我们先来看下Google Inc的paper:Wide & Deep Learning for Recommender Systems。
一、介绍
推荐系统可以看成是一个搜索排序系统,其中输入的query是一个用户和上下文的集合,输出是一个item列表。给定一个query,推荐任务就是在数据库中找到相关的items,接着基于目标(比如:点击or购买)去对items进行排序。
推荐系统与常见的搜索排序问题相同的一个挑战是,同时满足Memorization和Generalization。Memorization可以宽泛地定义成学到items或features的共现率,并利用(exploiting)这种在历史数据中的相关关系(correlation)。Generalization则基于相关关系的转移,并探索(explores)在过往很少或从不出现的新的特征组合。基于Memorization的推荐系统通常更局部化(topical),将items与执行相应动作的users直接相关。而基于Generalization的推荐则更趋向于推荐多样化的items。在本papers中,我们主要关注Google Play Stores的推荐问题,方法本身可用于其它场景。
对于工业界大规模的在线推荐和排序系统,常用的线性模型(比如:logistic regression)被广泛使用,因为它的简单性、可扩展性以及可解释性。模型通常在使用one-hot编码的二值化的稀疏特征上。例如,二值化特征”user_installed_app=netflix”,如果用户过去安装(installed)了Netflix,则具有特征值1. 通过在稀疏特征上使用cross-product transformation可以有效地达到Memorization,比如AND(user_installed_app=netflix, impression_app=pandora),如果用户过去安装了Netflix,接着被曝光了Pandora,那么它的值是1. 这可以解释一个特征对(feature pair)的共现率与目标label间的相关关系。通过使用更少(粗)粒度的特征可以添加Generalization,例如:AND(user_installed_category=video, impression_category=music),(注:上面Memorization使用的是具体的app,而此处Generalization使用的仅仅是app的category),但人工的特征工程通常是必需的。(cross-product transformation)的一个限制是,不能泛化到那些在训练数据上没有出现过的query-item特征对。
而Embedding-based的模型,比如因子分解机(FM)或深度神经网络,只需要很少的特征工程,通过为每个query和item特征对(pair)学到一个低维的dense embedding vector,可以泛化到之前未见过的query-item特征对,。然而,当底层的query-item矩阵很稀疏和高秩(high-rank)时(比如,用户具有特殊偏好或很少出现的items),很难为query-item pair学到有效的低维表示。在这种情况下,大多数query-item pairs之间是没有交叉的,但dense embeddings会为所有的query-item pairs生成非零的预测,这样会过泛化(over-generalize),并生成不相关的推荐。另一方面,使用交叉特征转换(cross-product features transformations)的线性模型可以使用更少的参数就能记住(memorize)这些“异常规则(exception rules)”。(embedding 优点:泛化,缺点:稀疏时)
在本文中,我们提出了Wide&Deep learning框架来在同一个模型中达到Memorization 和 Generalization,通过联合训练一个如图一所示的线性模型组件和一个神经网络组件。
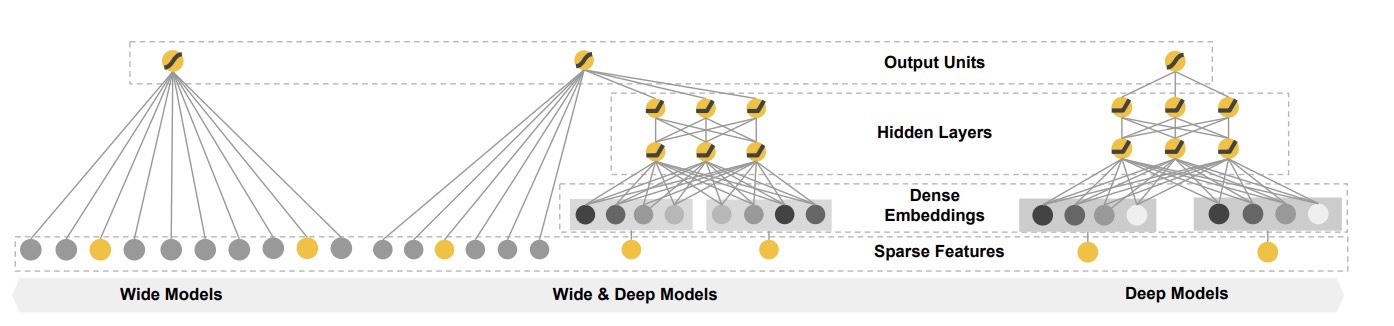
图1:
本文的主要贡献:
- Wide & Deep 学习框架,可以用于联合训练带embeddings的feed-forward神经网络以及带特征转换的线性模型,用于带稀疏输入的常见推荐系统中。
- Wide & Deep推荐系统的实现和评估在Google Play上已经产品化,这个app store具有数十亿的活跃用户、以及上百万的app。
- 开源,在Tensorflow上提供了一个高级API。
思想很简单,我们展示了Wide & Deep框架,它极大地提升了App的获得率(acquisition rate)并且同时满足training和serving的速度要求。
推荐系统总览
app推荐系统如图二所示。一个query,它包含着许多用户和上下文特征,当一个用户访问app store时生成。推荐系统会返回一个app列表(曝光:impressions),用户在此之上会执行特定的动作(点击:click或购买:purchase)。这些用户动作,伴随着queries和impressions,会以日志的形式记录下来。
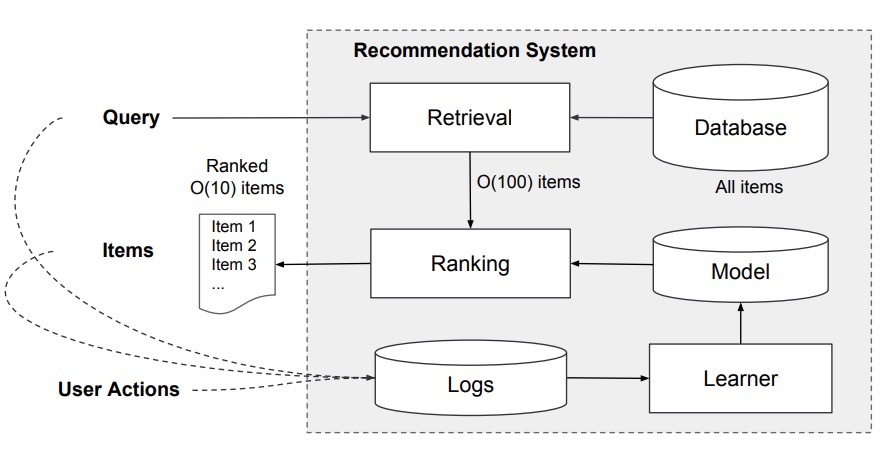
图2
由于在数据库中有超过百万的app,对于在serving延迟条件之内(通常为O(10)ms)的每一个query,尽可能得对每一个app进行评分是相当困难。因此,上述第一步收到一个query的过程是检索(retrieval)。检索系统会返回一个最匹配query的item的短列表,通常使用机器学习模型和人工定义规则来达到。在数量减至候选池后,排序系统(ranking system)会通过它们的得分对所有items进行排序。得分通常是$ P(y|x) $,对于给定的特征x,一个用户的动作标签y,包括用户特征(比如:国家,语言,人口属性信息),上下文特征(比如:设备,天的小时,周的天),曝光特征(比如:app age, app的历史统计信息)。在本文中,我们只关注在排序系统中使用Wide & Deep 学习框架。
3. Wide & Deep Learning
3.1 Wide组件
wide组件是一个泛化的线性模型,形式为:$ y=w^Tx+b $,如图1(左)所示。y是预测,$ x = [x_1, x_2, …, x_d] $是d维的特征向量, $ w = [w_1, w_2,…, w_d] $是模型参数,其中b为bias。特征集包括原始的输入特征和转换后的特征,一个最重要的转换是,cross-product transformation。它可以定义成:
\[\phi_k(x)=\prod_{i=1}^{d}x_{i}^{c_{ki}}, c_{ki} \in \{0, 1\}\]…(1)
其中$c_{ki}$为一个boolean变量,如果第i个特征是第k个变换$\phi_k$的一部分,那么为1; 否则为0.对于二值特征,一个cross-product transformation(比如:”AND(gender=female, language=en)”)只能当组成特征(“gender=female” 和 “language=en”)都为1时才会为1, 否则为0. 这会捕获二值特征间的交叉,为通用的线性模型添加非线性。
3.2 Deep组件
Deep组件是一个前馈神经网络(feed-forward NN),如图1(右)所示。对于类别型特征,原始的输入是特征字符串(比如:”language=en”)。这些稀疏的,高维的类别型特征会首先被转换成一个低维的、dense的、real-valued的向量,通常叫做“embedding vector”。embedding的维度通常是O(10)到O(100)的阶。该embedding vectors被随机初始化,接着最小化最终的loss的方式训练得到该值。这些低维的dense embedding vectors接着通过前向传递被feed给神经网络的隐层。特别地,每个隐层都会执行以下的计算:
\[a^{l+1} = f(W^{(l)} a^{(l)} + b^{(l)})\]…(2)
其中,l是层数,f是激活函数(通常为ReLUs),$a^{(l)}, b^{(l)}和W^{(l)}$分别是第l层的activations, bias,以及weights。
3.3 Wide & Deep模型的联合训练
Wide组件和Deep组件组合在一起,对它们的输入日志进行一个加权求和来做为预测,它会被feed给一个常见的logistic loss function来进行联合训练。注意,联合训练(joint training)和集成训练(ensemble)有明显的区别。在ensemble中,每个独立的模型会单独训练,相互并不知道,只有在预测时会组合在一起。相反地,联合训练(joint training)会同时优化所有参数,通过将wide组件和deep组件在训练时进行加权求和的方式进行。这也暗示了模型的size:对于一个ensemble,由于训练是不联合的(disjoint),每个单独的模型size通常需要更大些(例如:更多的特征和转换)来达到合理的精度。相比之下,对于联合训练(joint training)来说,wide组件只需要补充deep组件的缺点,使用一小部分的cross-product特征转换即可,而非使用一个full-size的wide模型。
一个Wide&Deep模型的联合训练,通过对梯度进行后向传播算法、SGD优化来完成。在试验中,我们使用FTRL算法,使用L1正则做为Wide组件的优化器,对Deep组件使用AdaGrad。
组合模型如图一(中)所示。对于一个logistic regression问题,模型的预测为:
\[P(Y = 1 | x) = \sigma(w_{wide}^{T} [x, \phi(x)] + w_{deep}^{T} a^{(l_f)} + b)\]…(3)
其中Y是二分类的label,$ \sigma(·) $是sigmoid function, $ \phi(x) $是对原始特征x做cross product transformations,b是bias项。$w_{wide}$是所有wide模型权重向量,$w_{deep}$是应用在最终激活函数$a^{(l_f)}$上的权重。
4.系统实现
app推荐的pipeline实现包含了三个stage:数据生成,模型训练,模型serving。如图3所示。
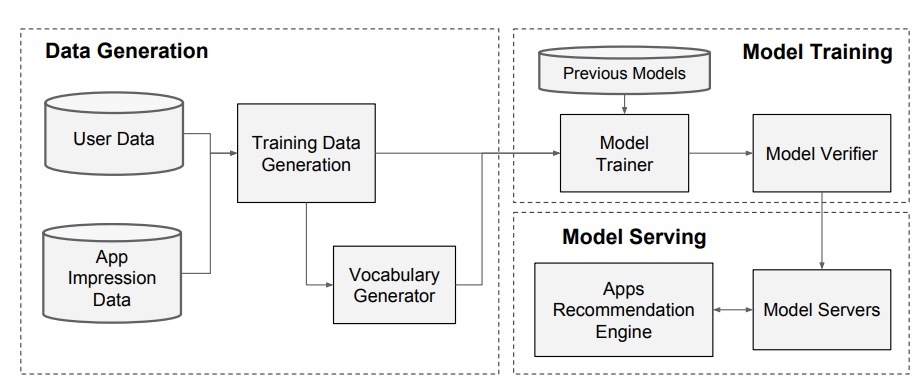
图3
4.1 数据生成
在这一阶段,用户和app的曝光数据在一定时间内被用于生成训练数据。每个样本对应于一个曝光。label为app的获得率(acquisition):如果曝光的app被下载则为1, 否则为0.
词汇表(Vocabularies),它是一个关于将类别特征字符串映射到integer ID上的表,也在该阶段生成。该系统会为至少出现过某个最小次数的所有的string特征计算ID空间。连续的real-valued特征被归一化到[0, 1],通过将一个特征值x映射到它的累积分布函数$P(X <= x)$,将它分成$n_q$份 (quantiles)。对于第i个份(quantiles),对应的归一化值为:$ \frac{i-1}{n_q-1}$。分位数(quantiles)边界在数据生成阶段计算。
4.2 模型训练
我们在试验中使用的模型结构如图4所示。在训练期间,我们的输入层接受训练数据和词汇表的输入,一起为一个label生成sparse和dense特征。wide组件包含了用户安装app和曝光app的cross-product transformation。对于模型的deep组件,会为每个类别型特征学到一个32维的embedding向量。我们将所有embeddings联接起来形成dense features,产生一个接近1200维的dense vector。联接向量接着输入到3个ReLU层,以及最终的logistic输出单元。
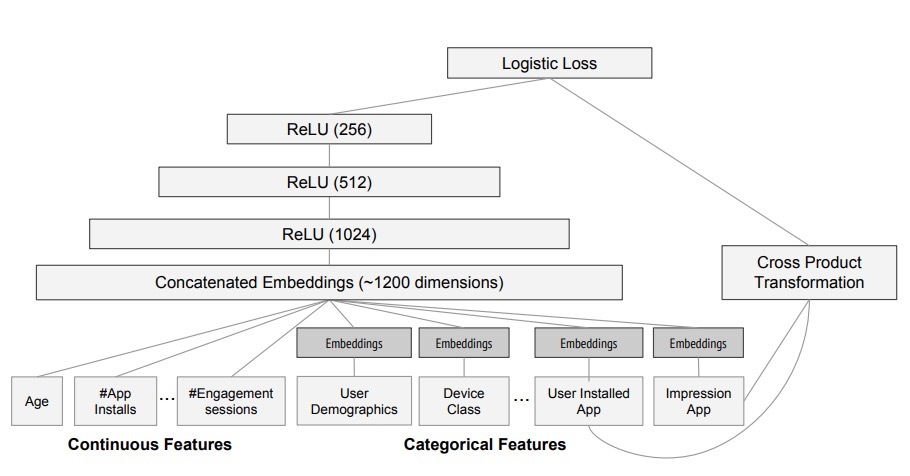
图4:
此处做个注解(美食推荐场景FoodIO):wide模型的目的是,记住(memorize)哪些items能更好地对应每个query。因此,你训练带交叉特征转换的线性模型,是为了捕获一个query-item feature pair与相应的目标label(一个item是否被消费、购买)间的共现关系。该模型会预测每个item的消费概率 \(P(consumption \| query, item)\),接着FoodIO会返回最高预测购买率的top item。例如,模型学到了特征:AND(query=”炸鸡(fried chicken)”, item=”鸡肉和华夫饼(chicken and waffles)”)的效果很好,而AND(query=”炸鸡(fried chicken)”, item=”鸡肉炒饭(chicken fried rice)”)这个并不受喜欢,尽管字符上更匹配。换句话说,它可以记住哪些用户喜欢,从而获得更多的交易额。
同理:上述wide中提到的installed app和impressed app可以理解成是上面的item和query。
Wide & Deep模型在超过5000亿的样本上进行训练。每一时刻有新的训练数据集到达时,模型需要重新训练。然而,每次从头到尾重新训练的计算开销很大,数据到达和模型更新后serving间的延迟较大。为了解决该问题,我们实现了一个warm-starting系统,它会使用前一个模型的embeddings和线性模型权重来初始化一个新的模型。
在将模型加载到模型服务器上之前,需要做模型的演习,以便确保它不会在serving的真实环境上出现问题。我们在经验上会验证模型质量,对比前一模型做心智检查(sanity check)。
4.3 模型Serving
一旦模型被训练和验证后,我们会将它加载到模型服务器上。对于每个请求,服务器会从app检索系统上接收到一个app候选集,以及用户特征来从高到低排序,接着将app按顺序展示给用户。得分的计算通过在Wide&Deep模型上运行一个前向推断传递(forward inference pass)来计算。
为了在10ms的级别服务每个请求,我们使用多线程并行来优化性能,运行运行更小的batches,而不是在单个batch inference step中为所有的候选app进行scoring。
5.试验结果
为了在真实的推荐系统上评估Wide & Deep learning的效果,我们运行了在线试验,并在两部分进行系统评测:app获得率(app acquisitions)和serving性能。
5.1 App Acquisitions
我们在一个A/B testing框架上做了3周的试验。对于控制组,1%的用户被随机选中,推荐由之前版本的排序系统生成,它是一个高度优化的wide-only logistic regression模型,具有丰富的cross-product特征转换。对于试验组,随机选中1%的用户,使用相同的特征进行训练。如表1所示,Wide & Deep模型在app store的主页上提升了app acquisition rate,对比控制组,有+3.9%的提升。另一个分组只使用deep组件,使用相同的神经网络模型,具有+1%的增益。
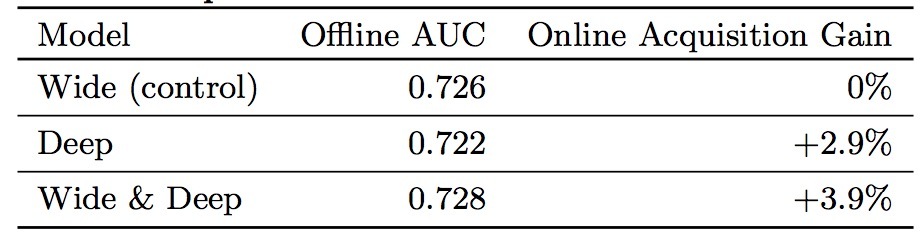
表1:
除了在线试验,我们也展示了在held-out离线数据上的AUC。其中Wide & Deep具有更高的离线AUC,在线也更好。一个可能的原因是,曝光和点击在离线数据集上是确定的,而在线系统通过混合generalization和memorization,从新的用户响应学到,生成新的探索推荐。
5.2 Serving Performance
Serving时具有高的吞吐率(throughout)和低延时是很有挑战性的。在高峰期,我们的推荐服务每秒处理1000w个app得分。单个线程上,在单个batch上为所有的候选得进行scoring会花费31ms。我们实现了多线程,并会将每个batch分割到更小的size上,它会将客户端的延迟的延迟减小到14ms上,所图2所示。
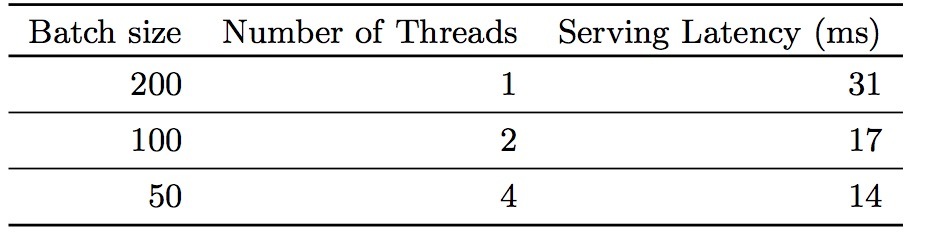
表2
6.相关工作
将使用特征交叉转换的wide linear model与使用dense embeddings的deep neural networks,受之前工作的启发,比如FM:它会向线性模型中添加generalization,它会将两个变量的交互分解成两个低维向量的点积。在该paper中,我们扩展了模型的能力,通过神经网络而非点积,来学习在embeddings间的高度非线性交叉(highly nonlinear interactions)。
在语言模型中,提出了RNN和n-gram的最大熵模型的joint training,通过学习从input到output之间的直接权重,可以极大减小RNN的复杂度(hidden layer)。在计算机视觉中,deep residual learning被用于减小训练更深模型的难度,使用简短连接(跳过一或多层)来提升accuracy。神经网络与图模型的joint training被用于人体姿式识别。在本文中,我们会探索前馈神经网络和线性模型的joint training,将稀疏特征和output unit进行直接连接,使用稀疏input数据来进行通用的推荐和ranking问题。
7.Tensorflow
只需要3步,即可以使用tf.estimator API来配置一个wide,deep或者Wide&Deep:
- 1.选中wide组件的特征:选中你想用的稀疏的base特征列和交叉列特征列
- 2.选择deep组件的特征:选择连续型的列,对于每个类别型列的embedding维,以及隐层的size。
- 将它们放置到一个Wide&Deep模型中(DNNLinearCombinedClassifier)
关于更详细的操作,示例代码在:/tensorflow/tensorflow/examples/learn/wide_n_deep_tutorial.py,具体详见tensorflow tutorial。