我们来看下Feng Niu等人提出的《Hogwild!: A Lock-Free Approach to Parallelizing Stochastic Gradient Descent》。
#
SGD是许多机器学习任务的一种流行优化算法。之前的许多研究者都提出了并行化SGD的schemes,但都需要影响性能的内存锁和同步机制。本文主要展示了使用新的理论分析、算法和Hogwild!实现,它允许处理器以相互覆写(overwriting)的方式访问共享内存。当相关优化问题是sparse时,大多数梯度更新(gradient updates)只会修改决策变量的很小一部分,接着Hogwild!可以达到一个近似最优的收敛率。实验结果表明Hogwild!的效果要比使用锁版本的要好一阶。
1.介绍
由于较小的内存占用、对噪声健壮、以及快速的learning rate,SGD被证明是很适合数据密集(data-intensive)的机器学习任务。然而,SGD的扩展性受它的顺序型(serial)特性限制;很难并行化。随着不贵的多核处理器和超大型机器出现,大规模(web-scale)数据集启发着研究者们为SGD开发了许多并行化schemes。许多大型数据集当前在类MapReduce并行处理框架上进行预处理,在并行SGD上的最近的许多工作都主要关注在MapReduce实现。MapReduce是一个很强大的工具,但它不适合online、数值密集的数据分析。迭代型计算很难在MapReduce上表示,并且确保容错的开销可能会产生更大的吞吐量。Google研究者建议其它系统(例如:Dremel)比MapReduce更适合。
对于一些数据集,数据的绝对规模(sheer size)预示着是否需要一个机器集群。然而,存在一个问题,在合适预处理后,对于统计分析所需要的数据,可能仍包含上兆(TB)字节。而对于一些问题,并不需要上百台集群,可以使用单个便宜的工作站就行。多核系统具有极大的性能优点:包括:
- 1)低延迟、高吞吐,共享主要内存:这样的系统中一个处理器可以以超过12GB/s的速率读写共享物理内存,延迟只有数10ns
- 2)跨多磁盘高带宽(high bandwidth off multiple disks):一个上千美金的RAID可以以超过1GB/s的速率将数据导入到主存中。而作为对比,由于存在容错机制上频繁的checkpoint,一个典型的MapReduce setup会以低于数十MB/s的速率读取数据。多核系统可以达到高速率,瓶颈在处理器间的同步(或locking)上。因而,为了能在多核机器上允许可扩展的数据分析,一些好的解决方案必须能最小化加锁开销。
在本paper中,我们提出了一种称为”HOGWILD!”的简单策略来消除与锁相关的开销:无锁方式并行运行SGD。在HOGWILD中,各处理器被允许公平访问共享内存,并且能随意更新内存私有变量(individual components)。这样的lock-free scheme看起来注定会失败,因为处理器可以覆盖写(overwrite)其它的处理器的操作。然而,当数据处理是稀疏时,这意味着单独的SGD steps只会修改决策变量的一小部分,我们展示了内存覆盖写(memory overwrites)很少发生,并且当它们发生时只会将很少的错误引入到计算中。我们展示了,理论上和实验上一个近似的与处理器数成线性加速,这通常发生在稀疏学习问题上。
在第2节,我们对稀疏概念公式化,它足够保障这样的加速,并提供了在分类问题、协同过滤、图分割上关于稀疏机器学习问题的示例。我们的稀疏性概率允许我们提供关于线性加速的理论保证。作为我们分析的一个副产品,我们也派生了常数步长(constant stepsizes)收敛率的算法。我们展示了使用constant stepsize schemes的1/k收敛率是可能的,它实现了一个在常数时间上的指数级补偿(backoff)。该结果本身挺有意思的,它展示了不必满足于\(1/\sqrt{k}\)来保证在SGD算法上的健壮性。
实际上我们发现,无锁版的计算性能要超过我们的理论保证。我们实验上比较了lock-free SGD,以及其它最近提出的方法。结果展示了所有提出内存锁(memory locking)的方法,比起lock-free版本要慢很多。
2.稀疏可分的cost functions
我们的目标是,最小化一个函数:\(f: X \subseteq R^n \rightarrow R\):
\[f(x)= \sum\limits_{e \in E} f_e(x_e)\]
…(1)
这里,e表示了\(\lbrace 1, ..., n \rbrace\)的一个小的子集,其中\(x_e\)表示向量x在坐标索引e上的值。在我们的lock-free方法中的关键点是,与许多机器学习问题相关的cost functions是稀疏的(sparse)的,\(\mid E \mid\)和n都非常大,但每个单独的\(f_e\)只在x的一小部分成分起作用。也就是说,每个子向量\(x_e\)只包含了x的一少部分成分(components)。
(2.1)的cost function引入了一个hypergraph:\(G=(V,E)\),它的节点是x的单个元素。每个子向量\(x_e\)相当于在图\(e \in E\)中引入一条边,它包含了节点的一些子集。以下的示例展示了该概念。
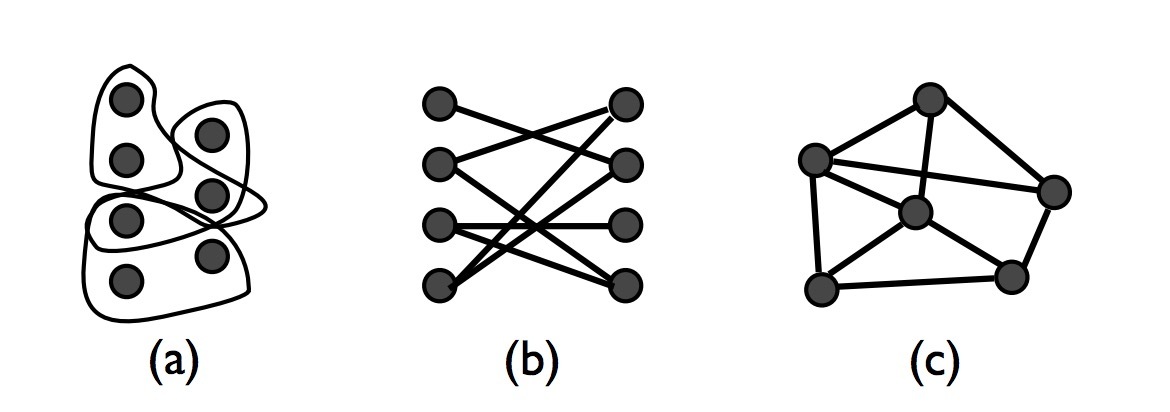
图1: 由cost function引入的样本图. (a) 一个sparse SVM会引入一个hypergraph,其中每个hyperedge对应一个样本 (b) 一个矩阵补全示例,它在行与列间引入了一个二分图(bipartite graph),如果有出现一个entry,那么两个节点间就有一条edge (c) 在graph-cut问题中的hypergraph就是一个简单图,它的切分就是我们想找的
2.1 Sparse SVM
假设我们的目标是,拟合一个SVM:数据对为\(E = \lbrace (z_1,y_1), ..., (z_{\mid E \mid}, y_{\mid E \mid}\rbrace\)。其中\(z \in R^n\)和y是对于每个\((z,y) \in E\)的一个label:
\[minimize_x \sum\limits_{\alpha \in E} max(1 - y_{\alpha} x^T z_{\alpha}, 0) + \lambda \| x\|_{2}^2\]
…(2.2)
其中,我们知道一个先验(priori)是,样本\(z_{\alpha}\)是非常稀疏的。为了以(2.1)的形式编写该cost function,假设\(e_{\alpha}\)表示该组件在\(z_{\alpha}\)中是非零的,并假设\(d_u\)表示在第u(u=1,2,…,n)维上非零的训练样本数。可以将(2.2)改写成:
\[minimize_x \sum\limits_{a \in E} (max(1-y_ax^T z_a, 0) + \lambda \sum\limits_{u \in e_a} \frac{x_u^2}{d_u})\]
…(2.3)
在(2.3)中的求和只依赖通过集合\(e_a\)索引的x的components。
2.2 矩阵补全(Matrix Completion)
在矩阵补全问题上,我们从索引集合E中提供了一个低秩的、\(n_r \times n_c\)的矩阵X的entries。这种问题在协同过滤(CF)、欧氏距离估计、聚类中常出现。我们的目标是,从该数据的稀疏样本中重构Z。一种流行的启发法(heuristic)可以将Z的估计恢复成:以下最小化公式得到的一个\(LR^*\)的因子乘积:
\[minimize_{L,R} \sum\limits_{(u,v) \in E} (L_u R_v^* - Z_{uv})^2 + \frac{\mu}{2} ||L||_F^2 + \frac{\mu}{2} ||R||_F^2\]
…(2.4)
其中,L是\(n_r \times r\), R为\(n_c \times r\),\(L_u(对应R_v)\)表示L(对应:R)的第u(对应:vth)行。为了将该问题放入到稀疏形式,如(2.1)所示,我们将(2.4)编写成:
\[minimize_{L,R} \sum_{(u,v)\in E} \lbrace (L_uR_v^* - Z_{uv})^2 + \frac{\mu}{2|E_{u-}|} ||L_u||_F^2 + \frac{\mu}{2|E_{-v}|} ||R_v||_F^2\rbrace\]
其中:\(E_{u-}= \lbrace v: (u,v) \in E \rbrace\),\(E_{-v} = \lbrace u: (u,v) \in E \rbrace\)
2.3 Graph Cuts
略
2.4 结论
在所有三个示例中,在一个特定项\(f_e\)上所涉及的components数目,对于所有总条目数来说只占很小比例。我们将该概率进行公式化,定义了以下的关于hypergraph G的统计:
\[\Omega := max_{e \in E} |e|\]
\[\Delta := \frac{max_{1 \le v \le n} |\lbrace e \in E: v \in e \rbrace| }{|E|}\]
\[\rho := \frac{max_{e \in E} | \lbrace \hat{e} \in E: \hat{e} \cap e \neq \emptyset \rbrace |}{|E|}\]
…(2.6)
量\(\Omega\)可以简单量化hyper edges的size。\(\rho\)决定了与任意给定edge交叉的edges最大比例。\(\Delta\)决定了与任何变量交叉的edges的最大比例。\(\rho\)是一个关于hypergraph稀疏度的衡量,其中\(\Delta\)决定着节点的正则化(node-regularity)。对于我们的例子,我们可以做出以下关于\(\rho\)和\(\Delta\)的观察:
- 1.Sparse SVM。\(\Delta\)是在一个样本中出现的任何特征的最大频率,\(\rho\)决定着hypergraph是如何聚类的。如果一些特征在整个数据集上很常见,那么\(\rho\)会与某一个很接近。
- 矩阵补全(Matrix Completion):如果我们假设,提供的样本是随机均匀抽样的,我们可以看到超过\(n_c log(n_c)\)个样本,接着\(\Delta \approx \frac{log(n_r)}{n_r}\)和\(\rho \approx \frac{2log(n_r)}{n_r}\) 。它会遵从一个彩票收集问题(coupon collector argument)。
- 3.Graph Cuts。 \(\Delta\)是由\(\mid E \mid\)划分的最大度(degree),\(\rho\)至少为\(2\Delta\)。
我们现在描述了一个简单的protocol,当\(\Omega, \Delta, \rho\)都很小时,它会在处理器数上达到一个线性加速。
3.Hogwild!算法
这里我们讨论并行化处理setup。我们假设,一个具有p个处理器的共享内存模型。决策变量x可以被所有处理器访问。每个处理器可以读取x,也可以为x贡献一个更新向量(update vector)。向量x存储在共享内存中,我们假设,component-wise加法操作是原子的,也就是说:
\[x_v \leftarrow x_v + \alpha\]
对于一个标量a和\(v \in \lbrace 1,...,n \rbrace\),该操作可以被任意处理器原子执行。该操作在大多数现代硬件上不需要一个独立的锁结构:这样的一个操作在GPUs和DSPs上是单个原子指令,它在像Intel Nehalem这样的专有目的多核处理器上可以通过一个compare-and-exchange操作来实现。相反的,一次更新多个components的操作需要一个辅助锁(auxiliary locking)结构。

每个处理器接着按照算法1的流程。为了完整描述该算法,假设:
- \(b_v\)表示在\(R^n\)中的标准基元素(standard basis elements)之一,其中v的范围为1, …, n。也就是说,\(b_v\)在第v个component上等于1, 否则为0. 假设\(P_v\)表示在坐标v上的欧几里德投影矩阵,例如:\(P_v = b_v b_v^T\)。其中\(P_v\)是一个对角矩阵,它在第v个对角上为1,否则为0。
- \(G_e(x) \in R^n\)表示函数\(f_e\)与 \(\mid E \mid\)相乘的一个梯度或者子梯度。也就是说,我们将\(f_e\),从坐标e上的一个函数扩展为\(R^n\)上所有坐标上,通过忽略下标e来得到。那么:
\[|E|^{-1} G_e(x) \in \partial f_e(x)\]
这里,在\(\neg e\)的组件上的\(G_e\)等于0.使用一个稀疏表示,只需要知道通过e索引的components中的x的值,我们就可以计算\(G_e(x)\)。注意,从E进行平均随机抽样得到e(uniform random sampling),我们具有:
\[E[G_e(x_e)] \in \partial f(x)\]
在算法1中,每个处理器会均匀地随机抽取一个项\(e \in E\),计算在\(x_e\)上\(f_e\)的梯度,接着:
\[x_v \leftarrow x_v - \gamma b_v^T G_e(x), v \in e\]
(3.1)
重要的是,注意,该处理器只修改通过e索引的变量,在\(\neg e\)中(e之外)的保持不变。
- \(\gamma\): 我们假设,stepsize \(\gamma\)是一个固定的常数。
- \(x_j\): 尽管这些处理器并不知道任何其它处理器是否已经修改了x,我们定义\(x_j\)是决策变量x在j执行更新后的状态(state)。由于两个处理器可能会在同时写入x,我们需要注意该定义,但我们会通过随机方式来简单断绝关系。注意,\(x_j\)通常使用一个旧的梯度进行更新,它基于x的一个在多个时钟周期前读取的值。我们使用\(x_{k(j)}\)来表示用于产生状态\(x_j\)的用于计算梯度或次梯度的决策变量值。
在下文中,我们提供了这种异步、增量梯度算法收敛的条件。另外,我们也展示了,如果通过f引入的hypergraph是同性的(isotropic)并且稀疏的,那么,该算法的收敛几乎与它的serial版本具有相同数目的梯度计算steps。由于我们以并行方式运行并且无锁,这意味着我们会得到一个与处理器数目成接近线性关系的加速。
注意:下标i,j,k指的是迭代数,v和e指的是components或者components的子集。
4.Lock-Free Parallelism的Fast Rates
我们接着讲述Hogwild!算法的理论分析。为了让这个分析更易理解,我们假设,我们会使用以下的“有放回(with replacement)”过程进行更新:每个处理器会均匀随机抽样一条边e,并计算该决策变量的当前值上的\(f_e\)的一个次梯度。
\[x_v \leftarrow x_v - \gamma |e| b_v^T G_e(x)\]
注意,该stepsize比(3.1)的step要更多一个因子\(\mid e \mid\)。注意,该更新完全等价于:
\[x \leftarrow x - \gamma |e| P_v^T G_e(x)\]
…(4.1)
该概念对于下面的分析更方便。
该有放回(with replacement)scheme假设:一个梯度被计算,那么它的components中只有一个元素被用于更新该决策变量。这样的一个scheme计算很浪费,因为该梯度的components其它部分携带着关于对cost function进行递减的信息。因此,实际上以及在我们的实验中,我们会执行该过程的一个修改版本。在每个epoch的开始处,我们将这些边进行无放回(without replacement)划分到所有处理器上。这些处理器接着在它们各自的队列上,对每条边的所有components执行完全更新(full updates)。然而,我们需再次强调的是,我们不会实现对任何变量的任何锁机制。我们不会分析该“无放回(without replacement)”过程,因为在任何无放回抽样模型中,没人可以对SGD进行可控分析。实际上据我们所知,无放回抽样的所有分析,会产生与一个标准的次梯度下降算法(它会采用(2.1)完全梯度的steps)相当的rates。也就是说,这些分析建议:无放回抽样需要一个\(\mid E \mid\)因子,因而比有放回抽样需要更多的steps。实际上,这种糟糕的情况从不会观察到。事实上,在机器学习中更明智的做法是,在SGD上进行无放回抽样,实际效果要好于有放回的形式。
为了说明我们的理论结果,我们必须描述一些工程量,它对于我们的并行化SGD scheme的分析很重要。为了简化该分析,我们假设,在(2.1)中的每个\(f_e\)是一个convex函数。我们假设f的Lipschitz连续微分,会使用Lipschitz常数L:
\[|| \nabla f(x') - \nabla f(x) || \le L || x' -x ||, \forall x', x \in X\]
…(4.2)
我们也假设,f是具有系数c很强的convex性质。这意味着:
\[f(x') \ge f(x) + (x'-x)^T \nabla f(x) + \frac{c}{2} ||x'-x||^2, \forall x', x \in X\]
…(4.3)
其中,f具有很强的convex性,存在一个唯一的最小解\(x_*\),我们表示\(f_* = f(x_*)\)。我们额外假设,存在一个常数M,使得:
\[|| G_e (x_e) ||_2 \le M,almost ∀ x \in X\]
…(4.4)
我们假设,\(\gamma c < 1\)。(实际上,当\(\gamma c > 1\),普通的梯度下降算法也会离散)
我们的主要结果通过以下进行归纳:
命题(Proposition) 4.1
假设在算法1中,当一个梯度被计算时,与它在step j被使用时,两者间的lag——\(j - k(j)\),总是小于或等于\(\tau\),即\(j - k(j) \lt \tau\),那么\(\gamma\)被定义为:
\[\gamma = \frac{\vartheta \epsilon c}{2 L M^2 \Omega(1+6\rho \tau + 4\tau^2 \Omega \Delta^{1/2})}\]
…(4.5)
对于一些 \(\epsilon > 0\)和\(\vartheta \in (0, 1)\)的情况。定义\(D_0 := \| x_0 - x_* \|^2\), 并让整数k满足:
\[k \gt \frac{2 L M^2 \Omega (1+6\tau \rho + 6 \tau^2 \Omega \Delta^{1/2}) log(L D_0/\epsilon)}{c^2 \vartheta \epsilon}\]
…(4.6)
那么在关于x的k个compoments更新后,我们有\(E[f(x_k) - f_*] \lt \epsilon\)
在该case中,\(\tau = 0\),它可以精准减小到由serial SGD达到的rate。如果\(\tau = o(n^{1/4})\),\(\rho\)和\(\Delta\)通常为\(o(1/n)\),可以达到一个相同的rate。在我们的setting中,\(\tau\)与处理器数据成比例,只要处理器数目小于\(n^{1/4}\),我们就可以获得在线性rate的循环。
我们在附录证明了命题4.1的两个steps. …(略)
注意,在(4.6)中\(log(1/\epsilon)\),对于一个常数stepsize的SGD scheme,我们的分析接近提供了一个1/k 的收敛率,不管是顺序版本(serial)还是并行版本(parallel)。另外,注意,我们的收敛率相当robust;我们会为曲率f的低估花费线性时间。相反的,, Nemirovski等人展示了当stepsize与迭代数成反比时,高估的c可能会产生指数下降(n exponential slow-down)。我们转向展示,我们可以消除(4.6)的log项,通过一个稍微复杂些的方式,其中stepsize会在多次迭代后缓慢递减。
5.Robust 1/k rates
假设,对于算法1, 我们使用stepsize \(\gamma < 1/c\)运行固定数目K次的梯度更新。接着,我们等待线程合并结果,通过一个常数因子\(\beta \in (0,1)\)来对\(\gamma\)进行reduce,接着运行\(\beta^{-1} K\)轮迭代。从某种意义上说,该piecewise constant stepsize protocol近似成一个1/k衰减的diminishing stepsize。以下分析与之前工作的主要不同之处是,对比开始非常大的stepsizes,我们的stepsize总是比1/c小。总是使用小的stepsizes运行,允许我们避免可能的指数级递减(exponential slow-downs),它发生于标准的diminishing stepsize schemes中。
为了更精准,假设\(a_k\)是任意满足下述条件的实数的序列:
\[a_{k+1} \le (1 - c_r \gamma)(a_k - a_{\infty}(\gamma)) + a_{\infty}(\gamma)\]
…(5.1)
其中,\(a_{\infty}\)是一些关于\(\gamma\)的非负函数,它满足:
\[a_{\infty} \le \gamma B\]
其中\(c_r\)和B是常数。这种递归是许多SGD收敛证明的基础,其中\(a_k\)表示在k轮迭代后的最优解的距离。我们会在附录中为Hogwild!选择合适的常数。我们也会在下面讨论对于标准的SGD算法的这些常数。
在\(\gamma\)上的依赖,对于下面的情况很有用。将(5.1)化解开:
\[a_k \le (1-c_r \gamma)^k (a_0 - a_{\infty}(\gamma)) + a_{\infty}(\gamma)\]
假设我们希望该量(quantity)要比\(\epsilon\)要小。两项都要小于\(\epsilon/2\)是充分的。对于第二项,这意味着:
\[\gamma \le \frac{\epsilon}{2B}\]
…(5.2)
对于第一项,我们需要:
\[(1-\gamma c_r)^k a_0 \le \epsilon / 2\]
它持有:
\[k \ge \frac{log(2a_0 / \epsilon)}{\gamma c_r}\]
…(5.3)
通过(5.2),我们应选择:\(\gamma = \frac{\epsilon \theta}{2B}\),其中\(\theta \in (0, 1]\)。使用(5.3)进行组合,k满足
\[k \ge \frac{2B log(2a_0/\epsilon)}{\theta \epsilon c_r}\]
在k轮迭代后,我们会有\(a_k \ge \epsilon\)。这几乎可以提供给我们一个1/k的rate,模上\(log(1/\epsilon)\)因子。
为了消除log因子,我们可以实现一个backoff scheme,其中,我们在多轮迭代后通过一个常数因子来减小stepsize。这种backoff scheme有两个phases:第一个阶段将包含以一个指数的rate收敛到 \(x_*\)的平方半径(它比\(\frac{2B}{c_r}\)要小)的球。接着,我们将通过对stepsize进行微调(shrinking)收敛到\(x_*\)。
为了计算到达在球体内所需的迭代次数,假设初始stepsize选择为:\(\gamma = \frac{\theta}{c_r} (0< \theta <1)\)。stepsize的选择保证了\(a_k\)会收敛到\(a_{\infty}\)。我们使用参数\(\theta\)来展示,我们不需要做多少调整,即可在我们的算法中得到最优stepsize(例如:\(\theta=1\))的下限。使用(5.3),我们可以发现:
\[k \ge \theta^{-1} log(\frac{a_0 c_r}{\theta B})\]
(5.4)
k轮迭代后足够收敛到该球体。注意,这是一个线性rate的收敛率。
现在,假设\(a_0 < \frac{2\theta B}{c_r}\)。假设在每一轮通过一个因子\(\beta\)来减小stepsize。这会导致通过一个因子\(\beta\)来减小已经达到的\(\epsilon\)。从而,在\(log_{\beta} (a_0 / \epsilon)\)轮迭代后,我们的accuracy会是\(\epsilon\)。迭代的总轮数接着会是公式(5.3)的各项求和,其中,\(a_0\)通过之前的epoch被设置成已经达到的半径,\(\epsilon\)被设置成\(\beta \times a_0\)。从而,对于epoch数v,初始距离是\(\beta^{v-1} a_0\),最终的半径为\(\beta^v\)。
5.1 顺序型(serial)SGD的结论
我们对比了constant step-size protocol,以及在第k轮迭代将stepsize设置为\(\gamma_0 / k\)(应用在等式(2.1)的标准顺序型(serial)增量梯度算法的一些初始step size \(\gamma\))。 Nemirovsk[23]等人展示了到最优解的期望平方距离,\(a_k\), 满足:
\[a_{k+1} \le (1-2c\gamma_k)a_k + \frac{1}{2} \gamma_k^2 M^2\]
我们可以将该递归式放到公式(5.1)中,通过设置:\(\gamma_k = \gamma, c_r = 2c, B= \frac{M^2}{4c}, a_{\infty} = \frac{\gamma M^2}{4c}\)。
[23]的作者演示了一个大的step size: \(\gamma_k = \frac{\theta}{2ck}, \theta > 1\) 可以产生一个边界:
\[a_k \le \frac{1}{k} max \lbrace \frac{M^2}{c^2} \prod \frac{M^2}{c^2} \prod \frac{1}{k - \vartheta ^{-1} log(\frac{4D_0 c^2}{\vartheta M^2})} \rbrace\]
该边界可以通过将这些算法参数插入到公式(5.6)中、并使得\(D_0=2a_0\) 来得到。
注意,两个边界渐近的在M、c、k上有相同的依赖,表达式:
\[\frac{2/\beta}{4(1-\beta)}\]
当\(\beta \approx 0.37\)是最小的,等于1.34. 表达式:
\[\frac{\theta^2}{4\theta - 4}\]
当\(\theta=2\)时是最小的,等于1. 因此,产生的常数在constant stepsize protocol中当所有其它参数设置为最优时,会稍微变差些。然而,如果\(D_0 \gt M^2/c^2\),那么1/k protocol的error会与\(D_0\)成比例,但我们的constant stepsize protocol仍在初始距离上只有一个log依赖。再者,constant stepsize scheme在对曲率参数c高估上会更健壮些(robust)。而对于1/k protocol,如果你高估了曲率(对应于\(\theta\)的一个小值),你会获得较慢的收敛率。简单的,在[23]中的一维样本展示了,\(\theta=0.2\)可以生成一个\(k^{-1/5}\)的收敛率。在我们的scheme中,\(\vartheta=0.2\)会通过一个因子5来简单增加迭代数目。
在[23]中提出的fix,会渐近式产生比\(1/\sqrt{k}\)更慢的收敛率。值得注间的是,我们不需要满足于这些更慢的收敛率,仍可以在1/k rates达到健壮收敛。
5.2 补偿(backoff) scheme的并行化实现
该scheme会为HOGWILD!产生一个1/k的收敛率,只有在每一轮(round/epoch)迭代结果时发生同步开销。当为Hogwild实现一个backoff scheme时,处理器间会在何时reduce stepsize上达到一致。一个简单的策略是,在所有的处理器上以一个固定数目的迭代次数运行,等待所有线程完成,然后在一个主线程上全局进行reduce stepsize。我们注意到,它可以为这些线程消除合并的需要,通过发送带外信息(out-of-band messages)给处理器来发送何时对\(\gamma\)进行reduce的信号来完成。这会让理论分析变得复杂,因为有可能有例外:当不同处理器以不同stepsizes运行时,但实际上可以允许某一个避免同步开销。我们不会实现该scheme,因此不会更进一步分析该思想。
6.相关工作
大多数并行化SGD的schemes是 Bertsekas and Tsitsiklis[4]提出的变种。实际上,在[4]中,他们描述了通过主从方式(master-worker)跨多机计算来使用stale gradient updates(老的梯度更新),也描述了不同处理控制访问决策变量的特定组件的settings。他们证明了这些方法的全局收敛,但没有提供收敛率。这些作者已经展示了SGD收敛率对多种模型是健壮的。
我们也注意到,constant stepsize protocols结合backoff过程在SGD实践中是权威,但在理论上不是。一些理论性工作至少已经展示了这些protocols的收敛性,可以在[20, 28]中找到。这些工作并没有确立上述的1/k rates。
最近,许多parallel schemes被提出。在MapReduce中,Zinkevich等提出在不同的机器上运行许多SGD实例,然后对output进行平均[30]。尽管作者宣称该方法可以同时reduce他们的估计方差(variance)和整体偏差(bias),在我们的实验中,对于我们关注的那类问题来说,该方法的效果不能胜过serial scheme。
通过一个distributed protocol对梯度求平均的schemes也由许多作者提出[10, 12]。而这些方法也可以达到线性加速,但他们很难在多核机器上有效实现,因为他们需要大量通信开销。分布式梯度求平均需要在多核之间进行消息传递,多个核需要频繁进行同步,以便计算合理的梯度平均。
与我们工作最接近的是round-robin scheme,它由Langford[16]提出。在该scheme中,多个处理器会排好序,然后按顺序更新决策变量。其中为进行写操作对内存上锁时所需时间,对比起梯度计算时间来说忽略不计,该方法会产生一个线性加速,因为在梯度中的lag所产生的errors并不会太剧烈。然而,我们注意到,在许多机器学习应用中,梯度计算时间是非常快的,我们现在证明了在许多应用中,Hogwild!的效果要胜过round-robin方法一个阶的量级。
7.实验
我们在许多机器学习任务上运行了数值型实验,并对比了[16]中的round-robin方法,它在Vowpal Wabbit[15]中有实现。我们将该方法简写为RR。为了公平,我们手工编码RR以便接近等同于Hogwild!方法,唯一的区别是,他们如何更新梯度的scheme不同。与Vowpal Wabbit软件中的RR的一个明显不同是,我们优化了RR的locking和signaling机制,以便使用spinlocks和busy waits(这对于通用signaling来说没有必要去实现round robin)。我们验证了对于我们讨论的问题,该optimization在wall clock time是会产生多一个阶。
我们也比较了一个称为AIG的模型,它可以看成是RR和Hogwild!间的一个折中。AIG会运行一个等同于Hogwild!的protocol,但它会锁住在e中的所有变量(在算法1中第4行的for loop的前后)。我们的实验演示了该细粒度的locking会产生不希望看到的速度减慢。
所有实验都以C++进行编码,并运行一个相同的配置:一个dual Xeon X650 CPUs(6 cores x 2超线程)机器,它具有24GB的RAM,software RAID-0超过7, 2TB Seagate Constellation, 7200RPM disks。kernel为Linux 2.6.18-128. 我们使用的内存不超过2GB。所有训练数据都存储在一个7-disk raid 0上。我们实现了一个定制的文件扫描器来演示从磁盘将数据集读取到共享内存的速度。这允许我们从raid读取的速率达到接近1GB/s。
所有的实验均使用一个constant stepsize \(\gamma\),它在每次整个训练集pass后会通过一个因子\(\beta\)进行衰减。我们使用20个这样的passes运行所有的实验,尽管更少的epochs通常就能达到收敛。我们的结果表明,对于learning rate \(\gamma\)收敛的最大值,我们会使用\(\beta = 0.9\)的吞吐量。我们注意到,结果与更大范围\((\gamma,\beta)\) pairs看起来相似,所有这三种并行化schemes的train erros和test errors都在相互很小的误差内。在分类问题会在第2节描述。
Sparse SVM。我们在Reuters RCV1数据集上测试了我们的sparse SVM实现,使用二分类任务CCAT。它具有804414条样本,划分为:23149训练样本,781265测试样本,存在47236个特征。我们在我们的实验中交换了训练集和测试集,以演示并行多核算法的可扩展性。在本例上,\(\rho = 0.44, \Delta = 1.0\),Hogwild中大值通常会产生一个badcase。在图3a中,我们看到,Hogwild可以达到3倍加速,而RR会随着线程的增加而变差。确实,对于快速梯度,RR要比顺序实现(serial implement)还差。
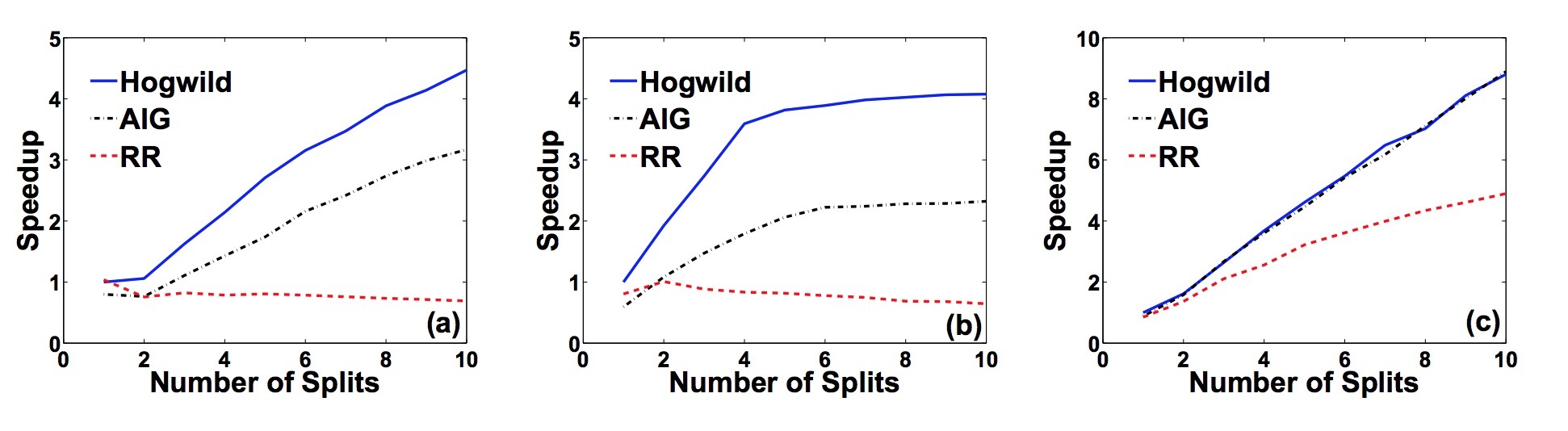
图3: 对于不同(a) RCV1 (b) Abdomen (c)DBLife,总CPU时间 vs. 线程数
对于该数据集,我们也实现了在[30]中的方法,它会以并行并对输出求平均方式运行多个SGD。在图5b中,我们展示了跨并行线程并在每个pass结尾进行ensemble求平均的方式的train error。我们注意到,线程只在计算的最后需要通信,每个并行线程会在每个pass中接触到每条数据样本。因而,10线程会比顺序版本(serial version)运行10倍(更多)的梯度计算。这里,不管是serial版本还是10个实例的版本,error是相同的。我们可以在该问题上下结论,并行求平均的scheme并没有优点。
矩阵补全(Matrix completion)。我们在三个非常大的matrix比赛问题中运行Hogwild!。Netflix Prize数据集具有17770行,480189列,以及100198085个条目。KDD Cup 2011(task 2)数据集具有624961行,1000990列,252800275个条目。我们也人工生成了一个低秩矩阵,它的rank=10, 1e7个行和列,2e9个条目。我们把该数据集称为”Jumbo”。在人工生成的样本中,\(rho\)和 \(\Delta\)都在1e-7. 这些值与\(rho\)和 \(\Delta\)都在1e-3阶上的真实数据集形成鲜明对比。
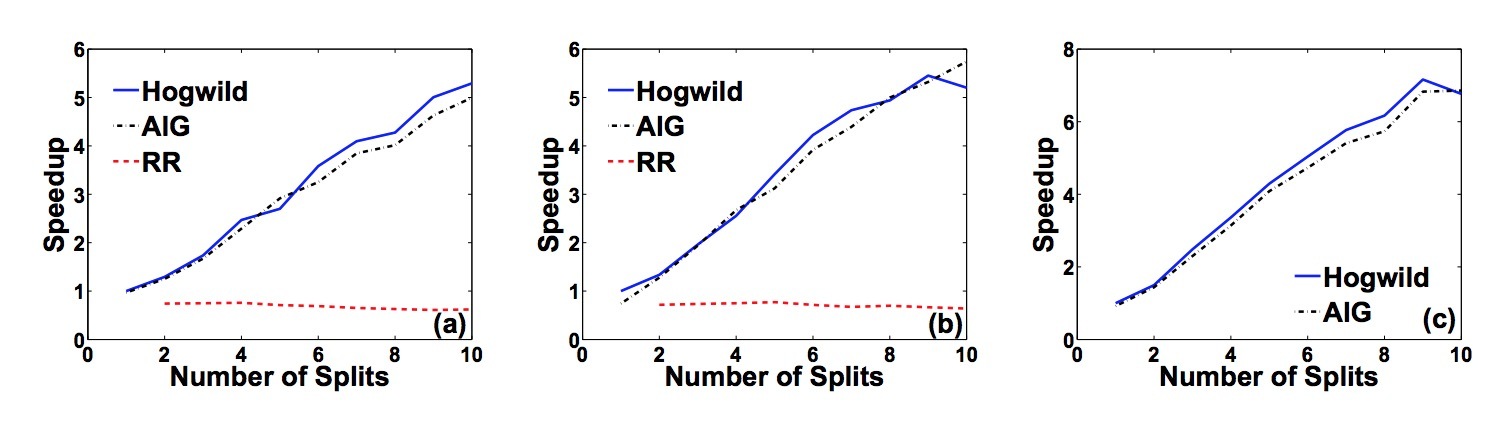
图4:
图5a展示了这三个数据集在使用Hogwild!的加速。注意,Jumbo和KDD数据集不能完全装载进(fit in)我们分配的内存,但即使从磁盘读取数据时,Hogwild都能获取一个接近线性的加速。Jumbo会花费2个半小时来完成。图4展示了Hogwild!、AIG和RR在三个矩阵补全(Matrix completion)数据集上的实验结果。与快速计算梯度的实验相似,RR并没有展现出比serial版本的方式有任何提升。事实上,使用10个线程,RR在KDD Cup上会比serial版本慢12%,在Netflix版本上会慢62%。实际上,以合理的时间量完成Jumbo实验是很慢的,而10-way并行化Hogwild!实现可以在3个小时内解决该问题。
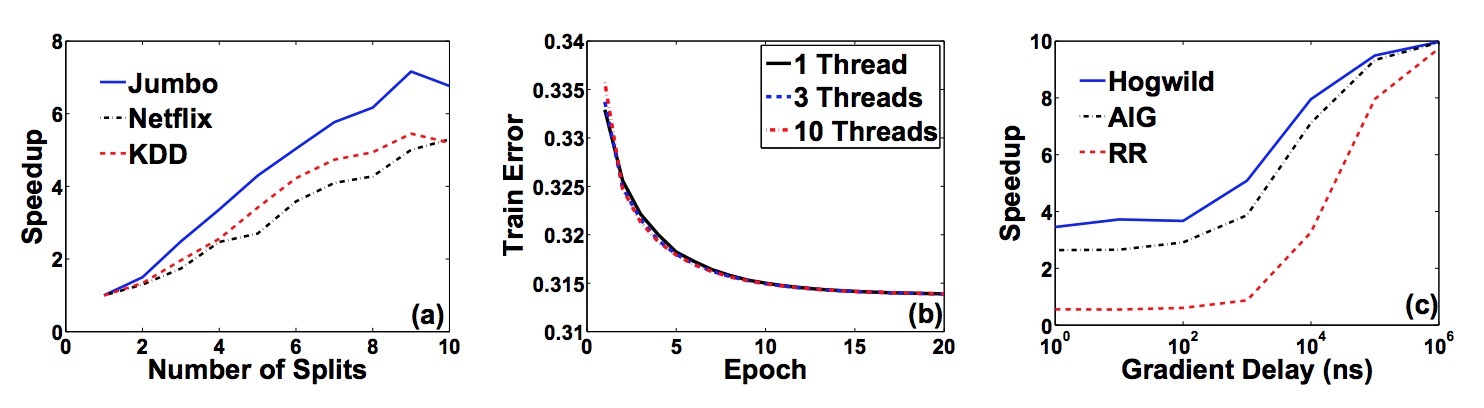
图5
Graph Cuts。 我们的第一个cut问题是一个在计算机视觉中很流行的标准图片切分。xxx(略)
如果梯度很慢会怎么样? 在DBLIFE数据集上,当梯度计算很慢时,RR方法会获得一个几乎线性的加速。这抛出了一个问题:对于梯度计算慢的问题,RR是否要胜过Hogwild?为了回答这个问题,我们运行了RCV1实验,并在每次梯度计算时引入一个人工生成的delay来模仿一个慢梯度计算。如图5c所示,我们画出了求解SVM问题所需的wall clock time,我们会对比RR与Hogwild方法的delay。
注意到,Hogwild!会获得一个更大的计算时间减少的收益。当delay为几ms时,两种方法的加速是相同的。也就是说,如果一个梯度花费超过1ms的计算时间,RR会与Hogwild相当(但不是超过)。在该rate上,每个小时只能计算大约100w次SGD,因此,梯度计算必须非常耗时,这时RR方法才有竞争力。
8.结论
我们提出的Hogwild算法利用了在机器学习中的稀疏性,在多种应用上可以达到接近线性的加速。经验上,我们的实验可胜过理论分析。例如,\(\rho\)在RCV1 SVM问题上相当大,我们也仍能获得巨大加速。再者,我们的算法允许并行加速,即使当梯度计算非常密集时。
我们的Hogwild scheme可以泛化到:一些变量的出现相当频繁的问题上。我们可以在高度竞争的那些特定变量上,选择不更新。例如,我们可能希望添加一个bias项到我们的SVM上,然后仍运行一个Hogwild scheme,更新bias只需要每上千次迭代时进行。
对于将来的工作,我们有兴趣枚举那些允许没有冲突的并行梯度计算的结构。也就是说,可能会与SGD迭代有偏差,以便完全避免处理器间的内存竞争。例如,最近的工作【25】提出了一个在matrix比赛问题中的SG的biased ordering,来完全避免处理器间的内存竞争。关于如何将该方法泛化到其它结构上,以便更快的机器学习计算,这样的调查也在开展中。
参考
1.https://arxiv.org/pdf/1106.5730v2.pdf