NVidia在2017年提出了《Training Deep AutoEncoders for Collaborative Filtering》:
1.介绍
Amazon, Netflix和Soptify均使用推荐系统给用户推荐items。推荐系统分为两类:基于上下文的推荐(context-based),基于个性化的推荐(personized)。
基于上下文的推荐可以解释上下文因子,比如:位置、日期、时间。基于个性化的推荐通常使用CF来推荐items给用户。在本方法中,用户兴趣会基于个人品味、其它用户在系统中行为的偏好、用户间的隐式相似度进行分析。底层假设是:两个具有相似品味的用户,比两个随机选择的用户,在对于某一个item具有相同的看法上,具有更高的似然。
在设计推荐系统中,目标是提取预测的accuracy。Netflix Prize比赛提供了最著名的示例:预测用户对于电影的评分。
这是个经典的CF问题:推断在 \(m \times n\)矩阵R中缺失条目,它的第(i,j)条目描述了由用户i给第j个item的评分。接着使用RMSE(Root Mean Squared Error)进行衡量。
1.1 相关工作
深度学习在图片识别、NLP、增强学习等领域取得了突破。自然的,这些成功也刺激了在推荐系统上使用deep learning。首先使用DL的推荐系统使用的是RBM(restricted Boltzman machines)[16]。一些最近方法使用autoencoders [17, 18],前馈神经网络[5]以及RNN [17]。许多流行的矩阵分解技术可以看成是降维。因此,对于推荐很自然地会采用deep autoencoders。I-AutoRec(item-based autoencoder)和U-AutoRec(user-based autoencoder)首先进行了成功尝试[17]。
还有许多非深度学习类型的CF方法[3,15]。矩阵分解技术,例如:ALS[8,12],概率矩阵分解[14]都很流行。最健壮的系统可以包含这些方法来赢取Netflix Prize竞赛[10]。
注意,Netflix Prize数据也包含了临时信号: 时间(time),即:何时做出的评分。这样,许多经典CF方法可以被扩展成插入时间信息,比如: TimeSVD++[11],最近的RNN-based技术[19]。
2.模型
我们的模型受U-AutoRec方法的启发,但有许多重要的区别。我们会训练更深的模型。为了确保没有预训练,我们会:
- a) 使用SELU(scaled exponential linear units)
- b) 使用较高的dropout
- c) 在训练期间使用迭代型output re-feeding
一个autoencoder是这样的网络,它会实现两个转换:
- encoder encode(x): \(R^n \rightarrow R^d\)
- decoder(z): \(R^d \rightarrow R^n\)
autoencoder的目标是获取数据的d维数据,以确保在x和\(f(x)=decode(encode(x))\)间的error measure是最小化的。图1描述了典型的4-layer autoencoder网络。如果在encoding阶段将噪声添加到该数据中,该autoencoder会被称为de-noising。Autoencoder是一个很好的降唯工具,可以被认为是一种严格泛化的PCA。一个没有非线性激活函数、只有“code” layer的autoencoder,可以在encoder中学习PCA转换,以MSE loss进行最优化。
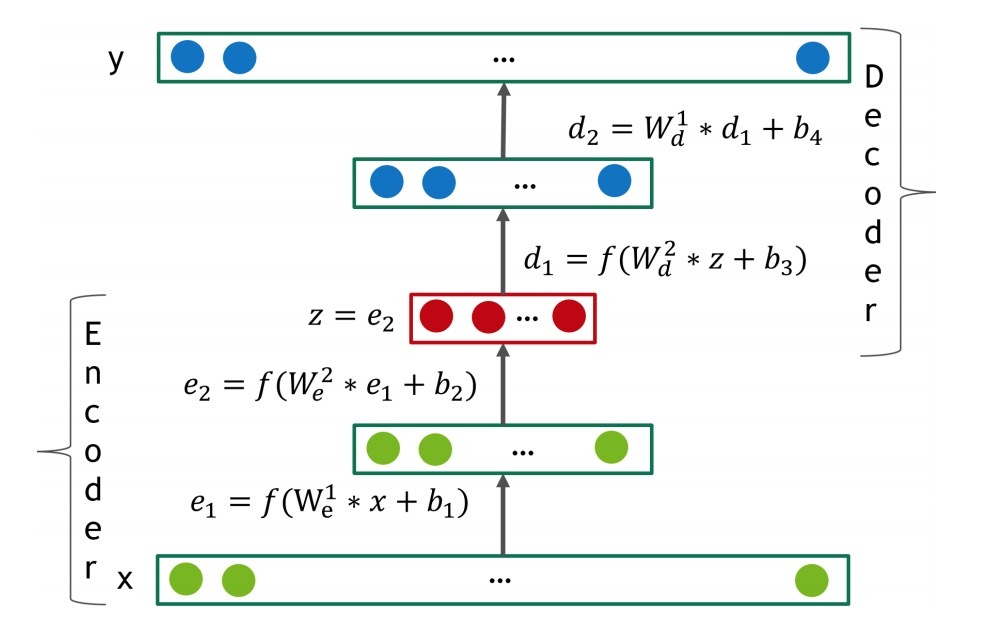
图1:
在我们的模型中,encoder和decoder部分的autoencoder包含了前馈神经网络,它具有经典的fully connected layers:\(l = f(W * x+b)\),其中f是一些非线性激活函数。如果activation的范围小于这些数据,decoder的最后的layer应是线性的。我们发现,对于在hidden layers中的激活函数f来说,包含非零负部分(non-zero negative part), 接着我们会在大多数我们的实验中使用SELU units。
如果ecoder与encoder是镜像结构,那么可以限制:decoder的权重\(W_d^l\)与从相应的layer l转换的encoder权重\(W_e^l\)相同。这样的autoencoder被称为受限的(constrained/tied),比不受限的参数数目要小一倍。
前向传播和推断(forward pass和inference):在forward pass(和inference)期间,模型会使用通过评分训练集\(x \in R^n\)的用户向量表示,其中n是items的数目。注意,x是非常稀疏的,而decoder的输出\(f(x) \in R^n\)是dense的,它包含了在语料中所有items的预测评分。
2.1 Loss function
由在用户表示向量x中预测零值是没有意义的,我们会根据[17]的方法,来最优化MMSE(Masked Mean Squared Error loss):
\[MMSE = \frac{m_i * (r_i - y_i)^2} {\sum_{i=0}^{i=n} m_i}\]…(1)
其中\(r_i\)是实际评分,\(y_i\)是重构评分(或预测评分),其中\(m_i\)是一个mask函数:
- 如果\(r \neq 0\)则\(m_i=1\)
- 否则为\(m_i=0\)
注意,这里在RMSE得分和MMSE得分之间有一个简单的关系:\(RMSE = \sqrt{MMSE}\)
2.2 Dense re-feeding
在训练和inference期间,输入\(x \in R^n\)是非常稀疏的,由于很少用户会在现实中进行评分,所有items只有一少部分有评分。另一方面,autoencoder的输出\(f(x)\)是dense的。假设考虑这样的理想场景:有一个完美的f,使得:
\(f(x)_i = x_i, \forall i: x_i \neq 0\),
其中\(f(x)_i\)可以准确预测所有用户对于items: \(x_i = 0\)的将来评分(future ratings)。那么这意味着,如果用户对新的item k进行评分(创建一个新向量x’),那么\(f(x)_k = x_k',f(x)=f(x')\)。这样,在理想场景下,\(y=f(x)\)应是一个关于训练良好的antoencoder \(f(y)=y\)的确定点(fixed point)。
为了显式增强fixed-point constraint,以及能执行dense training updates,我们使用一个迭代式dense re-feeding steps(以下的3和4)来增大每个最优化迭代(optimization iteration)。
- 1.给定稀疏x,使用等式(1)来计算dense f(x)和loss
- 2.计算梯度、执行权重更新(backward pass)
- 3.将f(x)看成是一个新的样本,计算f(f(x))。现在f(x)和f(f(x))是dense的,来自等式(1)的loss上所有m项都是非零的(第二个forward pass)
- 4.计算梯度、执行weight更新(第二个backward pass)
第(3)和(4)对于每个迭代也可以执行多次。
3.实验和结果
3.1 实验设定
对于评分预测任务,最相关的是,给定过去的评分来预测将来的评分,而非随机预测缺失的评分。对于评估,我们将原始的Netflix Prize训练集基于时间分割成许多份训练集和测试集。训练间隔(training interval)比测试间隔(testing interval)要包含了更早的时间。测试间隔接着被随机划分成Test和Validation子集,以便来自测试间隔的每个评分具有50%的机会出现在其中的一个子集上。没有出现在训练集上的users和items,会从test和validation子集上移除,表一提供了详细的数据。
对于大多数实验,我们使用了一个batch size=128, 使用momentum=0.9的SGD,learning-rate=0.001.我们使用xavier initialization来初始化参数。注意,不同于[18],我们没有使用layer-wise pre-training。我们相信,选择合适的activation function,可以成功。
3.2 激活函数类型的影响
为了探索使用不同activation function的影响,我们在深度学习的一些流行选择上做了测试:sigmoid, RELU, max(relu(x),6). tanh,ELU, LRELU,SELU。在每个hidden layer上使用4层autoencoder。由于评分的范围是[1, 5],我们将decoder的最后一层保持为线性,以用于sigmoid和tanh的模型。在其它所有模型中,activation function会被应用到所有layers。
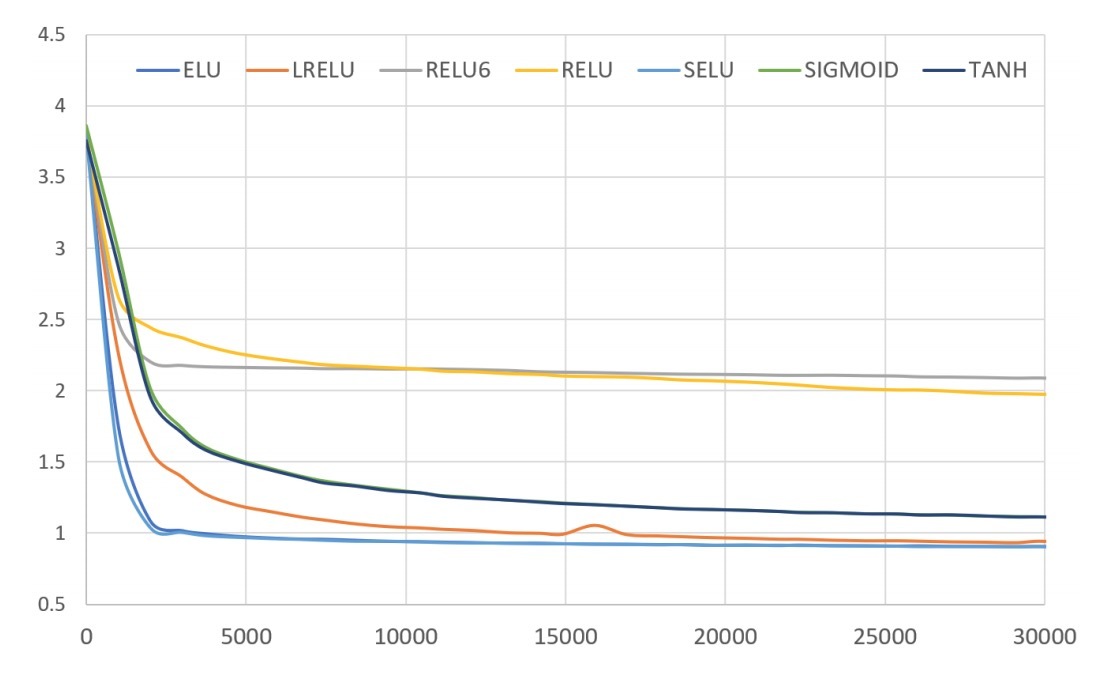
图2:
我们发现,在该任务上,ELU,SELU和LRELU的效果会比SIGMOID, RELU, RELU6和TANH要更好。图2做这部分做了展示。有两个属性,看起来分离的激活(separate activations)要比不分离的要更好:
- a) non-zero negative part
- b) unbounded positive part
这里,我们下结论,在该setting中,这些属性对于训练成功很重要。这样,我们使用SELU激活单元,并对基于SELU的网络进行模型效果调参。
图2
3.3 overfitting
我们训练所使用的最大数据是,表1的”Netflix Full”,包含了477K用户的98M条评分数据。在该数据集中的电影数(items)n=17768. 因而,encoder的第一层将具有\(d * n + d\)个权重,其中,d是在layer中的units数。
对于现代deep learning算法和硬件来说,这是相当小的任务。如果我们使用单层(single layer)的encoders和decoders,我们可能会对训练数据overfit,即使d小到512. 图3清晰地演示了这个。从不受限的autoencoder切换到受限autoencoder可以减少overfitting,但不会完整地解决该问题。
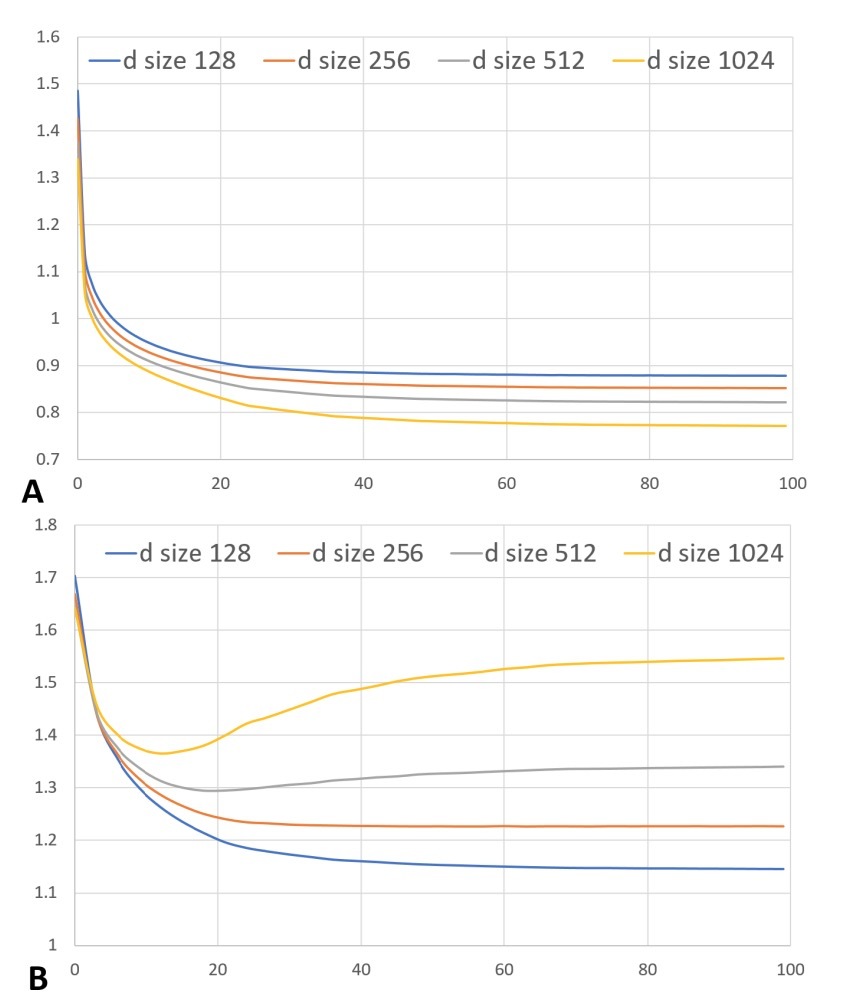
图3
3.4 层数更深
当让layers更宽时,可以帮助训练的loss下降,添加更多层通常有利用网络能力的泛化。我们为所有hidden layers选择足够小的维度(d=128),以便轻易避免overfitting,并开始添加更多的layers。表2展示了,这里存在着layers数与评估的accuracy间存在着一种正相关。
表2
在encoder和decoder的第一层到第三层,在RMSE上提供了很好的提升。(从1.146到0.8378). 之后,随机添加更多层会有用,然后,它会收益递减。注意,在encoder和decoder中中使用d=256,会有9115240个参数,它几科是这些深度模型的两倍还在多,它具有更差的评估RMSE(以上1.0)。
3.5 Dropout
第3.4节展示了,当我们添加更多小layers时,事实上会收益衰减。因而,我们会更宽范围地实验模型架构和超参数。我们的最有希望的模型具有以下架构:
n, 512, 512, 1024, 512, 512, n
这意味着encoder有3层(512, 512, 1024),coding layer为1024,decoder的size为(512, 512,n)。如果没有正则化,该模型会很快overfits。为了进行正则化,我们尝试了许多dropout值,非常高的dropout概率(比如:0.8)看起来是最好的。图4展示了评估的RMSE。我们只在encoder output上应用drouput,例如:f(x)=decode(dropout(encode(x)))。我们会尝试在模型的每一层应用dropout,但这扼杀了模型收敛,不会提升泛化。
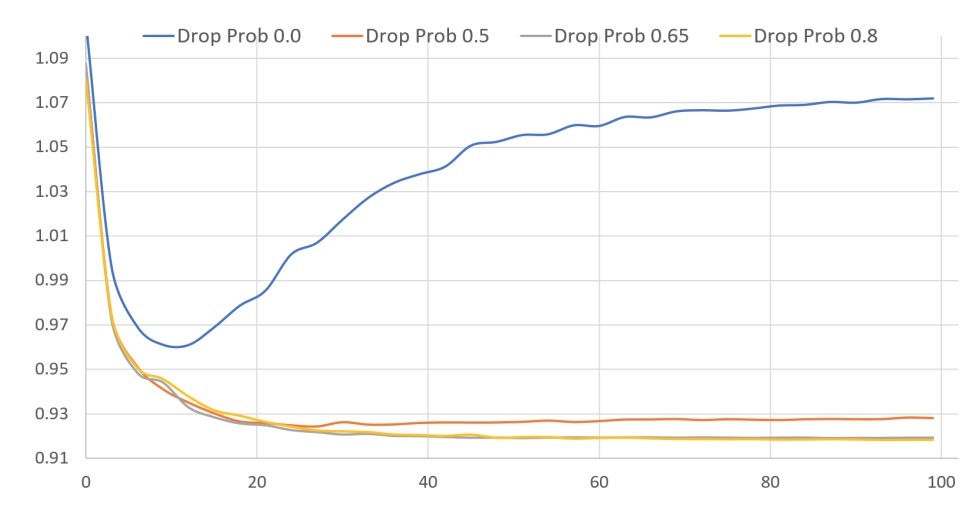
图4
3.6 Dense re-feeding
迭代式dense re-feeding(见2.2节)在我们的6-layer模型: (n, 512, 512, 1024, dp(0.8), 512, 512, n)的accuracy评估中会提供给我们额外的提升。这里,每个参数表示了inputs、hidden units、outputs的数目,dp(0.8)表示一个dropout layer,它的drop概率为0.8. 只应用output re-feeding不会对模型效果有提升。然而,结合更高的learning rate,它可以极大提升模型的performance。注意,更高的learning rate(0.005),如果没有dense re-feeding,模型会开始偏离。详见图5.
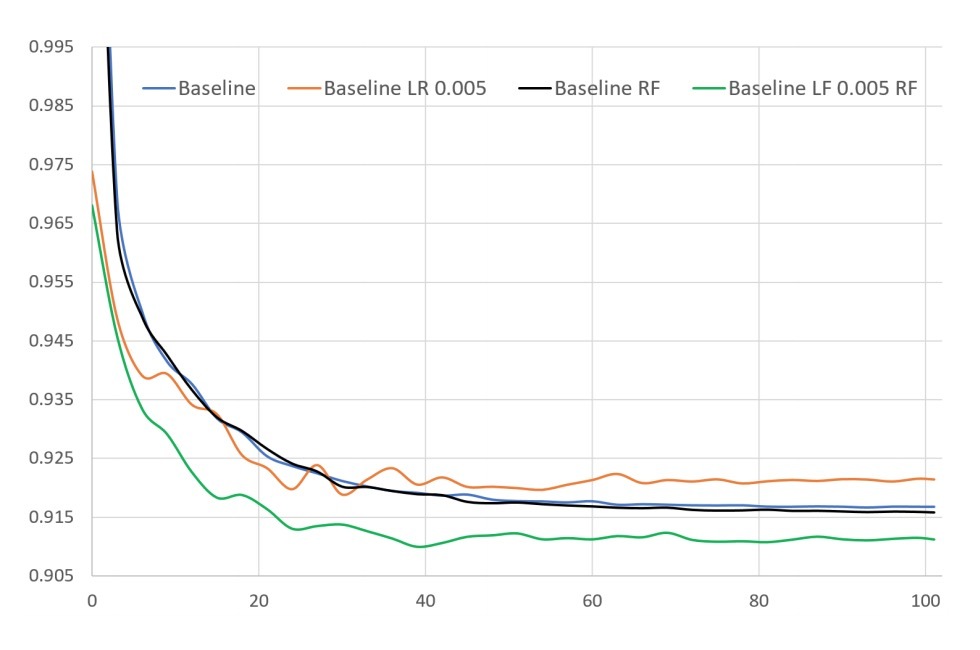
图5
应用dense re-feeding和增加learning rate,允许我们更进一步提升RMSE的评估RMSE,从0.9167到0.9100.选择最好的evalutation RMSE的一个checkpoint,计算test RMSE给定0.9099,我们相信比其它方法有更好。
3.7 与其它方法的比较
我们使用我们最好的模型,与Recurrent recommender Network进行比较(它要好于PMF, T-SVD, I/U-AR)。注意,不同于T-SVD和RRN,我们的方法不会对评分的时序动态性(temporal dynamics of ratings.)做出显式解释。表3展示了,它对future rating预测任务上要比其它方法要好。我们使用训练集训练每个模型,在100 epochs计算evaluation RMSE。接着,最高的evaluation RMSE的checkpoint在测试集上进行测试。
“Netflix 3 months”的训练数据比”Netflix full”要小7倍,也就是说,在模型效果上差些并不吃惊(0.9373 vs. 0.09099)。事实上,在”Netflix full”上效果最好的模型会在该集合上over-fits,我们必须减小模型复杂度(见表4)