界为0。在模型训练中,\(min_{\theta} L(\theta, \pi)\)是为了为每一layer学习一个user-node偏好模型。受益于tree hierarchy,\(min_{\theta} L(\theta, \pi)\)被转换成学习user-node偏好分布,因此可以使用任意的高级深度模型,它们可以通过流行的最优化算法:SGD、Adam等求解。在归一化用户偏好设定中,由于节点数会随着node level指数增加,使用NCE估计\(\hat{p}(b_j(\pi(c_i)) \mid u_i; \theta, \pi)\),通过sampling策略来避免计算归一化项。树学习的任务是为了在给定\(\theta\)时求解\(min_{\pi} L(\theta, \pi)\),它是一个组合优化问题。实际上,给定树结构,\(min_{\pi} L(\theta, \pi)\)等于发现在corpus C中items与T中的leaf nodes间的最优匹配。更进一步,我们有:
推论1: \(min_{\pi} L(\theta, \pi)\)本质上是一个分配问题(assignment problem):在一个加权二分图中发现一个最大权值匹配。
证明:假如第k项item \(c_k\)被分配到第m个leaf node \(n_m\),即:\(\pi(c_k) = n_m\),以下的加权值可以被计算:
\[L_{c_k,n_m} = \sum\limits_{(u,c) \in A_k} \sum_{j=0}^{l_{max}} log \hat{p} (b_j (\pi(c)) \mid u; \theta, \pi)\]…(3)
其中:
- \(A_k\)包含了所有正样本抽样对(u,c)
- \(c_k\)是target item c
如果我们将在T中的leaf nodes和在corpus C中的items看成是顶点(vertices),将leaf nodes和items间的完全连接(full connection)看成是边(edges),我们可以构建一个加权二分图V,\(L_{c_k,n_m}\)是在\(c_k\)和\(n_m\)间边的权重。更进一步,我们可以学到,每个在items和leaf nodes间的assignment \(\pi(\cdot)\),等于一个关于二分图V的matching。给定一个assignment \(\pi(\cdot)\),total loss(2)可以通过下式计算:
\[L(\theta, \pi) = -\sum_{i=1}^{|C|} L_{c_i, \pi(c_i)}\]其中\(\mid C \mid\)是corpus size。因此,\(min_{\pi} L(\theta, \pi)\)等于寻找V的最大权匹配(maximum weighted matching)。
对于分配问题,传统算法(比如:经典的匈牙利算法)很难应用于大语料上,因为它们具有很高复杂度。即使对于最简单的贪婪算法,它们会使用最大权\(L_{c_k,n_m}\)矩阵来贪婪地选择未分配对\((c_k,n_m)\),该矩阵是一个大的权重矩阵,需要事先计算和存储,这是不可接受的。为了克服该问题,我们提出了一个segmented tree learning算法。
我们不会将items直接分配给leaf nodes,作为替代,我们会自顶向下每隔d个levels会分配items。给定投影函数\(\pi(\cdot)\),我们将从level s到level d的\(L_{c_k, \pi(c_k)}\)的partial weight,表示为:
\[L_{c_k, \pi(c_k)}^{s,d} = \sum\limits_{(u,c) \in A_k} \sum_{j=s}^d log \hat{p}(b_j(\pi(c_k)) | u; \theta, \pi)\]我们首先会根据投影函数\(\pi(\cdot)\)来发现一个分配(assignment)来最大化\(\sum\limits_{i=1}^{\mid C \mid} L_{c_i, \pi(c_i)}^{1,d}\),该投影函数等价于分配所有items到level d的节点上。对于一个具有最大level=\(l_{max}\)的完全二叉树T(complete binary tree),每个level d上的节点,会分配不超过\(2^{l_{max}-d}\)的items。这是一个最大匹配问题(maximum matching problem),可以使用贪婪算法进行有效求解,因为如果d选得够好,对于每个item可能位置的数目会极大减小(比如:d=7时, 该数目为\(2^d=128\))。接着,每个item c对应在level d(\(b_d(\pi(c)))\))上的祖先节点保持不变,我们接着相继最大化next d levels,递归直到每个item被分配到一个叶子节点后停止。提出的算法在算法2中详细介绍。

算法2
算法2中的第5行,我们使用一个greedy算法,它使用再平衡策略(rebalance strategy)来求解这个子问题(sub-problem)。每个item \(c \in C_{_i}\)会首先将最大权重\(L_c^{l-d+1,l}\)被分配给在level l中的\(n_i\)子节点。接着,为了保证每个子节点的分配不超过\(2^{l_{max}-l}\)个items,会使用一个rebalance过程。为了提升tree learning的稳定性,以及促进整个框架的收敛,对于那些具有超过\(2^{l_{max}-l}\)items的节点,我们优先将在level l中具有相同的assignment的这些节点,保持使用前一轮迭代(比如:\(b_l(\pi'(c))==b_l(\pi_{old}(c)))\))。被分配给该节点的其它items会以权重\(L_{\cdot,n}^{(l-d+1,l)}\)的降序进行排序,items的超出部分,会根据每个item权重\(L_{c,\cdot}^{(l-d+1,l)}\)的降序,被移到仍有富余空间的其它节点上。算法2会帮助我们避免存储单个大的权重矩阵。另外,每个子任务可以并行运行,进一步提升效率。
3.3 层次化用户偏好表示
如3.1节所示,TDM是一个层次化检索模型,用来从粗到细的方式层次化地生成候选items。在检索时,会通过用户偏好预测模型M贯穿tree index执行一个自顶向下的(top-down)beam search。因此,在每个level中的M任务是异构的(heterogeneous)。基于此,一个关于M的特定层输入(layer-specific input),必须提升推荐的accuracy。
一系列相关工作表明【9,19,22,35,37-39】,用户的历史行为在预测用户兴趣时扮演着重要角色。另外,由于在用户行为中的每个item是一个one-hot ID特征,在deep model输入的生成上,常见的方法是首先将每个item嵌入到一个连续的特征空间上。一个non-leaf node是一个在tree hierarchy中它的子节点的一个抽象。给定一个用户行为序列\(c=\lbrace c_1, c_2, ..., c_m \rbrace\),其中\(c_i\)是用户交互的第i个item,我们提出使用\(c^l = \lbrace b_l(\pi(c_1)), b_l(\pi(c_2)), \cdots, b_l(\pi(c_m)) \rbrace\)与target node、以及其它可能特征(比如:user profile)一起来生成M在layer l的input,来预测user-node偏好,如图1(a)所示。在这种方式中,用户交互的items的祖先节点被当成抽象的用户行为使用。训练M时,在对应的layer上,我们使用该抽象来替换原始的user-behavior序列。总之,层次化用户偏好表示带给我们两个优点:
- 层的独立性(layer independence):对于不同layers来说,在layers间共享item embeddings,会像用户偏好的预测模型那样,在训练M时会带来在一些噪声(noises),因为对于不同layers来说targets是不同的。解决该问题的一个显式方法是,对于每一layer,将一个item与一个独立的embedding相绑定来生成M的输入。然而,这会极大增加参数的数目,使得系统很难优化和应用。我们提出的抽象用户行为会使用相应layer上的node embeddings来生成M的input,在训练时达到layer independence,无需增加参数的数目。
- 精准描述(Precise description):M会以层次化方式贯穿tree index来生成候选items。随着所检索的level的增加,在每一level上的候选节点会以从粗到细的方式描述最终的推荐items,直到达到leaf level。提出的层次化用户偏好表示(hierarchical user representations)会抓住检索过程的本质,并在相应layer的nodes上给出一个关于用户行为的精准描述,这可以提升用户偏好的预测,通过减少因太过详细或太过粗粒度描述而引入的混淆(confusion)。例如,在upper layers中M的任务是粗粒度选择一个候选集,用户行为也会在训练和预测时在相同的upper layers上使用均匀的node embeddings进行粗粒度描述。