我们来看下2010提出的《Learning from Logged Implicit Exploration Data》,LinUCB的姐妹篇,具体方法如下:
摘要
对于在”contextual bandit”或”partially labeld” setting中(只有一个选中的action的值会被学到)使用非随机探索数据(nonrandom exploration data),我们提供了一个合理和一致的基础。在许多settings中的主要挑战是:探索策略(exploration policy)并非显式可知,“离线(offline)”数据会记录下。之前提出的解决方案是需要在学习期间对actions进行控制,记录下随机探索、或者以一种可重复的方式遗忘式(obliviously)的选择actions。这里提出的该技术会解除这些限制,学习一个policy,使得:在给定来自历史数据的features(随机化没有出现或者被记录)下选择actions。
介绍
考虑广告展示问题,一个搜索引擎公司会选择一个ad来展示给它的目标用户。当用户点击展示的ad时,会产生来自广告主付费的收益(Revenue)。该问题的经济特性,产生了许多著名的公司。
在讨论提出的方法前,我们将该问题公式化,接着解释为什么许多常见方法会失败。
上下文探索(contextual exploration)的warm-start问题:
假设:
- X是一个任意输入空间
- \(A=\lbrace 1, \cdots, k \rbrace\)是一个actions集合
那么,contextual bandit问题的一个实例,可以通过在tuples \((x, \vec{r})\)上的一个分布D来指定,其中:\(x \in X\)是一个输入,\(\vec{r} \in [0, 1]^k\)是一个关于rewards的向量。事件(Events)会以一个round-by-round的方式发生,其中每个round t有:
- 1.抽取\((x, \vec{r}) \sim D\),并公布x
- 2.算法会选择一个action \(a \in A\),可以是一个关于x和历史信息的函数
- 3.公布action a的reward为\(r_a\),但不会公布\(a'\neq a\)是\(r_{a'}\)
理解以下这点很重要:这不是一个标准的监督学习问题,因为其它actions \(a' \neq a\)的reward并没有透露(注:有点绕,即隐式的)。
在该setting中标准的目标是:在多轮交互上最大化rewards \(r_a\)的求和。为了这样做,使用之前记录的events来在第一轮交互上形成一个好的policy是很重要的。因而,这就是一个”warm start”问题。
正式的,给定一个形如\(S=(x, a, r_a)^*\)的dataset,它通过一个uncontrolled logging policy进行交互(interaction)生成,我们希望构建一个policy h来最大化(近似或逼近)下面的期望:
\[V^h := \underset{(x,r) \sim D}{E} [r_{h(x)}]\]有许多方法尝试解决该问题的会失败:以下是一些尝试解决该问题的方法,但被证明是不适合的:
- 1.监督学习:我们可以学到一个regressor \(s: X \times A \rightarrow [0,1]\),它可以在观察到的events上基于action a和其它信息x,训练来预测reward。从该regressor,一个policy可以根据\(h(x)=argmax_{a \in A} s(x,a)\)来生成。该方法的缺点是,argmax会超出在训练数据中未包含的选择集合,因此不能被泛化。这可以通过一些极端情况进行验证。假设,有两个actions a和b,其中action a出现\(10^6\)次,action b出现\(10^2\)次。由于action b的次数比例只占\(10^{-4}\),一个学习算法会强迫在预测\(r_a\)和\(r_b\)的期望值间做权衡,并压倒性地偏向于估计\(r_a\),代价是精准估计\(r_b\)。然而,在应用上,action b可能会被argmax选中。当action b出现0次时,该问题会更糟糕
- 2.Bandit方法:略
- 3.Contextual Bandits:略
- 4.Exploration Scavenging:略
-
- 倾向指数(Propensity Scores), naively:当进行一个调查时,提问一个关于收入的问题,接着在不同收入级别上的回答者的比例,可以与基于参与该调查所选中的某些人的收入估计一个条件概率进行对比。给定该估计概率,结果可以被importance-weighted来估计在整个人口(population)上的平均调查结果。这里,该方法是有问题的,因为policy会做出决策,当记录数据是deterministic而非probabilistic。换句话说,对logging policy选择一个ad的概率的精准预测,意味着总是预测0或1, 这对于我们的目标是没用处的。尽管propensity scores的直接使用并不work,我们采用的该方法可以被认为是,对于一个propensity score的更好使用,下面会讨论。Lambert[4]提供了一个在互联网ad环境中关于propensity scoring的一个良好解释。
而我们的方法分为三个step:
- 1.对于每个event \((x,a,r_a)\),使用回归(regression)来估计logging policy会选择action a的概率(probability) 为\(\hat{\pi}(a \mid x)\)。这里,“probability”是随时间变化的——我们可以想像:在不同时间点,采用一个均匀随机的方式从policies集合(可能是deterministic)中抽取。
- 2.对于每个event \((x,a,r_a)\),根据\((x,a,r_a, \frac{1}{max \lbrace \hat{\pi}(a \mid x), \tau \rbrace})\),创建一个synthetic controlled contextual bandit event,其中\(\tau > 0\)是一些参数。\(\frac{1} { max \lbrace \hat{\pi}(a \mid x), \tau \rbrace}\)这个量是一个importance weight,它指定了当前event对于训练是有多重要。需要明确的是,参数\(\tau\)对于数值稳定性很重要。
- 3.应用一个offline contextual bandit算法到synthetic contextual bandit events集合上。在我们第二个实验结果的集合(4.2节)中,采用的argmax regressor的变种使用了两个关键修改之处:(a) 我们将argmax的范围限定在具有正概率的那些actions上 (b) 我们对events进行importance weight,以便训练过程会强调对于每个action平等的好估计。需要强调的是,在本paper中的理论分析可以应用于对于在contextual bandit events学习上的任何算法——我们选择该方法是因为它很容易在已存在方法上进行简单修改。
上述方法与前面提到的Propensity Score方法相似。相对它来说,我们使用一个不同的概率定义,当logging policy完全确定时该概率不必是0或1.
当考虑该方法时,会有三个关键问题:
- 1.在当给定特征x时,logging policy会确定式(deterministically)选中一个action (ad) a,\(\hat{\pi}(a \mid x)\)意味着什么,?基本observation:一个policy如果在day 1会确定式选中action a、接着在day 2会确定选中action b,这可以被看成是:(当events数目在每天都相同时,并且events间是IID的),在action a和b间使用概率0.5进行随机化。因而,在logged events的时间跨度上,\(\hat{\pi}(a \mid x)\)是一个给定特征x关于action a被展示的期望频率的估计。第3节中,我们会展示该方法在期望上是合理的,它提供了关于new policy的值的一种无偏估计。
- 2.在\(\hat{\pi}(a \mid x)\)上的客观误差(inevitable errors)是如何影响该过程的?结果表明它们有影响,取决于\(\tau\)。对于非常小的\(\tau\)值,\(\hat{\pi}(a \mid x)\)的估计必须极其精准来生成好的效果;而对于更大的值,会需要更小的accuracy。第3.1节会证明健壮性
- 3.参数\(\tau\)是如何影响最终结果的?当在估计过程中创建一个bias时,结果表明该bias的形式是很轻微的并且相对合理的——基于条件x具有低频展示的actions具有一个under-estimated value。这与期望的对于没有频率的actions的限制是一致的。
2.问题设定和假设
假设:
- \(\pi_1, \cdots, \pi_T\)是T个policies,
对于每个t,\(\pi_t\)是一个函数,它会将X的input映射到在A上的一个可能的deterministic分布。该学习算法会给定一个关于T个样本的dataset,每个样本形如:\((x,a,r_a) \in X \times A \times [0,1]\)(注:0,1为reward),其中:
- \((x,r)\)按第1节所述的方式从D中抽取
- action \(a \sim \pi_t(x)\)根据第t个policy被选中。
我们将该随机过程通过\((x,a,r_a) \sim (D, \pi_t(\cdot \mid x))\)来表示。相似的,与T个policies的交互会产生一个关于T条样本的序列S,我们表示为:\(S \sim (D, \pi_i(\cdot \mid x))_{i=1}^T\)。该learner不会给出关于\(\pi_t\)的先验知识。
offline policy estimator:
给定一个数据集:
\[S = \lbrace (x_t, a_t, r_{t,a_t}) \rbrace_{t=1}^T\]…(1)
其中:\(\forall t, x_t \in X, a_t \in A, r_{t,a_t} \in [0, 1]\)
我们会生成一个predictor \(\hat{\pi}: X \times A \rightarrow [0,1]\),接着使用它与一个阀值\(\tau \in [0,1]\)为一个policy h的value形成一个offline estimator。
正式的,给定一个new policy h: \(X \rightarrow A\)以及dataset S,将estimator 定义为:
\[\hat{V}_{\hat{\pi}}^h(S) = \frac{1}{|S|} \sum\limits_{(x,a,r) \in S} \frac{r_a I (h(x)=a)}{max \lbrace \hat{\pi}(a \mid x), \tau \rbrace}\]…(2)
其中,\(I(\cdot)\)是指示函数(indicator function)。我们会使用符号\(\hat{V}_{\hat{\pi}}^h\),因为没有歧义。\(\tau\)的目标是sum中个别项的上界,与之前的robust importance sampling方法相似。
3.理论成果
我们接着展示了我们的算法和主要理论成果。主要思想有两个:
- 1.我们具有一个policy estimation阶段,其中我们估计未知的logging policy;
- 2.我们具有一个policy optimization阶段,其中我们会使用我们估计的logging policy。
我们的主要结果,提供了一个泛化边界——解决estimation和optimization error对于total error贡献的问题。
logging policy \(\pi_t\)可能是确定的(deterministic),这意味着:基于logging policy中的随机化的常用方法是不可用的。我们会在下面展示:当现实情况是IID条件、并且policy会随actions的不同而变化时,这是ok的。我们会有效使用算法中的随机化标准方法来替代现实中的随机。
一个基本断言(假设)是:在期望上的estimator等价于一个随机policy(stochastic policy),定义如下:
\[\pi(a | x) = \underset{t \sim UNIF(1,\cdots,T)}{E} [\pi_t (a | x)]\]…(3)
其中,\(UNIF(\cdots)\)表示均匀分布。
stochastic policy \(\pi\)会在T policies \(\pi_t\)上随机均匀选择一个action。我们的第一个结果是,当现实中根据\(\pi\)或者policies序列\(\pi_t\)进行选择actions时,我们的estimator的期望值与是相同的。尽管该结果和它的证明是简单的,它是本paper后面部分的基础。注意,policies \(\pi_t\)可以是任意的,但我们会假设,它们不依赖于用于evaluation的数据。该假设只对证明来说是必要的,可以在实际中放宽些,如4.1节。
定理3.1: 对于在T轮上做出相同抽取的任意contextual bandit问题D,对于任意可能的stochastic policies \(\pi_t(a \mid x)\)的序列(\(pi\)由上面求得),以及对于任意的预测 \(\hat{\pi}\),有:
\[E_{S \sim (D,\pi_i(\cdot|x))_{i=1}^T} \hat{V}_{\hat{\pi}}^h(S) = E_{(x,\vec{r}) \sim D, a \sim \pi(\cdot |x)} \frac{r_a I (h(x)=a)}{max \lbrace \hat{\pi}(a|x), \tau \rbrace}\]…(4)
S就是上面指的dataset。
当在更简单、更标准的setting中(使用单一固定的(fixed) stochastic policy)使用T个policies时,该定理与我们的estimator的期望值相关。
3.1 Policy Estimation
在本节中,我们展示了如果\(\tau\)和\(\hat{\pi}\)的值选得合适,我们的estimator在评估new policies h时会足够精准。我们会进而使用前面章节的简化版,它展示了:我们可以将数据看成是由一个确定的stochastic policy \(\pi\)生成,比如:对于所有t来说,\(\pi_t = \pi\)。
对于一个给定的关于\(\pi\)的估计(estimate): \(\hat{\pi}\),我们通过下式来定义一个”regret”函数(\(reg:X \rightarrow [0,1]\)):
\[reg(x)= \underset{a \in A}{max} [(\pi(a \mid x) - \hat{\pi}(a \mid x))^2]\]…(5)
上面我们没有使用\(l_1\)和\(l_\infty\) loss,因为它们比\(l_2\) loss更难最小化。我们接下来的结果是:new estimator是一致的(consistent)。在接下来的理论声明中:
- \(I(\cdot)\)表示了indicator function
- \(\pi(a \mid x)\)是logging policy在输入x上选择action a的概率
- \(\hat{V}_{\hat{\pi}}^h\)是由等式(2)基于参数\(\tau\)的定义
引理3.1:
假设:
- \(\hat{\pi}\)是从X到在actions A分布上的任何函数
- \(h: X \rightarrow A\)是任意的deterministic policy。
- \(V^h(x) = E_{r \sim D(\cdot \mid x)}[r_{h(x)}]\)表示在input x上执行policy h的期望值
我们有:
\[E_x [ I(\pi(h(x) | x) \geq \tau) \cdot (V^h(x) - \frac{\sqrt{reg(x)}}{\tau}) ] \leq E[\hat{V}_{\hat{\pi}}^h] \leq V^h + E_x [ I(\pi(h(x) \mid x) \geq \tau) \cdot \frac{\sqrt{reg(x)}}{\tau} ]\]注:在上式中,期望\(E[\hat{V}_{\hat{\pi}}^h]\)会在关于T个tuples \((x,a,r)\)的所有序列上计算,其中\((x,r) \sim D\)以及\(a \sim \pi(\cdot \mid x)\)
该引理限制了在我们的estimate \(V^h(x)\)上的bias。有两个bias来源:一个来自于在估计\(\pi(a \mid x)\)的\(\hat{\pi}(a \mid x)\)引入的error,另一个来自于阀值\(\tau\)。 对于第一个来源,我们根据squared loss分析了结果,因为限定在squared loss估计上的regret的抽样复杂度是可行的。
引理3.1展示了:一个policy h的估计\(\hat{V}_{\pi}^h\)的期望值(expected value),是关于policy h的真实值(true value)的一个下界的近似,其中该近似(approximation)主要归因于在estimate \(\hat{\pi}\)中的errors,下界(lower bound)主要归因于阀值\(\tau\)。当\(\hat{\pi} = \pi\)时,引理3.1可以简化成:
\[E_x [ I(\pi(h(x) | x) \geq \tau) \cdot V^h(x)] \leq E[\hat{V}_{\hat{\pi}}^h] \leq V^h\]这样,有了一个关于\(\pi\)的完美predictor,estimator \(\hat{V}_{\hat{\pi}}^h\)的期望值(expected value)是一个在policy h的真实值(true value)(即\(V^h\))上有保证的下界。然而,正如该断言的左侧建议,它可以是一个非常松的界,特别是当由h选中的action被\(\pi\)选中概率通常较小时。
引理3.1中\(1/\tau\)的依赖有点烦,但不可避免。考虑到bandit问题的一个实例:它具有一个input x,两个action \(a_1,a_2\)。
假设:对于一些positive \(\epsilon\)有\(\pi(a_1 \mid x) = \tau + \epsilon\),\(h(x)=a_1\)就是我们正评估的policy。
进一步假设:rewards总是为1,并且\(\hat{\pi}(a_1 \mid x) = \tau\)。
那么,该estimator满足:
\[E[\hat{V}_{\hat{\pi}}^h]=\pi(a_1 \mid x) / \hat{\pi}(a_1 \mid x) = (\tau + \epsilon) / \tau\]因而,在estimate中的期望值是:
\[E[\hat{V}_{\hat{\pi}}^h] - V^h = |(\tau+\epsilon)/\tau - 1| = \epsilon /\tau\]其中:\(\hat{\pi}\)的regret为:
\[(\pi(a_1 \mid x) - \hat{\pi}(a_1 \mid x))^2 = \epsilon^2\]3.2 Policy Optimization
之前章节证明,我们可以通过观察一个stochastic policy \(\pi\)来有效评估一个policy h,只要由h选中的actions在\(\pi\)下有足够的支持,特别的:对于所有inputs x来说,有\(\pi(h(x) \mid x) \geq \tau\)。然而,我们通常感兴趣的是:在观察到logged data后,从一个policies集合H中选择最好的policy h。再者,如第2节所述,logged data从T个固定的、可能是deterministic的policies \(\pi_1, \cdots, \pi_T\)来生成,而非单个stochastic policy。如第3节所述,我们通过等式3定义了stochastic policy \(\pi\):
\[\pi(a | x) = E_{t \sim UNIF(1,\cdots,T)}[\pi_t(a | x)]\]3.1节的结果可以应用到policy optimization问题上。然而,注意,该数据被看成是通过从一个关于T个policies \(\pi_i, \cdots, \pi_T\)的执行序列上抽取得到,而非从\(\pi\)上进行T个抽取得到。
接下来,我们展示了使用在H(在\(\pi\)下得到充分支持)中最好的hypothesis可能效果很好。(即使数据不是从\(\pi\)中生成的)
定理3.2
假设:
- \(\hat{\pi}\)是任意从X到actions A分布的函数
- H是任意deterministic policies的集合
定义:
- \[\tilde{H}=\lbrace h \in H \mid \pi(h(x) \mid x) > \tau, \forall x \in X \rbrace\]
- \[\tilde{h} = argmax_{h \in \tilde{H}} \lbrace V^h \rbrace\]
假设:
- \(\hat{h} = argmax_{h \in H} \lbrace \hat{V}_{\hat{\pi}}^h \rbrace\)是最大化在等式(2)中定义的empirical value estimator的hypothesis。
接着,概率至少为\(1-\delta\):
\[V^{\hat{h}} \geq V^{\tilde{h}} - \frac{2}{\tau} (\sqrt{E_x[reg(x)]} + \sqrt{\frac{ln(2|H|/\delta)}{2T}})\]…(6)
其中,reg(x)是定义好的,对应于\(\pi\),在等式(5)中
定理3.2的证明依赖于我们estimator的下界特性(引理3.1的左侧不等式)。换句话说,如果H包含了一个非常好的policy,它在\(\pi\)下得到较小支持,我们不能通过我们的estimator来检测它。换句话说,我们的estimation是安全的,我们从不会激烈地过度估计(overestimate)在H中任意policy的value。“underestimate, but don’t overestimate”的特性,对于应用optimization技术来说很重要,这意味着我们可以使用一个不受限的学习算法来生成一个warm start policy。
4.评估
我们在两个来自Yahoo!的真实数据集中评估了我们的方法。第一个数据集包含了均匀随机的曝光数据,该数据集中可以获取一个关于任意policy的无偏估计。该数据集接着用于验证我们的offline evaluator(2)的accuracy。第二个数据集接着会演示如何从非随机离线数据中去做policy optimization。
4.1 实验I
第一个实验涉及了在Yahoo!首页”Today Module”上的新闻推荐。对于每个用户访问,该模块会从一个小的候选池中(由编辑人工挑选)选出一个高质量的新闻文章进行展示。该池子会在任意时刻包含20篇左右的文章。我们的目标是:对highlighted出的该文章的点击率(ctr)最大化。该问题可以被建模成一个contextual bandit问题,其中,context包含了user和article的信息,arms对应于articles,一篇被显示文章如果被点击则reward是1, 否则为0. 因此,一个policy的值就刚好等于它的整体(overall)CTR。为了保护商业敏感信息,我们只提供了归一化CTR(nCTR: normalized CTR),它被定义成是:真实(true) CTR与一个random policy间的比值(ratio)。
我们的数据集被表示成\(D_0\),它从Yahoo!首页的真实流量中收集,时间为2009年6月的两个星期。它包含了\(T=64.7M\) events,形式为三元组(x,a,r):其中context x包含了user/article的特征,arm a从一个动态候选池A中随机均匀的方式选中,r是一个二元reward信号表示用户是否点击了a。由于actions的选择是随机的,我们有:\(\hat{\pi}(a \mid x) = \pi(a \mid x) \equiv 1/ \mid A \mid\)且\(reg(x) \equiv 0\)。因此,引理3.1意味着当提供\(\tau < 1/ \mid A \mid\)时\(E[\hat{V}_{\hat{\pi}}^h] = V^h\)。更进一步,Hoeffding不等式的简单应用,保证了对于任意的policy h,\(\hat{V}_{\hat{\pi}}^h\)以\(O(1/\sqrt{T})\)的速率向\(V^h\)集中,这在经验上是可被验证的。给定dataset的size大小,我们使用该dataset并在(2)中使用\(\hat{\pi}(a \mid x)=1/\mid A \mid)\)来计算\(\hat{V}_0 = \hat{V}_{\hat{\pi}}^h\)。结果\(\hat{V}_0\)接着被看成是”ground truth”,当使用非随机log data来替代时,可以评估offline evaluator (2)有多准确。
为了获取非随机的log data,我们使用offline bandit仿真过程来运行LinUCB算法,在我们的随机log data \(D_0\)上,对于被记录的events \((x,a,r)\),UCB会在context x下选择arm a。注意,这里的\(\pi\)是一个deterministic学习算法,在不同的timesteps上对于相同的context可以选择不同的arms。我们称该被记录的events子集为 \(D_\pi\)。该recorded events集合与我们在真实的yahoo!首页的用户访问上运行LinUCB具有相同的分布。我们使用\(D_{\pi}\)作为非随机的log data,并进行了evaluation。
为了定义policy h进行evaluation,我们使用\(D_0\)跨所有用户来估计每篇article的整体CTR,接着h被定义成使用最高的估计得到的(estimated)CTR来选择该篇article。
我们接着使用offline evaluator (2)在\(D_\pi\)上对h进行评估。由于关于articles的A集合会随时间变化(新的文章会被增加,老文章被淘汰),\(\pi(a \mid x)\)会非常小,因为在两周时间中的文章量会很大,从而产生大的variance。为了解决该问题,我们将dataset \(D_\pi\)划分成子集,在每个子集中候选池仍是常数,接着使用ridge regression在特征x上为每个子集单独估计\(\pi(a \mid x)\)。我们注意到,这可以使用更多高级的条件概率估计技术。
图1绘出了:以ground truth \(\hat{V}_0\)为参照,\(\hat{V}_{\hat{\pi}}^h\)会随着\(\tau\)变化。正如所愿,随着\(\tau\)变得更大,我们的estimate可以变得更(向下)偏离(biased)。对于一个大范围的\(\tau\)值,我们的estimates是非常准确的,这意味着我们提出的方法是有意义的。作为对比,一个naive方法:假设\(\pi(a \mid x) = 1/\mid A \mid\)会给出一个非常差的估计。
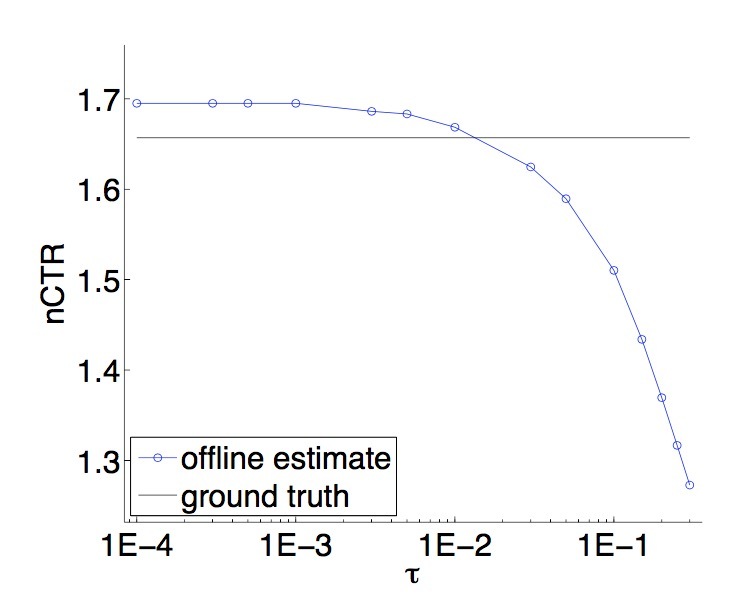
图1:
对于十分小的\(\tau\)值,看起来是一个趋向该policy value的过度估计。这是因为,事实上一个正随机变量的负moments,通常到大于它对应期望的moments。
注意,我们使用的logging policy \(\pi\),会与证明引理3.1所使用的一个假设相矛盾,也就是说,在timestep t上的exploration policy不会与一个更早的event相依赖。我们的offline evaluator在该setting中是准确的,这意味着该假设在实际中是可变宽松的。
4.2 实验II
在第二个实验中,我们会在warm-start问题上研究我们的方法。该数据集由Yahoo!提供,包含了在2008年一个月周期的数据。该数据由events日志(x,a,y)组成,其中,每个event表示了一个user访问了一个特定web页面x(它来自于一个大的web页集合X)。商业系统会从一个大的广告集合A中选择单个广告a放置到最前置、最重要的位置。它也会选择额外的广告来展示,但在我们的测试中会忽略。输出y是一个indicator,表示用户是否点击了该ad。
在该dataset中的ads数近似为880000个。训练数据集包含了3500w的events。test数据集包含了1900w的event,它们在训练集中的events之后发生。去重的web页数目为3400w。
我们基于当前页,训练一个policy h来选择一个广告,使得能最大化点击概率。为了学习,每个ad和page在内部都被表示成一个稀疏高维的feature vector。在page中或ad中出现的词(words)所对应于的features,可以通过词频进行加权。每个ad平均包含了30个ad features,每个page包含了大约50个page features。f的特征形式在它的输入(x,a)的特征上是线性的。(注:所使用的feature vector通常是page vector和ad vector的笛卡尔积)
被优化的指定policy,具有一个argmax形式:\(h(x)=argmax_{a \in C(x)} \lbrace f(x,a) \rbrace\),在关于f(x,a)如何被训练的问题上与之前的方法不同。这里:\(f: X \times A \rightarrow [0,1]\)是一个regression函数,它被训练用来估计点击概率,并且\(C(x)=\lbrace a \in A \mid \hat{\pi}(a \mid x) > 0 \rbrace\)是一个可行ads的集合。
训练样本的形式为:(x,a,y),其中y=1表示ad a在被展示到page x时被点击,否则为0。regressor f被选择用来逼近最小化weighted squared loss:\(\frac{(y-f(x,a))^2}{max \lbrace \hat{\pi}(a_t \mid x_t), \tau \rbrace}\)。使用SGD来最小化squared loss。
在评估期间,我们会计算在test data \((x_t, a_t, y_t)\)上的estimator:
\[\hat{V}_{\hat{\pi}}^h = \frac{1}{T} \sum\limits_{t=1}^T \frac{y_t I(h(x_t)=a_t)}{max \lbrace \hat{\pi}(a_t | x_t) , \tau \rbrace}\]…(7)
如简介所述,该estimator是有偏的,因为使用了参数\(\tau > 0\)。如第3节分析所示,该bias通常会欠估计(underestimate)policy h的true value。
我们解释了使用不同的阀值\(\tau\)以及其它参数。结果如表2所示。
Interval列的计算使用Chernoff bound相对熵的形式,\(\delta=0.05\)持有假设:变量是IID的,(即:在我们的case中,用于estimator计算的样本)。注意,该计算有些复杂,因为变量的范围是\([0, 1/\tau]\),而非常见的\([0, 1]\)。这可以通过乘以\(\tau\)来进行缩放,应用到bound上,接着将结果乘以\(1/\tau\)进行缩放。
“random” policy指的是,从feasible ads集合中随机选择:\(Random(x)=a \sim UNIF(C(X))\),其中\(UNIF(\cdot)\)表示均匀分布。
“Naive” policy对应于理论上有缺陷的监督学习方法(在介绍中详细说过)。这种policy的evaluation相当昂贵,需要每个example每个ad进行一个evaluation,在此,test set的size被减小到一个click 8373个examples,这会减小结果的重要性。通过按时间先后顺序选择在test set中的第一个events(例如:在training set中与它们最相似的events),我们会将该结果偏向于naive policy。然而,naive policy会收到0 reward,这要比其它方法都要小很多。使用这种evaluation的一个可能担忧之处是,naive policy总是会找到那些不会被explored的good ads。一种快速验证表明:这是不正确的——naive argmax会简单地做出难以置信的选择。注意,我们只上报了evaluation against \(\tau=0.05\),因为evaluation against \(\tau=0.01\)并不明显,尽管reward仍是0.
“Learned” policies会依赖于\(\tau\)。如定理3.2所示,随着\(\tau\)是减小,我们相竞争的hypotheses的有效集合是增加的,从而允许learned policy具有更好的效果。确实,当我们把\(\tau\)从0.05减小到0.01时,learned policy和random policy的估计会同时提升。
在test set上的empirical CTR是0.0213,要比最好的learned policy的estimate稍稍大些。然而,该数目并不直接可比,因为estimator在该policy的true value上提供了一个下界(这是由于一个非零的\(\tau\)会引入bias,因为任意部署的policy只会从可以展示的ads集合中选择,而非所有的ads集合(它们可能在某个时间点上未被展示过))。
empirical结果与理论方法大致是consistent的——它们提供了一个一致的关于policy value的最坏估计,不过它们具有足够动态的范围来区分learned polices vs. random policies,以及learned policies在更大空间(更小\(\tau\))vs.更小空间(更大\(\tau\))上,理论上不完善的naive方法 vs 合理的方法(在ads的explored空间上进行选择)。
5.结论
我们在理论上和经验上发表、调整、和评估了首个方法:使用来自controlled bias和estimation的logged data,解决在exploration的warm-start问题。该问题对于推荐内容给用户的互联网公司的应用是很有吸引力的。
然而,我们相信,这对于机器学习的其它应用领域也具有吸引力。例如,在reinforcement learning中,offline policy evaluation的标准方法会基于importance weighted samples[3,11]。这里发表的这个基本结果可以被应用到RL setting中,消除了这个必要条件:即显式(explicitly)一个选中action的概率,从而允许RL agent从来自其它agents的外部observations中进行学习。