hinton在2012 《Transforming Auto-encoders》中提出了胶囊“capsules”的概念。我们来看下这篇paper:
1.介绍
当前在图片中识别目标(objects)的方法效果很差,并且所使用的方法仍不够智能。一些最好的计算机视觉系统使用方向梯度直方图( histograms of oriented gradients)作为“visual words”,并使用一个天然空间金字塔(crude spatial pyramid)来将这些元素的局部分布进行建模。这样的方法无需精确知道目标在哪就可以正确识别目标(objects)——这种能力用于诊断人类大脑损伤。最好的人工神经网络使用手工编码的、权重共享的schemes(hand-coded weight-sharing schemes)来减小自由参数的数目,并通过对相同kernel的平移拷贝(transpated replicas)的局部池子(local pools)的激活(activities)做子抽样(subsampling)来达到局部平移不变性(local translational invariance)。该方法可以处理在图片中的变化(视角的变化引起),但它很明显不能处理识别任务,比如:脸部识别(facial identity recognition),这类任务需要知道高级部位间的精准局部关系(比如:鼻子和嘴)。在经过使用卷积网络做subsampling的多个stages后,在这些姿态(poses)中的高级特征具有许多不确定性。这通常被看成是一个合理的特性,因为它相当于在受限范围内的姿态是不变的,但这使得计算精准的局部关系来说是不可行的。
该paper会讨论CNN尝试这样去做时会误入岐途。作为对在“neurons”的activities的视角不变性(它使用单个标量输入对重复的特征检测器的一个local pool的activities进行归纳)的替代,人工神经网络应使用局部”capsules”来执行对输入的一些相对复杂的内部计算,并接着封装这些计算结果到一个包含高度信息化输出的小向量中。每个capsule会学习识别在一定受限视角条件(viewing conditions)和变形(deformations)等范围内的一个隐式定义的可视化实体(visual entity),它会同时输出在该限定范围内的该实体概率、以及一个“实例参数(instantiation parameters)“的集合,它会包含该可视化实体的精准姿态(pose)、光线照明(lighting)、变形(deformation),与该实体的一个隐式定义的规范版本相关联。当该capsule正常工作时,可视化实体的概率是局部不变的(locally invariant)——随着实体在各种可能出现方式(在capsule覆盖的受限区域内)上移动,该概率不会改变。该实例参数是“等变化的(equivariant)”——随着视角条件(viewing condition)的改变,实体会在appearance manifold上进行移动,该实例参数会通过一个相应的量进行变化,因为他们表示该实体在appearance manifold上的本征坐标。
capsules的主要优点之一是:输出显式的实例参数。该方法提供了一种简单方式通过识别它们的部件(parts)来识别整体(wholes)。如果一个capsule通过学习以向量形式输出它的可视化实体的姿态(pose),那么该向量与该pose在计算机显卡(computer graphics)中的“天然表示(nature representations)”成线性相关,这里存在着一个简单且高度选择性的测试方法,来判断该可视化实体表示是否可以通过两个active capsules(A和B)进行表示,这两个capsules具有合理的局部关系(spatial relationship)来激活一个更高层级的capsule C。假设capsule A的pose outputs通过一个矩阵\(T_A\)来表示,该矩阵指定了在A的标准可视化实体(canonical visual entity)与通过capsule A发现的该实体的实际实例(actual instantiation)之间的坐标转换。如果我们使用part-whole坐标转换\(T_{AC}\)乘以\(T_A\),这样就会将A的标准可视化实体与C的标准可视化实体相关联,我们就可以得到\(T_C\)的一个预测。相似的,我们使用\(T_B\)和\(T_{BC}\)来获取另一个预测。如果这些预测是一个好的匹配,通过capsules A和B发现的实例(instantiations)会在合理的局部关系以便激活capsule C,并且该预测的平均值会告诉我们:通过C表示的更大的可视化实体是如何对应于C的标准可视化实体进行转换的。例如,如果A表示一张嘴(mouth),B表示一个鼻子(nose),他们可以为面部姿态(pose of face)做出预测。如果这些预测达成一致,嘴和鼻子就必须在合理的局部关系内来形成一个脸。关于这种执行形态识别(shape recognition)的方法,其中一个有意思的特性是,局部-整体关系(part-whole)的认识是视角不变性的(viewpoint-invariant),可以通过权重矩阵进行表示,然而,关于当前已观察目标、及它相对应部件(parts)的实例参数的认知是视角等变化的(viewpoint-equivariant),并且可以通过neural activities来表示。
为了获取这个的一个part-whole的结构,“capsules”会实现在该结构中最低层的部件(parts),来从像素强度(pixel intensities)上抽取显式的姿态参数。该paper展示了,如果该神经网络可以直接、非可视的方式访问该变换(direct, nonvisual access to transformations),这些capsules相当容易从成对的转换图片中学习得到。从人类视角上看,例如,一次扫视会引起关于该视网膜图片的一个纯变换(pure translation),皮质(cortex)可以不可见地访问关于眼部移动的信息。
2.学习第一层capsules
一旦像素强度被转换成一个active集合的outputs时,第一层capsules中的每个capsule会生成一个关于它的可视化实体的pose的显式表示,很容易看到,越大越复杂的可视化实体是如何通过使用active、低级capsules的关于poses预测的方式来识别的。但是,第一层capsules是从哪里来的?一个人工神经网络是如何学到将像素强度的表示(language)转换成关于姿态参数(pose parameters)的表示的?该paper提出的该问题会有一个很令人吃惊的简单答案,我们称之为“transforming auto-encoder”。通过使用简单的2D图片和capsules,我们解释了该思想,pose outputs是一个关于x和y的位置。后面我们会泛化到更复杂的姿态(poses)。
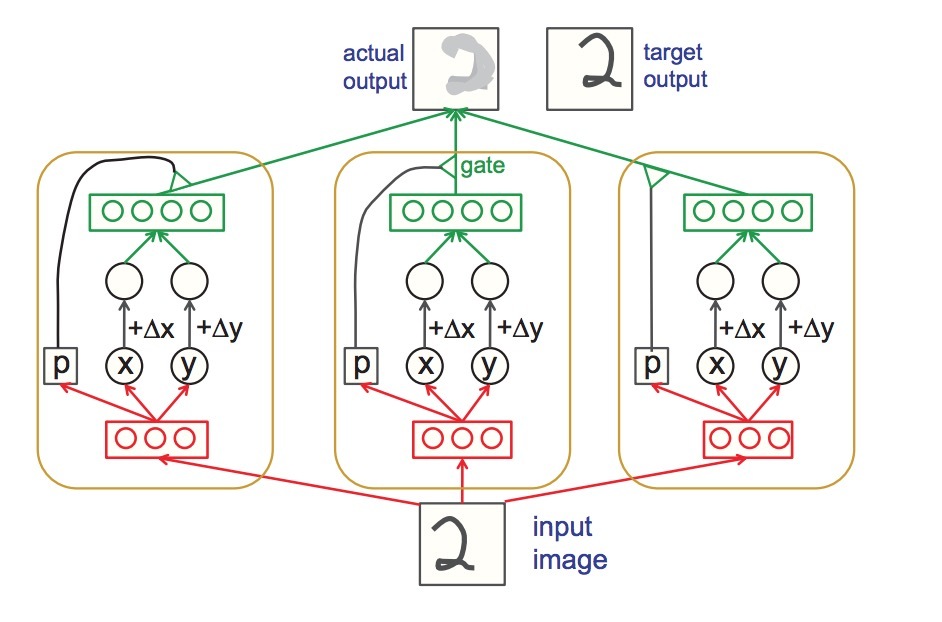
图1: 一个transforming auto-encoder的三个capsules,会建模平移(translations)。图中的每个capsule具有3个recognition units和4个generation units。在连接(connections)上的权重可以通过在实际outputs和target outputs之差进行BP学到
如图1所示,考虑该前馈神经网络。一旦它已经被学到,该网络就是确定的(deterministic),输入一张图片,进行平移shifts(\(\Delta x\)和\(\Delta y\)),它会输出shifted后的图片。该网络由多个独立的capsules组成,它们只会在最后一层进行交叉,一起合作生成期望得到的shifted后的图片。每个capsule具有自己的logistic “识别单元(recognition units)”,它们扮演着hidden layer的角色,来计算三个数(numbers):x, y, p,capsule会将它的输出发送给视觉系统的更高层。p是capsule的可视化实体出现在输入图片中的概率。capsule也具有它自己的“生成单元(generation units)”,可以被用于计算capsule对转换后图片的贡献。generation units的输入是\(x + \Delta x\)和\(y+\Delta y\),capsule的generation units对输出图片的贡献,会乘以p,因而 inactive capsules会无效。
为了让transforming auto-encoder生成正确的输出图片,通过每个active capsule计算得到的x和y值,会对应于它的可视化实体的实际x和y位置。并且我们不需要事先知道该可视化实体或它的坐标框架的原点(origin)。
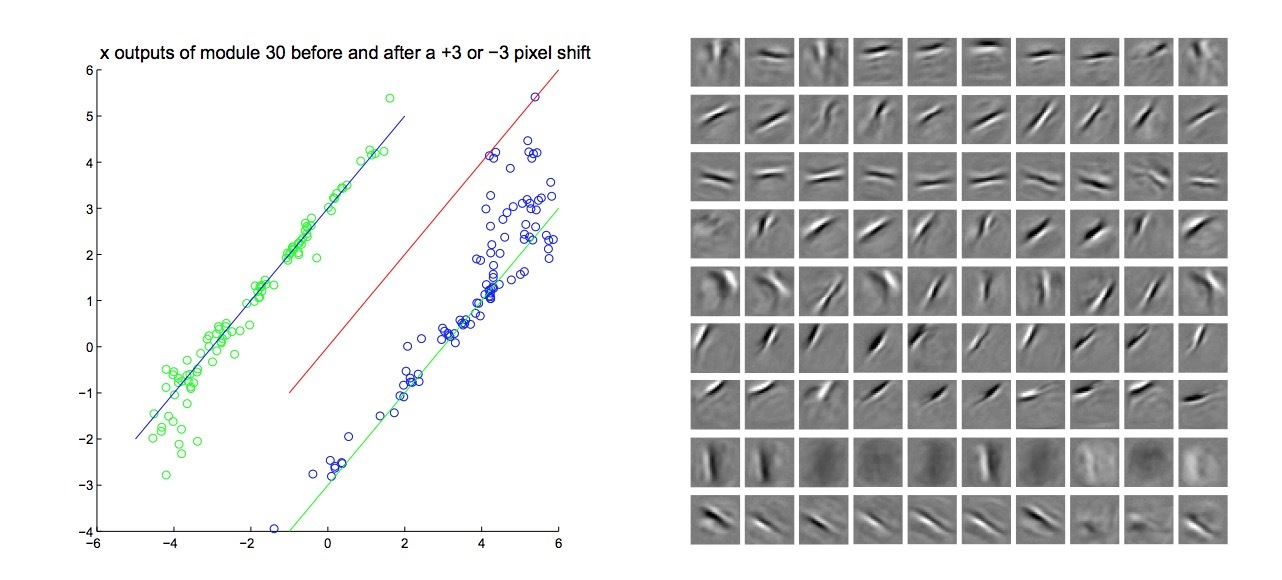
图2: 左图:一个散点图. 其中纵轴表示其中一个capsule对于每张数字图片的x输出,横轴表示如果该图片在x方向上以(+3 或 -3)像素进行shift时该相同capsule的x输出。如果原始图片已经接近该capsule在x坐标可以表示的极限,在该方向上进一步shifting会造成capsule生成错误的答案,但如果对于该capsule为管辖区域外的数据,将它的概率设置为0, 这不会有影响。 右图:9个capsules(纵),10个generative(横) units,对应的outgoing weights
对于该transforming auto-encoder的简单效果演示,我们训练了一个带30个capsules的网络,每个都有10个recognition units和20个generation units。每个capsule会看到一张MNIST数字图片的整体。输入和输出图片都可以使用-2, -1, 0, +1, +2像素在x和y方向上随机进行shift,transforming auto-encoder会将生成的\(\Delta x\)和\(\Delta y\)看成是一个额外输入。图2展示了当输入图片进行shift后,该capsules会以合理的方式输出shift后的x和y值。图2展示了,capsules会学习带高度局部化投影域(projective fields)的generative units。recognition units的receptive fields噪声较多,局部化更少些。

图3 Top: 完全仿射变换,使用一个带有25个capsules的 transforming auto-encoder,每个capsule具有40个recognition units和40个generation units。顶部行展示了输入的图片;中间行展示了输出的图片,底部行展示了被正确变换的输出图片. Bottom:该transforming anto-encoder的前20个generation units,前7个capsules的output weights。
2.1 更复杂的2D转化
如是每个capsule会给出9个real-valued outputs,它们被看成是一个3x3矩阵A,一个transforming auto-encoder可以被训练来预测一个完整的2D仿射变换(affine transformation:平移translation, 旋转rotation, 缩放scaling,裁减shearing)。一个已知矩阵T会被用于capsule A的output上,来获得matrix TA。当预测目标输出图片时,TA的元素接着被当成genreation units的输入。
2.2 在3D视角上建模变化

图4 左:对于训练数据,输入、输出和目标的立体像对(stereo-pairs)。右:对于在训练期间未见过的汽车模型的input、output和target stereo-pairs
使用矩阵乘法来建模视角效果的一个主要潜在优点是,它很容易拷贝到3D上。我们的前置实验(见图4)使用计算机显卡来生成从不同视角上关于汽车的不同类型的立体图片。transforming autoencoder包含了900个capsules,每个具有两个layers(32,64)的RLRU(rectified linear recognition units)。capsules具有11x11像素的receptive fields,它由一个在96x96图片上的30x30 grid组成,两个相邻capsules间的stride为3个pixels。它们不是weight-sharing的。从该layer的64个recognition units中生成的每个capsule,3D方向上的特征(可以用于调参来检测)的一个3x3矩阵表示,同时隐式定义特征出现的概率。该3x3矩阵接着乘以真实的在源图片和目标图片间的转换矩阵,结果被feed给capsule的具有128个GRLU(generative rectified linear units)的单个layer上。该generation unit activities会乘以capsules的“特征出现(feature presence)”概率,结果被用于增加在重构图片(它以capsule的11x11 receptive field的中心为中心)上一个22x22 patch上的强度。由于该数据由图片的立体对组成,每个capsule必须同时在立体对的成员上查看一个11x11 patch,同时也会在重构的22x22 patch的每个成员上进行。
3.讨论
略。