microsoft在2013年提出了DSSM结构:《Learning Deep Structured Semantic Models for Web Search using Clickthrough Data》。我们来看下该paper。
介绍
主要基于在IR上的隐语义模型的两点扩展。第一是以监督方式利用点击数据来学习隐语义模型【10】。第二是引入深度学习方法进行语义建模。
2.1 隐语义模型和点击数据的使用
对于query-document matching来说,在IR社区中使用隐语义模型是一个长期存在的研究主题。流行的模型可以分为两大类:线性投影模型和生成主题模型。
IR领域最著名的线性投影模型是LSA。通过在一个document-term矩阵上使用SVD,一个document(或一个query)可以映射成一个低维概念向量(conecpt vector):\(\hat{D} = A^T D\),其中A是投影矩阵。在文档搜索中,在一个query和一个document间的相关分(可以通过term向量分别表示为Q和D),根据投影矩阵A, 被认为是与概念向量\(\hat{Q}\)和\(\hat{D}\)间的cosine相似度得分成比例:
\[sim_A(Q,D) = \frac{\hat{Q}^T \hat{D}}{ \| \hat{Q} \| \|\hat{D} \|}\]…(1)
除了隐语义模型,在被点击的query-document pairs上训练的转换模型(translation models)也提供了一种语义匹配的方法[9】。不像隐语义模型,翻译模型可以直接通过在一个document中的一个term和在一个query中的一个term间的转换关系(translation relationships)。最近研究表明,大量的点击数据用户训练,该方法可以非常高效。我们在实验中也进行了比较。
2.2 deep learning
3.DSSM
3.1 DNN用于计算语义特征
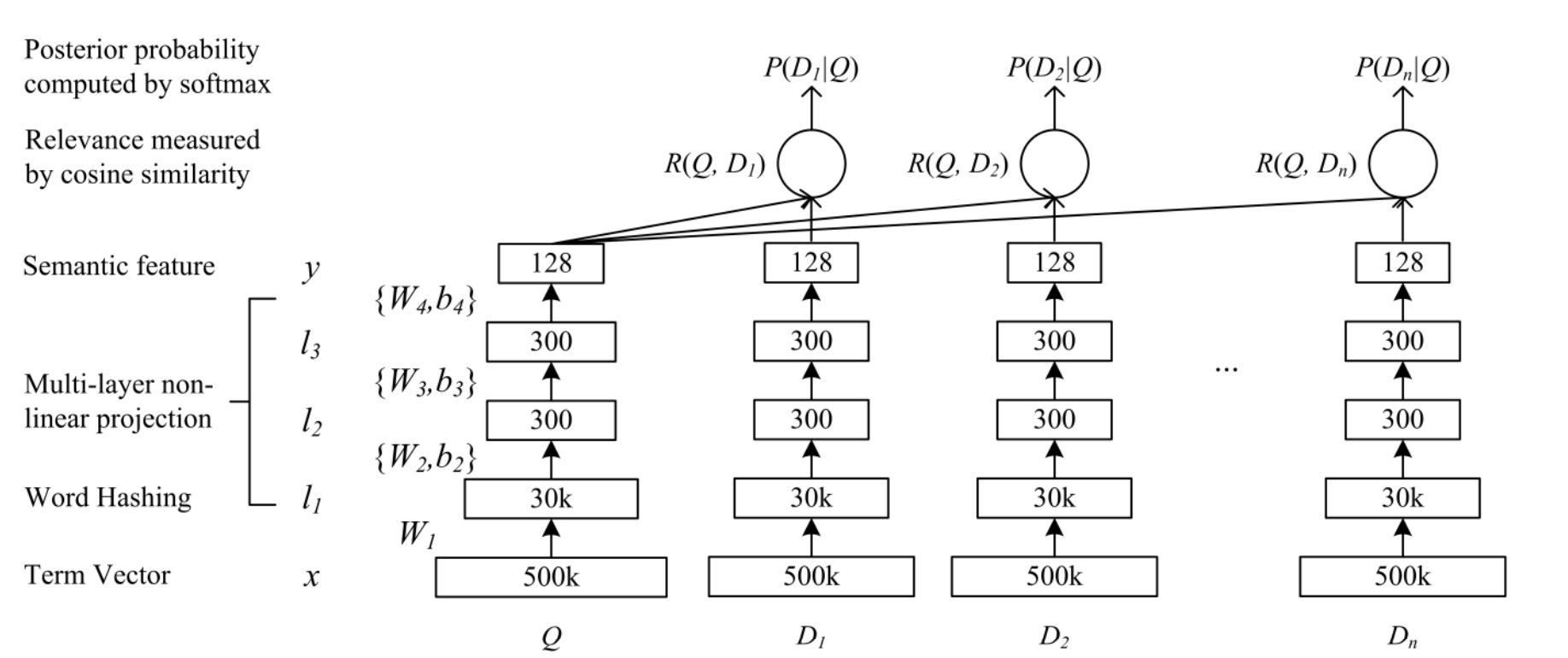
图1: DSSM图示。它使用一个DNN将高维稀疏文本特征投影到在语义空间中的低维dense特征。第一个hidden layer具有30k units,会完成word hashing。word-hashed features接着通过多个非线性投影层进行投影,在DNN中的最后一层的activities会形成在语义空间中的特征
通常我们开发的DNN结构,用于将原始文本特征(raw text features)映射到在一个语义空间中的特征(如图1所示)。DNN的输入(raw text features)是一个高维term vector,例如:在query中的terms的原始数目,或者一个没有归一化的文档,DNN输出是在一个低维语义特征空间中的一个concept vector。该DNN模型可以以如下方式用于网页文档排序(Web document ranking):
- 1) 将term vectors映射到它们相应的语义concept vectors上
- 2) 计算一个document和一个query间相关分,作为他们相应的语义concept vectors的cosine相似度 等式(3)和(5)
更正式的,如果我们将x表示成input term vector,y表示output vector,\(l_i, i=1, ..., N=1\),表示中间的hidden layers,\(W_i\)表示第i个weight matrix,\(b_i\)表示第i个bias term,我们有:
\[l_1 = W_1 x \\ l_i = f(W_i l_{i-1} + b_i), i=2, ..., N-1 \\ y = f(W_N l_{N-1} + b_N)\]…(3)
其中,我们使用tanh作为hidden layers和output layer的activation函数:
\[f(x)= \frac{1 - e^{-2x}}{1 + e^{-2x}}\]…(4)
在一个query Q和一个document D之间的语义相关得分,可以通过下面方式进行衡量:
\[R(Q,D) = cosine(y_Q, y_D) = \frac{y_Q^T y_D}{ \| y_Q \| \| y_D \|}\]…(5)
其中\(y_Q\)和\(y_D\)分别是query和document的是concept vectors。在web search领域,给定query,document可以通过它们的语义相关得分进行排序。
习惯上,term vector的size,可以被看成是在IR中原始的bag-of-words特征,等同于用于索引web document集合的字典表。字典的size通常非常大。因此,当使用term vector作为输入时,input layer的size对于inference和training来说无法想像。为了解决这个问题,我们开发了一个称为”word hashing”的方法来做为DNN的第一层,如图1的最低端所示。该layer只包含线性隐单元(linear hidden units),在其中有非常大size的权重矩阵不会被学习。在下面章节,我们描述了word hashing方法。
3.2 word hashing
这里描述的word hashing方法,目标是减少bag-of-words term vectors的维度。它基于字母型letter n-gram,该方法特别适合这个任务。给定一个词(比如:good),我们首先会添加起始结束标记(比如:#good#),接着,我们将该词切分成letter n-grams(例如,letter trigrams: #go, goo, ood, od#)。最终,该word会使用一个关于letter n-grams的向量进行表示。
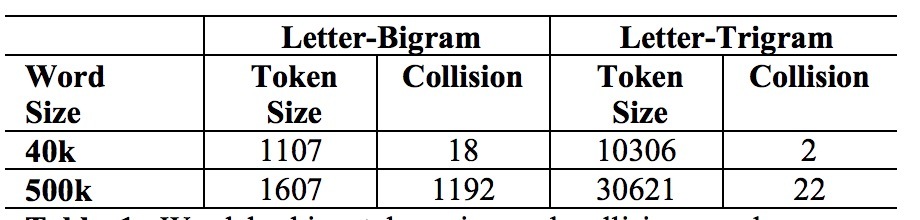
表1
该方法存在的一个问题是冲突(collision),例如,两个不同的词可以具有相同的letter n-gram vector表示。表1展示了关于在两个字典表上word hashing的一些统计。对比起one-hot vector的原始size,word hashing允许我们使用更低维度来表示一个query和一个document。以40k个词的字典作为示例。每个word可以被表示成使用leter-trigrams的一个10306维向量,给定一个4-fold降维会有较少冲突。当该技术应用到一个更大词汇表上时会有更大降维。如表1所示,在500k-word的字典表里,使用letter trigrams通过一个30621维向量来表示每个词, 16-fold的降维会有一个冲突率为0.0044% (=22/5000000)
由于英文单词数目是无限的,而英文(或其它相似语言)中的letter n-grams通常是有限的。另外,word hashing可以将具有不同字形的相同词映射到在letter n-gram空间中比较接近的点上。更重要的,当在训练集中的一个未见词(unseen word)以word-based representation时总是会引起困难,而使用letter n-gram-based representation则不会。唯一的风险是冲突会随着表1中的量而增加。因而,letter n-gram-based word hashing对于out-of-vocabulary问题是健壮的,允许我们将DNN解法扩展到包含极大词表量的Web search任务中。我们会演示第4节中展示该技术的好处。
在我们的实验中,基于word hashing的letter n-gram可以被看成是一个固定的线性转换(例如:非适配的 non-adaptive),通过这种方式,在input layer上的一个term vector可以被投影到在下一layer上的一个letter n-gram vector上,如图1所示。由于letter n-gram vector具有更低的维度,DNN learning可以有效执行。
3.3 DSSM的学习
点击日志包含了一列queries和它对应的点击文档。我们假设一个query与该query对应点击的文档是相关的(至少部分上是)。受语音和nlp领域判别式训练方法的影响(discriminative),我们提出了一个监督式训练方法来学习我们的模型参数,例如:权重矩阵\(W_i\)和bias vector \(b_i\)是DSSM的必要部分,因此学习目标是:给定queries,最大化点击文档的条件似然。
首先,我们会计算给定一个query,一个文档的后验概率,可以通过一个softmax函数:
\[P(D|Q) = \frac{exp(\gamma R(Q,D))}{\sum_{D' \in D} exp(\gamma R(Q,D'))}\]…(6)
其中,\(\gamma\)是一个softmax的平滑因子,它会根据经验进行设置。D表示待排序的候选文档集合。理想情况下,D应包含所有可能的文档。实现上,对于每个(query, click-document) pair,可以通过\((Q, D^+)\)来表示。其中:
- Q是一个query
- \(D^+\)是点击的文档
- \({D_j^-; j=1, ..., 4}\)表示4个随机选中的未点击文档。
在我们的学习中,当使用不同抽样策略来选择未点击文档时,我们不会观察到任何不同。
在训练阶段,估计的模型参数会对给定queries下的点击文档的似然做最大化。事实上,我们需要最小化以下的loss function:
\[L(\Lambda) = -log \prod\limits_{Q,D^+} P(D^+ | Q)\]…(7)
其中,\(\Lambda\)表示网络\(\lbrace W_i, b_i \rbrace\)的参数集,由于 \(L(\Lambda)\)对于\(\Lambda\)是可微的,模型的训练使用基于梯度的数值优化算法。
3.4 实现细节
为了决定训练参数以及避免overfitting,我们可以将点击数据分割成不重合的两部分,称为training set和validation set。在我们的实验中,我们使用如图1的三个hidden layers。第一个hidden layer是word hashing layer,它包含了30k节点(如表1所示的letter-trigrams的size)。下二个hidden layers具有300个hidden nodes,output layer具有128个nodes。word hashing会基于一个固定的投影矩阵。相似度会基于128维的output layer进行measure。根据[20],我们会在范围为:\((-\sqrt{6/(fanin+fanout)}, \sqrt{6/(fanin+fanout)})\)间的uniform分布来初始化网络权重,其中fanin和fanout是input和output units的数目。经验上,我们可以通过做layer-wise预训练但没有观察到更好的效果。在训练阶段,我们会使用mini-batch SGD来最优化模型。每个mini-batch包含了1024个训练样本。我们观察到DNN训练通常会在整个训练数据的20 epochs内收敛。
实验
详见paper。