
介绍
youtube在2019公布了它的MMoE多目标排序系统《Recommending What Video to Watch Next: A Multitask Ranking System》。
摘要
在本paper中,我们介绍了一个大规模多目标排序系统,用于在工业界视频分享平台上推荐下一个要观看的视频。该系统会面临许多挑战,包括:存在多个竞争性的排序目标(ranking objectives),以及在user feedback中的隐式选择偏差(implicit selection biases)。为了解决这些挑战,我们探索了多种软参数共享技术(soft-parameter sharing techniques),比如:Multi-gate Mixture-of-Experts,以便对多个排序目标进行有效最优化(optimize)。另外,我们会采用一个Wide&Deep框架来减缓选择偏差(selection biases)。我们演示了我们提出的技术可以在youtube推荐质量上产生有效提升。
介绍
在本paper中,我们描述了一个关于视频推荐的大规模排序系统。也就是说:在给定用户当前观看的一个视频的情况下,推荐该用户可能会观看和享受的下一个视频。通常推荐系统会遵循一个two-stage设计:candidate generation、ranking。该paper主要关注ranking。在该stage,推荐器会具有数百个候选,接着会应用一个复杂的模型来对它们进行排序,并将最可能观看的items推荐给用户。
设计一个真实世界的大规模视频推荐系统充满挑战:
- 通常有许多不同的、有时甚至有冲突的待优化目标。例如,我们想推荐用户点击率高、愿与朋友共享的、包括观看高的视频
- 在该系统中通常有隐式偏差(implicit bias)。例如,一个用户通常点击和观看一个视频,仅仅只因为它的排序高,而不是因为用户最喜欢它。因此,从当前系统的数据生成来进行模型训练会是有偏的,这会造成(feedback loop effect)效应[33]。如何有效和高效地学习减少这样的biases是个开放问题。
为了解决这样的挑战,我们为ranking system提出了一个有效的多任务神经网络架构,如图1所示。它会扩展Wide&Deep模型,通过采用Multi-gate Mixture-of-Experts(MMoE) [30]来进行多任务学习。另外,它会引入一个浅层塔结构(shallow tower)来建模和移除选择偏差。我们会应用该结构到视频推荐中:给定当前用户观看的视频,推荐下一个要观看的视频。我们在实验和真实环境中均有较大提升。
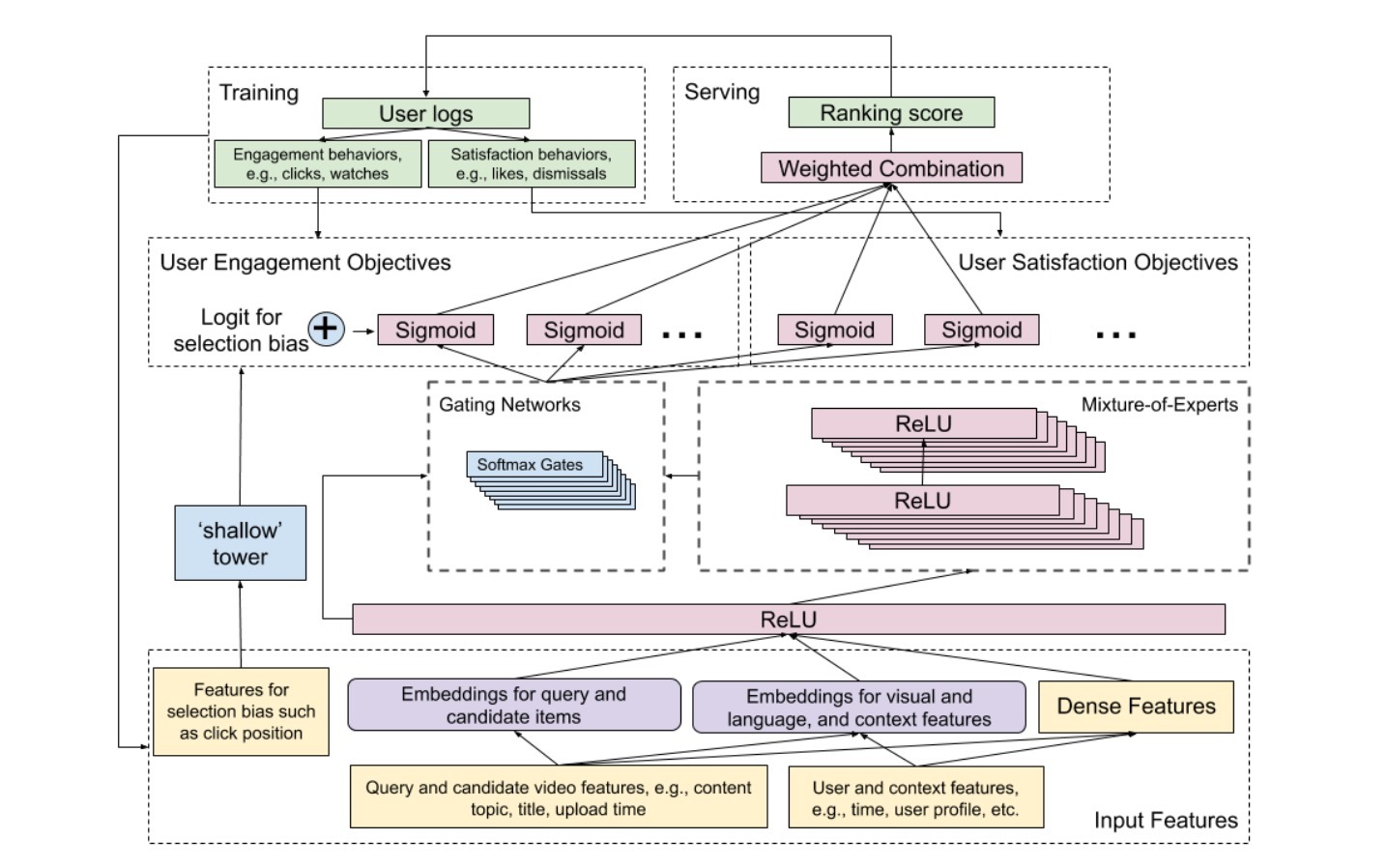
图1 我们提出的ranking系统的模型架构。它会消费user logs作为训练数据,构建Multi-gate Mixture-of-Experts layers来预测两类user behaviors,比如:engagement和satisfaction。它会使用一个side-tower来纠正ranking selection bias。在顶部,会组合多个预测到一个最终的ranking score
特别的,我们首先将我们的多任务目标分组成两类:
- 1) 参与度目标(engagement objectives),比如:用户点击(user clicks),推荐视频的参与度
- 2) 满意度目标(satisfaction objectives),比如:用户喜欢一个视频的程度,在推荐上留下一个评分
为了学习和估计多种类型的用户行为,我们使用MMoE来自动化学习那些跨潜在冲突的多目标共享的参数。Mixture-of-Experts[21]架构会将input layer模块化成experts,每个expert会关注input的不同部分。这可以提升从复杂特征空间(由多个模块生成)中学到的表示。
接着,通过使用多个gating network,每个objective可以选择experts来相互共享或不共享。
为了建模和减小来自有偏训练数据的选择偏差(selection bias,比如:position bias),我们提出了添加一个shallow tower到主模型中,如图1左侧所示。shallow tower会将input与selection bias(比如:由当前系统决定的ranking order)相关联,接着输出一个scalar作为一个bias项来服务给主模型的最终预测。该模型架构会将训练数据中的label分解成两部分:
- 1.从主模型中学到的无偏用户效用(unbiased user utility)
- 2.从shallow tower学到的估计倾向评分(estimated propensity score)
我们提出的模型结构可以被看成是Wide&Deep模型的一个扩展,shallow tower表示Wide部分。通过直接学习shallow tower和main model,我们可以具有优点:学习selection bias,无需对随机实验resort来获取propensity score。
为了评估我们提出的ranking系统,我们设计了offline和live实验来验证以下的效果:
- 1) 多任务学习
- 2) 移除一个常见的selection bias (position bias)
对比state-of-art的baseline方法,我们展示了我们提出的框架的改进。我们在Youtube上进行实验。
主要贡献有:
- 介绍了一种end-to-end的排序系统来进行视频推荐
- 将ranking问题公式化成一个多目标学习问题,并扩展了Multi-gate Mixture-of-Experts架构来提升在所有objectives上的效果
- 我们提出使用一个Wide&Deep模型架构来建模和缓和position bias
- 我们会在一个真实世界的大规模视频推荐系统上评估我们的方法,以及相应的提升
2.相关工作
3.问题描述
本节,我们首先描述了推荐下一次要观看的视频的问题,我们引入了一个two-stage setup。
除了上述提到的使用隐式反馈来构建ranking systems挑战外,对于真实的大规模视频推荐问题,我们需要考虑以下因素:
- 多模态特征空间(Multimodal feature space)。在一个context-aware个性化推荐系统中,我们需要使用从多模态(例如:视频内容、预览图、音频、标题、描述、用户demographics)来学习候选视频的user utility。从多模态特征空间中为推荐学习表示,对比其它机器学习应用来说是独一无二的挑战。它分为两个难点:
- 1) 桥接来自low-level的内容特征中的语义gap,以进行内容过滤(content filtering)
- 2) 为协同过滤学习items的稀疏表示
- 可扩展性(Scalability)。可扩展性相当重要,因为我们正构建一个数十亿用户和视频的推荐系统。模型必须在训练期间有效训练,在serving期间高效运行。尽管ranking system在每个query会对数百个candidates进行打分,真实世界场景的scoring需要实时完成,因为一些query和context信息不仅仅需要学习数十亿items和users的表示,而且需要在serving时高效运行。
回顾下我们的推荐系统的目标是:在给定当前观看的视频和上下文(context)时,提供一个关于视频的ranked list。为了处理多模态特征空间,对于每个视频,我们会抽取以下特征(比如:视频的meta-data和视频内容信号)来作为它的表示。对于context,我们会使用以下特征(比如:人口统计学user demographics、设备device、时间time、地点location)。
为了处理可扩展性,如[10]描述相似,我们的推荐系统具有两个stages:候选生成、ranking。。。
3.1 候选生成
我们的视频推荐系统会使用多种候选生成算法,每种算法会捕获query video和candidate video间的某一种相似性。例如,一个算法会通过将query video的topics相匹配来生成candidates;另一个算法则会基于该视频和query video一起被观察的频次来检索candiate videos。我们构建了与[10]相似的一个序列模型通过用户历史来生成个性化候选视频。我们也会使用[25]中提到的技术来生成context-aware high recall relevant candiadtes。最后,所有的candidates都会放到一个set中,给ranking system进行打分。
3.2 Ranking
我们的ranking系统会从数百个candidates中生成一个ranked list。不同于candidate generation,它会尝试过滤掉大多数items并只保留相关items,ranking system的目标是提供一个ranked list以便具有最高utility的items可以展示在top前面。因此,我们使用大多数高级机器学习技术常用的NN结构,以便能足够的建模表现力来学习特征关联和utility关系。
4.模型结构
4.1 系统总览
我们的ranking system会从两类用户反馈数据中学习:
- 1) engagement行为(比如:点击和观看)
- 2) satisfaction行为(比如:喜欢(likes)和dismissals)
给定每个candidate,ranking system会使用该candidate、query和context的的特征作为输入,学习预测多个user behaviors。
对于问题公式,我们采用l2r的框架。我们会将ranking问题建模成:一个具有多个objectives的分类问题和回归问题的组合。给定一个query、candidate和context,ranking模型会预测用户采用actions(比如:点击、观看、likes和dismissals)的概率。
为每个candidate做出预测的方法是point-wise的方法。作为对比,pair-wise或list-wise方法可以在两个或多个candidates的顺序上做出预测。pair-wise或list-wise方法可以被用于潜在提升推荐的多样性(diversity)。然而,我们基于serving的考虑主要使用point-wise ranking。在serving时,point-wise ranking很简单,可以高效地扩展到大量candidates上。作为比较,对于给定的candidates集合,pair-wise或list-wise方法需要对pairs或lists打分多次,以便找到最优的ranked list,限制了它们的可扩展性。
4.2 ranking objectives
我们使用user behaviors作为训练labels。由于用户可以对推荐items具有不同类型的behaviors,我们将我们的ranking system设计成支持多个objectives。每个objective的目标是预测一种类型的与user utility相关的user behavior。为了描述,以下我们将objectives分离成两个类别:engagement objectives和satisfaction objectives。
Engagement objectives会捕获user behaviors(比如:clicks和watches)。我们将这些行为的预测公式化为两种类型的任务:对于像点击这样行为的二元分类任务,以及对于像时长(time spent)相关的行为的回归任务。相似的,对于satisfaction objectives,我们将:与用户满意度相关的行为预测表示成二元分类任务或者回归任务。例如,像点击/like这样的行为可以公式化成一个二元分类任务,而像rating这样的行为被公式化成regression任务。对于二元分类任务,我们会计算cross entropy loss。而对于regression任务,我们会计算squared loss。
一旦多个ranking objectives和它们的问题类型被定下来,我们可以为这些预测任务训练一个multitask ranking模型。对于每个candidate,我们将它们作为多个预测的输入,并使用一个形如加权乘法的组合函数(combination function)来输出一个组合分(combined score)。该权值通过人工调参,以便在user engagements和user satisfactions上达到最佳效果。
4.3 使用MMoE建模任务关系和冲突
多目标的ranking systems常使用一个共享的bottom模型架构。然而,当任务间的关联很低时,这样的hard-parameter sharing技术有时会伤害到多目标学习。为了缓和多目标间的冲突,我们采用并扩展了一个最近发布的模型架构:MMoE(Multi-gate Mixture-of-Experts)【30】。
MMoE是一个soft-parameter sharing模型结构,它的设计是为了建模任务的冲突(conflicts)与关系(relation)。通过在跨多个任务上共享experts,它采用Mixture-of-Experts(MoE)结构到多任务学习中,而对于每个task也具有一个gating network进行训练。MMoE layer的设计是为了捕获任务的不同之处,对比起shared-bottom模型它无需大量模型参数。关键思路是,使用MoE layer来替代共享的ReLU layer,并为每个task添加一个独立的gating network。
对于我们的ranking system,我们提出在一个共享的hidden layer的top上添加experts,如图2b所示。这是因为MoE layer可以帮助学习来自input的模态信息(modularized information)。当在input layer的top上、或lower hidden layers上直接使用它时,它可以更好地建模多模态特征空间。然而,直接在input layer上应用MoE layer将极大增加模型training和serving的开销。这是因为,通常input layer的维度要比hidden layers的要更高。
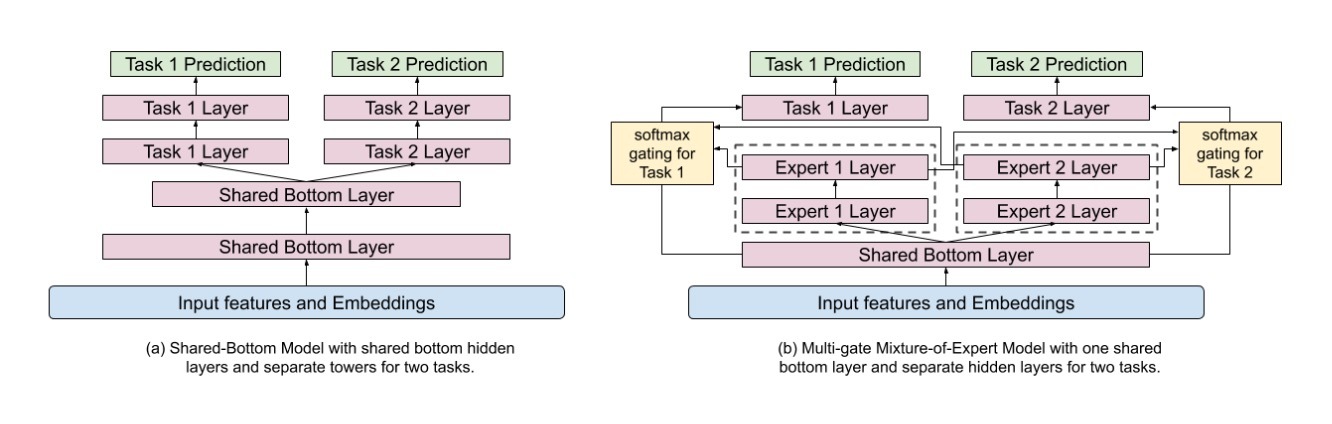
图2 使用MMoE来替换shared-bottom layers
我们关于expert networks的实现,等同于使用ReLU activations的multilayer perceptrons。给定task k、 prediction \(y_k\)、以及最后的hidden layer \(h^k\),对于task k的具有n个experts output的MMoE layer为:\(f^k(x)\),可以用以下的等式表示:
\[y_k = h^k (f^k(x)), \\ where \ \ f^k(x) = \sum\limits_{i=1}^n g_{(i)}^k(x) f_i(x)\]…(1)
其中:
- \(x \in R^d\)是一个lower-level shared hidden embedding
- \(g^k\)是task k的gating network
- \(g_{(i)}^k(x) \in R^n\)是第i个entry
- \(f_i(x)\)是第i个expert
gating networks是使用一个softmax layer的关于input的简单线性转换。
\[g^k(x) = softmax(W_{g^k} x)\]…(2)
其中:
\(W_{g^k} \in R^{n \times d}\)是线性变换的自由参数
与[32]中提到的sparse gating network对比,experts的数目会大些,每个训练样本只利用top experts,我们会使用一个相当小数目的experts。这样的设置是为了鼓励在多个gating networks间共享experts,并高效进行训练。
4.4 建模和移除Position和Selection Baises
隐式反馈被广泛用于训练l2r模型。大量隐式反馈从user logs中抽取,从而训练复杂的DNN模型。然而,隐式反馈是有偏的,因为它由已经存在的ranking system所生成。Position Bias以及其它类型的selection biases,在许多不同的ranking问题中被研究和验证[2,23,41]。
在我们的ranking系统中,query是当前被观看过的视频,candidates是相关视频,用户倾向于点击和观看更接近toplist展示的视频,不管它们实际的user utility——根据观看过的视频的相关度以及用户偏好。我们的目标是移除从ranking模型中移除这样的position bias。在我们的训练数据中、或者在模型训练期间,建模和减小selection biases可以产生模型质量增益,打破由selection biases产生的feedback loop。
我们提出的模型结构与Wide&Deep模型结构相似。我们将模型预测分解为两个components:
- 来自main tower的一个user-utility component
- 以及来自shallow tower的一个bias component
特别的,我们使用对selection bias有贡献的features来训练了一个shallow tower,比如:position bias的position feature,接着将它添加到main model的最终logit中,如图3所示。
- 在训练中,所有曝光(impressions)的positions都会被使用,有10%的feature drop-out rate来阻止模型过度依赖于position feature。
- 在serving时,position feature被认为是缺失的(missing)。
为什么我们将position feature和device feature相交叉(cross)的原因是:不同的position biases可以在不同类型的devices上观察到。
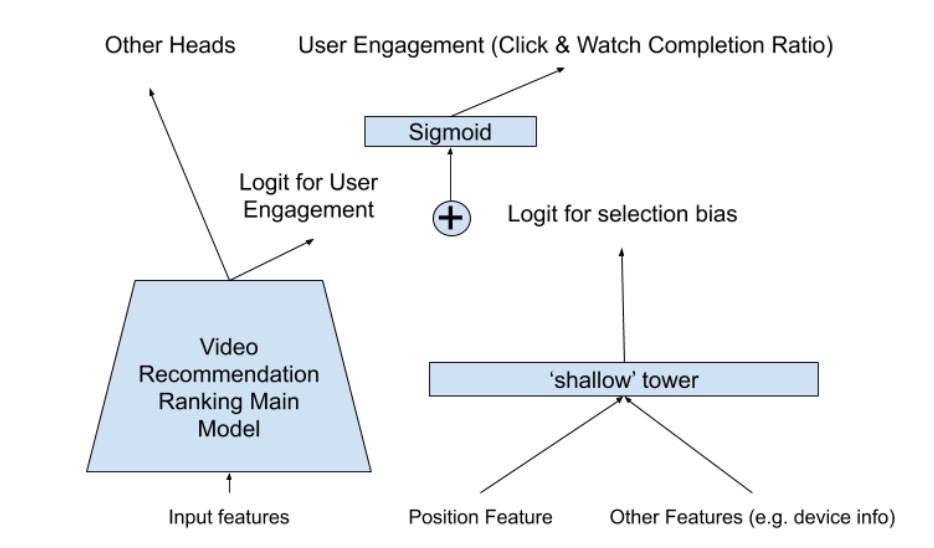
图3 添加一个shallow side tower来学习selection bias(比如:position bias)
5.实验结果
本节我们描述了我们的ranking system实验,它会在youtube上推荐next watch的视频。使用由YouTube提供的隐式反馈,我们可以训练我们的ranking models,并进行offline和live实验。
Youtube的规模和复杂度是一个完美的测试。它有19亿月活用户。每天会有数千亿的user logs关于推荐结果与用户活动的交互。Youtube的一个核心产品是,提供推荐功能:为给定一个观看过的视频推荐接下来要看的,如图4所示。
图4 在youtube上推荐watch next
…
5.2.3 Gating Network分布
为了进一步理解MMoE是如何帮助multi-objective optimization的,我们为在每个expert上的每个task在softmax gating network中绘制了累积概率。
5.3 建模和减小Position Bias
使用用户隐式反馈作为训练数据的一个主要挑战是,很难建模在隐式反馈和true user utility间的gap。使用多种类型的隐式信号和多种ranking objectives,在serving时在item推荐中我们具有更多把手(knobs)来tune以捕获从模型预测到user utility的转换。然而,我们仍需要建模和减小在隐式反馈中普遍存在的biases。例如:在用户和当前推荐系统交互中引起的selection biases。
这里,我们使用提出的轻量级模型架构,来评估如何来建模和减小一种类型的selection biases(例如:position bias)。我们的解决方案避免了在随机实验或复杂计算上花费太多开销。
5.3.1 用户隐反馈分析
为了验证在我们训练数据中存在的position bias,我们对不同位置做了CTR分析。图6表明,在相对位置1-9的CTR分布。所图所示,我们看到,随着位置越来越低,CTR也会降得越来越低。在更高位置上的CTR越高,这是因为推荐更相关items和position bias的组合效果。我们提出的方法会采用一个shallow tower,我们展示了该方法可以分离user utility和position bias的学习。
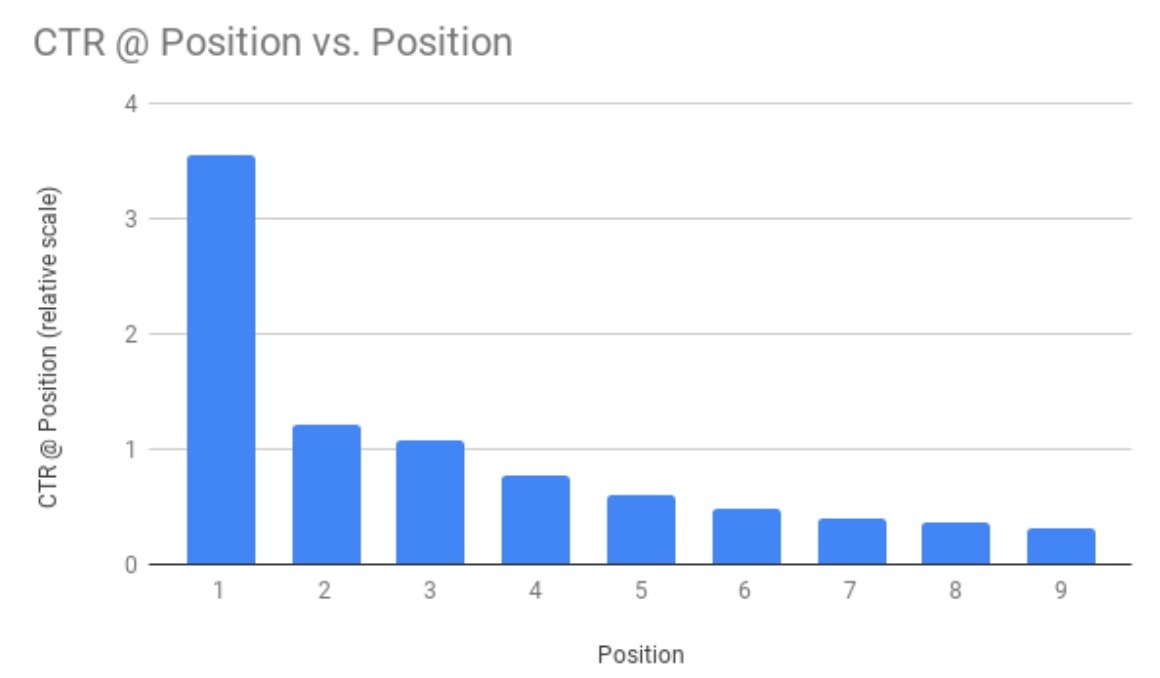
图6 位置1-9的CTR
5.3.2 Baseline方法
为了评估我们提出的模型架构,我们使用以下的baseline方法进行对比。
- 直接使用position feature做为一个input feature:这种简单方法已经在工业界推荐系统中广泛使用来消除position bias,大多数用于线性l2r rank模型中。
- 对抗学习(Adversarial learning):受域适应(domain adaptation)和机器学习公平性(machine learning fairness)中Adversarial learning的广泛使用的启发,我们使用一个相似的技术来引入一个辅助任务(auxiliary task),它可以预测在训练数据中的position。随后,在BP阶段,我们不让梯度传递到主模型(main model)中,以确保主模型的预测不依赖于position feature。
5.3.3 真实流量实验结果
表2展示了真实流量实验结果。我们可以看到提出的方法通过建模和消除position biases可以极大提升参与度指标。
5.3.4 学到的position biases
图7展示了每个position学到的position biases。从图中可知,越低的position,学到的bias越小。学到的biases会使用有偏的隐式反馈(biased implicit feedback)来估计倾向评分(propensity scores)。使用足够训练数据通过模型训练运行,可以使我们有效学到减小position biases。
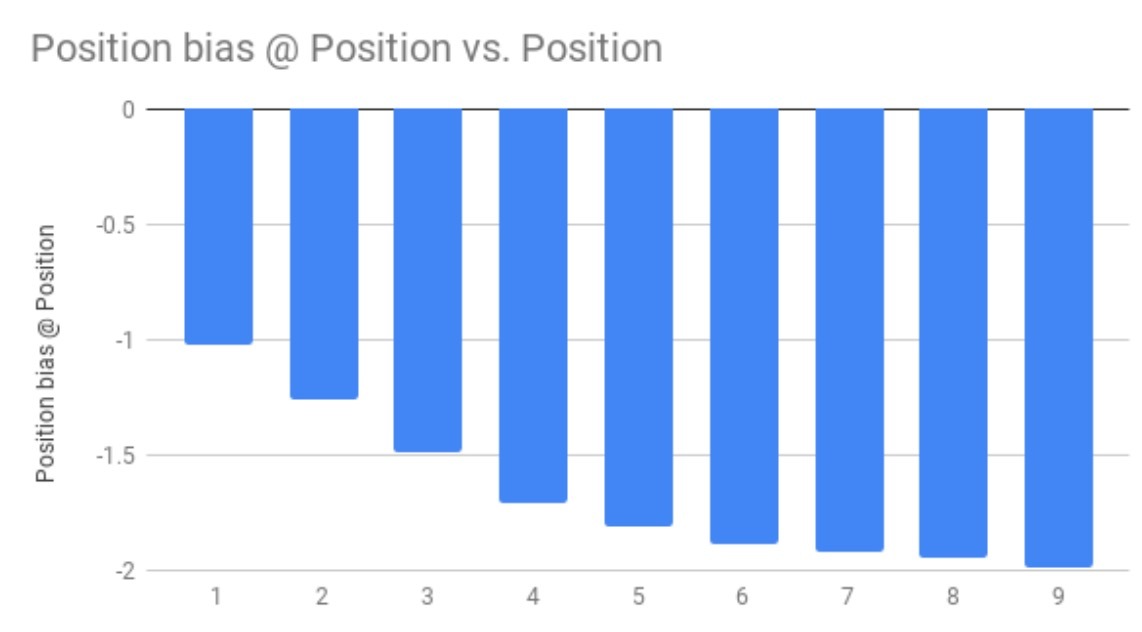
图7 每个position上学到的position bias
5.4 讨论
略




 算法3
算法3













