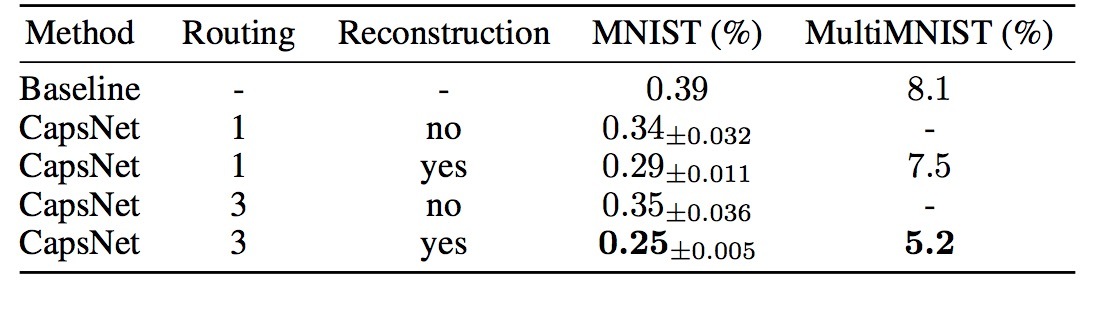
faiss中有IVF的概念。其实就是inverted file (IVF)。它在2003的《Video Google: A Text Retrieval Approach to Object Matching in Videos》中提出。我们来看下,该paper有两段提及,我们来看下:
一、
文本检索系统通常需要采用一些标准steps。文档首先被解析成words。接着,words通过它们的stems来表示,例如:“walk”、”walking”、”walks”会使用stem ‘walk’来表示。第三,会使用stop list来拒绝常用words,比如:”the”、”an”,它们很常见。剩余words接着会被分配一个唯一的id,每个document会通过一个vector来表示,该vector的components由该文档中所包含的words的词频组成。除了components会以多种方式加权外,在google的case中,一个web page的weighting取决于web pages链接到特定页的数目。上述所有steps都在实际检索前完成,在语料中的所有文档会表示成vectors集合,通过一个inverted file进行组织来更高效的检索。一个inverted file的结构类似于一个理想的book index。在corpus中每个word都有一个entry,它会跟一个该word出现的所有文档(以及在该文档中的位置)的list。
一个text会通过计算词频向量进行检索,并返回最近向量(通过角度)的文档。
二、目标检索(object retrieval)
实现-使用inverted files:在一个经典的文件结构中,所有words会存储在它们出现的文档中。一个inverted file结构,会为每个word生成一个entry(hit list),并存储在所有文档中该word的出现次数。在我们的case中,inverted file会为每个可视化的word生成一个entry,它会存储所有matches,例如:在所有帧中相同word的出现次数。document vector是非常稀疏的,使用一个inverted file可以使得检索非常快。在2GHz的pentium上使用matlab实现,查询一个4k frames的database只需要0.1秒。
三、faiss IVF
上面提到的都是IR中的inverted file。关于faiss IVF,Chris McCormick在它的blog中有提到,我们可以看下:
Inverted File Index(IVF) 是pre-filtering技术,以便你无需对所有vectors做exhaustive search。实现相当简单:首先,你使用聚类(比如:kmeans)将数据集聚类生成较大数目(比如:100个)的数据分区(partitions)。接着,在query时,你会将你的query vector与partition centroids进行对比,(例如:找到10个最近的聚类),接着你只在这些分区上对vectors进行搜索。
在IR中,”inverted index”指的是文本搜索索引,它会将词汇表中的每个词映射到数据文档中的所有位置。看起来有点像textbook的索引,将words映射到page numbers,因而称为inverted index。
然而,在我们的上下文中,该技术的意思是,使用k-means聚类将数据集进行划分,以便你可以重定义你的搜索(只需搜索部分分区,忽略其它)。
在构建index时,使用聚类将数据集聚到多个partitions上。在dataset中的每个vector会属于这些clusters/partitions的其中之一。对于每个partition,你都具有一个属于它的所有vectors的list(被称为:inverted file lists)。你具有关于所有这些partition centroids的一个matrix,它会被用于找出哪些partitions会进行search。
按这种方式划分数据集并不完美,因为如果一个query vector落到离它最近cluster的外面,那么它的最近邻很可能停留在多个附近的cluster上。解决该问题的简单方法是,搜索多个partitions。搜索多个附近的partitions很明显会花费更多时间,但它会给出更好的accuracy。
在搜索时,你可以比较你的query vector与所有partition centroids来找到离它最近的partition。可以配置多少个。一旦你发现了这些centroids,你只需从这些partitions中选择dataset vectors,使用product quantizer来进行KNN search。
需要注意一些术语:
- verb “probe”指的是,选择partitions进行search。代码中你会看到index参数”nprobe”意味着:有多少partitions进行probe。
- Faiss的作者喜欢使用术语:Voronoi cells(而非“dataset partitions”)。一个Voronoi cell指的是,属于一个cluster的space区域。也就是说,它会包含在space中的所有points(vector与某个cluster的centroid会比其它clusters更接近)。
4.faiss doc上的解释
Inverted list objects & scanners
faiss实现了two low-level APIs来泛化inverted list存储。这对于以key-value数据库存储lists很有用。
- InvertedLists抽象类定义了inverted lists是如何从搜索代码被访问的。任意提供该interface的对象可以被用来保存lists。
- InvertedListsScanner提供了细粒度的访问,因为scanning function可以在用户提供的id和code tables上被调用
4.1 IndexIVF回顾
IndexIVF类(以及它的子类)可以被被用于Faiss的所有大规模应用中。它会将input vectors聚类成nlist个groups(nlist是IndexIVF的一个field)。在add时,一个vector会被分配一个groups。在search时,与query vector最相似的groups会被识别出,并进行穷举扫描(exhaustively scan)。
因而,IndexIVF具有两个components:
- quantizer(也称为:coarse quantizer)index。给定一个vector,quantizer index的search function会返回该vector所属的group。当使用nprobe>1的结果进行search时,它会返回与query vector最接近的nprobe个groups(nprobe是IndexIVF的一个field)。
- InvertedLists对象。该object会将一个group id(\(0 \cdots nlist-1\))映射到一个(code, id) pairs序列上.
4.2 InvertedLists对象
- Codes:指的是一个常量size(code_size)的byte strings。例如,36维的IndexIVFFlat具有的code_size=36 * sizeof(float) = 144 bytes。
- Ids:64-bit integer(负值是保留的,因此有用位只有63bits)
实际上,codes和ids会以两个独立的arrays返回,因为一些applications只需要其中之一,并且memory alignement是不同的。
4.2.1 search方法
该object有有三个相关的方法:
/// get the size of a list
size_t list_size(size_t list_no);
/// @return codes size list_size * code_size
const uint8_t * get_codes (size_t list_no);
void release_codes (const uint8_t *codes) const;
/// @return ids size list_size
const idx_t * get_ids (size_t list_no);
void release_ids (const idx_t *ids) const;通过get_codes(以及get_ids)获得的指针需要通过release_codes(以及release_ids)来释放。如果你喜欢RAII,InvertedLists::ScopedCodes(以及InvertedLists::ScopedIds)会有用。
有一个额外的prefetch_lists方法,它会通过search方法被用来通知InvertedLists对象:一些inverted lists会在不久被用到。
因此,search过程的调用顺序如下:
search(v) {
list_nos = quantizer->search(v, nprobe)
invlists->prefetch(list_nos)
foreach no in list_nos {
codes = invlists->get_codes(no)
// linear scan of codes
// select most similar codes
ids = invlists->get_ids(no)
// convert list indexes to ids
invlists->release_ids(ids)
invlists->release_codes(codes)
}
}4.2.2 add()方法
添加vectors需要有对InvertedLists对象的read-write权限。这通过add_entries方法提供。其它方法update_entries和resize被用于扩充(bulk)操作,比如,merging、 splitting、removing elements。
4.3 InvertedLists对象的行为
4.3.1 内存管理
如果own_invlists为true,InvertedLists对象通过IndexIVF的destructor被删除。缺省的,ArrayInvertedLists对象会在IndexIVF实例化时被构建,own_invlists被设置为true。缺省的invlists可以被replace_invlists所替代,用户必须决定所属关系(ownership)。
4.3.2 Threading
只读操作允许多线程访问。一些注释关于并发读写操作。
4.3.3 I/O
InvertedLists对象不需要和index object一起存储。如果不是这样,index object只包含处理外存(external storage)的所需信息。
4.4 Build-in InvertedLists类
InvertedLists类主要考虑可扩展性而设计。然而,在Faiss中有两个InvertedLists classes。
4.4.1 ArrayInvertedLists
这是一个std::vector<std::vector<…> >。这是最简单的in-RAM inverted lists实现,开销很少,add时间很快。它有一个特殊状态(status),因为当一个IndexIVF被构建时它会被自动实例化,因此这些vectors会被马上add。
4.4.2 OnDiskInvertedLists
该inverted list data被存储到磁盘的一个内存映射文件上(memory-mapped file)。会存在一个间接表(indirection table),它将list ids映射到file上的offset。 由于data是memory-mapped,没必要显式地从disk上取数据。然而,prefetch函数很有用,可以用上分布式文件系统的并发读。
有意思的是,通过将IO_FLAG_MMAP flag设置为read_index,一个“normal” IndexIVF可以被加载进一个OnDiskInvertedLists中。这使得它可以加载任意数目的indexes,无需担心是否满足RAM。
4.5 InvertedListScanner对象
Inverted list scanning可以在Faiss之外被控制。这使得没必要实现list访问函数作为回调,这不是惯例。
为了支持它,Faiss提供了:
- encode_vector函数:它可以将inverted list codes计算成一个array中,用来放到不受faiss管理的inverted lists
- InvertedListScanner对象:可以通过IndexIVF类获得。它会扫描lists、或计算单个query-to-code distance。
该访问非常low-level,但用户具有对scanning的total control,无需实现像InvertedLists对象的回调。
4.6 Encoding vectors
为了编码vectors,calling code应:
- 对该vector进行quantize,来寻找要存到哪个inverted list
- 调用encode_vectors来实际编码它
两个函数会进行batch操作以便提高效率。
以下是一个简化代码,它会将nb vectors存储到xb中,来定制inverted lists:
// size nb
idx_t *list_nos = ... ;
// find inverted list numbers
index_ivf.quantizer->assign (nb, xb, list_nos);
// size index->code_size * nb
uint8_t *codes = ...;
// compute the codes to store
index->encode_vectors (nb, xb, list_nos, codes);
// populate the custom inverted lists
for (idx_t i = 0; i < nb; i++) {
idx_t list_no = list_nos[i];
// allocate a new entry in the inverted list list_no
// get a pointer to the new entry's id and code
idx_t * id_ptr = ...
uint8_t * code_ptr = ...
// assume the vectors are numbered sequentially
*id_ptr = i;
memcpy (code_ptr, codes + i * index->code_size, index->code_size);
}4.7 Searching
为了执行search,存在一些loop levels。
以下是执行query的简化代码。它会查询在index中np个vectors xq。
// size nprobe * nq
float * q_dis = ...
idx_t *q_lists = ...
// perform quantization manually
index.quantizer->search (nq, xq, nprobe, q_dis, q_lists);
// get a scanner object
scanner = index.get_InvertedListScanner();
// allocate result arrays (size k * nq), properly initialized
idx_t *I = ...
float *D = ...
// loop over queries
for (idx_t i = 0; i < nq; i++) {
// set the current query
scanner->set_query (xq + i * d);
// loop over inverted lists for this query
for (int j = 0; j < nprobe; j++) {
// set the current inverted list
int list_no = q_lists[i * nprobe + j];
scanner->set_list (list_no, q_dis[i * nprobe + j]);
// get the inverted list from somewhere
long list_size = ...
idx_t *ids = ....
uint8_t *codes = ....
// perform the scan, updating result lists
scanner->scan_codes (list_size, codes, ids, D + i * k, I + i * k, k);
}
// re-order heap in decreasing order
maxheap_reorder (k, D + i * k, I + i * k);
}




 图2
图2