阿里盒马团队在KDD 2018上开放了它们的方法:《Learning and Transferring IDs Representation in E-commerce》, 这个方法也很简单,我们来看下paper的主要内容部分:
3.4 联合嵌入Attribute IDs
通过探索在item ID和它的attribute IDs间的结构连接,我们提出了一个hirerarchical embedding模型来联合学习item ID和attribute IDs的低维表示。模型结构如图4所示,其中item ID是核心的交互单元,它与attibute IDs间通过虚线连接。
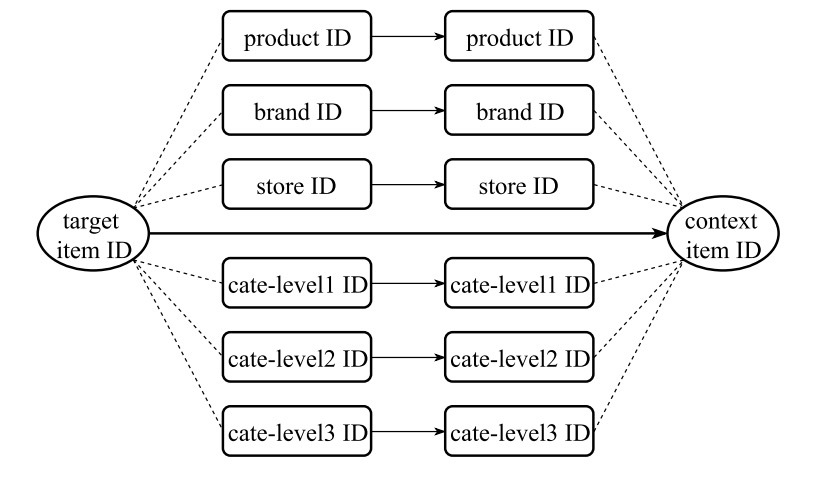
图4
首先,item IDs的共现也隐含了对应attribute IDs间的共现,它通过图4的实心键头表示。假设存在K个类型的IDs,并使 \(ID_s(item_i) = [id_1(item_i), \cdots, id_k(item_i), \cdots, id_K(item_i)]\),其中\(id_1(item_i)\)等于\(item_i\)的item ID,\(id_2(item_i)\)是product ID,\(id_3(item_i)\)是store ID等。我们学习目标替换成:
\[P(ID_s(item_j) | ID_s(item_i)) \\ = \sigma(\sum\limits_{k=1}^K (w_{jk} e_{jk}')^T (w_{ik} e_{ik})) \\ = \prod\limits_{s=1}^S \sigma(-\sum_{k=1}^K (w_{sk} e_{sk}')^T (w_{ik} e_{ik}))\]…(7)
其中,\(e_{\cdot k}' \in E_k'(\subset R^{m_k \times D_k})\)以及\(e_{\cdot k} \in E_k(\subset R^{m_k \times D_k})\)。\(E_k'\)和\(E_k\)是分别对应于类型(type)为k的context和target representations。对于类型k,\(m_k\)是它的embedding vectors的维度,\(D_k\)是它的字典size。注意,不同类型的IDs可以被嵌入到不同的维度上。标量\(w_{ik}\)是\(id_k(item_i)\)的权重。假设每个item的贡献与\(id_k(item_i)\)相等,\(id_k(item_i)\)包含了\(V_{ik}\)个不同的items,\(w_{ik}\)与\(V_{ik}\)成反比是合理的。更正式的,我们有:
\[I(x)= \begin{cases} 0, & \text{x is False} \\ 1, & \text{x is True} \end{cases}\]…(8)
\[V_{ik} = \sum\limits_{j=1}^D I(id_k(item_i) = id_k(item_j))\]…(9)
\[w_{ik} = \frac{1}{V_{ik}} (k=1, \cdots, K)\]…(10)
例如,\(w_{i1}=1\)表示每个\(id_1(item_i)\)刚好包含了一个item;而\(w_{i2} = \frac{1}{10}\)表示:product ID\((item_i)\)包含了10个不同的items。
第二,item ID和attribute IDs间的结构连接意味着限制(constraints),例如:两个item IDs的向量应更接近,不仅是对于它们的共现,而且对于它们共享相同的product ID, store ID, brand ID或cate-level1 ID等。相反的,attribute IDs等价于包含在对应item IDs内的信息。以store ID为例,对于一个指定store ID的embedding vector,它可以看成是应该商店所售卖的所有item IDs的合适的总结(summary)。 相应的,我们定义了:
\[p(item_i | ID_s(item_i)) = \sigma(\sum\limits_{k=2}^K w_{ik} e_{i1}^T M_k e_{ik})\]…(11)
其中,\(M_k \subset R^{m_1 \times m_k} (k=2, \cdots, K)\)是一个转移矩阵,它会将embedding vector \(e_{i1}\)转称到相同维度的embedding vector \(e_{ik}\)上。接着,我们最大化下面的平均log概率:
\[J = \frac{1}{N} \sum\limits_{n=1}^N ( \sum\limits_{-C \leq j \leq C}^{1 \leq n+j \leq N, j \neq 0} log p(ID_s(item_{n+j}) | ID_s(item_n)) \\ + \alpha log p(item_n | ID_s(item_n)) - \beta \sum_{k=1}^K \| M_k \|_2)\]…(12)
其中,\(\alpha\)是介于IDs间的约束强度,\(\beta\)是在转移矩阵上的L2正则的强度。
我们的方法可以将item ID和它的attrbute IDs嵌入到一个语义空间中,它很有用。item ID的属性和它的attrbute IDs对于一个相对长的时间来说是稳定的,该jointly embedding model和学到的表示会每周更新一次。
3.5 Embedding User IDs
用户偏好受item IDs交互序列的影响,通过对交互的item IDs的embedding vectors做聚合来表示user IDs是合理的。有许多方法来聚合item embedding vectors,比如:Average, RNN等[26],本paper中使用的是平均方式(Average)。
由于Hema中的用户偏好变化很快,user IDs的embedding vectors也应进行频繁更新(比如:按天更新),来快速响应最新的偏好。不同于RNN模型,它需要训练过程并且计算开销很大,Average可以在很短的时间内学习和更新表示。
对于用户\(u \in U\),假设\(S_u = [item_1, \cdots, item_t, \cdots, item_T]\)表示交互序列,其中最近的T个item IDs以逆时序的方式排列。我们为用户u构建了embedding vector:
\[Embedding(u) = \frac{1}{T} \sum\limits_{t=1}^{T} e_t\]其中,\(e_t\)是\(item_t\)的embedding vector。
3.6 模型学习
对该jointly embedding model进行优化等同于最大化(12)的log似然,它与log-uniform negative-sampling相近。为了解决该最优化问题,我们首先使用“Xavier” initialzation来初始化所有可训练参数。接着使用SGD算法和shuffled mini-batches到J上。参数的更新通过BP+Adam rule来完成。为了加速并行操作,在NVIDIA-GPU+tensorflow上训练。
模型的超参数设置如下:context window C=4; negative samples数 S=2; embedding dimensions为 \([m_1, m_2, m_3, m_4, m_5, m_6, m_7] = [100, 100, 10, 20, 10, 10, 20]\);constraints强度\(\alpha=1.0\);L2 reg强度 \(\beta=0.01\);batch size=128, 训练5个epochs。
#