Minmin Chen、Alex Beutel等在《Top-K Off-Policy Correction
for a REINFORCE Recommender System》中提出使用强化学习来提升youtube推荐。主要是从bias/variance的角度出发,具体方法如下:
摘要
工业界推荐系统会处理非常大的动作空间(action spaces)——数百万items来进行推荐。同时,他们需要服务数十亿的用户,这些用户在任意时间点都是唯一的,使得用户状态空间(user state space)很复杂。幸运的是,存在海量的隐式反馈日志(比如:用户点击,停留时间等)可用于学习。从日志反馈中学习是有偏的(biases),这是因为只有在推荐系统上观察到的反馈是由之前版本的推荐系统(previous versions)选中的。在本文中,我们提出了一种通用的方法,在youtube生产环境上的top-k推荐系统中,使用一个基于策略梯度的算法(policy-gradient-based algorithm,比如:REINFORCE),来解决这样的偏差。该paper的主要贡献有:
- 1.将REINFORCE扩展到生产环境推荐系统上,动作空间有数百万;
- 2.使用off-policy correction来解决在从多种行为策略中收集的日志反馈的数据偏差(data biases)
- 3.提出了一种新的top-K off-policy correction来解释我们一次推荐多个items的策略推荐
- 4.展示了探索(exploration)的价值
我们通过一系列仿真(simulations)和youtube的多个真实环境,来展示我们的方法的效果。
1.介绍
在工业界,通过推荐系统来帮助用户从海量内容中挑选和发现用户感兴趣的少部分内容。该问题十分具有挑战性,因为要推荐海量的items数目。另一方面,将合适的item在合适的时间上曝光给正确的用户,需要推荐系统能基于历史交互,不断地适应用户的兴趣漂移。不幸的是,对于一个大的状态空间(state space)和动作空间(action space),我们只观察到相对少量的数据,大多数用户只被曝光了少量items,而显式反馈的数据占比更少。也就是说,推荐系统在训练时只能接受相当稀疏的数据,例如:Netflix Prize Dataset只有0.1%的数据是dense的。因此,推荐系统的大量研究会探索不同的机制来处理相当稀疏的情况。从隐式用户反馈(比如:点击、停留时间)中学习,对未观察到的交互进行填充,对于提升推荐是很重要的一步。
大多数独立的研究线上,增强学习(RL)已经在游戏、机器人领域取得了相当大的进步。RL通常聚焦于构建agents,在一个环境(environment)中采取哪些动作(action)来最大化一些长期收益(long term reward)。这里,我们探索了将推荐解析成:构建RL agents来最大化每个用户使用该系统的长期满意度。在推荐问题上,这提供给我们一个新的视角和机会来基于在RL最新进展之上进行构建。然而,将这些新东西应用于实际还是有许多挑战。
如上所述,推荐系统需要处理大的状态空间(state spaces)和动作空间(action spaces),在工业界尤其显著。推荐可提供的items集合是不确定的(non-stationary),新items会不断被引入到系统中,从而产生一个日益增长的带新items的动作空间(action space),这会产生更稀疏的反馈。另外,在这些items上的用户偏好是会随时间一直漂移的(shifting),从而产生连续演化的用户状态(user states)。在这样一个复杂的环境(environment)中,通过这些大量actions进行reason,在应用已有RL算法时提出了独特的挑战。这里,我们分享了我们的实践:在非常大的动作空间和状态空间中,在一个神经网络候选生成器(neural candidate generator)上(一个top-k推荐系统)应用REINFORCE算法[48]。
除了大量动作和状态空间外,推荐系统中的RL仍是有区别的:只有有限提供的数据。经典的RL应用通过self-play和仿真(simulation)生成的大量训练数据,已经克服了数据无效性(data inefficiencies)。相比较而言,推荐系统的复杂动态性,使得对于仿真生成真实推荐数据是不可能的。因此,我们不能轻易寻找(probe for)关于之前的state和action space的未探索领域上的回报(reward),因为观测到的回报(observing reward)需要为一个真实用户给出一个真实推荐。作为替代,该模型几乎依赖于之前推荐模型们(models即policies)所提供的数据,大多数模型我们是不能控制的或不再可以控制。对于从其它policies中大多数日志反馈,我们采用一个off-policy learning方法,在该方法中我们会同时学习之前policies的一个模型,当训练我们的新policy时,在纠正数据偏差时包含它。我们也通过实验演示了在探索数据(exploratory data)上的价值(value)。
最终,在RL方法中大多数研究主要关注于:产生一个可以选择单个item的policy。而真实世界的推荐系统,通常会一次提供用户多个推荐[44]。因此,我们为我们的top-K推荐系统定义了一个新的top-K off-policy correction。我们发现,在模拟和真实环境中,标准off-policy correction会产生一个对于top-1推荐来说最优的policy,而我们的top-K off-policy correction会生成更好的top-K推荐。我们提供了以下的贡献:
- 1.REINFORCE推荐系统:我们在一个非常大的action space中,扩展了一个REINFORCE policy-gradient-based方法来学习一个神经网络推荐policy。
- 2.Off-Policy候选生成:我们使用off-policy correction来从日志反馈中学习,这些日志从之前的model policies的一个ensemble中收集而来。我们会结合一个已经学到的关于行为策略(behavior policies)的神经网络模型来纠正数据偏差。
- 3.Top-K Off-policy Correction:我们提供了一个新的top-K off-policy correction来说明:我们的推荐一次输出多个items。
- 4.真实环境的提升:我们展示了在真实环境中(在RL文献中很少有这种情况),这些方法对于提升用户长期满意度的价值。
我们发现,这些方法的组合对于增加用户满意度是很有用的,并相信对于在推荐中进一步使用RL仍有许多实际挑战。
2.相关工作
增强学习:Value-based方法(比如:Q-learning),policy-based方法(比如:policy gradients constitue经典方法)来解决RL问题。[29]中罗列了现代RL方法的常见比较,主要关注于异步学习(asynchronous learning),它的关键点是扩展到更大问题上。尽管value-based方法有许多优点(比如:seamless off-policy learning),他们被证明是在函数逼近(function approximation)上是不稳定的[41]。通常,对于这些方法来说,需要进行大量的超参数调参(hyperparameter tuning)才能达到稳定行为。尽管许多value-based方法(比如:Q-learning)取得了实际成功,这些算法的策略收敛(policy convergence)没有被充分研究。另外,对于函数逼近来说,Policy-based方法只要给定一个足够小的learning rate,仍然相当稳定。因此,我们选择一个policy-gradient-based方法(尤其是REINFORCE[48]),将这种on-policy方法适配到在当训练off-policy时提供可靠的policy gradient估计。
神经网络推荐系统:与我们的方法紧密相关的另一条线是,在推荐系统中应用深度神经网络[11,16,37],特别是使用RNN结合时序信息和历史事件用于推荐[6,17,20,45,49]。我们使用相似的网络结构,通过与推荐系统的交互来建模用户状态(user states)的演进。由于神经网络架构设计不是本文重点,有兴趣可以自己了解。
推荐系统中的Bandit问题:在线学习方法很流行,由于新的用户反馈是可提供的,可以快速被适配到推荐系统中。Bandit算法比如(UCB)[3],会以一种解析可跟踪的方式(它在regret上提供了很强的保证)来权衡exploration和exploitation。不同的算法,比如:Thomson sampling【9】,已经被成功应用于新闻推荐和展示广告。Contextual bandits提供了一种关于基础在线学习方法的context-aware refinement,并会将推荐系统朝着用户兴趣的方向裁减[27]。Agarwal【2】使得contextual bandits可跟踪,并且很容易实现。MF和bandits的混合方法被开发出来用于解决cold-start问题[28]。
推荐系统中的倾向得分(Propensity Scoring)和增强学习(Reinforcement learning):学习off-policy的问题在RL中是很普遍的,通常会影响policy gradient。由于一个policy会演进,因此在对应梯度期望下的分布需要重新计算。在机器人领域的标准方法[1,36],会通过限制policy更新的方式来绕过,以便在某一更新policy下新数据被收集之前,不能从实质上变更policy,作为回报,它会提供关于RL目标函数的单调提升保证。这样的近似(proximal)算法很不幸不能应用于item目录和用户行为快速变化的推荐情景中,因此大量的policy会发生变更。同时,对于大的状态空间和动作空间规模来说,收集日志反馈很慢。事实上,在推荐系统环境中,对于一个给定policy的离线评估已经是个挑战。多个off-policy estimators会利用逆倾向得分(inverse-propensity scores)、上限逆倾向得分(capped inverse-propensity scores)、以及许多变量控制的measures已经被开发出[13,42,43,47]。Off-policy评估会将一个相似的数据框架纠正为off-policy RL,相似的方法会被应用于两个问题上。逆倾向指数已经被大规模的用于提升一个serving policy【39】。Joachims[21]为一个无偏排序模型学习了一个日志反馈的模型;我们采用一个相似的方式,但使用一个DNN来建模日志行为策略(logged behavior policy),它对于off-policy learning来说是必需的。更常见的是,off-policy方法已经被适配到更复杂的问题上(比如:[44]为石板推荐)。
3.增强推荐


为便于理解,这里插入了张图(from 李宏毅课程)。
我们开始描述我们的推荐系统,及我们的RL-based算法。
对于每个用户,我们考虑一个关于用户历史交互行为的序列,它会记录下由推荐系统的动作(actions,比如:视频推荐)、用户反馈(比如:点击和观看时长)。给定这样一个序列,我们会预测下一个发生的动作(action:比如:视频推荐),以便提升用户满意度指标(比如:点击、观看时长)。
我们将该过程翻译成一个马尔可夫决策过程(Markov Decision Process: MDP)\((S, A, P, R, \rho_0, \gamma)\),其中:
- S:用于描述用户状态(user states)的一个连续状态空间(state space)
- A:一个离散的动作空间(action space),它包含了推荐可提供的items
- \(P: S \times A \times S \rightarrow R\):是一个状态转移概率
- \(R: S \times A \rightarrow R\):回报函数(reward function),其中\(r(s,a)\)是立即回报(immediate reward),它通过在用户状态(user state)s上执行动作a得到
- \(\rho_0\):初始state分布
- \(\gamma\):对于future rewards的discount factor
我们的目标是:寻找一个policy \(\pi(a \mid s)\)(它会将一个在item上的分布转化成:基于用户状态\(s \in S\)的条件来推荐\(a \in A\)),以便最大化由推荐系统获得的期望累积回报(expected cumulative reward):
\[max_{\pi} E_{\tau \sim \pi} [R(\tau)], where \ R(\tau) = \sum\limits_{t=0}^{|\tau|} r(s_t, a_t)\]
这里,在轨迹(trajectories) \(\tau = (s_0, a_0, s_1, \cdots)\)上采用的期望,它通过根据policy: \(s_0 \sim \rho_0, a_t \sim \pi(\cdot \mid s_t), s_{t+1} \sim P(\cdot \mid s_t, a_t)\)来获得。
提供了不同族的方法来解决这样的RL问题:Q-learning[38], Policy Gradient[26,36,48]以及黑盒优化(black box potimization)[15]。这里我们主要关注policy-gradient-based方法,比如:REINFORCE[48]。
我们假设:policy的一个函数形式为\(\pi_\theta\),参数为\(\theta \in R^d\)。根据各policy参数的期望累积回报(expected cumulative reward)的梯度,可以通过”log-trick”的方式进行解析法求导,生成以下的REINFORCE梯度:
\[E_{\tau \sim \pi_\theta} [R(\tau) \nabla_\theta log \pi_{\theta} (\tau)]\]
…(1)
在online RL中,policy gradient由正在更新的policy生成的轨迹(trajectories)上计算得到,policy gradient的估计是无偏的,可以分解成:
\[\sum_{\tau \sim \pi_{\theta}} R(\tau) \nabla_{\theta} log \pi_{\theta}(\tau) \approx \sum_{\tau \sim \pi_{\theta}} [ \sum_{t=0}^{|\tau|} R_t \nabla_{\theta} log \pi_{\theta} (a_t | s_t)]\]
…(2)
对于一个在时间t上的动作(action),通过使用一个discouted future reward \(R_t = \sum\limits_{t'=t}^{\mid \tau \mid} \gamma^{t'-t} r(s_{t'}, a_{t'})\)将替换\(R(\tau)\)得到的该近似结果,可以减小在梯度估计时的方差(variance)。
4.off-policy collrection
由于学习和基础设施的限制,我们的学习器(learner)没有与推荐系统的实时交互控制,这不同于经典的增强学习。换句话说,我们不能执行对policy的在线更新,以及立即根据updated policy来生成轨迹(trajectories)。作为替代,我们会接收的的关于actions的日志反馈由一个历史policy(或者一个policies组合)选中,它们在action space上会具有一个与正在更新的policy不同的分布。
我们主要关注解决:当在该环境中应用policy gradient方法时所带来的数据偏差。特别的,在生产环境中在部署一个新版本的policy前,我们会收集包含多个小时的一个周期性数据,并计算许多policy参数更新,这意味着我们用来估计policy gradient的轨迹集合是由一个不同的policy生成的。再者,我们会从其它推荐(它们采用弹性的不同policies)收集到的成批的反馈数据中学习。一个navie policy gradient estimator不再是无偏的,因为在等式(2)中的gradient需要从updated policy \(\pi_\theta\)中抽取轨迹(trajectories),而我们收集的轨迹会从一个历史policies \(\beta\)的一个组合中抽取。
我们会使用importance weighting[31,33,34]的方法来解决该分布不匹配问题(distribution)。考虑到一个轨迹 \(\tau=(s_0,a_0,s_1,...)\),它根据一个行为策略\(\beta\)抽样得到,那么off-policy-corrected gradient estimator为:
\[\sum_{\tau \sim \beta} \frac{\pi_{\theta}(\tau)}{\beta(\tau)} [\sum_{t=0}^{|\tau|} R_t \nabla_{\theta} log(\pi_{\theta} (a_t | s_t))]\]
其中:
\[\frac{\pi_{\theta}(\tau)}{\beta(\tau)} = \frac{\rho(s_0) \prod_{t=0}^{|\tau|} P(s_{t+1}|s_t, a_t) \pi(a_t|s_t)}{\rho(s_0) \prod_{t=0}^{|\tau|} P(s_{t+1}|s_t, a_t) \beta(a_t | s_t)} = \prod_{t=0}^{|\tau|} \frac{\pi(a_t | s_t)}{\beta(a_t | s_t)}\]
是importance weight。该correction会生成一个无偏估计器(unbiased estimator),其中:轨迹(trajectories)会使用根据\(\beta\)抽样到的actions进行收集得到。然而,由于链式乘积(chained products),该estimator的方差是很大的,这会快速导致非常低或非常高的importance weights值。
为了减少在时间t时该轨迹上的每个gradient项的方差,我们会首先忽略在该链式乘法中时间t后的项,并在将来时间采用一个一阶近似来对importance weights进行近似:
\[\prod_{t'=0}^{|\tau|} \frac{\pi(a_{t'} | s_{t'})}{\beta(a_{t'} | s_{t'})} \approx \prod_{t'=0}^{t} \frac{\pi(a_{t'} | s_{t'})}{\beta(a_{t'}|s_{t'})} = \frac{P_{\pi_{\theta}}(s_t)}{P_{\beta}(s_t)} \frac{\pi(a_t | s_t)}{\beta(a_t|s_t)} \approx \frac{\pi(a_t|s_t)}{\beta(a_t | s_t)}\]
这会产生一个具有更低方差的关于policy gradient的有偏估计器(biased estimator):
\[\sum_{\tau \sim \beta} [\sum_{t=0}^{|\tau|} \frac{\pi_{\theta} (a_t |s_t)}{\beta(a_t | s_t)} R_t \nabla_{\theta} log \pi_{\theta} (a_t | s_t)]\]
…(3)
Achiam[1]证明了:该一阶近似对于学到的policy上的总回报的影响,会通过\(O(E_{s \sim d^{\beta}} [D_{TV}(\pi \mid \beta)[s]])\)来限定幅值,其中\(D_{TV}\)是在\(\pi(\cdot \mid s)\)和\(\beta(\cdot \mid s)\)间的总方差,\(d^{\beta}\)是在\(\beta\)下的discounted future state分布。该estimator会权衡精确的off-policy correction的方差,并仍能为一个non-corrected policy gradient收集大的偏差,这更适合on-policy learning。
4.1 对policy \(\pi_{\theta}\)进行参数化
这里有:
- user state (\(s_t \in R^n\)): 我们对每个时间t上的user state建模,这可以同时捕获用户兴趣的演进,它使用n维向量\(s_t \in R^n\)来表示。
- action (\(u_{a_t} \in R^m\)): 沿着该轨迹(trajectory)每个时间t上的action会使用一个m维向量\(u_{a_t} \in R^m\)进行嵌入。
我们会使用一个RNN [6, 49]来建模状态转移\(P: S \times A \times S\):
\[s_{t+1} = f(s_t, u_{a_t})\]
我们使用了许多流行的RNN cells(比如:LSTM, GRU)进行实验,最终使用一个简单的cell,称为:Chaos Free RNN (CFN)[24],因为它的稳定性和计算高效性。该state会被递归更新:
\[s_{t+1} = z_t \odot tanh(s_t) + i_t \odot tanh(W_a u_{a_t}) \\
z_t = \sigma(U_z s_t + W_z u_{a_t} + b_z) \\
i_t = \sigma(U_i s_t + W_i u_{a_t} + b_i)\]
…(4)
其中:
- \(z_t \in R^n\)是update gate
- \(i_t \in R^n\)是input gate
考虑到一个user state s, policy \(\pi_{\theta}( a \mid s)\)接着使用一个简单的softmax进行建模:
\[\pi_{\theta}(a | s) = \frac{exp(s^{\top} v_a / T)}{\sum\limits_{a' \in A} exp(s^{\top} v_{a'} / T)}\]
…(5)
其中:
- \(v_a \in R^n\)是每个action a在action space A中的另一个embedding(注:前面的\(u_{a_t} \in R^m\)是m维,而\(v_a\)是与\(s_t\)相同维度)
- T是时序(通常设置为1)。T值越大会在action space上产生一个更平滑的policy。
在softmax中的归一化项需要检查所有可能的动作,在我们的环境中有数百万量级。为了加速计算,我们会在训练中使用sampled softmax。在serving时,我们使用一个高效的最近邻查寻算法来检索top actions,并使用这些actions来近似softmax概率,如第5节所述。
总之,policy \(\pi_{\theta}\)的参数\(\theta\)包含了:
- 两个action embeddings:\(U \in R^{m \times \mid A \mid}\)和\(V \in R^{n \times \mid A \mid}\),
- 在RNN cell中的权重矩阵:\(U_z, U_i \in R^{n \times n}, W_u, W_i, W_a \in R^{n \times m}\)
- biases:\(b_u, b_i \in R^n\)
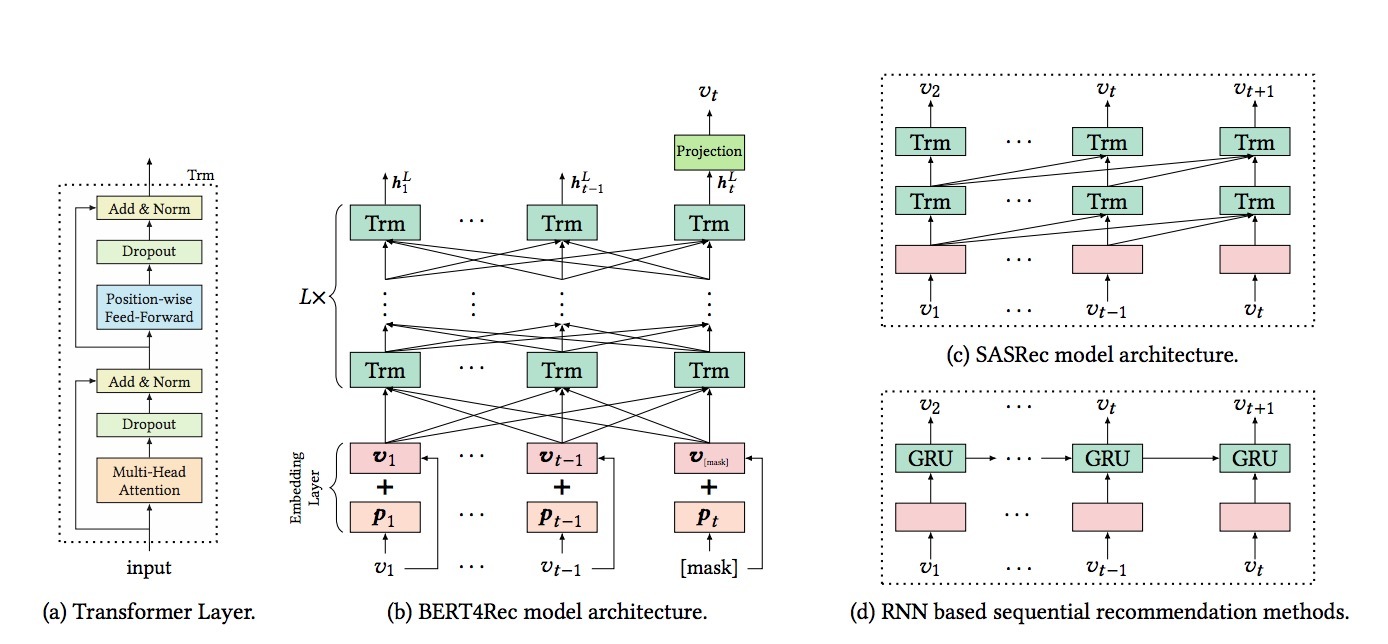
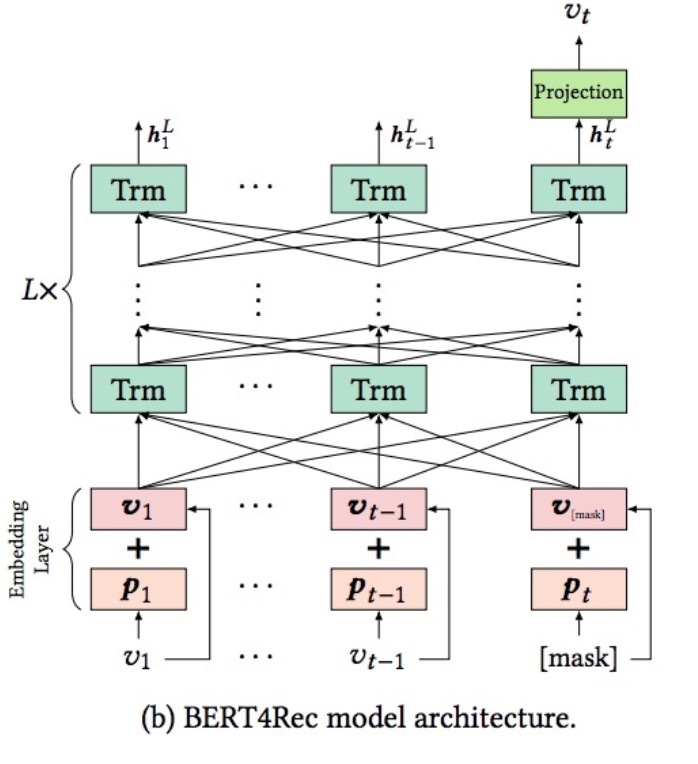
图1展示了一个描述main policy \(\pi_{\theta}\)的神经网络架构。给定一个观察到的轨迹 \(\tau = (s_0, a_0, s_1, ...)\),它从一个行为策略(behavior policy)\(\beta\)中抽样得到,该新策略(new policy)首先会生成一个关于user state \(s_{t+1}\)的模型,它使用一个initial state \(s_0 \sim \rho_0\)并通过等式(4)的recurrent cell迭代得到。给定user state \(s_{t+1}\),policy head会通过等式(5)的softmax来转化在action space分布。有了\(\pi_{\theta}(a_{t+1} \mid s_{t+1})\),我们接着使用等式(3)生成一个policy gradient来更新该policy。

图1 该图展示了policy \(\pi_{\theta}\)的参数变量(parametrisation)以及behavior policy \(\beta_{\theta'}\)
4.2 估计behavior policy \(\beta\)
伴随等式(3)的off-policy corrected estimator出现的一个难题是:得到behavior policy \(\beta\)。理想状态下,对于一个选中action的日志反馈(logged feedback),我们希望也能记录(log)下选中该action的behavior policy概率。直接记录该behavior policy在我们的情况下是不可行的,因为:
- (1) 在我们的系统中有许多agents,许多是不可控的
- (2) 一些agents具有一个deterministic policy,将\(\beta\)设置成0或1并不是使用这些日志反馈(logged feedback)的最有效方式
作为替代,我们采用[39]中首先引入的方法,并估计行为策略\(\beta\),在我们的情况中\(\beta\)是在系统中一个多种agents的policies的混合(它们使用logged actions)。给定一个logged feedback集合 \(D = \lbrace (s_i, a_i), i=1, \cdots, N \rbrace\),Strehlet[39]会以不依赖user state的方式,通过对整个语料的action频率进行聚合来估计\(\hat{\beta}(a)\)。作为对比,我们会采用一个依赖上下文(context-dependent)的neural estimator。对于收集到的每个state-action pair(s, a),我们会估计概率\(\hat{\beta}_{\theta'}(a \mid s)\),它指的是该behavior policies的混合体来选中该action的概率,使用另一个softmax来计算,参数为\(\theta'\)。如图1所示,我们会复用该user state s(它由main policy的RNN model生成),接着使用另一个softmax layer来建模该mixed behavior policy。为了阻止该behavior head干扰到该main policy的该user state,我们会阻止该gradient反向传播回该RNN。我们也进行了将\(\pi_{\theta}\)和\(\beta_{\theta'}\)的estimators分离开的实验,由于会计算另一个state representation,这会增加计算开销,但在离线和在线实验中不会产生任何指标提升。
尽管在两个policy head \(\pi_{\theta}\)和\(\beta_{\theta'}\)间存在大量参数共享,但两者间还是有两个明显的不同之处:
- (1) main policy \(\pi_{\theta}\)会使用一个weighted softmax来考虑长期回报(long term reward)进行有效训练;而behavior policy head \(\beta_{\theta'}\)只会使用state-action pairs进行训练(言下之意,不考虑reward?)
- (2) main policy head \(\pi_\theta\)只使用在该trajectory上具有非零回报(non-zero reward)的items进行训练(注3);而behavior policy \(\beta_{\theta'}\)使用在该轨迹上的所有items进行训练,从而避免引入在\(\beta\)估计时的bias
注3:1.具有零回报(zero-reward)的Actions不会对\(\pi_{\theta}\)中的梯度更新有贡献;2.我们会在user state update中忽略它们,因为用户不可能会注意到它们,因此,我们假设user state不会被这些actions所影响 3.它会节约计算开销
在[39]中是有争议的:一个behavior policy(在给定state s,在time \(t_1\)上的它会确定式选中(deterministically choosing)一个action a;在time \(t_2\)上选中action b),可以看成是:在日志的时间间隔上,在action a和action b间的随机化(randomizing)。这里,我们在同一点上是有争议的,这也解释了:给定一个deterministic policy,为什么behavior policy可以是0或1。另外,由于我们有多个policies同时进行acting,在给定user state s的情况下,如果一个policy会确定式选中(determinstically choosing)action a,另一个policy会确定式选中action b,那么,以这样的方式估计\(\hat{\beta}_{\theta'}\)可以近似成:在给定user state s下通过这些混合的behavior policies,action a被选中的期望频率(expected frequency)。
4.3 Top-K off-policy Correction
在我们的setting中存在的另一个挑战是:我们的系统一次会推荐一个包含k个items的页面给用户。由于用户会浏览我们的推荐(整个集合或部分集合),并与一个以上的item存在潜在交互,我们需要选择一个相关items集合(而非单个item)。换句话说,我们会寻找一个policy \(\prod\limits_{\theta} (A \mid s)\),这样每个action A会选择一个关于k个items的集合,来最大化期望累积回报(expected cumulative reward):
\[max_{\theta} E_{\tau \sim \prod_{\theta}} [ \sum\limits_t r(s_t, A_t)]\]
轨迹(trajectory) \(\tau = (s_0, A_0, s_1, \cdots)\)会通过根据 \(s_0 \sim \rho_0, A_t \sim \prod(\mid s_t), s_{t+1} \sim P(\cdot \mid s_t, A_t)\) 进行acting来获得。不幸的是,动作空间(action space)在该集合推荐公式下是指数级增长,在给定items数时这会过大(从阶数为百万级的语料中选择items)。
为了让该问题可跟踪,我们假设:一个无重复(non-repetitive) items的集合的期望回报(expected reward)等于在集合中每个item的expected reward的和(该假设仍会认为:用户会独立地检查每个item)。更进一步,我们通过对每个item a根据softmax policy \(\pi_\theta\)进行独立抽样,接着进行去重来限制生成action A集合。也就是:
\[\prod_{\theta}(A' | s) = \prod\limits_{a \in A'} \pi_{\theta} (a | s)\]
注意:集合\(A'\)会包含重复的items,可以移除重复项来形成一个无重复的集合A。
在这些假设下,我们可以对该集合推荐setting采用REINFORCE算法,将在等式(2)的梯度更新修改为:
\[\sum_{\tau \sim \pi_\theta} [ \sum_{t=0}^{|\tau|} R_t \nabla_{\theta} log \alpha_{\theta} (a_t | s_t)]\]
其中:
- \(\alpha_{\theta} (a \mid s) = 1 - (1- \pi_{\theta}(a \mid s))^K\):表示的是一个item a出现在最终的无重复集合A中的概率。这里,\(K = \mid A'\mid >\mid A\mid = k\)。(注:作为有放回(replacement)和去重(de-duplicate)抽样的结果,最终集合A的size是可变的)
我们接着更新等式(3)中的off-policy corrected gradient,通过使用\(\alpha_{\theta}\)替代\(\pi_{\theta}\),生成top-K off-policy correction factor:
\[\sum_{\tau \sim \beta} [ \sum_{t=0}^{|\tau|} \frac{\alpha_{\theta} (a_t |s_t)}{\beta(a_t|s_t)} R_t \nabla_{\theta} log \alpha_{\theta} (a_t | s_t)] \\
= \sum_{\tau \sim \beta} [\sum_{t=0}^{|\tau|} \frac{\pi_{\theta}(a_t|s_t)}{\beta(a_t|s_t)} \frac{\partial \alpha(a_t|s_t)}{\partial \pi(a_t|s_t)} R_t \nabla_{\theta} log \pi_{\theta} (a_t | s_t)]\]
…(6)
对比等式(6)和等式(3),top-K policy会增加一个额外的乘子\(\lambda_K(s_t, a_t)\)到original off-policy correction factor的\(\frac{\pi(a \mid s)}{\beta(a \mid s)}\)中:
\[\lambda_K(s_t, a_t) = \frac{\partial \alpha(a_t | s_t)}{\partial \pi(a_t | s_t)} = K(1-\pi_{\theta} (a_t | s_t))^{K-1}\]
…(7)
现在,我们回顾下该额外乘子:
- 随着\(\pi_{\theta}(a\mid s) \rightarrow 0, \lambda_K(s,a) \rightarrow K\)。对比起标准的off-policy correction,top-K off-policy correction会通过一个K因子来增加policy update;
- 随着\(\pi_{\theta}(a \mid s) \rightarrow 1, \lambda_K(s,a) \rightarrow 0\)。该乘子会使policy update归0
- 随着K的增加,以及\(\pi_{\theta}(a \mid s)\)会达到一个合理的范围, 该乘子会更快地将graident减小于0
总之,当期望的item在softmax policy \(\pi_{\theta}(\cdot \mid s)\)具有一个很小的量,比起标准的correction,top-K correction会更可能推高它的likelihood。一旦softmax policy \(\pi_{\theta}(\cdot \mid s)\)在期望的item上转化成一个合理的量(以确认它可能出现在top-K中),correction接着会将梯度归0, 不再尝试推高它的似然。作为回报,它允许其它感兴趣的items在softmax policy中占据一定的量。我们会在仿真和真实环境中进一步演示,而标准的off-policy correction会收敛到一个当选择单个item时最优的policy,top-K correction会产生更好的top-K推荐。
4.4 Variance Reduction技术
在本节开始,我们会采用一个一阶近似来减小在梯度估计时的方差(Variance)。尽管如此,梯度仍会有较大的方差,因为等式(3)中展示的\(\omega(s,a) = \frac{\pi(a \mid s)}{\beta(a \mid s)}\)具有很大的importance weight,这与top-K off-policy correction相类似。具有较大值的importance weight是因为由(1)中来自behavior policy的new policy \(\pi(\cdot \mid s)\)的导数具有较大值所产生,特别的,new policy会探索那些被behavior policy很少探索过的区域。也就是说,\(\pi(a \mid s) \gg \beta(a \mid s)\)和(2)在\(\beta\)估计中有大的方差。
我们测试了在counterfactual learning和RL文献中提出的许多技术来控制在梯度估计时的方差。大多数这些技术会减小方差,但在梯度估计时会引入一些bias。
Weight Capping。
我们测试的第一种方法会简单的将weight设置上限:
\[\omega_c(s,a) = min(\frac{\pi(a|s)}{\beta(a|s)}, c)\]
…(8)
c的值越小,会减小在梯度估计时的方差,但会引入更大的bias。
NIS(归一化重要性抽样:Normalized Importance Sampling)
我们使用的第二种技术是引入一个ratio来控制变量,其中我们使用经典的权重归一化,如下:
\[\bar{\omega}(s, a) = \frac{w(s,a)}{\sum\limits_{(s',a') \sim \beta} w(s', a')}\]
由于\(E_{\beta}[w(s,a)] = 1\),归一化常数等于n,batch size在预期之中。随着n的增大,NIS的效果等价于调低learning rate。
TRPO(Trusted Region Policy Optimization). TRPO会阻止new policy \(\pi\)背离behavior policy,它通过增加一个正则项来惩罚这两个policies的KL散度。它会达到与weight capping相似的效果。
5.探索(EXPLORATION)
有一点很明确:训练数据的分布对于学习一个好的policy来说很重要。现有的推荐系统很少采用会询问actions的探索策略(exploration policies),这已经被广泛研究过。实际上,暴力探索(brute-force exploration),比如:\(\epsilon-greedy\),对于像Youtube这样的生产系统来说并不是可行的,这很可能产生不合适的推荐和一个较差的用户体验。例如,Schnabel【35】研究了探索(exploration)的代价。
作为替代,我们使用Boltzmann exploration[12]来获取探索数据(exploratory data)的收益,不会给用户体验带来负面影响。我们会考虑使用一个随机policy,其中推荐会从\(\pi_{\theta}\)中抽样,而非采用最高概率的K个items。由于计算低效性(我们需要计算full softmax),这对于考虑我们的action space来说开销过于高昂。另外,我们会利用高效的ANN-based系统来查询在softmax中的top M个items。我们接着会feed这些M个items的logits到一个更小的softmax中来归一化该概率,接着从该分布中抽样。通过设置\(M \gg K\),我们仍可以检索大多数概率块,限制了生成坏的推荐的风险,并允许计算高效的抽样。实际上,我们会通过返回top \(K'\)个最大概率的items,以及从剩余的\(M-K'\)个items中抽取\(K-K'\)个items,来进一步平衡exploration和exploitation。
6.实验结果
我们展示了:在一个工业界规模的推荐系统中,在一系列仿真实验和真实实验中,这些用于解决数据偏差(data biases)的方法的效果。
6.1 仿真
我们设计了仿真实验来阐明:在更多受控环境下off-policy correction的思想。为了简化我们的仿真,我们假设:该问题是无状态的(stateless),换句话说,reward R与user states是相互独立的,action不会改变user states。作为结果,在一个trajectory上的每个action可以被独立选中。
6.1.1 off-policy correction
在第一个仿真中,我们假设存在10个items:\(A=\lbrace a_i, i=1, \cdots, 10 \rbrace\)。每个action的reward等于它的index,也就是说:\(r(a_i)=i\)(可以理解成按reward大小排好序)。当我们选中单个item时,在该setting下最优的policy总是会选中第10个item(因为它的reward最大),也就是说:
\[\pi^* (a_i) = I(i=10)\]
我们使用一个无状态的softmax来对\(\pi_{\theta}\)参数化:
\[\pi(a_i) = \frac{e^{\theta_i}}{\sum_j e^{\theta_j}}\]
如果observations是从behavior policy \(\beta\)中抽样得到的,那么等式(1)中不对数据偏差负责的naively使用policy gradient的方式,会收敛到以下的一个policy:
\[\pi(a_i) = \frac{r(a_i)\beta(a_i)}{\sum_j r(a_j) \beta(a_j)}\]
这具有一个明显的缺点(downside):behavior policy越选择一个次优(sub-optimal)的item,new policy越会朝着选择相同的item偏移。

图2: 当behavior policy \(\beta\)倾向于喜欢最小reward的actions时,(比如:\(\beta(a_i)=\frac{11-i}{55}, \forall i = 1, \cdots, 10\)),所学到的policy \(\pi_{\theta}\),(左):没有使用off-policy correction; (右): 使用off-policy correction
这里我附上了我的理解代码(本节的目的,主要是为说明:当存在behavior policy倾向喜欢选择较小reward actions时,不使用off-policy correction效果会差):
1
2
3
4
5
6
7
8
|
actions = [1,2,3,4,5,6,7,8,9,10]
b = lambda x: (11-x)/55.0
beta = [b(i) for i in actions]
rxb = [(i+1)*j for i, j in enumerate(beta)]
total = sum(rxb)
pi = [i/total for i in rxb]
|
图2比较了:当behavior policy \(\beta\)倾向于最少回报的items,分别使用/不使用 off-policy correction及SGD所学到的policies \(\pi_{\theta}\)。如图2(左)所示,没有对数据偏差负责naivly使用behavior policy的方式,会导致一个sub-optimal policy。在最坏的case下,如果behavior policy总是选择具有最低回报的action,我们将以一个任意差(poor)的policy结束,并模仿该behavior policy(例如:收敛到选择最少回报的item)。另外一方面,使用off-policy correction则允许我们收敛到最优policy \(\pi^*\),无需关注数据是如何收集的,如图2(右)。
6.1.2 Top-K-policy correction
为了理解标准off-policy correction和top-K off-policy correction间的不同,我们设计了另一个仿真实验,它可以推荐多个items。我们假设有10个items,其中\(r(a_1)=10, r(a_2)=9\),具有更低reward的其余items为:\(r(a_i)=1, \forall i=3,\cdots,10\)。这里,我们关注推荐两个items的问题,即K=2。 behavior policy \(\beta\)会符合一个均匀分布(uniform distribution),例如:以平等的机率选择每个item。
给定从\(\beta\)中抽样到的一个observation \((a_i, r_i)\),标准的off-policy correction具有一个SGD,以如下形式进行更新:
\[\theta_j = \theta_j + \eta \frac{\pi_{\theta}(a_j)}{\beta(a_j)} r(a_i) [ I(j=i) - \pi_{\theta}(a_j)]
, \forall j = 1, \cdots, 10\]
其中,\(\eta\)是learning rate。SGD会根据在\(\pi_\theta\)下的expected reward的比例继续增加item \(a_i\)的似然(likelihood),直到\(\pi_{\theta}(a_i)=1\),此时的梯度为0。换句话说,top-K off-policy correction以如下形式进行更新:
\[\theta_j = \theta_j + \eta \lambda_K(a_i) \frac{\pi_\theta(a_j)}{\beta(a_j)} r(a_i) [I(j=i) - \pi_{\theta}(a_j)], \forall j=1, \cdots, 10\]
其中,\(\lambda_K(a_i)\)是在第4.3节定义的乘子。当\(\pi_{\theta}(a_i)\)很小时,\(\lambda_K(a_i) \approx K\),SGD会更强烈地增加item \(a_i\)的似然。由于\(\pi_\theta(a_i)\)会达到一个足够大的值,\(\lambda_K(a_i)\)会趋向于0. 作为结果,SGD不再强制增加该item的likelihood,即使当\(\pi_\theta(a_i)\)仍小于1时。作为回报(in return),这会允许第二好(second-best)的item在所学到的policy上占据一些位置。

图3 学到的policy \(\pi_{\theta}\). (左): 标准的off-policy correction; (右): 对于top-2推荐,使用top-k correction.
图3展示了使用标准(left) off-policy correction和top-k off policy correction)(右)学到的policies \(\pi_{\theta}\)。我们可以看到,使用标准的off-policy correction,尽管学到的policy会校准(calibrated),从某种意义上说,它仍会维持items关于expected reward的顺序,它会收敛到一个policy:它能在top-1 item上将整个mass转换(cast),也就是:\(\pi(a_1) \approx 1.0\)。作为结果,学到的policy会与在次优item(本例中的\(a_2\))和其余items间的差异失去联系。换句话说,该top-K correction会收敛到一个在第二优item上具有较大mass的policy,而维持在items间optimality的次序。作为结果,我们可以推荐给用户两个高回报(high-reward) items,并在整体上聚合更多reward。
6.2 真实环境
具有仿真实验对于理解新方法有价值,任何推荐系统的目标最终都是提升真实用户体验。我们因此在真实系统中运行A/B test实验。
我们在Youtube中所使用的生产环境上的 RNN candidate genreation model上评估这了些方法,相似的描述见[6,11]。该模型是生产环境推荐系统的众多候选生成器(candidate generators)之一,它们会进行打分(scored)然后通过一个独立的ranking模型进行排序(ranked),之后再在Youtube主页或视频观看页的侧边栏上展示给用户视频。如上所述,该模型的训练会采用REINFORCE算法。该立即回报(immediate reward) r被设计来体现不同的用户活动(user activities);被推荐的视频如果没有点击会收到零回报(zero reward)。长期回报(long-term reward)r会在4-10小时的时间范围内进行聚合。在每个实验中,控制模型(control model)和测试模型(test model)会使用相同的reward function。实验会运行许多天,在这期间模型会每隔24小时使用新事件作为训练数据进行持续训练。我们可以查看推荐系统的多种在线指标,我们主要关注用户观看视频时长,被称为:ViewTime。
这里的实验描述了在生产系统中的多个顺序提升。不幸的是,在这样的setting中,最新(latest)的推荐系统会为下一次实验提供训练数据,结果是,一旦生产系统包含了一个新方法,后续的实验就不能与之前的系统相进行比较。因此,后续的每个实验都应该看成是为每个(compoenent)单独分析,我需要在每一部分声明:在从新方法接收数据起,之前的推荐系统是什么。
6.2.1 Exploration
我们开始理解探索数据(exploratory data)在提升模型质量上的价值。特别的,我们会measure是否服务(serving)一个随机策略(stochastic policy),在该policy下我们使用在第5节中描述的softmax模型进行抽样,可以比serving一个确定策略(deterministic policy)(这种模型总是推荐根据softmax使用最高概率的K个items)来产生成好的推荐。
我们开展了一系列实验来理解:serving一个随机策略(stochastic policy) vs. serving一个确定策略(deterministic policy)的影响,并保持训练过程不变。在该实验中,控制流量(control polulation)使用一个deterministic policy进行serving,测试流量(test traffic)的一小部分使用第5节描述的stochastic policy进行serving。两种policies都基于等式(2)相同softmax model进行训练。为了控制在serving时stochastic policy的随机量,我们使用等式(5)的不同时间(temperature) T来区分。T值越低,会将stochastic policy降为一个deterministic policy,而一个更高的T会产生一个random policy,它以相等的机会推荐任意item。T设置为1, 我们可以观察到,在实验期间ViewTime在统计上没有较大变化,这意味着从sampling引入的随机量不会直接伤害用户体验。
然而,该实验的setup不会说明,在训练期间提供探索数据的好处。从日志数据中学习的一个主要偏差之一是,该模型不会观察未被之前推荐policy所选中actions的反馈(feedback),对数据进行探索会缓和该问题。我们展开了以下实验,其中,我们将探索数据引入到训练中。为了这样做,我们将平台上的用户分成三个buckets:90%,5%,5%。前两个buckets使用一个deterministic policy并基于一个deterministic model进行serving,最后一个bucket的用户使用一个基于一个使用exploratory data训练的模型得到的stochastic policy进行serving。deterministic model只使用由前两个分桶的数据进行训练,而stochastic model则使用第一和第三个buckets的数据进行训练。这两个模型会接收相同量的训练数据,结果表明,由于存在exploration,stochastic model更可能观察到一些更罕见state、action pairs的结果。
根据该实验过程,我们观察到在test流量中,在ViewTime上一个很大的增长。尽管提升并不大,它由一个相当小量的探索数据(只有5%的用户体验了该stochastic policy)所带来。我们期待stochastic policy被全量后所能带来的更高增益。
6.2.2 Off-policy Correction
在使用一个stochastic policy之后,我们会在训练期间对合并进的(incorporating)off-policy correction进行测试。这里,我们遵循一个更传统的A/B testing setup【注6】,我们会训练两个模型,它们均会使用所有流量。控制模型(control model)会根据等式(2)进行训练,通过reward对样本进行加权。测试模型(test model)会遵循图1的结构,其中该模型会同时学习一个serving policy \(\pi_\theta\)以及behavior policy \(\beta_{\theta}'\)。serving policy会使用等式(3)描述的off-policy correction进行训练,其中每个样本会同时使用reward以及importance weight \(\frac{\pi_\theta}{\beta_{\theta}'}\)进行加权来解决数据偏差。
【注6】:实际中,我们使用一个相当小比例的用户做为test polulation;作为结果,我们记录的feedback则几乎通过control model获取
在实验期间,我们观察到,学到的policy(test)会开始偏离behavior policy(control)(它被用于获取流量)。图4画出了:根据在控制流量中视频的排序(rank),对应在control/experiment流量中nominator所选中的视频(videos)的CDF(累积分布函数)(rank 1是由控制模型最可能指定的视频,最右表示最小可能指定)。我们看到,test model并不会模仿收集数据所用的模型(如蓝色所示),test model(绿色所示)会更喜欢那些被control model更少曝光的视频。我们观察到:来自top ranks之外视频的nominations的比例,在experiment流量中以几倍的因子递增。这与我们在图2仿真中观察到的现象一致。当忽略在数据收集过程中的偏差时,会创建一个“rich get richer”现象,其中,在学到的policy所指定(nominated)的一个视频,会只因为它在behavior policy上很难指定,采用off-policy correction可以减小该效应。

图4: 根据在control population中视频的排序(rank),在control 和test population中nominated的视频的CDF。标准的off-policy correction会解决”rich get richer”现象
有意思的是,在真实环境中,我们不会观察到control和test 流量(polulation)间在ViewTime上有一个大的改变。然而,我们看到,在视频观看(vv)数上有0.53%的提升,这在统计上是很大的,表明用户确实获得了更大的enjoyment。
6.2.3 top-k off-policy
…
理解超参数
最后,我们直接比较了超参数的不同选择对top-k off-policy correction的影响,以及在用户体验上的不同。我们会在top-k off-policy correction成为生产模型之后执行这些测试。
actions数目。
我们首先探索了在top-K off-policy correction中K的选择。我们训练了三个结构相同的模型,分别使用:\(K \in \lbrace 1,2,16,32 \rbrace\)。控制(生产)模型(control(production) model)是top-K off-policy model,它使用K=16. 我们在图5中绘制了在5天实验中的结果。如第4.3节所示,K=1时,top-K off-policy correction会变成标准的off-policy correction。当K=1时,会失去0.66%的ViewTime(对比baseline K=16)。这进一步证明,该收益是由top-K off-policy correction带来的。设置K=2时,效果比生产模型还差,但gap降到了0.35%。K=32时效果与baseline相当。K=8时,有+0.15%的提升。
Capping
这里,我们在所学推荐器的最终质量上考虑了variance reduction技术。如4.4节所述,weight capping可以在初始实验中带来最大的online收益。我们不会观察到从归一化importance sampling或TRPO中进一步的metric提升。我们使用一个回归测试来学习weight capping的影响。我们比较了一个模型,它使用等式(8)中cap \(c=e^3\),以及\(c=e^5\)进行训练。正如我们在importance weight上提出的限制,学到的policy \(\pi_\theta\)可以潜在overfit到一个更少记录的actions,它们可能接收高的reward。在真实实验中,我们观察到使用importance weight在ViewTime中有0.52的损失。
参考