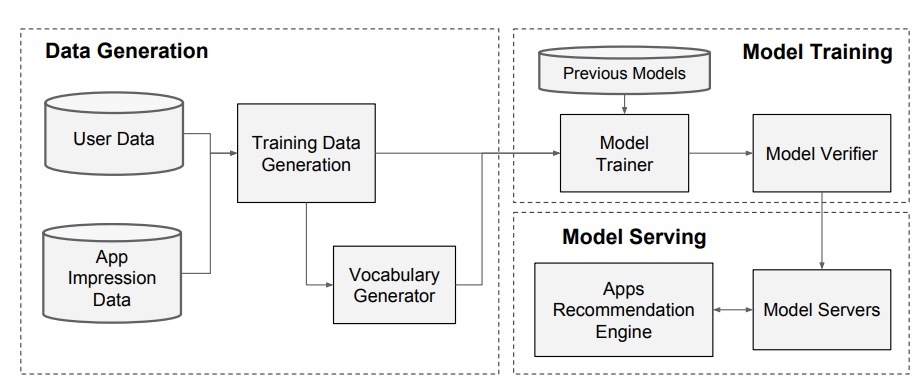
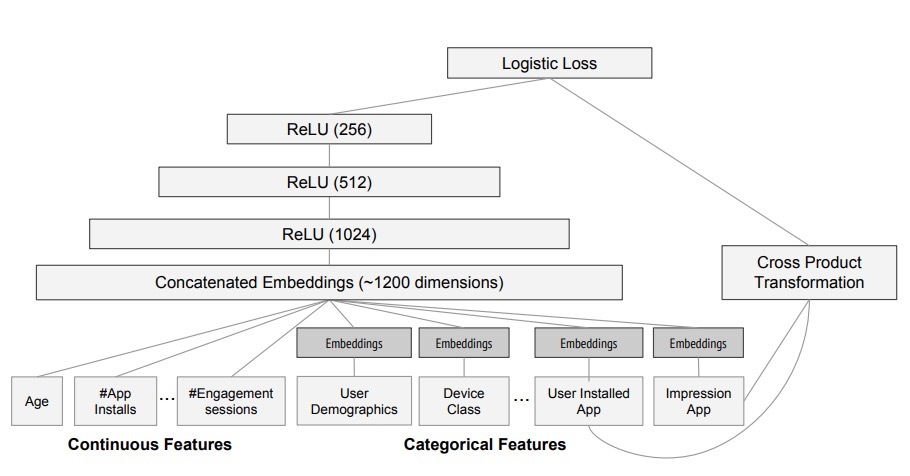
microsoft在2016年提出了MV-DNN结构:《A Multi-View Deep Learning Approach for Cross Domain User Modeling in Recommendation Systems》。我们来看下该paper。
介绍
为了解决CF和CB的诸多限制,我们提出了利用user features和item features的推荐方法。为了构建user features,不同于许多user profile-based的方法,我们提出了从浏览记录、搜索历史中抽取丰富特征来建模用户的兴趣。依赖的假设是:用户的历史在线动作会影响用户的背景(background)和偏好(preference),因此提出了一种关于用户会对哪些items和topics感兴趣的更精确看法。例如,一个用户做出的许多查询和网页访问都与婴儿有关,那么她很可能是一个新生儿的母亲。有了这些丰富的在线行为,推荐相关items可以更有效率和有效果。
在我们的工作中,我们提出了一种新的deep learning方法,它扩展了DSSM(Deep Structured Semantic Models),它将users和items映射到一个共享语义空间中,并推荐那些在映射空间中与该用户具有最大相似度的items。为了达到该目的,我们的模型会对users和items进行投影,每一者都通过一个丰富的特征集表示,通过非线性转换层映射到一个完全共享的隐语义空间中,其中user的mapping以及该用户喜欢的items的mappings间的相似度会最大化。这允放该模型学习感兴趣的mappings:比如,访问了fifa.com的用户可能会读取关于世界杯相关的新闻文章、或喜欢关于PC or XBox足球游戏。用户侧的丰富特征可以允许建模用户的行为,从而克服在content-based推荐中的限制。它也可以有效解决用户的冷启动问题,因为模型允许我们从queries和相关推荐items(比如音乐)上捕获用户兴趣,即使它们没有使用音乐服务的历史记录。我们的deep learning模型具有一个ranking-based objective函数,它会将正样本(用户喜欢的items)的排序比负样本的更高。该ranking-based objective对于推荐系统更好。
另外,我们扩展了原始的DSSM模型(它被称为是single-view DNN),因为它从来自单个域的user-features 和items学习模型。我们将新模型命名为“Multi-View DNN”。在文献中,multi-view learning是一个比较成熟的领域,它可以从相互不共享的公共特征空间的数据中进行学习。我们将MV-DNN看成了在multi-view learning setup中一种通用的Deeplearning方法。特别的,在我们的数据集中有News、Apps和Movie/TV logs,我们不需要为这种不同域(domain)构建独立模型,它们可以将user features映射到相同域(domain)的item features上,我们会构建一个新的multi-view模型,它会为在隐空间中的user features发现一个单一映射,可以从所有域中使用items的特征进行联合优化。MV-DNN会利用多个跨域数据来学习一个更好的用户表示(user representation),也会利用全域的用户偏好数据使用以一种规则的方式解决数据稀疏性问题。
3.数据集描述
这部分会介绍数据集。我们描述了数据收集过程,以及每个数据集的特征表示,以及一些基础的数据统计。
在该研究中会使用4个数据集,它们从microsoft的产品中收集,包含:
- (1) Bing Web vertical搜索引擎日志
- (2) Bing News vertical的新闻文章浏览历史
- (3) Windows AppStore的App下载日志
- (4) XBox的Movie/TV观看日志
所有日志的收集从2013-12 〜 2014 6月,包含了英语系国家:美国、加拿大、英国。
(用户特征: user features):我们从Bings收集了用户的搜索queries和它们的点击urls来形成用户特征。queries首先会被归一化、获取词干、接着将它们split成unigram特征,urls会被简写成domain-level(例如:www.linkedin.com)来减小特征空间。我们接着使用TF-IDF得分来保持最流行和重要(no-trivial)特征。整体上,我们选择了300w的unigram特征和500k的domain特征,来产生一个总长度为3500w的用户特征向量。
(新闻特征:News Features):我们收集了从Bing News vertical的新闻文章点击。每个News Item通过三部分特征表示。第一部分是,使用字符tri-gram表示编码的标题特征。第二部分是,使用二值特征编码的News的top-level类目(比如:娱乐)特征。第三部分是,每篇文章的命名实体,使用一个NLP parser抽取得到,同样使用tri-gram进行编码。这会产生一个包含10w维的特征向量。
(APP特征):用户APP的下载历史,来自windows AppStore日志。每个App的标题使用字符tri-gram表示,会以二值形式组合上类目特征(比如:游戏)。对于APP描述常变化的特性,我们决定不包含这些特征。这一部分会产生一个5w维的特征向量。
(Movie/TV Features):对于Xbox日志,我们为每个XBox用户收集了Movie/TV观看历史。每个item的标题和描述,会组合成文本特征,接着使用字符型tri-gram编码。该genre也使用二值特征编码。这一部分会产生5w维特征向量。
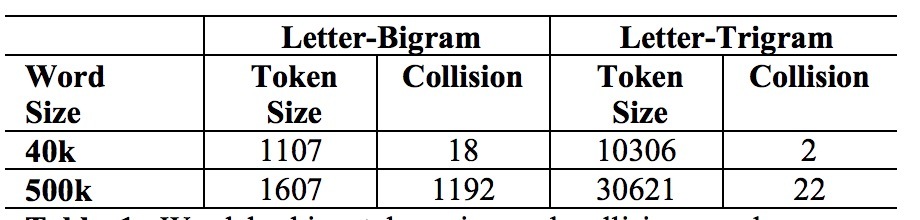
在我们的神经网络框架中,user features被映射到user view上,其余被映射到不同的item views上。出于训练目的,每个user view会被匹配到一个item view上,它包含了用户的完整集合。为了这样做,我们对登陆用户的每个user-item view pair, 以及基于id间交叉做了抽样。这会为每个user-item view pair产生不同数目的用户。表1描述了在该paper中的一些统计。
4. 用于建模用户的DSSM
DSSM的引入是为了增强在搜索上下文中的query document matching。

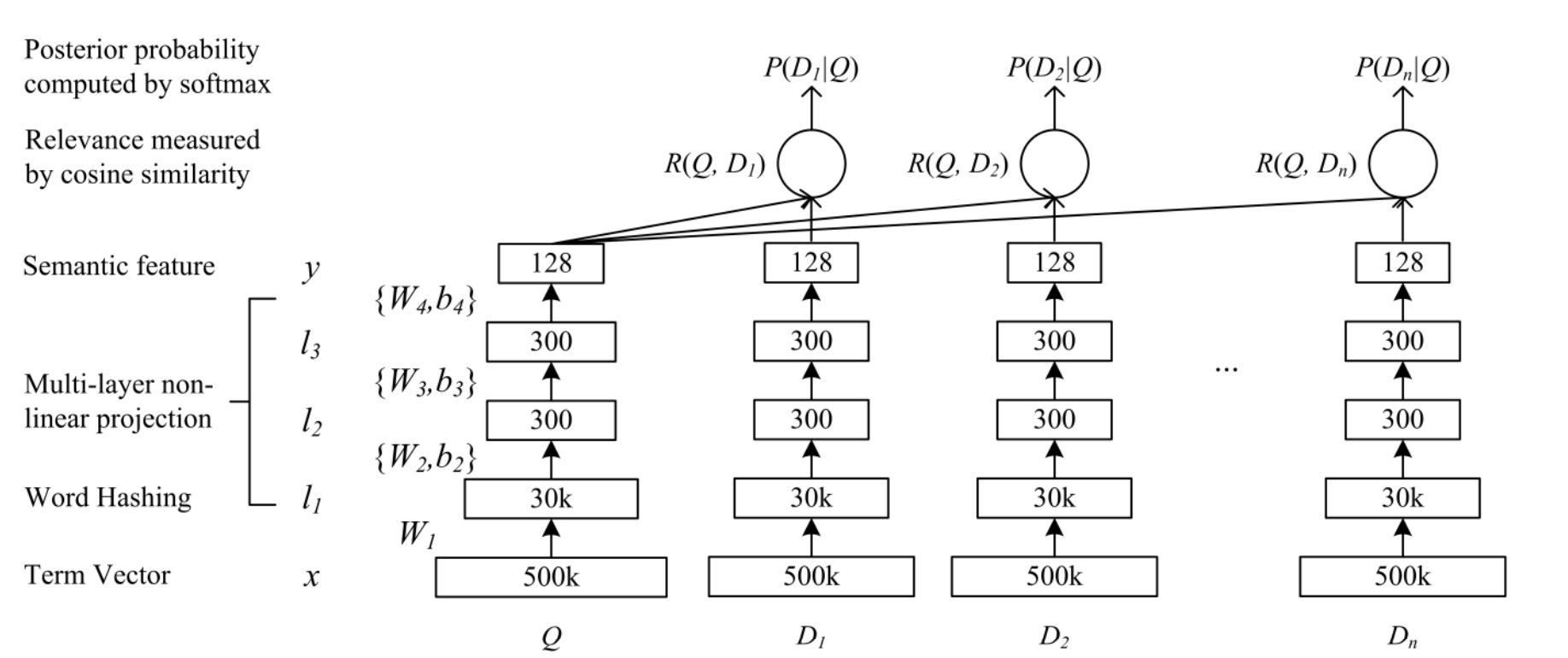
图1 DSSM深度结构语义模型
DSSM的典型结构如图1所示。到DNN的输入(原始文本特征)是一个高维向量,例如,在一个query或一个文档中的terms原始数目(没有归一化)。接着DSSM会将该输入传给两个神经网络,两者都有各自不同的输入,会将它们映射到在一个共享语义空间中的语义向量中。对于网页文档排序,DSSM会计算一个query和一个document间的相关得分(对应两个语义向量间的cosine相似度),并通过相似得分进行文档排序。
更正式的,如果x表示输入的term向量,y表示输出向量,\(l_i, i=1,...,N-1\)表示内部的hidden layers,\(W_i\)表示第i个权重矩阵,\(b_i\)表示第i个bias term,我们有:
\[l_1 = W_1 x \\ l_i = f(W_i l_{i-1} + b_i), i=2,...,N-1 \\ y = f(W_N l_{N-1} + b_N)\]…(1)
其中,我们使用tanh函数作为在output layer和hidden layers \(l_i\)上的activation函数:
\[f(x)= \frac{1 - e^{-2x}} {1+ e^{-2x}}\]…(2)
在一个query Q和一个document D间的语义相关得分,接着通过R进行measure:
\[R(Q, D) = cosine(y_Q, y_D) = \frac{y_Q^T y_D} {||y_Q|| \cdot ||y_D||}\]…(3)
其中,\(y_Q\)和\(y_D\)各自是query和document的语义向量。在Web搜索中,给定query,document会通过它们的语义相关得分进行排序。
惯例上,每个word w通过一个one-hot词向量表示,其它维度对应于词汇表size。然而,词汇表size经常在现实中非常大,one-hot向量的词表示会让模型学习开销很大。因此,DSSM使用word hashing layer通过一个letter-trigram向量来表示一个词。例如:给定一个词(web),在添加了词边界符号后(#web#),该词被分割成ngram序列(#we, web, eb#)。接着,该词被表示成一个关于letter-trigrams的count vector。例如,web的letter-trigram表示为:
在图1中,第一层 matrix \(W_1\)表示letter-trigram矩阵,它从一个term-vector转移到它的letter-trigram count vector上,无需学习。尽管英文words的总数目会增长得相当大,去重后的英文letter-trigrams的总数目通常是有限的。因此,它可以泛化到在训练数据中那些未见过的新词上。
在训练中,假设一个query与该query下被点击的documents相关,DSSM的参数(例如:权重矩阵\(W_i\)),可以使用该信号被训练。例如,给定一个query后一个document的后验概率,可以从两者间的语义相关分数中会通过一个softmax函数进行估计:
\[P(D|Q) = \frac{exp(\gamma R(Q,D))}{\sum\limits_{D' \in D} exp(\gamma R(Q,D'))}\]…(4)
其中\(\gamma\)是softmax的一个平滑因子,它通常会在一个held-out数据集上进行经验型设置。D表示要排序的候选文档集合。理想的,D应包含所有可能的文档。实际上,对于(query, clicked-document) pair,可以使用\((Q, D^+)\)表示,其中:
- Q表示一个query
- \(D^{+}\)表示点击的文档,
- \(\lbrace D_j^-; j=1, ..., N\rbrace\)来表示: N个随机选中的未点击文档
- D: 包含\(D^{+}\)和N个随机选中的未点击文档来近似D
在训练中,模型参数被估计成:给定queries,被点击文档的极大似然:
\[L(\Lambda) = \log \prod\limits_{(Q,D^+)} P(D^+ | Q)\]…(5)
其中,\(\Lambda\)表示神经网络的参数集。
5.MV-DNN
DSSM可以看成是一个multi-learning框架,其中它会将两种不同的数据视图映射到一个共享视图(shared view)中。在某种程度上,它可以被看成是:在一个更通用的setting中来学习两个不同views间的一个共享mapping。

图2: 多域推荐(multiple domain recommendation)的MV-DNN。它使用一个DNN来将高维稀疏特征(例如:users, News, App的原始特征)映射成低维dense特征到一个联合语义空间中(joint semantic space)。第一个hidden layer,有50k units,会完成word hashing。word-hashed features接着通过多个非线性投影投影层被投影。最后一层的activities会形成在语义空间中的特征。注意,在该图中的输入特征维度x(5M和3M)被假设成:每个view可以有任意的特征数。详见文本。
在该工作中,我们提出了一个DSSM的扩展,它具有对数据的多个views,我们称之为Multi-view DNN。在该setting中,我们具有v+1个views,一个主视图(pivot view)称为\(X_u\),其它v个辅助视图(auxiliary views)为:\(X_1, ..., X_v\)。每个\(X_i\)具有它自己的输入域\(X_i \in R^{d_i}\)。每个view也具有它自己的非线性映射层 \(f_i(X_i, W_i)\),它会将\(X_i\)转换到共享语义空间\(Y_i\)上。训练数据包含了一个样本集合。第j个样本具有主view \(X_{u,j}\)的一个实例,以及一个活动辅助视图\(X_{a,j}\),其中a是在sample j中active view的索引。所有其它视图输入\(X_{i:i \neq a}\)被设置为0向量(0 vectors)。该学习目标是(objects)是为每个view(比如:相似的求和)发现一个线性映射,以便最大化相似度(在主视图\(Y_u\) mapping以及其它视图\(Y_1, ..., Y_v\) mapping间的语义空间的相似度)的求和。公式为:
\[p = arg max_{W_u, W_1,...,W_v} \sum\limits_{j=1}^N \frac{e^{\alpha_a cos(Y_u, Y_{a,j}}}{ \sum_{X' \in R^{d_a}} e^{\alpha cos(Y_u, f_a(X', W_a))} }\]…(6)
MV-DNN的结构如图2所示。在我们的推荐系统设置中,我们将\(X_u\)设置为user features的主视图,并为各种不同的想推荐的items类型创建了辅助视图。
该目标函数是意图是,为users features尝试找到单个mapping(\(W_u\)),可以将users features转换到一个空间中,它与该用户在不同视图/域中所喜欢的所有其它items相匹配(match)。该方法会共享参数,并允许该域(domains)即使没有足够信息也能学习较好的mapping(通过其它带有足够信息的domains数据来学)。
如果假设具有相似新闻文章品味的用户,同时也在其它域(domains)上有相似品味,这意味着这些domains可以从通过News domain学到的user mapping上受益。如果该假设是合法的,那么从任意domain上的样本都可以帮助将相似用户在所有domains上进行更准确的分群。经验结果表明,在该domains上的假设是合理的,我们会在实验章节再做描述。
5.1 训练MV-DNN
MV-DNN可以使用SGD进行训练。实际上,每个训练样本会包含一个输入对(inputs pairs),一个用于用户视图(user view),一个用于其它数据视图。因此,尽管事实上在我们的模型只有一个用户视图(user view),通常采用N个用户特征文件会更方便,每个对应于一个item feature file,其中N是user-item view pairs的总数目。在算法1中,我们会描述训练MV-DNN的高级过程。当各自对所有\(W_i \in \lbrace W_u, W_1, ..., W_v \rbrace\)进行求导时,我们会得到两个非零导数 \(\frac{\partial p }{\partial W_u}\)和 \(\frac{\partial p}{\partial W_a}\),它允许我们应用与DSSM相同的梯度更新规则【9】,使用\(X_u\)来取代q,使用\(X_a\)来取代d。

算法1
5.2 MV-DNN的优点
尽管MV-DNN是从原始的DSSM框架进行扩展而来的,但它具有许多独特的特性比前者更优。首先,原始的DSSM模型用于相同特征维度size的query view和document view的,使用相同的表示(representation)进行预处理(例如:letter tri-gram)。这在特征组合阶段会有巨大限制。由于推荐系统的差异性,很可能user view和item view会有不同的输入特征。同时,许多类型的特征不能使用letter trigram进行最优表示。例如,URL domain feature通常包含了前缀和后缀,(比如:www, com, org),它们会被映射到相同的特征上(如果使用了letter tri-gram)。实际上,我们已经发现,当输入原始文本很短时(例如:原始DSSM模型中的query text和document title),该letter tri-gram表示很理想,但如果建模包含了大量queries和url domains的用户级别特征(user level features)就会变得不合适。新的MV-DNN会移除该限制,来包含类别型特征(比如:电影类型和app类目,地理特征:比如国家和区域),也可以包含原始文本特征(用户输入侧使用1-grams或2-grams来表示)。
第二,MV-DNN可以扩展到许多不同的domains上,原始DSSM框加做不到。通过在每个user-item view pair上执行pair-wise训练(如算法1描述所示),我们的模型可以很方便的采用view pairs的新集合,在训练过程中的任意阶段,它包含了完全独立的users和items集合;例如:添加来自Xbox games的一个新数据集。通过在每个训练迭代过程中选择user-view pairs,我们的模型事实上可以收敛到一个最优的user view embedding上,它通过所有的item views训练得到。注意,尽管理论上我们在不同的item-views上具有不同的user sets,在我们的实验期间,考虑便利性和特征归一化的方便,我们会选择在所有views上保持相同集合的用户。
6.数据降维
实际上,提出的深度学习方法通常需要为user view处理高维特征空间中的海量训练样本。为了扩展系统,我们提出了许多降维技术来减少在user view上特征数。接着,我们提出了一个思想来压缩(compact)和总结(summarize)用户训练样本,它可以将训练数据的数目减少到与users数目成线性倍数上。
6.1 top features
对于user features,一种简单的降维方法是,选择top-k个最常用的特征。。。。
6.2 K-means
6.3 LSH
6.4 减小训练样本数
每个view的训练样本包含了一个关于\((User_i, Item_j)\) pairs集合(表示:\(User_i喜欢Item_j\))。实际上,一个user可能会喜欢许多items,它们有时候会造成训练数据非常大。例如,在我们的新闻推荐数据集上,大概有10亿pairs数目,这会造成训练过程非常慢(当使用最优的GPU实现时)。
为了解决该问题,我们会压缩训练数据,以便它对于每个user每个view都可以包含单个训练样本。特别的,压缩版的训练样本包含了user features 与一个用户在该view中所喜欢的所有items的平均分的 features组成的pairs。
实验
详见paper。