youtube的基于深度学习的推荐系统,主要分成两大部分:
介绍
Youtube是世界上最大的创建、分享、和发现视频内容的平台。Youtube推荐负责帮助超过十亿用户从不断增长的视频语料中发现个性化内容。在本paper中,我们主要关注深度学习对youtube视频推荐的巨大影响。图1展示了youtube app主页的推荐。
图1
youtube推荐视频极具挑战性,主要有:
- 规模(Scale):许多已经存在的推荐算法证明只能在小数据集上进行。对于youtube的海量用户和语料来说必须要有高度特定的分布式学习算法和高效的serving系统
- 新鲜度(Freshness):Youtube具有一个非常动态的语料,每秒钟都有许多视频被上传上来。推荐系统必须对这些新上传的视频内容进行建模,从而被用户快速接受。新内容与播放良好的老视频间的平衡,则通过EE(exploration/exploitation)的角度去理解。
- 噪声(Noise):由于稀疏性、以及多种不可观察的外部因素,youtube的历史用户行为很难去预测。我们很少能获取真实的用户满意度,只能建模含噪声的隐式反馈信号。更进一步,由于没有一个较好的知识本体(ontology)定义,与内容有关的metadata很难进行组织。我们的算法必须对这些特性足够健壮。
与Google的其它产品领域进行合作,youtube已经迁移到了深度学习作为通用解法。我们的系统构建在google Brain上,它开源了tensorflow。tensorflow提供了一个灵活的框架来实验许多DNN架构。我们的模型可以学习接近10亿参数,在数百亿的样本上进行训练。
对比与MF领域的研究,使用DNN网络进行推荐的工作还相当少。神经网络被用于新闻推荐[17],引文[8],评论评分[20]等。协同过滤也被公式化成DNN[22]和autoencoders[18]。Elkahky等使用深度学习对用户进行跨领域建模。在一个基于内容的设定中,Burges等使用DNN进行用户推荐。
该paper组织如下:第2节讲述系统。第3节描述候选生成模型,包括如何训练以及用于对推荐进行serving。实验结果将展示模型如何从hidden units的deep layers以及额外的异构信号受益。第4节详述了排序模型,包含经典的LR如何被修改来训练一个模型预测期望的观看时长(而非点击概率)。实验结果表明,hidden layer的深度在这种情况下有用。最后,第5节为结论。
2.系统总览
推荐系统的整体结构如图2所示。系统由两个神经网络组成,一个用于候选生成,另一个用于ranking。
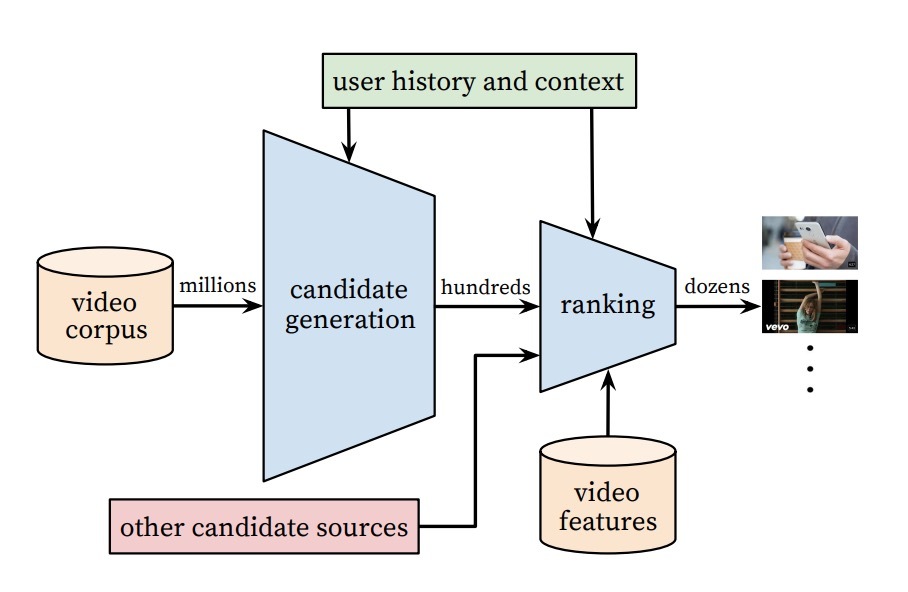
图2
候选生成网络会采用youtube用户历史行为作为输入,并从一个大语料中检索出一个视频子集(数百个)。这些候选(candidates)通常与用户高度相关,带有较高的precision。候选生成网络只通过CF提供了宽泛的个性化。用户的相似度被表示成粗粒度特征,比如:视频ID,搜索query tokens和人口统计学信息(demographics)。
在列表中呈现一些“best”推荐,则需要一个细粒度的表示(representation)来在具有较高recall的候选间的区分相对重要性。ranking网络会完成该任务,它会根据一个期望的目标函数,使用用户和视频的丰富特征集合,来为每个视频分配一个分数。根据排序,最高得分的视频会呈现给用户。
这种two-stage推荐方法,允许用户从一个非常大的视频语料(数百万)做出推荐,可确定的是,只有少量视频出现在移动设备中,它们对于用户是个性化、并且是吸引人的。再者,该设计可以允许对由其它源生成的候选进行混合,比如早期描述的工作[3]。
在部署期间,我们使用离线指标(precision, recall, ranking loss等)做了大量评估,来指导我们的系统进行增量改进。然而,对于一个算法或模型的效果最终决定,还是要看真实环境上的A/B testing。在真实环境中,我们会评估在CTR、观看时长、以及其它评估用户参与度的指标上上的细微变化。这很重要,因为真实A/B结果不总是与离线实现相关。
一、候选生成
在候选生成期间,从海量的Youtube语料中晒筛选出数百个与用户相关的视频。以前的推荐系统使用MF方法来根据rank loss训练。我们的神经网络模型的每个迭代会模仿该因子分解行为,它使用只嵌入用户之前观看行为的浅层网络。从该观点上看,我们的方法可以看成是因子分解技术的非线性泛化。
3.1 推荐即分类
我们将推荐当成是一个极端多分类问题(extreme multi-class),其中预测问题变为:视频库V,有上百万的视频,某用户U,在上下文C上,在时间t时的观看行为$w_t$,刚好是某个视频i.
\[P(w_t =i|U,C)=\frac{e^{v_{i} u}}{\sum_{j \in V}{e^{v_{j} u}}}\]其中u表示一个高维的(user,context)pair的“embedding”, v表示每个候选视频的emdedding。在该假设中,一个emdedding可以简化成一个稀疏实体的映射(视频,用户等各有一个),映射到一个N维的dense vector中。深度神经网络的任务是:学到user embeddings: u,作为用户历史和上下文的函数,这在使用一个softmax分类器对视频进行判别时有用。
使用隐式反馈(观看行为)来训练模型,其中,用户完成一个视频可以认为是一个正例。
Efficient Extreme Multiclass
为了有效地训练这样一个具有上百万分类的模型,我们采用的技术是:从后台分布(“候选抽样candidate sampling”)中抽样负类(negative classes),接着通过按重要性加权(importance weighting)[10]来纠正这些样本。对于每个样本,为true-label和negative-label,学习目标是最小化cross-entropy loss。实际中,会抽样上千个负样本,这种方法可以比传统的softmax快100倍。另一个可选的方法是:hierarchical softmax,但这里我们不去做对比。
在提供服务的阶段(serving time),我们需要计算最可能的N个分类(视频),以便选中其中的top N,来展现给用户。对上百w级的item进行打分,会在10ms左右的延迟内完成。之前的Youtube系统靠hashing技术[24]解决,和这里描述的分类器使用相类似的技术。由于在serving time时并不需要对softmax输出层校准(calibrated)likelihoods,打分问题(scoring problem)可以缩减至在点乘空间中的最近邻搜索问题,可以使用[12]中提供的库来完成。我们发现,在最近邻搜索算法上做A/B test效果并不特别明显。
1.1 模型架构
受语言模型中的CBOW(continuous bag of words)的启发,我们为固定size视频库中的每个视频学习高维emdeddings,接着将这些emdeddings前馈(feed)输入到一个前馈神经网络。一个用户的观看历史,可以被表示成一个关于稀疏视频id的可变长序列,这些id会通过embeddings被映射到一个dense vector representation上。该网络需要固定大小的dense inputs,最后选择对emdeddings的简单平均(simply averaging),因为它在不同策略中(sum, component-wise max,等)效果最好。最重要的,该emdeddings会和其它一些模型参数一起通过常规的梯度下降BP更新即可学到。特征被拼接(concatenate)到一个很宽的第一层上(wide first layer),后面跟着许多层的完全连接的ReLU层[6]。图3展示了整体架构,它带有额外的非视频观看特征(no-video watch features)。
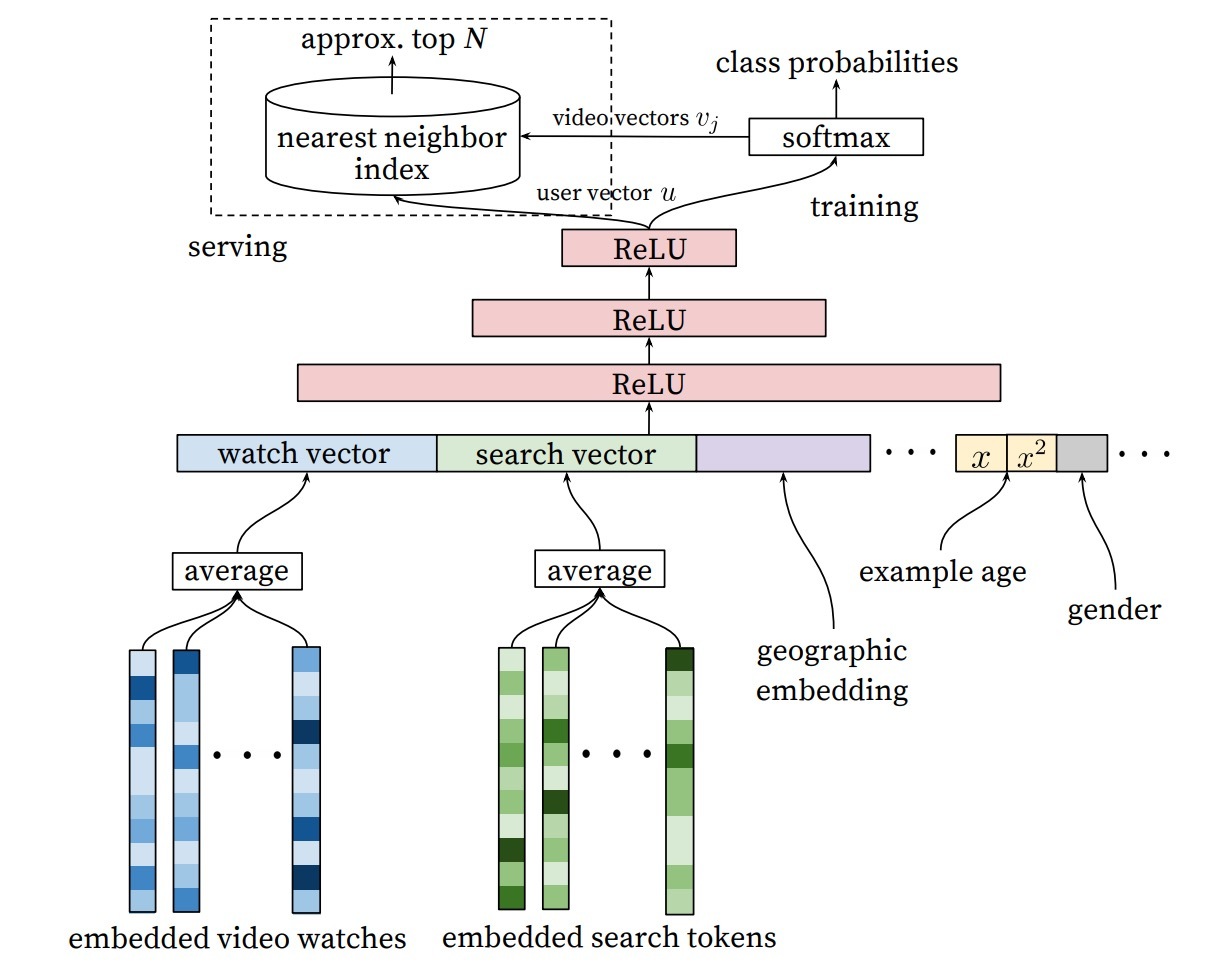
图3:
1.2 多种信号
将DNN作为普通的矩阵分解(MF)的一种泛化,其中一个关键优点是,任何连续的特征和类别特征都可以很方便地加进模型中。搜索历史的处理,可以与观看历史的处理方式相类似 – 每一个查询(query)可以tokenized化成1-gram和2-gram,每一个token都可被嵌入。一旦求平均,用户的tokenized化的嵌入式query,代表了一个总结型的稠密搜索历史(summarized dense search history)。人口统计学特征(Demographic features),对于新用户的推荐很重要。用户的地域和设备信息(device),都可以被嵌入和串联。简单的二元特征和连续特征,比如用户性别,登陆态,年龄,都可以归一化到[0,1]上的实数值,直接输入到该网络。
“样本时限”特征(”Example Age” Feature)
YouTube上,每秒都有许多视频上传上来。推荐这些最新上传的新鲜(“fresh”)内容,对于YouTube产品来说相当重要。我们一致观察到:用户喜欢新鲜内容,尽管并非相关。除了简单的推荐用户想看的新视频所带来的一次传播效果外,还存在着关键的病毒式的二次传播现象。
机器学习系统经常展示出对过往行为存在一个隐式偏差(implicit bias),因为它们通常是基于历史样本的训练,来预测将来的行为。视频流行度分布是高度不稳定(non-stationary)的,我们的推荐系统会生成在视频库上的多项分布(multinomial distribution),将会影响在多周训练窗口上的平均观看似然。为了纠正这一点,我们将训练样本的age,作为一个训练特征进行feed。在serving time时,该特征被置为0(或者为一个微小的负数),反映出模型在训练窗口的最末尾正在做预测。
图4展示了该方法在选择视频上的效果。
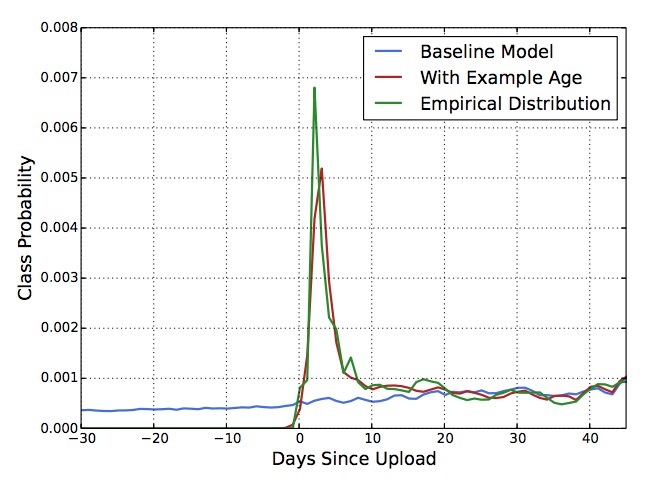
图4: 对于一个给定的视频[26],使用样本age作为特征训练的模型能够精准表示数据的上传时间和与时间相关的流行度间的关系。如果没有该特征,模型将会预测在训练窗口上的近似平均似然(baseline)。
1.3 Label和Context选择
需要重点强调的是,推荐(recommendation)通常涉及到求解一个替代问题(surrogate problem),并将结果转换成一个特殊上下文。一个经典的示例是,如果能准确预测rating,会产生有效的电影推荐[2]。我们已经发现,这种代理学习问题(surrogate learning problem)在A/B testing上很重要,但很难在离线试验中进行衡量。
训练样本需要从所有YouTube观看行为(即使嵌入在别的网站上)上生成,而非仅仅只使用我们生成的推荐的观看行为。否则,新内容将很难浮现出来,推荐系统在探索(exploitation)上将过度偏差。如果用户正通过别的方式探索发现视频,而非使用我们的推荐,我们希望能够快速通过协同过滤传播该发现给他人。 一个关键点是,提升live metrics的目的是为每个用户生成一个固定数目的训练样本,有效地在loss function上对我们的用户做平等的加权。这可以防止一少部分高活跃度用户主宰着loss。
这在一定程度上与我们的直觉相反,必须注意:为防止模型利用网站布局,以及代理问题造成的过拟合,需要隐瞒分类器信息(withhold information from the classifier)。可以考虑将一个样本看成是用户已经发起的一个查询(query): 比如“taylor swift”。由于我们的问题是预测下一个要看的视频。通过给定该信息,分类器将会预测要观看的最可能的视频,是那些出现在相应搜索结果页中关于”taylor swift”的视频。一点也不惊奇的是,如果再次生成用户最新的搜索页作为主页推荐,效果会很差。通过抛弃顺序信息,使用无顺序的词袋(bag of tokens)表示搜索query,该分类器不再直接认识到label的来源。
视频的自然消费模式,通常会导致非常不对称的co-watch概率。连播电视剧(Episodic series)通常被按顺序观看,用户经常发现,对于同一个流派(genre)中的艺术家们(artists),在关注更小众的剧之前,会从最广为流行的剧开始。因此我们发现对于预测用户的下一次观看行为上有着更好的效果,而非去预测一个随机held-out观看(a randomly held-out watch)(见图5)。许多协同过滤系统隐式地选择标签和上下文,通过hold-out一个随机item,然后通过用户历史观看中的其它item来预测它(5a)。这会泄露将来的信息(future information),并忽略任何不对称的消费模式(asymmetric consumption patterns)。相反的,我们通过选择一个随机观看(a random watch),然后“回滚(rollback)”一个用户的历史,只输入用户在hold-out label的watch之前(5b)的动作。
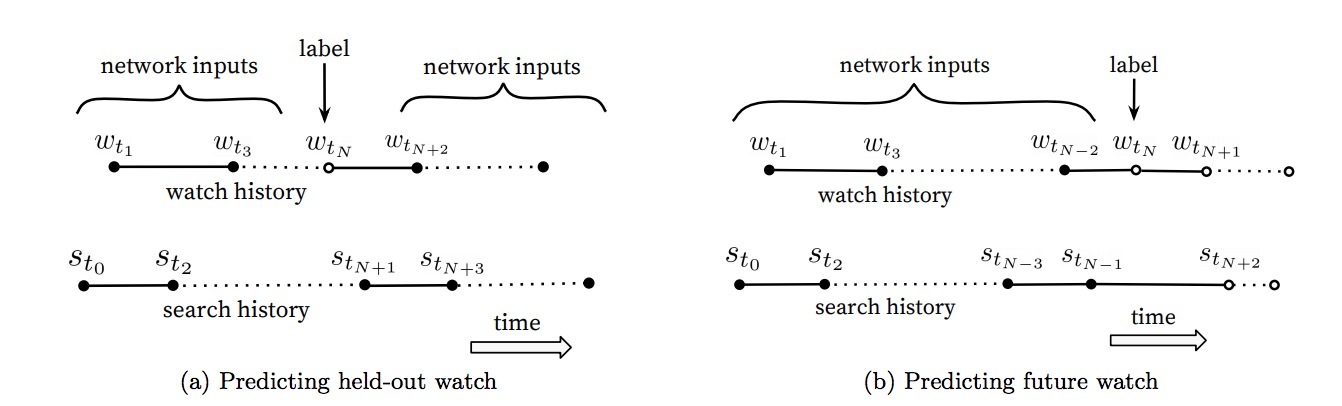
图5: 选择labels和输入上下文给模型,在离线评估时很有挑战性,但对真实的效果有巨大提升。这里,实心事件•表示网络的输入特征,而空心事件◦表示排除在外。我们发现,预测一个将来的观看(5b),在A/B test中效果更好。在(5b)中,example age通过\(t_{max}-t_N\)来表示,其中\(t_{max}\)是训练数据中观察到的最大时间。
1.4 特征和深度的试验
如图6所示,添加特征和深度,可以极大提升在holdout data上的precision。在这些试验中,1M的视频量,和1M的搜索tokens,被嵌入到256个float值上,每个都在一个最大的bag-size:50个最近的watches和50个最近的searches。softmax层输出一个在1M个视频classes、256维的多项分布(可以看成是一个独立的output video emdedding)。这些模型被训练,直接覆盖所有的YouTube用户,对应在数据上的多个epochs上。网络结构按一个公共的”tower”模式,在网络的底部是最宽的,每个后继的隐层,将单元数二等分(与图3相同)。深度为0的网络,是一个有效的线性因式分解模型,它的效果与以往的系统很相似。增加宽度(width)和深度(depth),直到增量的效果越来越小,收敛越来越难:
- Depth 0: 一个线性层,可简单地将串联层转换成与softmax相匹配的256维.
- Depth 1: 256 ReLU
- Depth 2: 512 ReLU -> 256 ReLU
- Depth 3: 1024 ReLU -> 512 ReLU -> 256 ReLU
- Depth 4: 2048 ReLU -> 1024 ReLU -> 512 ReLU -> 256 ReLU
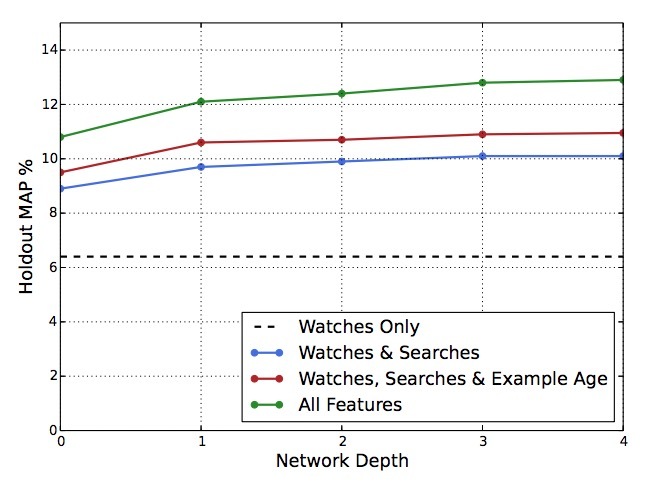
图6 在video embeddings之外的features可以提升holdout的Mean Average Precision(MAP)以及layers的深度添加了表现力,以便模通过对这些交互建模来有效使用这些额外特征
二、Ranking
Ranking的主要作用是,针对指定的UI,使用曝光数据来特化和校正候选预测(specialized and calibrate candidate predictions)。例如,用户通常会观看一个probability值较高的视频,但不大可能去点击指定主页上缩略图的曝光。在Ranking时,我们会访问许多描述视频的特征、以及视频与用户关系的特征,因为在候选集生成阶段,只有一小部分的视频被打过分,而非上百w的视频。Ranking对于聚合不同的候选源很重要,因为每个源的得分不能直接对比。
我们使用一个与候选生成阶段相似的架构的深度神经网络,它会使用logistic regression(图7)为每个视频的曝光分配一个独立的值。视频的列表接着会通过该分值进行排序,并返回给用户。我们最终的ranking objective会基于线上的A/B testing结果进行调整,但总体上是一个关于每次曝光的期望观看时长(expected watch time)的简单函数。根据ctr的排序通常会促进视频期诈现象:用户不会播放完整(标题党:点击诱惑”clickbait”),而观看时长(watch time)可以捕获更好的参与度(engagement)[13,25]。
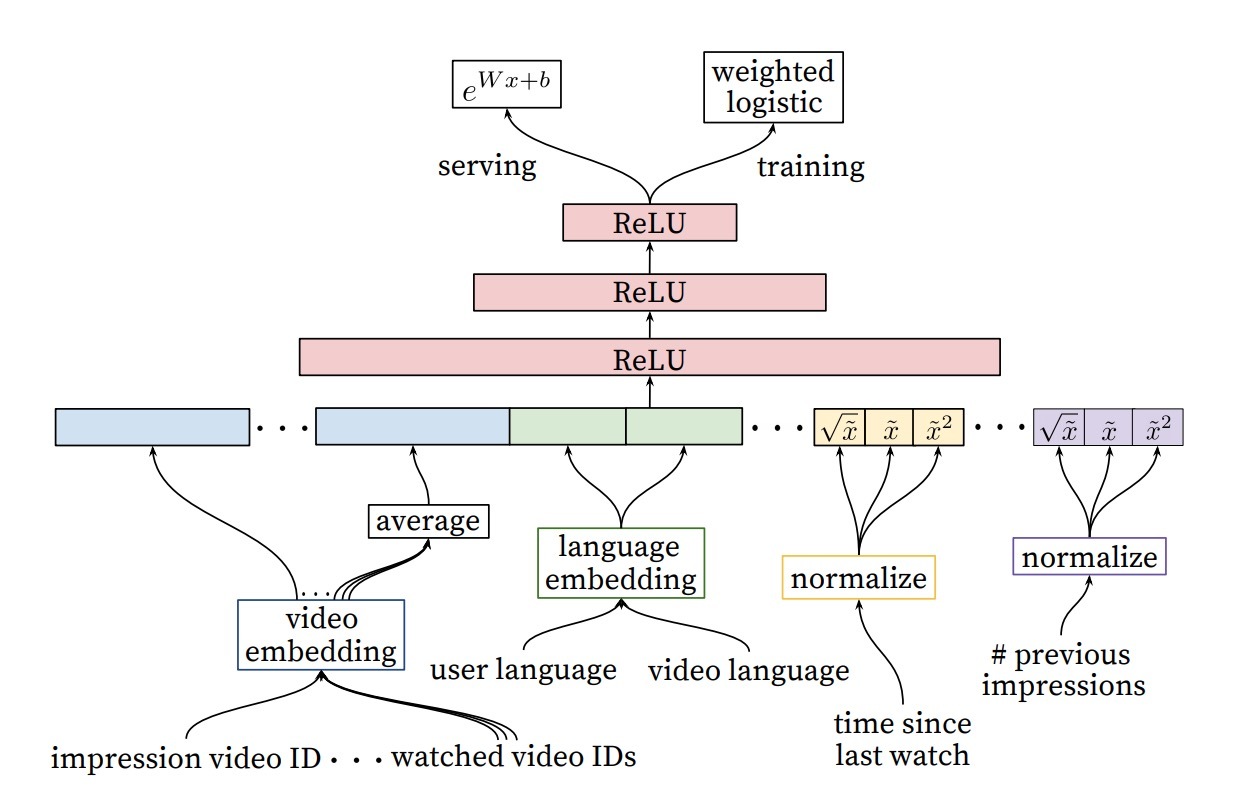
图7: 深度ranking网络架构,描绘了嵌入的类别特征(单值和多值类别都存在),与归一化的连续特征的embeddings和powers共享。所有的层都是完全连接的。惯例上,成百上千的特征都可以输入到网络中。
2.1 特征表示
我们的特征,与传统的类别特征分类,以及连续型/普通特征相互隔离开来。类别型特征,在基数上变化多样–一些是二元的(比如:用户是否登陆),而其它一些则可能有上百万种可能的值(比如:用户最新的搜索query)。特征会根据它们是否是单值(“univalent”),或者多值集合(“multivalent”),再做进一步分割。关于单值类别特征的一个示例是:被打过分的曝光视频id;而相应的多值特征可能是一批(a bag of)关于该用户已经观看过的N个视频id。我们也会根据特征是否描述了item的属性(“impression”)或者user/context的属性(”query”),将特征进行分类。Query特征在每次请求时被计算一次,而impression特征则会为每个评过分的item计算。
特征工程(Feature Engineering)
我们通常在我们的排序模型中使用成百上千的特征,它们被分成类别型和连续型特征。尽管深度学习可以缓和手工建立特征工程的负担,但我们的原始数据天然就不能直接输入到前馈神经网络中。我们仍需要花费可观的工程资源来将用户和视频数据转换成有用的特征。最主要的挑战主要在:表示用户动作的临时顺序,以及如何将这些动作与被打分的视频曝光(impression)相关联。
我们观察到,最重要的信号是,那些描述一个用户与item本身、以及其它相似item的之前交互行为,这与广告排序(randing ads)上的经验相类似。例如,考虑用户的过往历史,以及上传被打分的频道-该用户从该频道观看了多少视频?该用户在该主题上观看一个视频的最近时间是何时?这些连续特征相当强大,它们描述了用户在相关item上的过往动作,因为它们在不同的item上泛化得很好。我们也发现,很重要,从候选生成阶段(Candidate generation)到排序阶段(Ranking)以特征的形式进行信息传递,比如:哪个源被指定给该视频候选?会分配什么分值?
描述过往视频曝光的频率的特征,对于在推荐中引入“搅动(churn)”很重要(连续的请求不会返回相同的列表)。如果一个用户最近被推荐了某个视频,但没有观看它,接着模型将自然地在下一页加载时降级该曝光(impression)。Serving即时曝光和观看历史,是一项工程壮举,超出了本paper的范围,对于产生响应式推荐至关重要。
类别特征embedding (embedding categorical features)
与候选生成阶段相类似,我们使用embeddings,将稀疏的类别型特征映射到dense表征上,更适合于神经网络。每个唯一的ID空间(视频库:”vocabulary”) 都具有一个单独学到的emdedding,它维度的递增与唯一值的数目的log成比例。这些库是简单的look-up table,在训练前由整个数据一次构建。非常大的基数ID空间(视频ID或者搜索query terms)被截断,通过只包含topN,在基于点击曝光的频率排序之后。Out-of-vocabulary的值,可以简单地映射到零嵌入上(zero embdding)。正如在候选生成阶段,多值类别特征的embeddings是被平均化的,在被输入到网络之前。
重要的是,相同ID空间的类别型特征,也共享着底层的embeddbings。例如,存着单个关于视频ID的全局embedding,供许多不同的特征使用(曝光的视频ID,该用户观看的最近视频ID,作为推荐系统”种子”的视频ID等等)。尽管共享emdedding,每个特征独自输入到网络中,因此,上面的层可以学到每个特征的特定表征(representation)。共享嵌入(sharing emdeddings)对于提升泛化、加速训练、及减小内存等相当重要。绝大多数模型参数都是在这些高基数(high-cardinality)的embedding空间中 - 例如,100w的ID,嵌入到32维的空间上,与2048个单元的宽完全连接层多7倍多的参数。
归一化连续特征(Normalizing Continuous Features)
众所周知,神经网络对于输入的归一化和分布是很敏感的[9],其它方法(比如:决策树ensembles)对于独立特征的缩放(scaling)是稳定的。我们发现,对连续特征进行合理的归一化,对于收敛来说很重要。连续特征x,具有分布f,被转换成x^,通过对值进行归一化,比如:特征平均地分布在[0,1)上使用累积分布,$ \hat{x}=\int_{-\infty}^{x}df $。该积分与特征值的分位数的线性插值相近似,在训练开始这,在所有数据上的单个pass中计算。
另外,原始的归一化特征$ \hat{x} $,我们也输入$ \hat{x}^2 $和$ \sqrt{\hat{x}} $,给网络更多有表现力的阶,通过允许它,很容易形成特征的super-linear和sub-linear function。我们发现:输入连续特征的阶,可以提升离线的accuracy。
2.2 对期望的观看时长建模
我们的目标是,给定训练样本:包含正例(曝光的视频被点击)和负例(曝光的视频没被点击),来预测期望的观看时间。正例可以解释成:该用户花费观看该视频的时间量。为了预测期望的观看时间,我们出于该目的,开发并使用加权logistic regression技术。
该模型的训练通过logistic regression和cross-entropy loss进行(图7)。然而,正例(被点的)的曝光,会由视频所观察到的观看时间进行加权。所有负例(未点击)的曝光,都使用单位加权。这种方式下,通过logistic regression学到的差异(odds)是:$ \frac{\sum{T_i}}{N-k} $,其中:
- N是训练样本的数目
- k是正例曝光的数目
- Ti是第i个曝光的观看时间
假设,正例曝光很小(真实情况就这样),学到的差异(odds)近似为:\(E[T](1+P)\)
- 其中P是点击概率
- E[T]是该曝光所期望的观看时间
由于P很小,该乘积近似为E[T]。为便于推理,我们使用指数函数\(e^x\)作为最终的激活函数,来产生这些odds,来近似估计期望的观看时长。
2.3 隐层的试验
表1展示了,我们在下一天的holdout数据上,使用不同的隐层配置所获得的结果。Value展示了每个配置(”加权,每用户的loss”),包括正例和负例,曝光展示给单个页内的某个用户。我们首先使用我们的模型对两种曝光进行打分。如果负例的曝光接受到更高的分值,那么我们会认为,正例的观看时长为:误预测的观看时长(mispredicted watch time)。加权的每用户loss,就是误预测的观看时间的总量,作为一个分数,在heldout曝光pair上的一个总观看时长。
这些结果展示了隐层的width的增加会提升效果,同样depth的增加也会。然而,服务器的CPU时间需要进行权衡下。该配置是一个1024-wide的ReLU,后面跟着一个512-wide的ReLU,再接一个256-wide的ReLU,会给我们最佳的结果,而允许我们在CPU预算范围内。
对于1024->512->256的模型,我们尝试只输入归一化连续特征,而不输入它们的powers,会增加0.2%的loss。相同的隐层配置,我们也训练了一个模型,其中正例和负例的加权相同。不令人惊讶,观看时间加权loss会增加4.1%之多。

表1:在基于观看时长加权的pairwise loss上,更深和更宽的隐ReLU层的效果