google在2017年提出了一个Deep&Cross Network的模型:
1.介绍
在该paper中,提出了Deep&Cross Network(DCN)模型,它能对sparse和dense的输入进行自动特征学习。DCN可以有效地捕获关于有限阶(bounded degrees)上的有效特征交叉,学到高度非线性交叉,无需人工特征工程或暴力搜索(exhaustive searching)。并且计算代价低。
- 我们提出了一个新的cross network,它显式地在每个layer上进行特征交叉(feature crossing),可有效学习有限阶(bouned degrees)的特征交叉预测,无需人工特征工程和暴力搜索。
- 该cross network简单有效。通过设计,最高的多项式阶在每一layer递增,由layer depth决定。该网络包含了所有阶的交叉项(直到最高阶),它们的系数都不同。
- 该cross network内存高效,很容易实现。
- 我们的实验结果表明,比起接近相同阶的DNN,DCN具有更低的logloss,更少的参数。
2.DCN
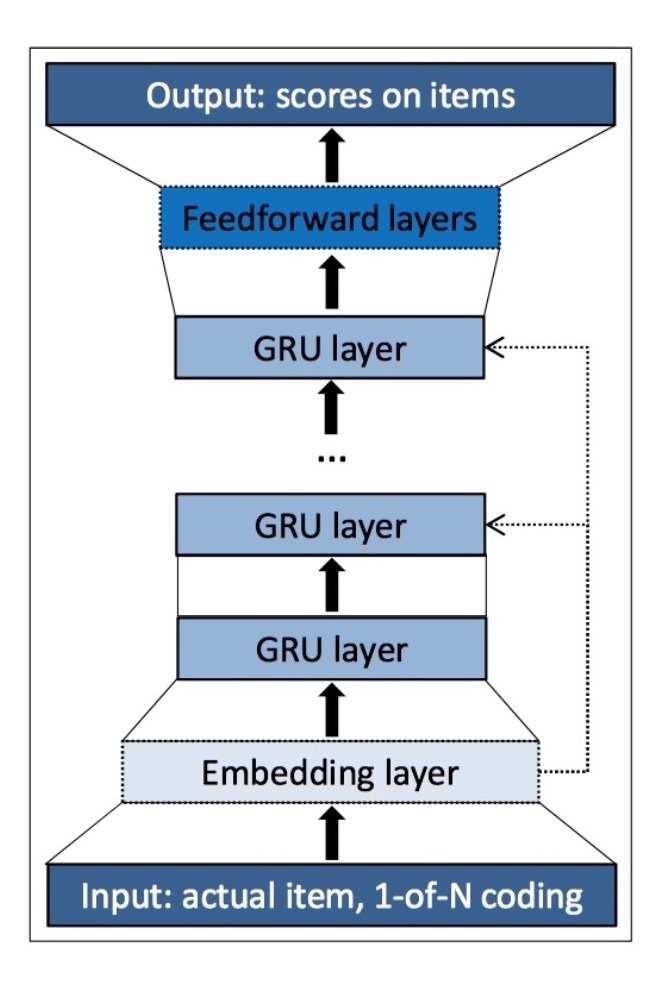
本节描述了Deep & Cross Network模型。一个DCN模型会以一个embedding and stacking layer开始,接着并列连一个cross network和一个deep network。接着通过最后一个combination layer将两个network的输出进行组合。完整的DCN模型如图1所示。

图1: Deep & Cross Network
2.1 Embedding and Stacking Layer
输入数据带有sparse和dense feature。在大规模推荐系统的CTR预测中,输入几乎都是类别型特征(categorical features),比如:”country=usa”。这样的feature通常被编码成one-hot vectors,比如:”[0,1,0]”;然而,对于大的vocabularies,这通常会产生超高维度的特征空间。
为了减小该维度,我们使用一个embedding procedure来将这些二元features转换到关于真实值(real values)的dense vectors中(称为embedding vectors)。
\[x_{embed,i} = W_{embed,i} x_i\]…(1)
其中:
- \(x_{embed,i}\)是embedding vector
- \(x_i\)是第i个category的二元输入
- \(W_{embed,i} \in R^{n_e \times n_v}\)是对应的embedding matrix,会与网络中的其它参数一起进行优化,\(n_e, n_v\)分别是embedding size和vocabulary size
最后,我们将embedding vectors和归一化稠密特征(normalized dense features)\(x_{dense}\)进行stack成一个vector:
\[x_0 = [ x_{embed,1}^T, ..., X_{embed,k}^T, X_{dense}^T]\]…(2)
2.2 Cross Network
新的cross network的核心思想是,将显式特征(explicit feature)以一种有效方式进行交叉。cross network由多个cross layers组成,每一个layer具有以下的公式:
\[x_{l+1} = x_0 x_l^T w_l + b_l + x_l = f(x_l, w_l, b_l) + x_l\]…(3)
其中:
- \(x_l, x_{l+1}\)是列向量(column vectors),分别表示来自第l层和第(l+1)层cross layers的输出;
- \(w_l, b_l \in R^d\)是第l层layer的weight和bias参数。
在完成一个特征交叉f后,每个cross layer会将它的输入加回去,对应的mapping function f:\(R^d \rightarrow R^d\),刚好等于残差\(x_{l+1} - x_l\)。一个cross layer的可视化如图2所示。

图2: 一个cross layer的visualization
特征的高阶交叉(high-degree interaction):cross network的独特结构使得交叉特征的阶(the degress of cross features)随着layer的深度而增长。对于第l层layer,它的最高多项式阶(在输入\(x_0\)上)是\(l+1\). 实际上,cross network由这些交叉项\(x_1^{\alpha_1} x_2^{\alpha_2} ... x_d^{\alpha_d}\)组成,对应的阶从1到l+1. 详见第3节。
复杂度分析:假设\(L_c\)表示cross layers的数目,d表示输入维度。那么,在该cross network中涉及的参数数目为:
\[d \times L_c \times 2\]一个cross network的时间和空间复杂度对于输入维度是线性关系。因而,比起它的deep部分,一个cross network引入的复杂度微不足道,DCN的整体复杂度与传统的DNN在同一水平线上。如此高效(efficiency)是受益于\(x_0 x_l^T\)的rank-one特性,它可以使我们生成所有的交叉项,无需计算或存储整个matrix。
cross network的参数数目少,从而限制了模型的能力(capacity)。为了捕获高阶非线性交叉,我们平行引入了一个deep network。
2.3 Deep Network
Deep network是一个fully-connected feed-forward神经网络,每个deep layer具有以下的公式:
\[h_{l+1} = f(W_l h_l + b_l)\]…(4)
其中:
- \(h_l \in R^{n_l}, h_{l+1} \in R^{n_{l+1}}\)分别是第l层和第(l+1)层hidden layer;
- \(W_l \in R^{n_{l+1} \times n_l}, b_l \in R^{n_{l+1}}\)是第l个deep layer的参数;
- \(f(\cdot)\)是ReLU function。
复杂度分析:出于简洁性,我们假设所有的deep layers具有相同的size。假设\(L_d\)表示deep layers的数目,m表示deep layer的size。那么,在该deep network中的参数的数目为:
\[d \times m + m + (m^2 + m) \times (L_d - 1)\]2.4 Combination Layer
Combination Layer将两个network的输出进行拼接(concatenate),然后将该拼接向量(concatenated vector)feed 进一个标准的logits layer上。
下面是一个二分类问题的公式:
\[p = \sigma ( [x_{L_1}^T, h_{L_2}^T] w_{logits})\]…(5)
其中:
- \(x_{L_1} \in R^d, h_{L_2} \in R^m\)分别是来自cross network和deep network的输出
- \(W_{logits} \in R^{d+m}\)是combination layer的weight vector,其中\(\sigma(x) = 1/(1+exp(-x))\)。
loss function是logloss,带有一个正则项。
\[loss = - \frac{1}{N} \sum_{i=1}^{N} y_i log(p_i) + (1-y_i) log(1-p_i) + \lambda \sum_{l} \| w_l \|^2\]…(6)
其中 \(p_i\)是等式(5)计算得到的probabilities,\(y_i\)是true labels,N是输入的总数,\(\lambda\)是\(L_2\)正则项参数。
我们对两个network进行jointly train,在训练期间,每个独立的network会察觉到另一个。
3.Cross Network分析
在这一节,我们分析了DCN的cross network,以便于更有效地理解。我们提供了三个视角:多项式近似,泛化到FM,有效投影。为了简洁,我们假设:\(b_i = 0\)
概念:假设在\(w_j\)中的第i个元素是\(w_j^{(i)}\)。对于多索引(multi-index) \(\alpha = [\alpha_1, ..., \alpha_d] \in N^d\),以及\(x = [x_1, ..., x_d] \in R^d\),我们定义了:\(\| \alpha \| = \sum_{i+1}^d \alpha_i\)。
术语:交叉项\(x_1^{\alpha_1} x_2^{\alpha_2} ... x_d^{\alpha_d}\)的阶(degree)由\(\|\alpha\|\)定义。一个多项式的阶由它的项的最高阶决定。
3.1 多项式近似
根据维尔斯特拉斯逼近定理(Weierstrass approximation theorem),任意满足特定平滑假设条件下的函数,可以通过一个多项式进行逼近到一个特定的精度上。因而,我们从多项式近似的角度分析了cross network。特别的,cross network会以一种高效的、有表现力的、能更好地对现实世界数据集进行泛化的方式,近似相同阶的多项式类。
我们详细研究了一个cross network,将它近似成相同阶的多项式类(polynomial class)。假定\(P_n(x)\)表示n阶的多元多项式类(multivariate polynomial class):
\[P_n(x)= \{ \sum_{\alpha} w_{\alpha} x_1^{\alpha_1} x_2^{\alpha_2} ... x_d^{\alpha_d} | 0 \le |\alpha| \le n, \alpha \in N^d \}\]…(7)
在该类中的每个多项式具有\(O(d^n)\)个系数。只有\(O(d)\)个参数,cross network包含了在相同阶的多项式中的所有交叉项,每一项的系数与其它项各不相同。
理论 3.1: 一个l-layer的cross network,具有i+1个layer,定义成:\(x_{i+1} = x_0 x_i^T w_i + x_i\)。假设网络的输入是\(x_0 = [x_1, x_2, ..., x_d]^T\),输出是\(g_l(x_0) = x_l^T w_l\),参数是\(w_i, b_i \in R^d\)。接着,多元多项式\(g_l(x_0)\)会以下面的类进行重现(reproduce):
\[\{ \sum_{\alpha} (w_0,...,w_l) x_1^{\alpha_1} x_2^{\alpha_2} ... x_d^{\alpha_d} | 0 \le |\alpha| \le l+1, \alpha \in N^d \}\]其中:
- 其中 \(c_\alpha = M_\alpha \sum_{i \in B_\alpha} \sum_{j \in P_\alpha} \prod_{k=1}^{|\alpha|} w_{i_k}^{j_k}\), \(M_\alpha\)是一个与\(w_i\)独立的常数
- \(i = [i_1, ..., i_{|\alpha|}]\)和 \(j = [j_1, ..., j_{|\alpha|}]\)是多元索引(multi-indices), \(B_{\alpha} = \{ y \in \{ 0, 1,...,l\}^{|\alpha |} | y_i < y_j \wedge y_{|\alpha|} = l \}\),
- \(P_\alpha\)是indice \((\underbrace{1, ..., 1}_{\alpha_1 times} ... \underbrace{d, ..., d}_{\alpha_d times})\)的所有排列(permutations)的集合。
定理3.1的理论证明详见paper中的附录。举个例子,\(x_1 x_2 x_3\)的系数\(c_\alpha\),其中\(\alpha = (1,1,1,0,...,0)\)。直到一些常数,其中\(l = 2, c_\alpha = \sum_{i,j,k \in P_\alpha} w_0^{(i)} w_1^{(j)} w_2^{(k)}\);其中\(l=3, c_\alpha = \sum_{i,j,k \in P_\alpha} w_0^{(i)} w_1^{(j)} w_3^{(k)} + w_0^{(i)} w_2^{(j)} w_3^{(k)} + w_1^{(i)} w_2^{(j)} w_3^{(k)}\)
3.2 FM的泛化
cross network共享参数,类似于FM模型的参数共享,并扩展到了一个更深的结构上。
在FM模型中,特征\(x_i\)与一个 weight vector \(v_i\)相关联,交叉项\(x_i x_j\)的权重通过 \(<v_i, v_j>\)计算得到。在DCN中,\(x_i\)与标量\(\{ w_k^{(i)} \}_{k=1}^{l}\)有关,\(x_i x_j\)的权重是集合\(\{ w_k^{(i)}\}_{k=0}^l\)和\(\{ w_k^{(j)}\}_{k=0}^{l}\)的参数乘积。两种模型都会为每个特征学到一些与其它特征相互独立的参数,交叉项的权重是相应参数的一种特定组合。
参数共享(parameter sharing)不权使得模型更有效,也使模型可以泛化到未见过的特征交叉上,对噪声更健壮。例如,使用sparse features的数据集。如果两个二元特征\(x_i\)和\(x_j\)很少或者几乎从未在训练集中共现过,假设,\(x_i \ne 0 \wedge x_j \ne 0\),接着,学到关于\(x_i x_j\)的权重不会带有对预测有意义的信息。
FM是一个浅层结构(shallow structure),受限于交叉项的阶是2. 而DCN可以构建所有的交叉项\(x_1^{\alpha_1} x_2^{\alpha_2} ... x_d^{\alpha_d}\),其中阶 \(|\alpha|\)由一些常数决定,见理论3.1。因而,cross network扩展了参数共享的思想,将单个layer扩展到多个layer,并且有更高阶的交叉项。注意,与高阶FM不同的是,在cross network中的参数数目,只随着输入维度线性增长。
3.3 有效投影
每个cross layer会以一种有效方式,将在\(x_0\)和\(x_l\)间的所有pairwise交叉进行投影到输入维度上。
考虑到\(\tilde{x} \in R^d\)是一个cross layer的输入。cross layer首先隐式构建了\(d^2\)个关于\(x_i \tilde{x}_j\)的pairwise交叉,接着以一种内存高效的方式,隐式地将它们投影到维度d上。这种直接的方式会带来3次方开销。
我们的cross layer提供了一种有效的解决方式,将开销减小到维度d的线性开销上。考虑\(x_p = x_0 \tilde{x}^T w\)。事实上等于:
\[x_p^T = [x_1\tilde{x}_1 ... x_1\tilde{x}_d ... x_d\tilde{x}_1 ... x_d\tilde{x}_d] \left[ \begin{array}{ccc} w&0&...&0\\ 0&w&...&0\\ \vdots&\vdots&\ddots&\vdots\\ 0&0&...&w \end{array} \right]\]…(8)
其中,row vectors包含了所有\(d^2\) 个 \(x_i \tilde{x}_j\)的pairwise交叉,投影矩阵具有一个块对角化结构,其中:\(w \in R^d\)是一个列向量。
4.实验结果
在本节中,我们评估了CDN在多个数据集上的效果。
4.1 Criteo Display Ads数据集
Criteo Display Ads数据集用于预测点击率。具有13个integer features和26个categorial features。其中,每个category都具有一个很高的维度基数。对于该数据集,在logloss上提升0.001可以看成是巨大的提升。当考虑到在一个很大的用户基数时,在预测准确率(prediction accuracy)的一个小的提升,可以为公司带到来一个大的回报。数据包含了11GB的包含7天的用户日志(~41000,000条记录)。我们使用前6天的数据做为训练,并将第7天的数据随机划分成等size的validation和test set。
4.2 实现细节
DCN在tensorflow上实现,我们会讨论一些关于训练CDN的细节。
数据处理和embedding。实数型特征通过一个log转换进行归一化。对于类别型特征,会将这些特征嵌入到dense vectors中,维度为 \(6 \times (category \ cardinality) ^{1/4}\)。最后将所有的embedding结果拼接(concatenating)成一个维度为1026的向量。
优化(Optimization):我们使用Adam optimizer,mini-batch进行随机优化。batch size=512. Batch normalization被应用于deep网络,gradient clip norm设置为100.
正则化:我们使用early stopping,我们未发现L2正则或dropout很有效。
超参数:我们基于一个grid search来在hidden layers的数目、size、初始learning rate以及cross layers的数目上进行探索。hidden layers的数目范围为2一5, hidden layers的数目从32到1024. 对于DCN,cross layers的数目从1到6.初始learning rate从0.0001依次递增调到0.001. 所有试验都使用early stopping,训练step为150000, 超过它可能会发生overfitting。