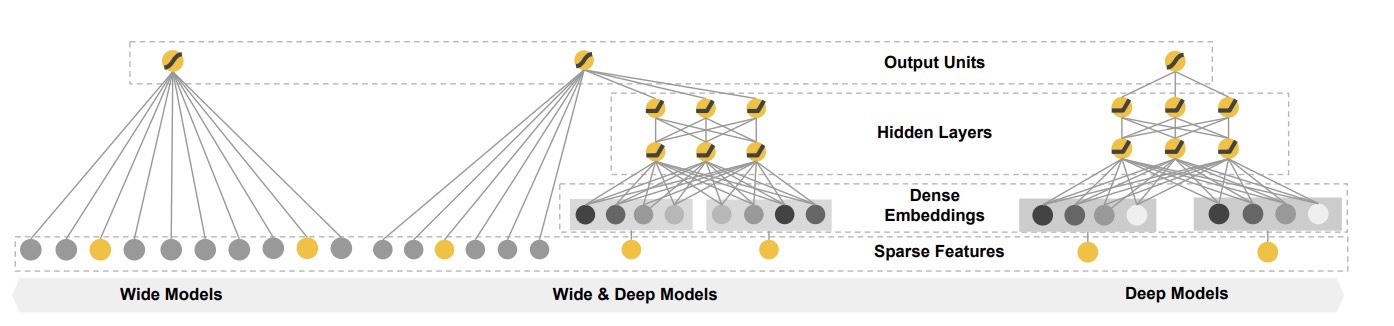
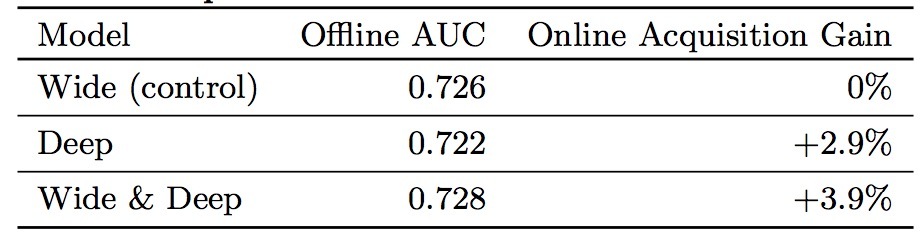
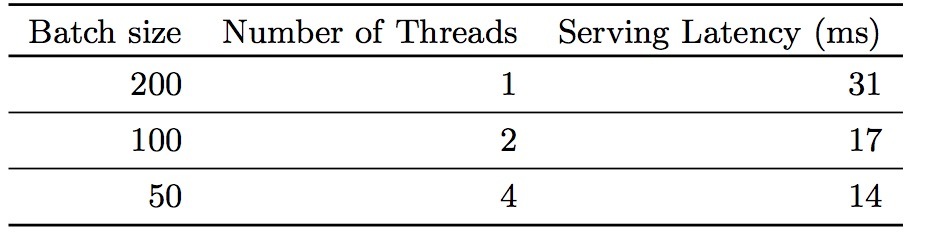
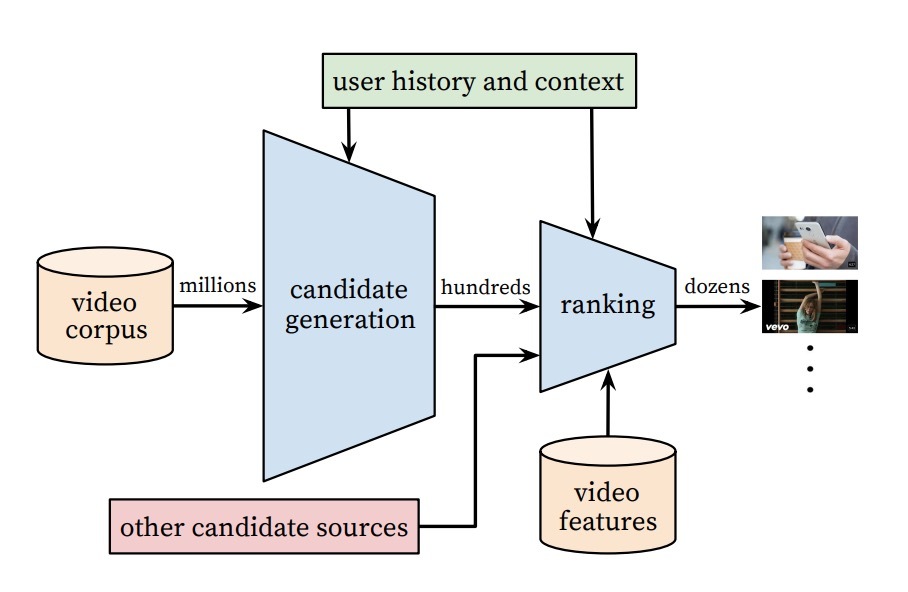
PNN是上海交大Yanru Qu等人提出的:
一、介绍
使用在线广告中的CTR预估做为示例来建模和探索对应的metrics效果。该任务会构建一个预测模型来估计用户在给定上下文上点击一个特定广告的概率。
每个数据样本包含了多个field的类别数据,比如:User信息(City, Hour等),Publisher信息(Domain、Ad slot,等),以及广告信息(Ad creative ID, Campaign ID等)。所有这些信息都被表示成一个multi-field的类别型特征向量,其中每个field(比如:City)是一个one-hot编码的向量。这种field-wise one-hot编码表示可以产生高维且稀疏的特征。另外,field间还存在着局部依赖(local dependencies)和层级结果(hierarchical structures)。
他们探索了一个DNN模型来捕获在multi-field类别型数据中的高阶隐模式(high-order letent patterns)。并想出了product layer的想法来自动探索特征交叉。在FM中,特征交叉通过两个特征向量的内积(inner-product)来定义。
提出的deep-learning模型称为“PNN (Productbased Neural Network)”。在本部分,会详细介绍该模型以及它的两个变种:IPNN(Inner Product-based Neural Network)、OPNN(Outer Product-based Neural Network);其中IPNN具有一个inner-product layer,而OPNN则具有一个outer-product layer。
1.1 PNN

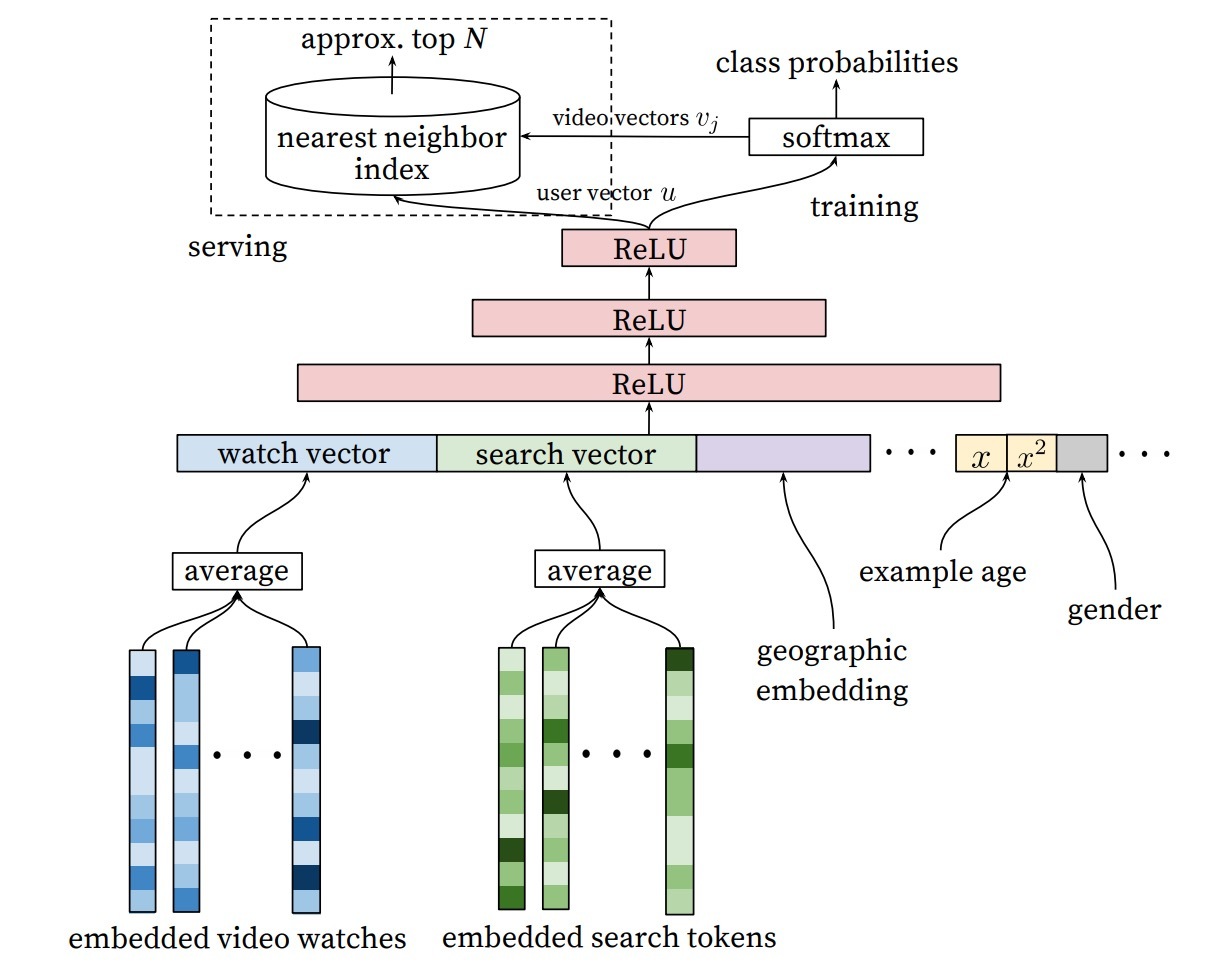
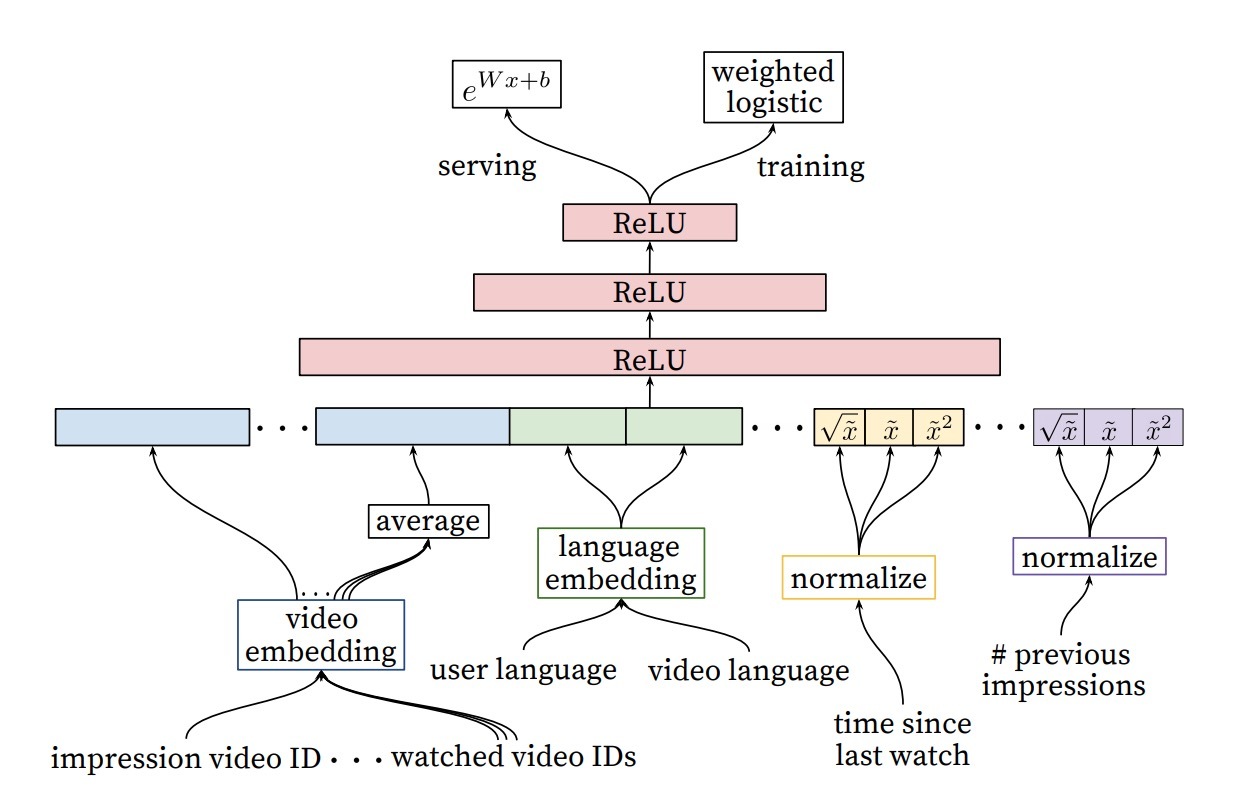
图1: PNN
PNN模型的结构如图1所示。从上到下看,PNN的输出是一个实数值 \(\hat{y} \in (0, 1)\),作为预测CTR:
\[\hat{y} = \sigma(W_3 l_2 + b_3)\]…(1)
其中,\(W_3 \in R^{1 \times D_2}\) 和 \(b_3 \in R\)是output layer的参数,\(l_2 \in R^{D_2}\)是第二个hidden layer的output,\(\sigma(x)\)是sigmoid激活函数:\(\sigma(x) = 1/(1+e^{-x})\)。其中,我们使用\(D_i\)来表示第i个hidden layer的维度。
第二个hidden layer的输出\(l_2\)为:
\[l_2 = relu(W_2 l_1 + b_2)\]…(2)
其中\(l_1 \in R^{D_1}\)是第一个hidden layer的输出。relu的定义为:\(relu(x)=max(0,x)\)。
第一个hidden layer是fully_connected product layer。它的输入包含了线性信号\(l_z\)和二阶信号\(l_p\)。\(l_1\)的定义如下:
\[l_1 = relu(l_z + l_p + b_1)\]…(3)
其中所有的\(l_z, l_p, b_1 \in R^{D_1}\)。
接着,定义tensor的内积(inner product)操作:
\[A \odot B \triangleq \sum_{i,j} A_{i,j} B_{i,j}\]…(4)
内积会首先对A, B进行element-wise乘积,接着对这些element-wise乘积进行求和得到一个标量(scalar)。之后,\(l_z\)和\(l_p\)会分别通过z和p进行计算:
\[l_z = (l_z^1, l_z^2, ..., l_z^n, ..., l_z^{D_1}), l_z^n = W_z^n \odot z\] \[l_p = (l_p^1, l_p^2, ..., l_p^n, ..., l_p^{D_1}), l_p^n = W_p^n \odot p\]…(5)
其中\(W_z^n\)和\(W_p^n\)是在product layer中的weights,它们的shapes分别由z和p决定。
通过引入一个”1”常量信号,product layer不仅能生成二阶信号p,也能管理线性信号z,如图1所示。更特殊地:
\[z = (z_1, z_2, ..., z_N) \triangleq (f_1, f_2, ..., f_N)\]…(6)
\[p = \{ p_{i,j} \}, i=1...N, j=1...N\]…(7)
其中\(f_i \in R^M\)是field i的embedding vector。\(p_{i,j} = g(f_i, f_j)\)定义了pairwise特征交叉。通过为g设计不同的操作,我们的PNN模型具有不同的实现。在该paper中提出了两个PNN的变种:IPNN和OPNN。
field i的embedding vector:\(f_i\),是embedding layer的ouput:
\[f_i = W_0^i x [start_i : end_i]\]…(8)
其中x是包含了多个field的输入特征向量,\(x[start_i:end_i]\)表示embedding layer的参数,\(W_0^i \in R^{M \times (end_i - start_i + 1)}\)是与第i个field进行fully_connected。
最后,会使用监督学习来最小化logloss:
\[L(y, \hat{y}) = -y log \hat{y} - (1-y) log(1-\hat{y})\]…(9)
其中,y是ground truth(1为click,0为non-click),\(\hat{y}\)是我们模型在等式(1)中的预测CTR。
1.2 IPNN
基于内积的神经网络(IPNN)中,我们首先定义了pair-wise特征交叉作为向量内积: \(g(f_i, f_j) = \langle f_i, f_j \rangle\)。
有了常数信号”1”,线性信息z会被保留:
\[l_z^n = W_z^n \odot z = \sum_{i=1}^{N} \sum_{j=1}^{M} (W_z^n)_{i,j} z_{i,j}\]…(10)
对于二阶信号p,pairwise的内积项\(g(f_i,f_j)\)形成了一个二阶矩阵\(p \in R^{N \times N}\)。回顾下公式(5)的定义,\(l_p^n = \sum_{i=1}^{N} \sum_{j=1}^{N} (W_p^n)_{i,j} p_{i,j}\)和向量内积的交换律,p和\(W_p^n\)是对称的。
这样的pairwise连接扩展了神经网络的能力(capacity),但也极大地增了了复杂性。在这种情况下,在等式(3)中描述的\(l_1\)的公式,具有\(O(N^2(D_1+M))\)的空间复杂度,其中\(D_1\)和M是关于网络结构的超参数,N是input fields的数目。受FM的启发,我们提出矩阵因子分解(matrix factorization)的思想来减小复杂度。
通过引入假设\(W_p^n = \theta^n \theta^{nT}\),其中\(\theta^n \in R^N\),我们可以将\(l_1\)简化成:
\[W_p^n \odot p = \sum_{i=1}^N \sum_{j=1}^N \theta_i^n \theta_j^n \langle f_i, f_j \rangle = \langle \sum_{i=1}^N \delta_{i}^n, \sum_{i=1}^N \delta_i^n \rangle\]…(11)
其中,出于便利,我们使用\(\delta_i^n \in R^M\)来表示一个特征向量\(f_i\)通过\(\delta_i^n\)来加权,例如,\(\delta_i^n = \delta_i^n f_i\)。以及我们也有\(\delta^n = (\delta_1^n, \delta_2^n, ..., \delta_i^n, ..., \delta_N^n) \in R^{N \times M}\)
在第n个单个结点上进行1阶分解,我们给出了\(l_p\)的完整形式:
\[l_p = (| \sum_i \delta_i^1 |, ..., | \sum_i \delta_i^n |, ..., | \sum_i \delta_i^{D_1} |)\]…(12)
通过在公式(12)中的\(l_p\)的reduction,\(l_1\)的空间复杂度变成\(O(D_1 M N)\)。总之,\(l_1\)复杂度从二阶降至线性(对N)。这种公式对于一些中间结果可以复用。再者,矩阵操作更容易在GPU上加速。
更普通的,我们讨论了\(W_p^n\)的K阶分解。我们应指出\(W_p^n = \delta_n \delta_n^T\)只对该假设进行一阶分解。总的矩阵分解方法可以来自:
\[W_p^n \odot p = \sum_{i=1}^N \sum_{j=1}^N \langle \delta_n^i, \delta_n^j \rangle \langle f_i, f_j \rangle\]…(13)
在这种情况下,\(\theta_n^i \in R^K\)。这种通用分解具有更弱的猜想,更具表现力,但会导至K倍的模型复杂度。
1.3 OPNN
向量的内积采用一对向量作为输入,并输出一个标量。不同于此,向量的外积(outer-product)采用一对向量,并生成一个矩阵,在该部分,我们讨论了OPNN。
在IPNN和OPNN间的唯一区别是,二次项p。在OPNN,我们定义了特征交叉:\(g(f_i, f_j) = f_i f_j^T\)。这样对于在p中的每个元素,\(p_{i,j} \in R^{M \times M}\)是一个方阵(square matrix)。
为了计算\(l_1\),空间复杂度是\(O(D_1 M^2 N^2)\),时间复杂度也是\(O(D_1 M^2 N^2)\)。回顾下\(D_1\)和M是网络结构的超参数,N是input fields的数目,实际上该实现很昂贵。为了减小复杂度,我们提出了superposition的思想。
通过element-wise superposition,我们可以通过一个大的step来减小复杂度。特别的,我们重新定义了p公式:
\[p = \sum_i^N \sum_i^N f_i f_j^T = f_{\sum} (f_{sum})^T, f_{\sum} = \sum_{i}^N f_i\]…(14)
其中\(p \in R^{M \times M}\)变成对称的,这里的\(W_p^n\)也应是对称的。回顾下公式(5) \(W_p \in R^{D_1 \times M \times M}\)。在这种情况下,空间复杂度\(l_1\)变成了\(O(D_1 M(M+N))\),时间复杂度也是\(O(D_1 M(M+N))\).
对比起FNN,PNN具有一个product layer。如果移除product layer的了\(l_p\)部分,PNN等同于FNN。有了内积操作,PNN与FM相当相似:如果没有hidden layer,并且output layer只是简单地使用weight=1进行求和,PNN等同于FM。受Net2Net的启发,我们首先训练了一个PNN来作为初始化,接着启动对整个网络的back propagation。产生的PNN至少和FNN或FM一样好。
总之,PNN使用product layers来探索特征交叉。向量积可以看成是一系列加法/乘法操作。内积和外积只是两种实现。事实上,我们可以定义更通用或复杂的product layers,来在探索特征交叉上获取PNN更好的capability。
类似于电路,加法就像是”OR”门,而乘法则像”AND”门,该product layer看起来是学习规则(rules)而非特征(features)。回顾计算机视觉方法,在图片上的象素是真实世界中的原始特征(raw features),在web应用中的类别型数据是人工特征(artificial features)具有更高级和丰富的含义。Logic在处理概念、领域、关系上是一个很强的工具。这样我们相信,在神经网络中引入product操作,对于建模multi-field categorical data方面会提升网络能力。
实验
详见paper。