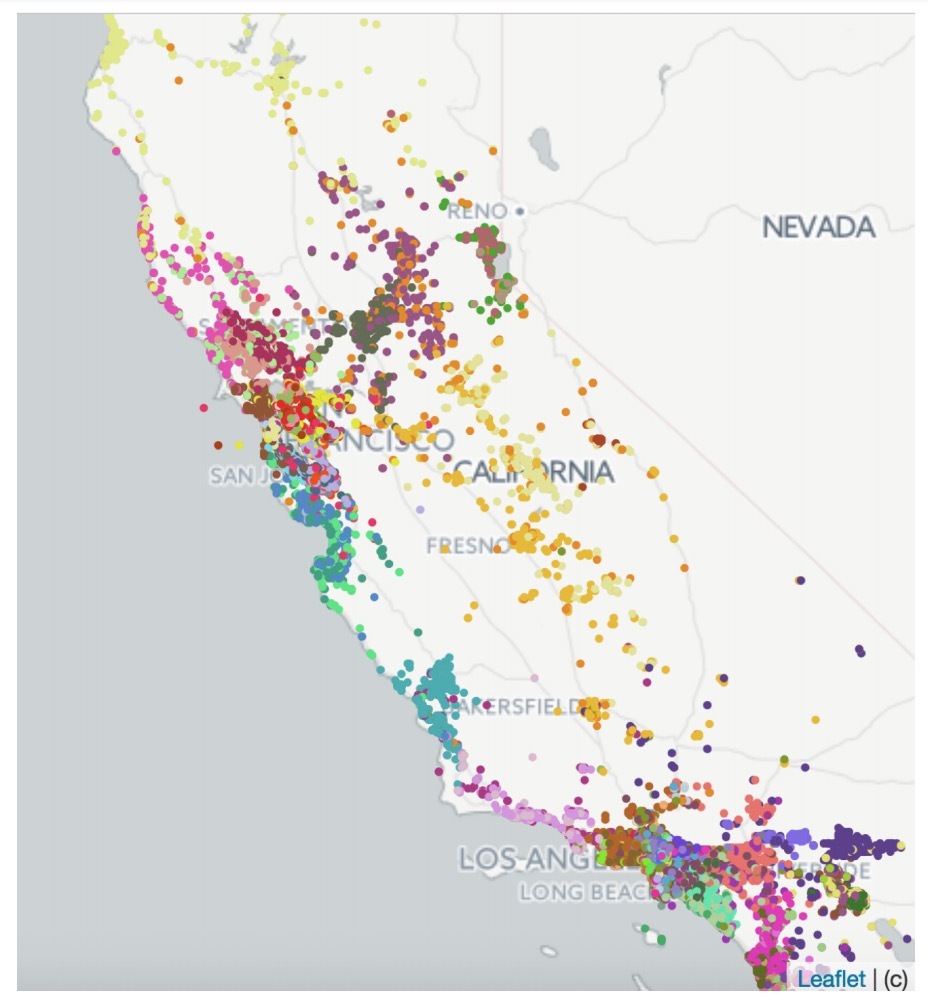
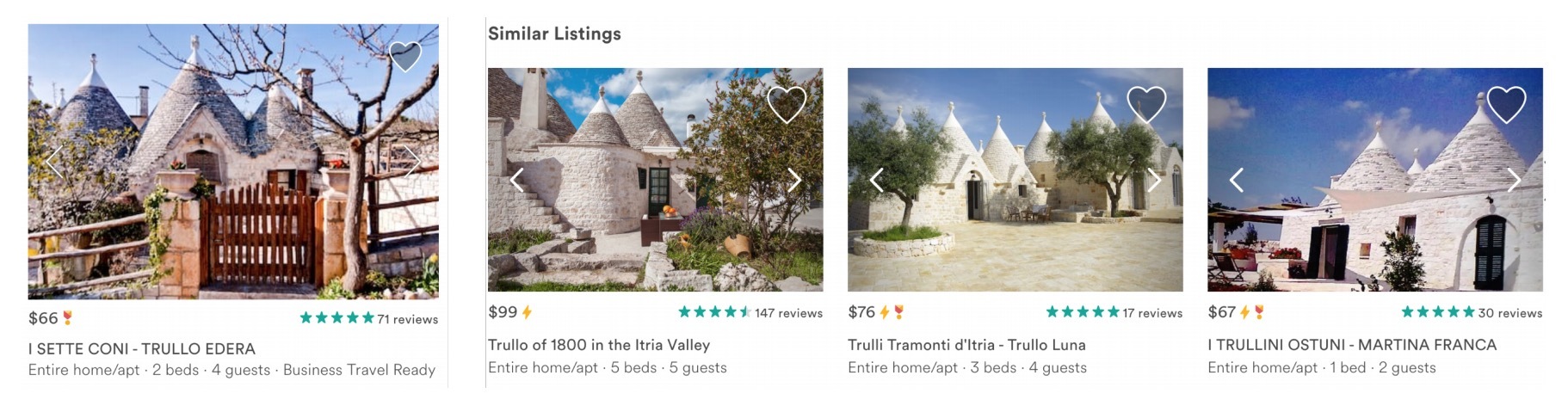
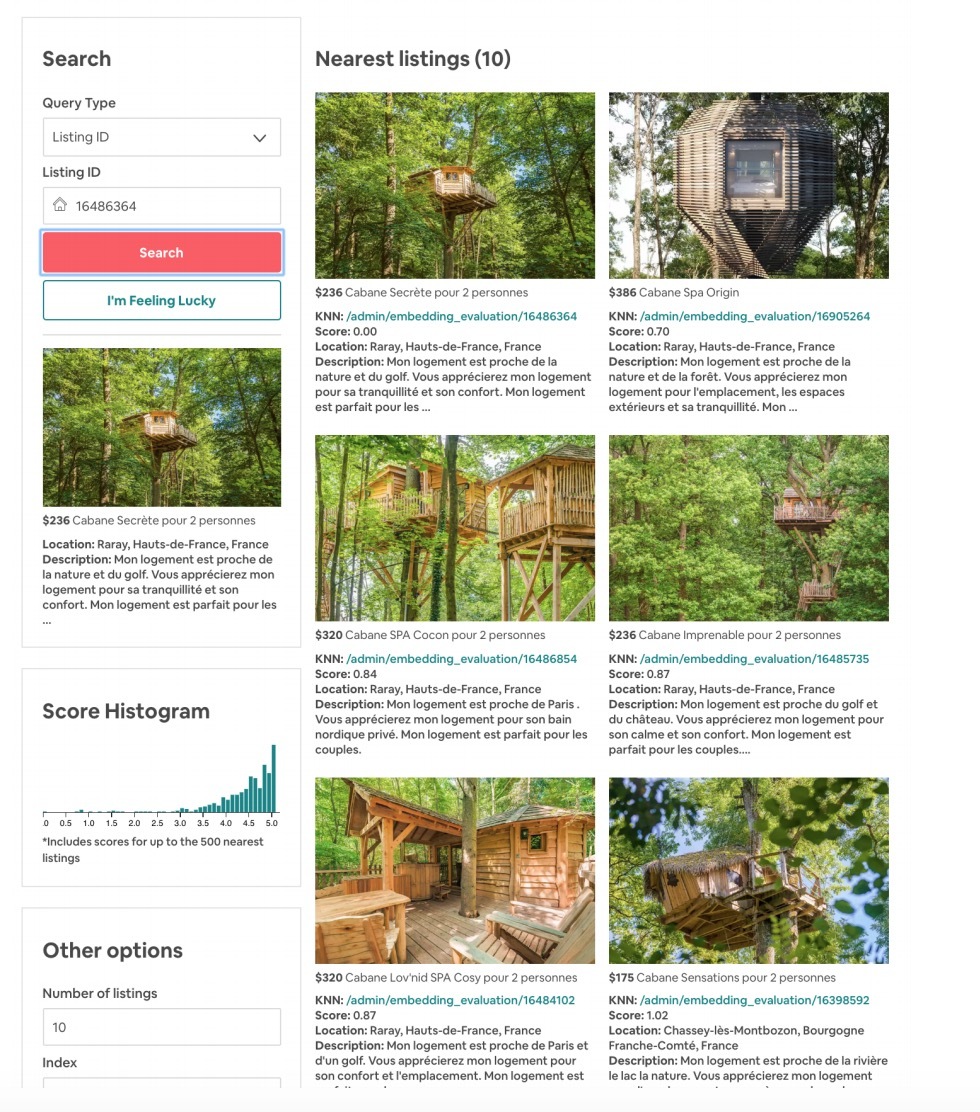
hulu在NIPS 2018上开放了它们的方法:《Fast Greedy MAP Inference for Determinantal Point Process to Improve Recommendation Diversity》, 来解决推荐多样性问题。我们来看下:
摘要
DPP是一种优雅的概率模型。然而,为DPP进行最大后验推断(MAP:maximum a posteriori inference),在许多应用中扮演着一个重要角色,这是一个NP-hard问题。流行的贪婪算法贪心法计算开销很大,很难用于大规模实时场景。为了克服计算挑战,在本paper中,我们提出了一种新算法,可以极快加速DPP的贪婪后验推断(greedy MAP inference)。另外,我们的算法也会应用到以下场景:在结果序列中,只需要在附近很少的items上进行多样性排斥。我们应用该算法来生成相关性和多样性推荐。实验结果表明,我们提出的算法要比state-of-the-art的其它方法要快,并在一些公开数据集上提供了一个更好的relevance-diversity trade-off,同时也在online A/B test上要好。
1.介绍
行列式点过程(DPP: determinantal point process)首先在[33]中介绍用来给出在热平衡(thermal equilibrium)中的费米子系统的分布。除了在量子物理学和随机矩阵上的早期应用,它也可以被应用到多种机器学习任务上,比如:多人姿态估计(multiple person pose estimation)、图片搜索、文档归纳、视频归纳、产品推荐、tweet timeline生成。对比其它概率模型(比如:图形模型),DPP的一个主要优点是,对于不同类型的推断(包含:conditioning和sampling),它遵循多项式时间算法(polynomial-time algorithms)。
上述推断的一个例外是:最大后验推断(MAP)(例如:寻找具有最高概率的items集合),它是一个NP-hard问题。因此,具有较低计算复杂度的近似推断方法(approximate inference)更受欢迎。paper[17]提出了针对DPP的一种近似最优的MAP推断(inference)。然而,该算法是一个基于梯度的方法,它在每次迭代上评估梯度时具有较高的计算复杂度,使得它对于大规模实时应用来说不实际。另一个方法是广泛使用的贪心法(greedy algorithm),事实证明:DPP中的log概率是次模的(submodular)。尽管它具有相对较弱的理论保证,但它仍被广泛使用,因为它在经验上对效果有前景。贪心法(greedy algorithm)[17,32]的已知实现具有\(O(M^4)\)的复杂度,其中M是items的总数目。Han et al.的最近工作[20]通过引入一些近似可以将复杂度降到\(O(M^3)\),但会牺牲accuracy。在本paper中,我们提出了关于该w贪心法的一种准确(exact)实现,它具有\(O(M^3)\)的复杂度,它经验上比近似算法[20]要更快。
DPP的基本特性是:它会为那些相互比较多样化(diverse)的items集合分配更高的概率。在一些应用中,选择的items是以序列方式展示的,在少量相邻items间会有负作用(negative interactions)。例如,当推荐一个关于items的长序列给用户时,每个时候只有少量序列会捕获用户的注意力。在这种场景下,要求离得较远的items相互间更多样(diverse)些是没必要的。我们会为这种情况开发快速算法。
本文贡献。在本paper中,我们提出了一种新算法,它能极大加速DPP的greedy MAP inference。通过增量更新Cholesky因子,我们的算法可以将计算复杂度降至\(O(M^3)\),运行\((O(N^2 M))\)的时间来返回N个items,使它在大规模实时场景中变得可用。据我们所知,这是首个具有很低时间复杂度的greedy Map inferenece for DPP的准确实现(exact implementation)。
另外,我们也将该算法应用到以下场景:只需要在一个滑动窗口中保证多样性。假设window size为:\(w < N\),复杂度可以减小到\(O(w N M)\)。这个特性使得它很适合用于以下场景,即:在一个短的滑动窗口内保证多样性。
注:
- M:items的总数目
- N:最终返回N个items结果
- w:window size
最后,我们将提出的算法应用到推荐任务上。推荐多样化的items可以给用户探索的机会来发现新items 和 意外发现的items,也使得该服务可以发现用户的新兴趣。正如实验结果所示,在公开数据集和online A/B test上,对比起其它已知的方法,DPP-based方法在相关性和多样性的trade-off上更好。
2.背景
概念。
- 集合使用大写字母表示,比如:Z。
- \(\#Z\)表示Z中的元素数。
- 向量和矩阵分别通过粗体小写字母和粗体大写字母表示。
- \((\cdot)^{\top}\)表示向量或矩阵的转置。
- \(\langle x,y \rangle\)是向量x和y的内积。
- 给定子集X和Y,\(L_{X,Y}\)是L的sub-matrix,通过行中的X和列中的Y索引。
出于简洁,我们假设:
- \(L_{X,X} = L_X, L_{X,\lbrace i \rbrace}=L_{X,i}\),
- 以及\(L_{\lbrace i \rbrace, X} = L_{i,X}\)。
- \(det(L)\)是L的行列式,惯例上\(det(L_\emptyset)=1\)。
2.1 DPP
DPP是一个优雅的概率模型,它可以表示负作用(negative interactions)[30]。正式的,对于一个离散集合\(Z=\lbrace 1,2,...,M \rbrace\),一个DPP的\(P\)表示在Z的所有子集集合(共\(2^Z\)种)上的一个概率度量(probability measure)。当P会为空集给出非零概率时,存在一个矩阵\(L \in R^{M \times M}\),对于所有子集\(Y \subseteq Z\),Y的概率为:
\[P(Y) \propto det(L_Y)\]…(1)
其中:L是一个实数型(real)、半正定(positive semidefinite (PSD))的kernel matrix,它通过Z的元素进行索引。在该分布下,许多类型的推断(inference)任务(比如:marginalization, conditioning,sampling)可以在多项式时间内执行,除了后验推断(MAP inference)外:
\[Y_{map} = \underset{y \subseteq Z}{argmax} \ det(L_Y)\]在一些应用中,我们需要引入一个在Y上的基数约束,让它返回具有最大概率的固定size的一个集合,这会为k-DPP产生MAP inference。
除了在第一节介绍的DPP在MAP inference上的工作外,一些其它工作也提出了抽取样本并返回最高概率的样本。在[16]中,一种快速抽样算法,它具有复杂度\(O(N^2 M)\),其中提供了L的特征分解(eigendecomposition)。尽管[16]中的更新规则与我们的工作相似,但有两个主要的不同之处使得我们的方法更高效。首先,[16]的L的特征分解具有时间复杂度\(O(M^3)\)。当我们只需要返回较少数目的items时,该计算开销主宰着运行时开销。通过对比,我们的方法只需要\(O(N^2 M)\)的复杂度来返回N个items。第二,DPP的抽样方法通常需要执行多个样本试验来达到贪婪算法的可比的经验式性能,它会进一步增加了计算复杂度。
2.2 贪婪次模最大化(Greedy Submodular Maximization)
一个集合函数是在\(2^Z\)上定义的一个实数函数。如果一个集合函数f的边际增益(marginal gains)是非增的(no-increasing),例如:对于任意的\(i \in Z\)和任意的\(X \subseteq Y \subseteq Z \setminus \lbrace i \rbrace\),当新增一项i时,满足:
\[f(X \cup \lbrace i \rbrace) - f(X) \geq f(Y \cup \lbrace i \rbrace) - f(Y)\]其中:
- f是次模函数(submodular)
在DPP中的log概率函数\(f(Y)=log det(L_Y)\)是次模函数(submodular),在[17]中有介绍。次模最大化(submodular maximization)对应是:寻找能让一个次模函数最大化的一个集合。DPP的MAP inference是一个次模最大化过程。
次模函数最大化通常是NP-hard的。一个流行的近似方法是基于贪心法[37]。初始化为\(\emptyset\),在每次迭代中,如果增加一个item能最大化边际增益(marginal gain):
\[j = \underset{i \in Z \backslash Y_g}{argmax} \ f(Y_g \cup \lbrace i \rbrace) - f(Y_g)\]那么它就会被添加到\(Y_g\)中,直到最大边际增益(maximal marginal gain)为负 或者 违反了基数约束。当f是单调的(monotone),例如:\(f(X) \leq f(Y)\)对于任意的\(X \subseteq Y\),贪心算法会遵循一个\((1-1/e)\)的近似保证,它服从一个基数约束[37]。对于通用的无约束的次模最大化(no constraints),一个修改版的贪心算法会保证(1/2)近似。尽管这些理论保证,在DPP中广泛使用的贪心算法是因为它的经验上的性能保障(promising empirical performance)。
2.3 推荐多样性
提升推荐多样性在机器学习中是一个活跃的领域。对于该问题,有一些方法在相关度和差异度间达到了较好的平衡【11,9,51,8,21】。然而,这些方法只使用了成对差异(pairwise dissimilarity)来描述整个列表(list)的总的多样性,并不会捕获在items间的一些复杂关系(例如:一个item的特性可以通过其它两者的线性组合来描述)。一些尝试构建新的推荐系统的其它工作,提出通过学习过程来提升多样性【3,43,48】,但这会使得算法变得更不通用、更不适合于直接集成到已经存在的推荐系统中。
在【52,2,12,45,4,44】中提出的一些工作,定义了基于类目信息(taxonomy information)的相似矩阵。然而,语义型类目信息(semantic taxonomy information)并不总是有提供,基于它们来定义相似度可能不可靠。一些其它工作提出基于解释(explanation)[50]、聚类(clustering)[7,5,31]、特征空间(feature space)[40]、或覆盖(coverage)[47,39]来定义多样性指标(diversity metric)。
本文中,我们使用DPP模型以及我们提出的算法来最优化在相关度和多样性间的权衡。不同于之前已经存在的成对差异(pairwise dissimilarities)的技术,我们的方法会在整个子集的特征空间(feature space)中定义多样性。注意,我们的方法本质上与推荐中DPP-based的方法不同。在[18,34,14,15]中,他们提出了在购物篮(shopping basket)中推荐商品,核心是学习DPP的kernel matrix来描述items间的关系。作为对比,我们的目标是通过MAP inference来生成一个相关度和多样性推荐列表。
本paper中考虑的diversity不同于在[1,38]中的聚合多样性(aggregate diversity)。增加聚合多样性可以提升长尾items,而提升多样性则会在每个推荐列表中更偏好于多样性的items。
3.Fast Greedy MAP Inference
在本节中,我们提出了一种对于DPP的greedy Map inference算法的快速实现。在每轮迭代中,item j满足:
\[j = \underset{i \in Z \backslash Y_g}{argmax} \ log det(L_{Y_g \cup \lbrace i \rbrace}) - log det(L_{Y_g})\]…(1)
那么该item就会被添加到已经选中的item set \(Y_g\)中。由于L是一个半正定矩阵(PSD matrix),所有主子式都是半正定的(PSD)。假设\(det(L_{Y_g}) > 0\),\(L_{Y_g}\)的柯列斯基分解(Cholesky decomposition)提供如下:
\[L_{Y_g} = V V^{\top}\]其中:
- V是一个可逆下三角矩阵
对于任意\(i \in Z \backslash Y_g\),\(L_{Y_g \cup \lbrace i \rbrace}\)的柯列斯基分解(Cholesky decomposition)可以定为:
\[L_{Y_g \cup \lbrace i \rbrace} = \begin{bmatrix} L_{Y_g} & L_{Y_{g,i}} \\ L_{i,Y_g} & L_{ii} \\ \end{bmatrix} = \begin{bmatrix} V & 0 \\ c_i & d_i \\ \end{bmatrix} \begin{bmatrix} V & 0 \\ c_i & d_i \\ \end{bmatrix}^{\top}\]…(2)
其中,行向量\(c_i\)和标量\(d_i \geq 0\)满足:
\[V_{c_i}^{\top} = L_{Y_{g,i}}\]…(3)
\[d_i^2 = L_{ii} - \| c_i \|_2^2\]…(4)
另外,根据等式(2), 它可以为:
\[det(L_{Y_g \cup \lbrace i \rbrace}) = det(VV^{\top}) \cdot d_i^2 = det(L_{Y_g}) \cdot d_i^2\]…(5)
因此,等式(1)等于:
\[j = \underset{i \in Z \backslash Y_g}{argmax} \ log(d_i^2)\]…(6)
一旦等式(6)被求解,我们可以根据等式(2),进一步,\(L_{Y_g \cup \lbrace j \rbrace}\)的Cholesky decomposition变成是:
\[L_{Y_g \cup \lbrace j \rbrace} = \begin{bmatrix} V & 0 \\ c_j & d_j \\ \end{bmatrix} \begin{bmatrix} V & 0 \\ c_j & d_j \\ \end{bmatrix}^{\top}\]…(7)
其中,\(c_j\)和\(d_j\)是已经提供的。当一个新item被添加到\(Y_g\)之后,\(L_{Y_g}\)的Cholesky因子可以被有效更新。
对于每个item i,\(c_i\)和\(d_i\)可以被增量更新。在等式(6)被求解后,将\(c_i'\)和\(d_i'\)定义成\(i \in Z \backslash (Y_g \cup \lbrace j \rbrace)\)的新向量和标量。根据等式(3)和等式(7),我们有:
\[\begin{bmatrix} V & 0 \\ c_i & d_i \\ \end{bmatrix} c_i'^T = L_{Y_g \cup \lbrace j \rbrace, i} = \begin{bmatrix} L_{Y_{g,i}} \\ L_{ji} \\ \end{bmatrix}\]…(8)
通过将等式(3)和等式(8)组合,我们可以对\(c_i\)和\(d_i^2\)进行更新,有:
\[c_i' = \begin{bmatrix} c_i & (L_{ji}- \langle c_j,c_i\rangle) / d_j \end{bmatrix} \doteq \begin{bmatrix} c_i & e_i \end{bmatrix}\]等式(4)意味着:
\[d_i'^2 = L_{ii} - \| c_i' \|_2^2 = L_{ii} - \| c_i \|_2^2 - e_i^2 = d_i^2 - e_i^2\]…(9)
最初,\(Y_g = \emptyset\), 等式(5)意味着: \(d_i^2 = det(L_{ii}) = L_{ii}\)。完整算法会在算法1中有总结。对于无约束的MAP inference来说停止条件(stopping criteria)是\(e_j^2 < 1\),或者\(\#Y_g > N\)(当使用基数约束时)。对于后者,我们引入了一个很小的数\(\epsilon > 0\),并为\(1/d_j\)的数值稳定值将\(d_j^2 < \epsilon\)设置为停止条件(stopping criteria)。

算法1
在k次迭代中,对于每个item \(i \in Z \backslash Y_g\),更新\(c_i\)和\(d_i\)涉及到两个长度为k的向量内积,总复杂度为\(O(kM)\)。因此,算法1对于无约束MAP inference会在\(O(M^3)\)运行,并返回N个items。注意,对于\(c_i\)和\(d_i\)通过额外的\(O(NM)\)(或者对于无约束情况下的\(O(M^2)\))空间来达成。
4.带滑动窗口的多样性
在一些应用中,选中的items集合会以序列的方式展示,只需要在一个滑动窗口内控制多样性。窗口大小(window size)为w。我们将等式(1)修改为:
\[j = \underset{i \in Z \backslash Y_g}{argmax} \ log det(L_{Y_g^w \cup \lbrace i \rbrace}) - log det(L_{Y_g^w})\]…(10)
其中,\(Y_g^w \subseteq Y_g\)包含了 w-1 个最新添加的items。当\(\#Y_g \geq w\)时,方法[32]的一种简单修改版本可以在复杂度\(O(w^2 M)\)上求解等式(1)。我们应用我们的算法到该场景下,以便等式(10)可以在\(O(wM)\)时间上求解。
在第3节中,当\(V, c_i, d_i\)可提供时,我们展示了如何有效选择一个新item。对于等式(10),V是\(L_{Y_g^w}\)是Cholesky因子。在等式(10)求解后,我们可以相似地去为\(L_{Y_g^w \cup \lbrace i \rbrace}\)更新\(V, c_i, d_i\)。当在\(Y_g^w\)中的items数目是w-1时,为了更新\(Y_g^w\),我们也需要移除在\(Y_g^w\)中最早添加的items。当最早添加的item被移除时,对于更新\(V,c_i, d_i\)的详细推导,会在补充材料中给出。

算法2
完整算法如Algorithm 2所示。第10-21行展示了在最早item被移除后,如何适当去更新\(V, c_i, d_i\)。在第k次迭代中,其中\(k \geq w\),更新V、所有的\(c_i\)、\(d_i\)各需要O(W^2)、O(wM)、O(M)时间。算法2需要总复杂度\(O(w N M)\)来返回\(N \geq w\)个items。数值稳定性会在补充材料中讨论。
5.提升推荐多样性
在本节中,我们描述了一个DPP-based方法来为用户推荐相关和多样的items。对于一个用户u,profile item set \(P_u\)被定义成用户喜欢的items集合。基于\(P_u\),推荐系统会为该用户推荐items \(R_u\)。
该方法会采用三个输入:
- \(C_u\):表示一个候选item集合
- \(r_u\):指的是一个分值向量(score vector) ,它表示在\(C_u\)中的items的相关性(relevance)
- \(S\):一个半正定矩阵,表示每个items pair的相似度
前两个输入可以通过许多传统的推荐算法的内部结果中获得。第三个输入(相似矩阵S),可以基于items的属性、与用户的交互关系、或者两者组合来获得。该方法可以看成是对items相关度及它们的相似度的一个ranking算法。
为了在推荐任务上应用DPP模型,我们需要构建kernel matrix。在[30]中所示,kernel matrix可以写成一个格拉姆矩阵(Gram matrix): \(L=B^T B\),其中B的列可以是表示items的向量(vectors)。我们可以将每个列向量\(B_i\)通过\(r_i \geq 0\)(item score)和一个\(f_i \in R^D\)(具有\(\| f_i \|_2 = 1\)的归一化向量)的两者乘积的方式来构建。kernel L的条目可以被写成是:
\[L_{ij} = \langle B_i,B_j \rangle = \langle r_i f_i, r_j f_j \rangle = r_i r_j \langle f_i, f_j \rangle\]…(11)
我们可以将** \(\langle f_i, f_j \rangle\) ** 看成是item i和item j间的相似度的度量,例如:\(\langle f_i, f_j \rangle = S_{ij}\)。因此,user u的kernel matrix可以被写成是:
\[L = Diag(r_u) \cdot S \cdot Diag(r_u)\]其中:
- \(Diag(r_u)\)是对角阵(diagonal matrix),它的对角向量(diagonal vector)是\(r_u\)。
\(R_u\)的log概率是:
\[log det(L_{R_u}) = \sum\limits_{i \in R^u} log(r_{u,i}^2) + log det(S_{R_u})\]…(12)
当\(R^u\)的item representations是正交时(即相似度为0),等式(12)的第二项是最大化的,因而它可以提升多样性。它很清楚地展示了,DPP模型是如何解释被推荐items的相关度和多样性。
[11,51,8]中的一些好特性(nice feature)是,它们涉及一个可调参数,它会允许用户来调节在相关度和多样性间的trade-off。根据等式(12),原始的DPP模型不会提供这样一个机制。我们会修改\(R_u\)的log概率为:
\[log P(R_u) \propto \theta \cdot \sum\limits_{i \in R^u} r_{u,i} + (1-\theta) \cdot log det(S_{R_u})\]其中\(\theta \in [0, 1]\)。这对应于一个使用以下kernel的DPP:
\[L' = Diag(exp(\alpha r_u)) \cdot S \cdot Diag(exp(\alpha r_u))\]其中\(\alpha = \theta / (2(1-\theta))\)。我们也会获得log概率的边际增益(marginal gain):
\[log P(R_u \cup \lbrace i \rbrace) - log P(R_u) \propto \theta \cdot r_{u,i} + (1-\theta) \cdot (log det(S_{R_u \cup \lbrace i \rbrace}) - log det(S_{R_u}))\]…(13)
接着,算法1和算法2可以轻易修改成:使用kernel matrix S来最大化等式(13)。
注意,对于推荐任务,我们需要相似度\(S_{i,j} \in [0, 1]\),其中0意味着最大的多样性(diverse),1意味着最相似(similar)。当归一化向量\(\langle f_i, f_j \rangle\)的内积可以采用负值。在极端情况下,最多样的对(most diverse pair) \(f_i = -f_j\),但相应的子矩阵(sub-matrix)的行列式为0, 这与\(f_i = f_j\)相同。为了保证非负性(nonnegativity),当将S保持为一个半正定矩阵时,我们会采用一个线性映射,比如:
\[S_{ij} = \frac{1+\langle f_i,f_j \rangle}{2} = \langle \frac{1}{\sqrt{2}} \begin{bmatrix} 1 \\ f_i \end{bmatrix}, \frac{1}{\sqrt{2}} \begin{bmatrix} 1 \\ f_i \end{bmatrix} \rangle \in [0, 1]\]6.实验结果
在本节,我们会在人造数据集和真实推荐任务上评估和比较提出的算法。算法实现使用Python(向量化vectorization)来实现。实验在2.2GHz Intel Core i7和16GB RAM上进行。
6.1 人造数据集(Synthetic Dataset)
在本节,我们会评估算法1在DPP MAP inference上的效果。我们根据[20]来设置实验。kernel matrix的条目满足等式(11),其中:
\(r_i = exp(0.01 x_i + 0.2)\),它使用从正态分布\(N(0,1)\)上抽取的\(x_i \in R\),以及\(f_i \in R^D\)(其中:D与总的item size M相同,),以及从\(N(0,1)\)独立同分布(i.i.d.)的方式抽取的条目,以及接着进行归一化。
我们提出的faster exact algorithm (FaX)会与带有lazy评估[36]的Schur complement、以及faster approximate algorithm (ApX) [20]进行比较。
…
 图1
图1
6.2 短序列推荐
在本节,我们会评估:在以下两个公开数据集上,推荐items的短序列给用户的效果。
- Netflix Prize:该数据集包含了用户的电影评分。
- Million Song Dataset:该数据集包含了用户播放歌曲的数目。
对于每个数据集,我们通过为每个用户随机选择一个交互item的方式来构建测试集,接着使用剩余数据来进行训练。我们在[24]上采用一个item-based推荐算法[24]来学习一个item-item的PSD相似度矩阵S。对于每个用户:
- profile set \(P_u\)包含了在训练集中的交互items,
- 候选集\(C_u\)通过在\(P_u\)中的每个item的50个最相似items进行union得到。
- 两个数据集的\(\#C_u\)的中位数(median)分别是735(netflix)和811(song).
对于在\(C_u\)中的任意item,相关分是对在\(P_u\)中所有items的聚合相似度。有了S和\(C_u\),分值向量(score vector) \(r_u\),算法会推荐\(N=20\)个items。
推荐的效果指标包含了MRR (平均倒数排名:mean reciprocal rank)、ILAD(intra-list average distance)、ILMD(intra-list minimal distance)。它们的定义如下:
\[MRR = \underset{u \in U}{mean} P_u^{-1} \\ ILAD = mean_{u \in U} \underset{i,j \in R_u, i \neq j}{mean} (1-S_{ij}) \\ ILMD = \underset{u in U}{mean} \underset{i,j \in R_u, i \neq j}{min} (1-S_{ij})\]其中,U是所有用户的集合,\(p_u\)是在测试集中关于items的最小排序位置。
- MRR会测度相关度
- ILAD和ILMD会度量多样性(diversity)
我们也会在附录中比较指标PW recall(popularity weighted recall). 对于这些指标来说,越高越好。
我们的DPP-based算法(DPP),会与MMR(最大化相关性:maximal marginal relevance)、MSD(最大化多样性:maxsum diversification)、entropy regularizer (Entropy)、基于覆盖的算法(Cover)进行比较。他们涉及到一个可调参数来调节相关性和多样性间的trade-off。对于Cover,参数为\(\gamma \in [0,1]\),它定义了饱和函数\(f(t) = t^{\gamma}\)。
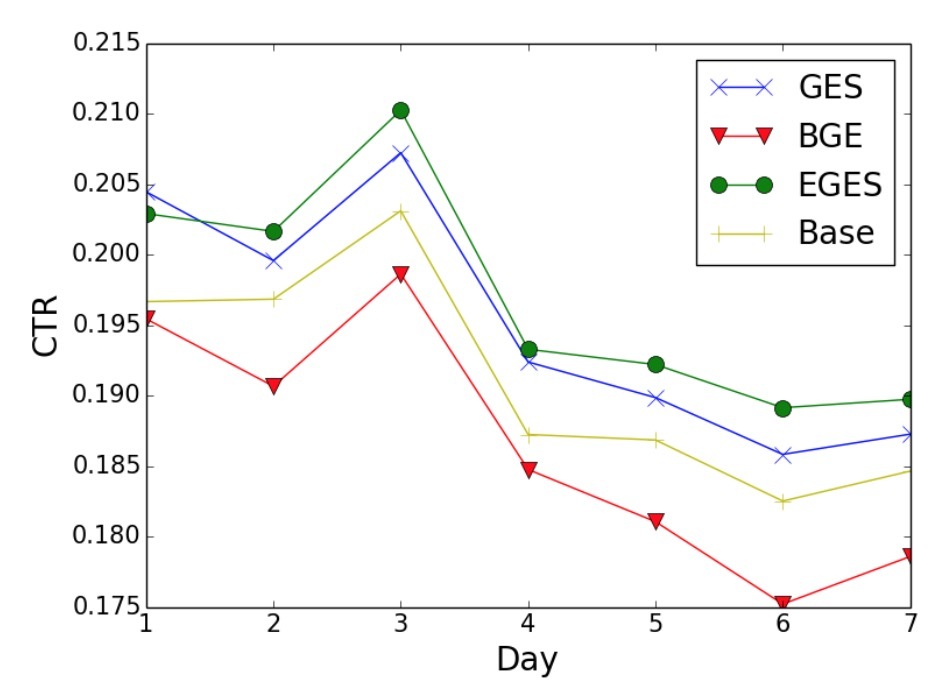
在第一个实验中,我们在Netflix数据集上测试了DPP的参数\(\theta \in [0,1]\)的trade-off影响。结果如图2所示。随着\(\theta\)的增加,MRR一开始会逐渐提升,当\(\theta \approx 0.7\)时达到最佳值,接着略微减小。ILAD和ILMD会随\(\theta\)的递增而单调递减。当\(\theta=1\)时,DPP会返回最高相关分值的items。因此,需要考虑采用适度的多样性,从而达到最佳效果。

图2
在第2个实验中,为了区分参数的多种trade-off,会比较在相关度和多样性间的效果trade-off,如图3所示。不同算法选择的参数几乎具有相近范围的MRR。可以看到,Cover在Netflix Prize上效果最好,但在Song数据集上最差。在其它算法间,DPP则具有最好的relevance-diversity trade-off效果。如表1所示。MMR, DSP,DPP要比Entropy和Cover快。因为DPP的运行99%概率要小于2ms,它可以用于实时场景。

表1

图3
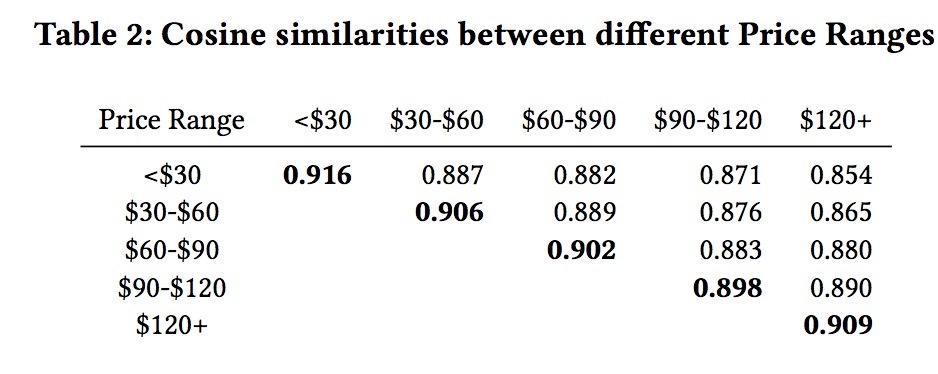
我们在一个电影推荐系统中在线进行A/B test,并运行了4周。对于每个用户,候选电影的相关得分通过一个在线打分模型来生成。离线矩阵因子算法【26】每天会进行训练来生成电影表示,它可以用于计算相似度。对于控制组(control group),5%的users会被随机选中,然后展示给最高相关得分的N=8部电影。对于对照组(treatment group),另一5%的随机users会通过一个fine-tuned的trade-off参数控制的DPP来生成N部电影。两个在线指标:观看标题数和观看时长(分钟)的提升,如表2所示。结果展示了与使用MMR的另一随机选中的users的对比。可以看到,DPP要比没有多样性算法的系统、以及使用MMR的系统上效果要好。

表2
6.3 长序列推荐
在这部分,我们会评估算法2的效果,来为用户推荐items的长序列。对于每个数据集,我们通过为每个用户随机选择5个交互items来构建测试集(test set),并使用剩余部分来进行训练。每个长序列包含了N=100个items。我们选择window size \(w=100\)以便在序列中的每w个后续items是多样化的。总的来说,如果每次一个用户可以只看到序列的一小部分,w可以是这部分大小(portion size)的阶。其它设置与前一节一致。
效果指标包含了nDCG(normalized discounted cumulative gain)、ILALD(intra-list average local distance)、ILMLD(intra-list minimal local distance)。后两者的定义为:
\[ILALD = mean_{u \in U} mean_{i,j \in R^u, i \neq j,d_{ij} \leq w} (1-S_{ij}), \\ ILMLD = mean_{u \in U} min_{i,j \in R^u, i \neq j, d_{ij} \leq w} (1 - S_{ij})\]其中,\(d_{ij}\)是在\(R_u\)中item i和j的位置距离。相似的,指标越高越好。为了做出一个公平对比,我们会修改在MMR和MSD中的多样性项(diversity terms),以便它们只考虑最近添加的w-1个items。Entropy 和 Cover是不可测的,因为他们不适合该场景。通过调节多个trade-off参数,我们可以在图4中看到MMR, MSD, DPP的相关性和多样性的trade-off效果。不同算法选中的参数与nDCG具有近似相同的范围。我们可以看到,DPP的效果在relevance-diversity上的trade-off要最好。我们也会在补充材料中比较的PW Recall的指标。

图4
7.结论
在本paper中,我们介绍了一种DPP greedy MAP inference的fast和exact实现。我们的算法的时间复杂度\(O(M^3)\),它大大低于state-of-art exact实现。我们提出的加速技术可以应用于在目标函数中PSD矩阵的log行列式的其它问题,比如entropy regularizer。我们也会将我们的快速算法应用到以下场景:只需要在一个滑动窗口中多样化。实验展示了我们的算法要比state-of-art算法要快,我们提出的方法在推荐任务上提供了更好的relevance-diversity的trade-off。
附录
博主注
为什么DPP会对quality和diversity进行balance?
DPP如何平衡取出的子集的quality和diversity?Kulesza and Taskar在《机器学习中的DPP》[29 3.1节]提供的分解给出了一个更直观的理解:
建模问题的一个非常重要的实际关注点是可解释性;实践者必须以一种直觉的方式来理解模型参数。DPP kernel的entries不全是透明的,他们可以看成是相似度的度量——受DPP的primary qualitative characterization的作为多样化过程(diversitying)影响。
对于任意半正定矩阵(PSD),DPP kernel L可以被分解成一个格兰姆矩阵(Gramian matrix):\(L=B^T B\),其中B的每一列(column)表示真实集(ground set)中N个items之一。接着,将每一列\(B_i\)写成是一个质量项(quality terms: \(q_i \in R^+\),标量) 和一个归一化多样性特征(normalized diversity features: \(\phi_i \in R^D, \| \phi_i \| = 1\))(当D=N时足够对任意DPP进行分解,单独保留D是因为实际上我们希望使用高维的特征向量)的乘积。依次会将L分解成质量项和归一化多样性特征:
\[L_{ij} = B_i^T B_j = q_i \phi_i^T \phi_j q_j\]我们可以认为\(q_i \in R^+\)是一个item i内在“好坏(goodness)”的度量,\(\phi_i^T \phi_j)\in [-1,1]\)是item i和item j间相似度的一个带符号的measure。我们使用以下的公式来表示相似度:
\[S_{ij} = \phi_i^T \phi_j) = \frac{L_{ij}}{\sqrt{L_ii L_jj}}\]对于向量\(\phi_i (S_{ij} = \phi_i^T \phi_j)\)的Gramian矩阵S,被称为多样性模型(diversity model);q被称为质量模型(quality model)。
L的这种分解有两个主要优点。第一,隐式强制了约束:L必须是正定的,可以潜在简化学习。第二,它允许我们独立建模quality和diversity,接着将它们组合成一个统一的模型。实际上:
\[P_L(Y) \propto (\prod\limits_{i \in Y} q_i^2) det(S_Y)\]其中,第一项会随着选中items的quality的增加而增加,第二项会随着选中diversity的增加而增加。我们将q称为quality model,将S或\(\phi\)称为diversity model。如果没有diversity model,我们会选中高质量的items,但我们会趋向于选中相似的高质量items。如果没有qulity model,我们会获得一个非常diverse的集合,但可能不会包含在Y集合中最重要的items,反而会关注低质量的异类。通过两个models的组合我们可以达到一个更平衡的结果。
从几何空间上看,\(L_y\)的行列式等于:通过对于\(i \in Y\)的vectors \(\q_i \phi_i\)展开的平行六面体的square volume。表示item i的vector的幅值为\(q_i\),方向是\(\phi_i\)。上图清楚地表示了以这种方式分解的DPPs是如何天然做到high quality和high diversity两个目标间的balance。更进一步,我们几乎总是假设:我们的模型可被分解成:quality和diversity组件。

DPP几何:(a) 一个subset Y的概率是由\(q_i \phi_i\)展开的volume的square (b) 随着item i的quality \(q_i\)增加,包含item i的集合的概率也增加 (c) 随着item i和j变得越相似,\(\phi_i^T \phi_j\)会增加,同时包含i和j的集合的概率会减小
它提供了将一个关于子集Y的概率分解成:它的元素(elements)的质量(quality)和它们的多样性(diversity)的乘积。Y的概率等于 按vectors \(q_i \phi_i\)逐个平方:一个子集的概率会随着它的items的质量(quality)增加而增加,会随着两个items变得更相似而减小。



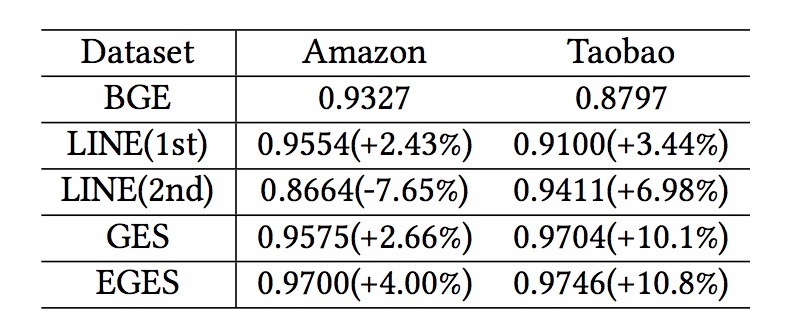 表2
表2