google在google+这个产品上提出了《Improving User Topic Interest Profiles by Behavior Factorization》,我们来看下具体实现:
1.介绍
2.相关工作
2.1 构建user profiles
对于许多用户而言,社交媒体上共享的信息是过饱和的。因此,主题兴趣画像(topic interest profiles)的构建是个性化推荐系统中很重要的一部分。我们的工作受关于利用行为信号的个性化研究的启发。
搜索引擎研究者已经利用user profiles来提供个性化搜索结果【9,11,4,30,35】。通常,user profiles会被表示成一个在高维空间中的向量,这些向量表示了在不同items上的用户偏好(比如:网页、电影、社交媒体posts),或者在不同空间上的用户偏好(例如:表示主题的关键词、或来自类目树taxonomy的主题类别)
2.1.1 MF & Embedding模型
推荐方法的一大类是CF,系统通常会使用一个user-by-item矩阵,每个条目表示用户在一个相应item上的评分。因此,在输入矩阵中的某一行表示:一个特征用户对items的偏好。关于一个用户在一个指定item上的未知偏好,可以使用矩阵补全(matrix completion)来进行推断(infer),研究者们已经使用MF方法取得了巨大进展。
在我们的paper中,我们并没有使用通过items(发表:posts)偏好来表示user profile的方法,我们更关注对user的主题兴趣(topical interests)进行推断,其中主题通过Google知识图谱的条目进行表示(比如:”basketball”、’video games’)。研究者已经使用MF来创建embedding模型,或者生成式模型(如:LDA)来构建user profiles[21]。MF以及生成式模型可以学到latent embedding空间,其中偏好可以通过user和item间的latent embedding factors的相似度进行计算。
比起item-based方法,topic-based方法在社交媒体中更加可扩展,其中实际items(posts)数目会很大。做为替代,通过计算在user topic兴趣和item(post)兴趣间的相似度,我们可以预测在一个item上的一个用户的兴趣。
2.2 社交媒体的个性化user profiles
正如在其它推荐问题上一样,社交媒体研究者通常将构建一个user profile看成是构建一个个性化推荐系统的首要任务。研究者在社交媒体上已经应用MF和生成式模型(LDA)来建模user-topic矩阵,并专门构建了user profiles[8,7,34,3,6,15,33,27]。例如,Guy等人基于content和item的偏好来构建user profiles,接着为社交媒体items(比如:书签和社交软件)来提供个性化推荐[8,7]。Chen等人在twitter上构建了user topic profiles并提供了会话的个性化推荐。User profile也被用于提供好友推荐[6],社群推荐[33],动作推荐(mentioning推荐[33], commenting[27])。
对于一个user profile来说,用户偏好可以使用隐式反馈(比如:用户活动)进行infer[8]。作为对比,在传统推荐系统中,CF通常需要显式评分,这会带来用户的额外开销。例如,Hu等人提出了一个MF方法来利用稀疏数据的隐式反馈。在该思想基础上,Noel等人在MF上提出了一个新的目标函数,并考虑上在feature-based相似度、以及user-user信息。
2.3 上下文个性化
社交媒体平台提供了用户丰富的上下文信息,比如:用户在何时(when)对某用户发表(who’s post)的某主题(what topic)进行了web评论。许多最近研究讨论了如何利用这些丰富的上下文来学习更好的user profiles。Singh等人提出的CMF(协同矩阵因子分解),目标是使用上下文信息来在异构网络上提供推荐。与该工作比较接近的有:
- (a) Liu提出了 a social-aided context-aware recommender systems for books and movies. 会利用丰富的上下文信息来将user-item矩阵划分为多个矩阵[20]
- (b) Jamali等人提出了: a context-dependent matrix factorization model to create user profiles for recommendation in social network [14]。
除了矩阵分解技术外,研究者提出了context-aware generative models来在Twitter上帮助创建user profiles和隐语义模型[25,32,36]。例如,Zhang等人使用生成模型提出了一个two-step framework来首先发现不同的主题域,接着使用MF方法在每个域上提供推荐[37]。不同用户可能对不同领域感兴趣,与我们工作相关,但在用户行为上有些区别。我们主要关注:每个用户的主题兴趣是如何通过不同类型的行为进行划分的。
研究者们已经使用内存来构建和提升user profiles。Li等人提出了一种 transfer learning方法来对两个领域的两个向量,使用相互间的信息进行因子分解[18]。Hu等人提出了一个三元因子分解(triadic-factorization-based)方法来对user-item-domain的tensor进行因子分解,来提供跨领域的个性化推荐。
2.4 行为因子分解
“如果你将知觉(perception)看成是一种联系(contact)和洽谈(communion)的方式,那么,支配感知就是支配联系,限制和管理感知就是限制和管理联系。”—Erving Goffman, The Presentation of Self in Everyday Lif.
最近工作表明,多种上下文可以提升user profiles的质量。在我们的paper中,展示了社交媒体用户具有不同类型的行为与不同主题进行交互,我们应使用行为类型看成是一种重要的上下文。我们也会为不同行为类型构建多个user profiles,接着在不同行为独立的推荐中,灵活使用这些不同的profiles。例如:推荐阅读(read)的内容,推荐分享(reshare)的内容。等
社会学家表明,人们在他们的每一天生活中,会呈现不同的画面给其它人;他们每天的对话会以不同主题展开,具有不同的听众。社交媒体的出现吸引了社会学家的兴趣,他们在网络社群上研究了该现象。例如,社会学家建立了这样的理论:由于用户对于在公开社交媒体上的准确受众(exact audiences)没有清晰看法,他们的行为具有模糊上下文边界[22]。然而,由于不同类型的行为,比如:发表(posting)和评论(commenting),会影响非常不同的受众,我们以下的分析建议,用户在社交媒体上仍会展示出不同的“身份(’identities’)”,以及对不同的主题展示不同类型的行为。通过定量研究,Zhao等人指出:用户体验社交媒体平台(比如:Facebook),与现实中的多种身份相似。据我们所知,我们的paper是首次提出:用户在一个社交媒体上利用不同的在线表示。
3. google+行为分析
我们分析了在google+上的匿名用户在线行为。我们首先抽取了在发表(posts)上的主题条目作为我们的特征,来为每个post构建特征向量。对于每个用户在posts上的行为动作,我们会聚合post对应的feature vectors来为每个用户-行为组合(user-behavior combination)构建一个entity vector。接着,我们对这些user-behavior entity vectors表示的不同的主题兴趣进行粗粒度的measure。我们展示了在这些向量间存在很大的不同,这启发了我们利用行为因子分解来建模不同的行为类型。
3.1 数据集描述
使用了2014 五月的google+用户公开行为来进行分析。我们在所有公开发现上分析了所有用户行为,每条记录被表示为一个tuple:(u,b,E),其中一个用户u(具有一个匿名id)使用行为b来参与一个包含了实体集合E的post。有4种类型的行为:发表(post),分享(reshare)、评论(comment)、+1.
我们会使用google知识图谱的实体形式(它包含的概念有:computer algorithms, landmarks, celebrities, cities, or movies.)来抽取更高级的语义概念,而非使用更低级向量(比如:word tokens)。它当前包含了5亿实体,在主题覆盖上提供了广度与深度。
我们基于标准的实体识别方法(利用实体间的共现先验,实体间的相关度似然,实体在文本中位置,接着最终对实体主题进行最终排序),使用一个实体抽取器。
对于给定的一个post,我们使用相应的知识图谱实体作为特征来表示它的主题。因此,在input tuple(u,b,E)中每个E是一个关于知识图谱实体的集合。例如,如果一个用户\(u_1\)创建了一个关于宠物狗图片的post,与该行为对应的是:(\(u_1\), CreatePost, {“Dog”, “Pet”, …})。如果另一个用户\(u_2\)在一个关于Xbox Minecraft的youtube视频post上进行了评论,该行为对应于该tuple:(\(u_2\), Comment, {“Minecraft”, “Xbox”, …})。
3.2 衡量行为间的不同
对于每个user,我们会使用一个特定类型行为来从他交互的posts中聚合实体。最后,对于每个用户,我们对应于4种不同类型的行类会获得4个主题实体集合。
我们接着使用Jaccard相似度来衡量集合间的不同。
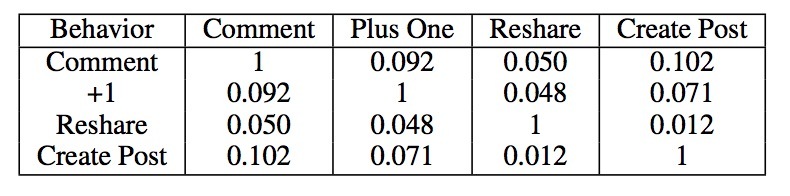
表1: Average Jaccard similarity between pairs of behavior types
在我们计算了每个用户不同行为的jaccard相似得分后,我们接着在所有用户上对分数进行平均。我们过滤掉了:小于10个实体的用户认为是不活跃。表1展示了平均jaccard相似度的结果。我们可以看到,任意两种行为类型间的平均jaccard系统很低。以comment和+1行为为例,在这两种行为间只有9%的主题重合。我们也衡量了用户的发布(publishing)和消费(cosuming)行为上的不同。我们会将用户comment和+1行为的实体组合成一个consuming实体集合,我们将create post和reshare行为的实体组合成一个publishing实体集合。平均jaccard index为0.122. 关于jaccard得分的低重合率表明:用户在不同行为上差异很大。
3.3 讨论
结果分析表明,对于每个用户,他通常在每个行为上具有不同的主题兴趣。也就是说,她通常会在create posts上的主题与comments上的主题会很不同。结果表明,常见的无指定行为(non-behavior-specific)的user profiles可能会在那些强调不同行为类型的应用上执行效果差。
内容推荐者通常会对用户要消费的内容进行定向预测,它可能会受行为(comment和+1)的影响要更好。在其它上下文中,我们会替代预测:用户会创建什么主题的posts。因此,通过为每种行为类型创建主题偏好,特定行为的user profile在不同的推荐上下文上具有更好的效果。
总之,用户在社交媒体上的不同行为包含了重要的上下文信息,它可以帮助我们提升用户个性化profiles上的效果。我们展示了,用户在G+上不同的行为类型会极大影响不同的主题兴趣,使用单独的行为类型构建不同的profiles允许我们为不同的行为上下文定制内容推荐系统。
4.问题定义
4.1 输入行为信号
我们不会为每个用户构建单个profile,相反的,我们提出了为一个用户构建多个profiles来表示它的不同行为类型。特别的,这里我们将社交媒体上的posts行为作为输入,输出一个主题兴趣向量集合来表示每个用户的不同类型的profiles。
给定一个用户集合\(U\),不同的行为类型\(B\),以及一个可以表示社交媒体内容\(E\)的特征集合,输入数据可以被表示成:
\[I = \lbrace t_i = (u_i, b_i, E_i), i=1, ..., N \rbrace\]其中\(u_i \in U, b_i \in B, E_i \subset E\)。
- 每个\(t_i\)表示一个用户在社交媒体内容的某个特定片段上的动作。例如,一个\(t_i\)可以是:创建一个post,或者对某个post进行comment。
- \(E_i\)是该post的特征集合。
这里由于我们正构建user topic profiles,我们使用Google知识图谱的实体作为我们的特征集。然而,总体上,\(E\)可以是任意low-level(例如:words)或high-level的特征(例如:其它实体,或地理位置特征)。
4.2 User profiles
我们将user profiles定义成在特征空间E中的向量集合:
\[B = \lbrace P_u = \lbrace V_{u_B} \rbrace \rbrace\]其中,\(u \in U, B \subset B\),
- \(P_u\)是用户u的user profile,
- \(V_{u_B}\)是用户u在对应于她的行为类型B上的偏好向量。
\(P_u\)可以被认为是一个user tensor。
B即可以是单个行为类型(例如:创建一个post),或是一个不同行为类型的组合(例如:创建一个post和reshare一个post组合)。准确表述为:
\[V_{u_B} = ( p_{u_B}^{e_1}, p_{u_B}^{e_2}, ..., p_{u_B}^{e_k} ), e_j \in E\]其中,对于j=1,…,k,\(p_{u_B}^{e_j}\)是用户u的行为类型 B在特征\(e_j\)上的偏好。
5.我们的方法
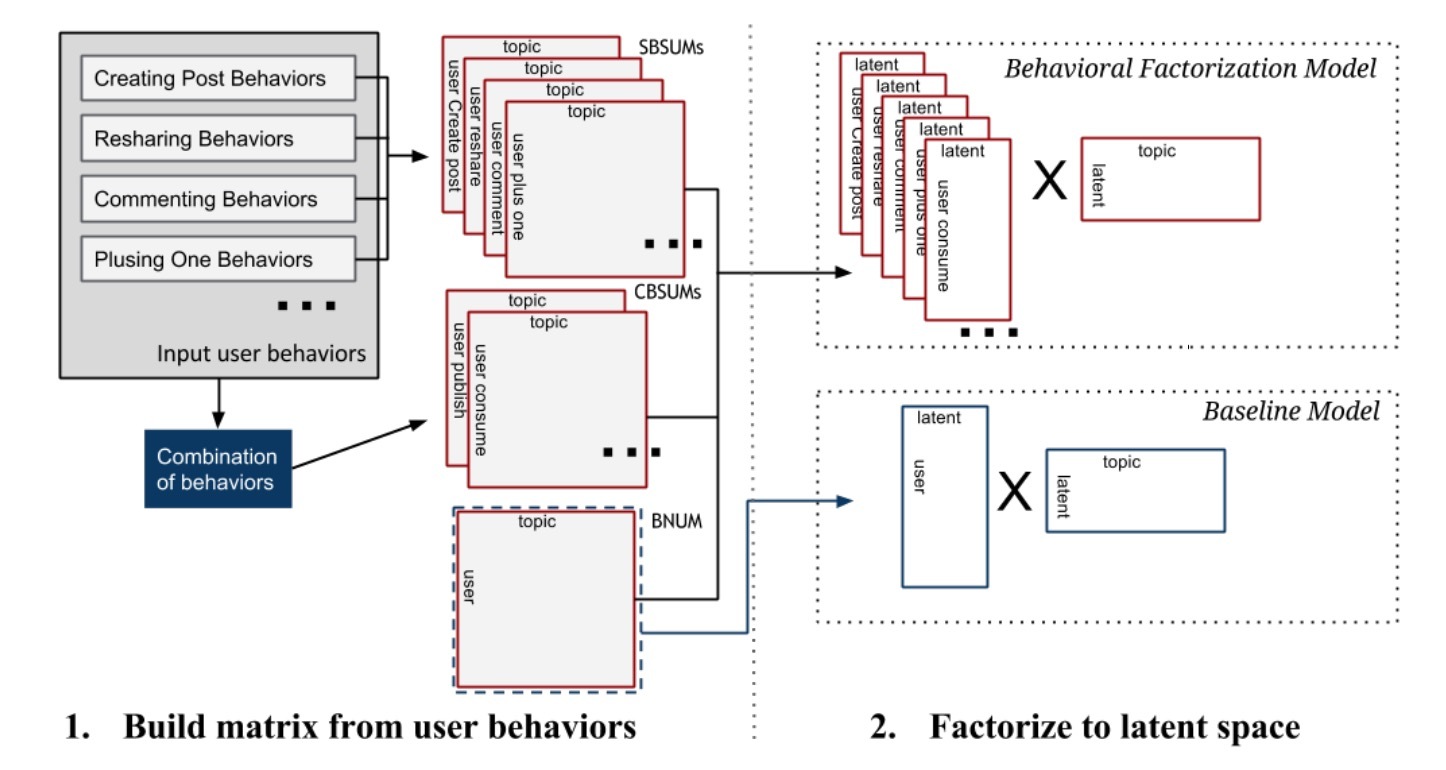
图1: 生成矩阵和因子分解框架
我们引入了行为因子分解法来为个性化推荐构建user profiles,它包含了三个steps,如图1和2所示。
- step 1: 给定第4节中定义的input user action tuples \(I\),我们首先构建不同行为类型的矩阵。这对应于图1中的左部分。
- step 2: 我们对step 1中生成的矩阵进行因子分解来学到latent embedding space。这对应于图1中的右部分。
- step 3: 最后,我们使用学到的latent space来对兴趣主题做预测来构建user profiles。这会为每个用户u创建profiles \(P_u = \lbrace V_{u_B} \rbrace\)。这对应于图2.
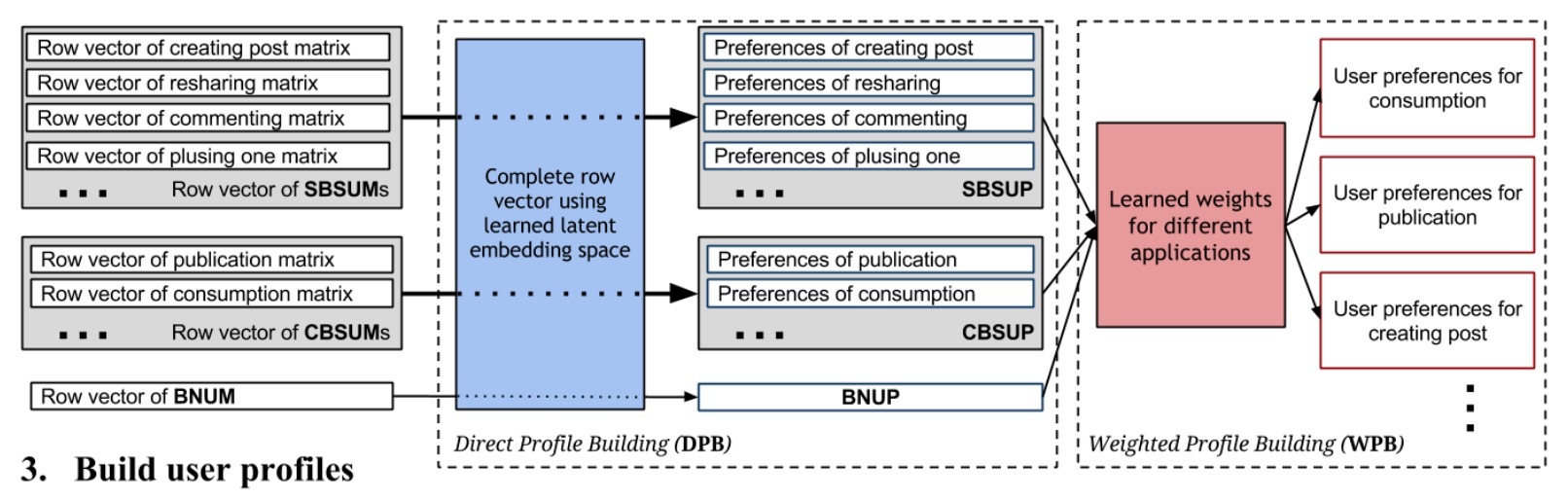
图2: 使用latent embedding space构建user profiles
我们会轮流做介绍。
5.1 step 1: 为不同行为类型构建矩阵
在常见的矩阵因子分解技术中,输入的user-item矩阵R被表示成一个\(N \times K\)的矩阵,其中N表示user的数目,K表示items的数目。R被分解成两个矩阵的乘积,矩阵X (\(N \times L\)),矩阵Y(\(K \times L\))。换句话说,R中的行向量和列向量被映射到一个L维的latent embedding space中。有了这个学到的隐向量,对于在user-item矩阵中任意观察到的行向量,学到的embedding空间可以被用于帮助完成特定的行向量来补全一个用户在items上的估计偏好。
由于我们正构建user-topic-based profiles,我们使用users在主题的兴趣(\(N \times K\) user-topic matrix)作为输入,而非将users在items上的兴趣(\(N \times K\)的user-item matrix)作为输入。
另外,除了使用一个\(N \times K\)矩阵作为输入之外,我们构建和因子分解得到多个矩阵,包括:
- (a) 传统的\(N \times K\)矩阵,被称为Behavior Non-specific User-topic Matrix(BNUM)
- (b) Single Behavior-Specific User-topic Matrix(SBSUM)
- (c) Combined Behavior-Specific User-topic Matrix(CBSUM)
5.1.1 BNUM (Behavior Non-specific User-topic Matrix)
这里,每个条目表示一个用户在特定主题上的隐式兴趣。给定输入用户tuples \(I=\lbrace t_i = (u_i, b_i, E_i), i=1, 2, ... \rbrace\),我们首先引入涉及用户u的tuples \(I_u\):
\[I_u = \lbrace t_j = (u_j, b_j, E_j) \rbrace, t_j \in I \wedge u_j = u\]接着,我们为每个user和topic pair生成观察值:
\[r_{ui} = r(I_u, i)\]也就是说,我们首先抽取所有涉及用户u的tuples \(I_u\),在给定用户u涉及主题i的tuples下,使用函数r来计算隐式兴趣。该函数有许多可能的形式,对于不同行为可以训练不同的权重。我们使用以下的等式做为baseline来计算隐式兴趣:
\[r_{ui} = \frac{(\sum\limits_{I_u} \sum\limits_{e \in E_j} \sigma_i(e)) + 1}{(\sum\limits_{I_u} \| E_j \|) + (\|\cup_{I_u} E_j\|)}\]…(1)
如果i=e,\(\sigma_i(e)\)为1; 否则为0. 也就是说用户u对主题i的隐式兴趣,可以通过i在所有用户u行为上的出现次数,除以所有items的出现总和来计算。我们会使用additive smoothing来对该值进行平滑。
5.1.2 SBSUM (Single Behavior-Specific User-topic Matrix SBSUM)
SBSUM和CBSUM将行为类型单独划分来生成独立的user-topic矩阵。给定一个行为类型的特征集合\(B \subset B\),我们想构建矩阵\(R_B = \lbrace r_{ui}^B \rbrace\),其中每个条目表示从B中行为类型得到的隐式兴趣。
我们使用与等式(1)的相同方法,但增加了限制来过滤不在B中的行为类型:
\[r_{ui}^B = \frac{(\sum\limits_{I_u \wedge b_j \in B} \sum\limits_{e \in E_j} \sigma_i(e)) + 1}{ \sum\limits_{I_u \wedge b_j \in B} \| E_j \| ) + (\|\cup_{I_u \wedge b_j \in B} E_j \|)}\]…(2)
对于每个B,使用该等式,我们可以构建一个矩阵,它使用B中的行为类型来表示用户观察隐式反馈,可以被设置成单个行为类型,或是多个行为类型集合。因此,基于B选择,我们可以构建两个类型的特定行为user-topic矩阵(BSUM):SBSUM, CBSUM。
首先,我们为每个行为类型构建了一个user-topic矩阵,比如:creating post,resharing,commenting或+1. 每个矩阵的条目是观察值\(r_{ui}^B\),它通过等式(2)计算,其中B是单个行为。给定\(B = \lbrace b_1, b_2, ..., b_M \rbrace\)为所有行为类型集合,我们生成以下M个SBSUM:
\[\begin{cases} R_{b_1} = \lbrace r_{ui}^B \rbrace, B=\lbrace b_1,b_1 \in \mathscr{B} \rbrace \\ R_{b_2} = \lbrace r_{ui}^B \rbrace, B=\lbrace b_2,b_2 \in \mathscr{B} \rbrace \\ ... \\ R_{b_M} = \lbrace r_{ui}^B \rbrace, B=\lbrace b_M,b_M \in \mathscr{B} \rbrace \end{cases}\]…(3)
5.1.3 CBSUM(Combined Behavior Specific User-topic Matrix)
在构建SBSUM时,我们创建了M个矩阵,每个表示单个行为类型。然而,我们也希望捕获多种行为类型组合的主题兴趣。例如,在G+中,creating post和resharing posts会生成内容并广播给所有followers,这两种行为类型可以组合在一起来表示用户的发表(publication)。
同时,commenting和+1两者表示用户对post的消费行为。将两者组合在一起可以表示关于用户消费(consumption)的主题兴趣。因此,给定行为类型集合,每个集合是B \(\lbrace B_1, B_2, ..., B_p \rbrace\)的一个子集,我们构建了P个矩阵,每一个均表示用户的组合行为:
\[\begin{cases} R_{B_1} = \lbrace r_{ui}^B \rbrace, B=\lbrace B_1,B_1 \in \mathscr{B} \rbrace \\ R_{B_2} = \lbrace r_{ui}^B \rbrace, B=\lbrace B_2,B_2 \in \mathscr{B} \rbrace \\ ... \\ R_{B_M} = \lbrace r_{ui}^B \rbrace, B=\lbrace b_M,b_M \in \mathscr{B} \rbrace \end{cases}\]…(4)
5.2 step 2: 学习latent embedding space
这里我们引入了一个矩阵分解(MF)技术来构建用户的主题画像(topic profile)作为baseline方法。另外,我们引入了我们提出的方法,它将baseline算法扩展成行为因子分解。
5.2.1 baseline: MF
在构建BNUM后,我们会学习一个latent embedding space,它可以被用于补全observed user-topic matrix来获得预测的user-topic偏好。在推荐研究中,在学术界和工业界有许多方法尝试改进MF技术。这里我们使用hu[13]提出的因子分解技术。
采用[13]有一个非常特别的原因。在社交媒体平台上,对于大多数用户来说,隐式兴趣信号更容易获取。然而,许多推荐算法并没有考虑显式兴趣 vs. 隐式兴趣信号间的潜在不同。在user-item矩阵上有效的所有其它MF方法,可以被应用到我们的框架中,来使用行为因子分解(behavior factorization)构建user profiles。注意:在后续讨论中,user-topic矩阵中的”topic”与user-item中的item相似。
给定从\(r_{ui}\)的隐式兴趣中观察到的user-item矩阵,Hu[13]将观察集划分成两个变量:偏好\(p_{ui}\)、置信度\(c_{ui}\)。这里\(p_{ui}\)是一个二值变量,它表示用户u是否对item i感兴趣:
\[p_{ui} = \begin{cases} 1 , r_{ui}>0 \\ 0 , r_{ui}=0 \end{cases}\]置信度\(c_{ui}\)表示对偏好\(p_{ui}\)的置信等级。它表示你对兴趣值有多肯定。它可以通过以下方式进行计算:\(c_{ui} = 1 + \alpha r_{ui}\)。
接着,该算法会学到一个latent embedding space,它会将每个user u和item i映射到该空间上(对应于\(x_u\)和\(y_i\))。为了学习该空间,算法会尝试解决以下的最优化等式:
\[\min\limits_{x_*,y_*} \sum\limits_{ui} c_{ui} (p_{ui} - x_u^T y_i) ^ 2 + \lambda( \sum\limits_{u} \| x_u \|^2 + \sum\limits_i \| y_i \|^2)\]…(5)
结果\(x_u\)和\(y_i\)可以被用于补全user-item矩阵,它会估计一个user会喜欢一个item有多喜欢。[13]提出的算法对于隐式feedback/interest datasets工作良好。
在这一点上,我们使用等式(1)来构建user-topic矩阵,采用MF来学习一个latent embedding space。再者,我们可以通过估计用户u在所有主题上的偏好来建模任意用户u的兴趣。对于没有出现在原始user-topic matrix(用于训练该embedding space)中的任意新用户,我们仍能通过使用学到的topic embedding vectors \(y_i\)来将它们映射到该embedding space中。我们将在第5.3节中讨论。
5.2.2 行为因子分解模型(BF)
不同于上述介绍的矩阵因子分解模型,我们希望将用户不同的行为类型进行划分,并为每个用户对于不同的行为生成主题偏好。因此,我们不再使用对单个user-topic matrix进行因子分解,而是会对step 1生成的多个user-topic矩阵(BNUM, SBSUM, CBSUM)进行因子分解。
有一些在context-aware矩阵分解、张量分解等技术(Liu[20])上进行的早期探索,会创建多个矩阵并同时学习一个latent space。然而,这些技术不能直接用在我们的行为因子分解问题上,因为我们正构建多个user-topic矩阵,它具有相同的列(column)/主题(topic)空间,但具有不同的行(rows)/用户(users)。他们构建的矩阵对于不同的context具有不同的items,相反的我们会使用一个隐式建模方法,也会考虑上行为上下文间的关系,比如:发布行为组合和消费行为组合。
图1展示了行为因子分解(BF)方法与baseline模型对比的区别。在step 1从用户行为构建矩阵时,不再仅构建BNUM,我们也会构建两类矩阵:SBSUM和CBSUM。
在step 2中,我们将所有生成的矩阵因子分解成相同的latent embedding space。我们会学习一个latent embedding space,并将对应每个特定的行为类型的每个用户和每个item映射到该空间中。在每个矩阵中的每个条目是对该用户行为的隐式兴趣值,因此,我们可以以如下方式扩展baseline模型。
这里\(p_{ui}^B\)和\(c_{ui}^B\)表示每个矩阵的偏好的置信度。给定所有特定的行为类型,我们使用等式(3)和(4)的\(\Gamma = \lbrace B_1, B_2, ...\rbrace\),我们通过优化如下的等式来学习embedding space:
\[min_{x_*,y_*} \sum\limits_{B \in \Gamma} \sum\limits_{u,i} c_{ui}^B (p_{ui}^B - x_u^{B^T} y_i)^2 + \lambda (\sum\limits_{B \in \Gamma} \sum\limits_{u} \| x_u^B \|^2 + \sum\limits_{i} \|y_i\|^2)\]….(6)
通过写出在\(\Gamma\)上的求和,我们使用一个与原始等式(5)相似解来求解该最优化问题,并为user-behavior和topics学习embedding space。
对比原始的user-topic矩阵,通过我们方法学到的embedding space的可能在对语义相似度的衡量上会更好,因为从之前分析(第3节),我们知道在user-topic矩阵上的观察值是从不同行为上的多种不同兴趣的混合。将这些信号相隔离可以产生一个更清晰的topic model。一个最近的paper:《how to learn generative graphical models such as LDA in social media》【31】。在该paper中,他们探索了如何将文档聚合成语料,并表示一个特定的context。由于生成式图模型和矩阵分解都是尝式从数据中学习latent space,该意图可以在两种方法上均可采用。我们的假设是,在user-behavior级别上构建矩阵,而非在user级别上;这可以帮忙我们清晰地标识跨主题的语义联合,不会增加太多的稀疏性。
5.3 step 3: 构建user profiles
最终,我们介绍了如何使用学到的latent embedding spaces来构建user profiles。如图2所示,我们介绍两种方法:
- i) 从profile矩阵的input row vectors构建direct profile
- ii) 通过一个回归模型学到一个权重集合,合并不同的direct profile进行构建weighted profile
对于每个user u,我们会构建\(p_u = \lbrace V_{u_B} \rbrace\)。每个\(V_{u_B}\)是一个关于用户u在特定行为类型B上的主题偏好向量。我们会构建三种类型的user profiles,对应于三种类型的input矩阵:
- BNUP:
- SBSUP:
- CBSUP:
5.3.1 DPB(Direct Profile Building)
我们会使用一个用户的embedding factors(例如:在学到的latent embedding space中对于user u的向量\(x_u\))来生成他的完整的user profiles: \(V_{u_B} \in P_u\)。在DPB中,input是矩阵\(R_B\)中的observed row vectors(对于在\(\Gamma\)中的任意B来说),我们会为每个B构建user profile。
给定一个用户u和B,我们可以获取embedding factor \(x_u^B\),接着使用该embedding factor和topic embedding factors \(Y = \lbrace y_i \rbrace\),通过计算点乘:\(x_u^{B^T} Y\)来生成用户u行为B的偏好列表。接着对于每个用户u,她的output user profile可以被表示成:
\[P_u = \lbrace V_{u_B} = x_u^{B^T} Y \brace, B \in \Gamma\]…(7)
特别的,给定任意B(它是\(B\)的一个子集),我们使用以下的等式来生成用户的SBSUP和CBSUP:
\[V_{u_B} = ( p_{u_B}^{e_1}, p_{u_B}^{e_2}, ..., p_{u_B}^{e_K}), p_{u_B}^{e_i} = x_u^{B^T} y_1\]…(8)
其中,\(x_u^B\)是用户u在行为类型B上的embedding factor。
总之,在DPB中,不同的profiles通过不同的input row vectors来生成,BNUM的row vector会生成BNUP,SBSUM的row vector会生成SBSUP,CBSUM的row vectors会生成CBSUP。例如,为了为每个用户构建BNUP,我们设置\(B = \mathcal{B}\),并使用所有他的已观察主题兴趣值(observed topic interest value)来生成他在该embedding space中的embedding factor \(x_u\)。接着为每个topic i计算\(x_uy_i\),来得到他的BNUP。
\[V_u = (p_u^{e_1}, p_u^{e_2}, ..., p_u^{e_K}), p_u^{e_i} = x_u^T y_i\]…(9)
对于不在学到的embedding model中的新用户,我们仍可以使用等式(2)来生成他的row input vectors,接着将该向量投影到一个embedding factor上。
5.3.2 WPB (Weighted Profile Building)
DPB会为一个用户生成一个behavior profile(如果该用户在过往有行为)。通过将用户的行为类型相分隔,我们可以使用DPB来为用户u的行为B生成profile,但这需要用户u在行为B上具有非零的观察值。对于那些在B上没有行为的用户,\(V_{u_B}\)会为空,这意味着一个没有该行为类型动作的user,不会有一个user profile。这在某种程度上对应于在推荐系统中的冷启动问题。
然而,我们可以通过使用在其它行为类型的user profiles来解决该问题。我们可以使用加权求和(weighted sum)将他们组合来生成一个在主题上的组合偏好向量。这对应于一个transfer learning问题。
这里,为了为用户u的行为类型B生成偏好向量\(V_{u_B}\),而非直接使用等式(7)的结果,我们可以使用等式(10)为在\(\Gamma\)中的所有行为类型所生成的所有偏好向量进行加权求和(weighted sum):
\[V_{u_B} = \sum\limits_{B_t \in \Gamma} W_{B_t} x_u^{B_t^T} Y\]…(10)
\(\Gamma\)中不同行为类型的权重是模型级别的参数,例如:我们会为整个数据集的每个\(B_t \in \Gamma\)学到一个权重。因此,这些权重可以使用一个监督学习方法来从在我们的数据集中具有多种行为类型的所有用户上学到。因此,对于那些在过程历史记录中没有\(B_t\)的用户,我们仍可以为他们构建profiles。
在我们的实现中,我们可以使用线性回归和SGD来学习这些参数。因此,WPB可以生成BNUP、SBSUP、CBSUP,具体取决于应用。在大多数内容推荐应用中,常见的信息消费行为(consumption behaviors)非常重要,我们使用用户已观察到消费行为(observed)来学习权重来构建consumption profile。
6.评估
在之前章节,我们提出了行为因子分解法,它可以学习一个强大的latent space,并为多种行为类型构建user profiles。在该实验中,我们希望验证两个假设:
- H1: 从我们的行为因子分解方法中学到的latent embedding模型在构建user profiles比baseline MF模型要更好
- H2: 通过从多种行为类型中组合偏好向量,我们可以提升在特定行为类型上的user profiles的覆盖度(coverage)
在乘余章节,我们首先描述了如何设置实验,例如:我们使用了什么datasets,如何评估输出的user profiles的效果。接着我们比较了行为因子模型与baseline模型。我们也比较了在构建user profiles上的我们提出的两个方法,结果表明:通过组合行为类型,可以提升高质量的用户覆盖度。
6.1 实验设置
为了评估构建user profiles的效果,我们检查了在预测用户主题兴趣的不同方法。我们将dataset划分为两部分:training set和testing set。我们使用trainingset来训练和构建user profiles,然后在testing set上比较不同模型的效果。
6.1.1 Dataset
我们的dataset包含了在2014年 5月和6月的公开的Google+ 用户行为。第3.1节描述了dataset的生成。我们会同时使用5月的数据来训练baseline和我们的MF模型。我们随机从6月的行为数据中进行20%抽样来学习5.3.2节WPB的权重。使用乘余80%行为数据来评估不同方法的效果。
输入矩阵:在我们的dataset上,我们包含了所有公开5月和6月的posts数据。有4种类型关于posts的行为数据。我们构建不同的user-behavior-topic矩阵:
- SBSUM
- Publication CBSUM
- Consumption CBSUM
- BNUM
6.1.2 评估指标
对于一个给定的行为类型\(B_t\),我们构建的user profile是一个关于在主题\(V_{u_{B_t}}\)上的偏好向量。在该vector上的值会估计:用户u是否会喜欢在行为\(B_t\)上的每个topic。这可以使用\(R_u^{B_t} = \lbrace r_{ui}^{B_t}, i \in E \rbrace\)在testing set上使用等式(2)计算的隐式兴趣进行评估。
尽管在\(V_{u_{B_t}}\)的实际值,和\(R_u^{B_t}\)不需要是相同的,\(B_t\)的一个好的user profile,\(V_{u_{B_t}}\)主题顺序进排序,必须与我们在testing set中观察的相似。
为了比较这两个vectors的顺序,我们会将\(V_{u_{B_t}}\)和\(R_{u}^{B_t}\)转换成两个关于在E中主题的排序列表:\(L_{method} = (e_{r_1}, e_{r_2}, ..., e_{r_N})\)是由profile building方法生成的关于top N主题的排序列表,\(L_{observed} = (e_{o_1}, e_{o_2}, ..., e_{o_N'})\)是所有观察到主题的排序列表。我们会使用如下指标进行评估:
- Recall@N: \(L_{method}\)的top N的主题有多少出现在\(L_{observed}\)
- NDCG@N:
- AP@N:
7.讨论
7.1 潜在的应用
有许多应用可以使用我们方法构建的user profiles。由于我们将用户行为(还有不同的items集合:比如:posts, communities, users)映射到相同的embedding模型上,用户行为和items间的相似度可以用于为推荐生成排序列表。对比常用的user profiles(它不会分隔用户行为),我们的方法不仅会考虑users和items间的内容相似性,也会考虑不同推荐任务的上下文。例如,consumption profile可以用于为一个正在阅读post的用户推荐相关的posts,publication profile可以用于在一个用户创建一个post后为他推荐新朋友。
7.2 局限性和未来改进
提出的行为因子分解框架确实可以提升用户兴趣画像的效果,然而仍有局限性。其中之一是,我们的框架依赖于:用户不同的行为类型天然能反映用户的不同兴趣。在构建社交媒体的用户兴趣画像(比如G+)能运行良好,但不能泛化到其它领域上(比如:不同行为类型不能反映不同的用户兴趣)。
另外,结果表明我们的方法不能在用户非常稀疏、或者目标行为类型(尝试预测)没有数据的情况下。一个原因是,这些用户可能比其它用户具有更低的活跃度。另一个原因是,我们的方法会最优化多个矩阵,它们可能会对相同的用户丢失跨不同行为类型的相关性。为了解决这个问题,我们对使用tensor factorization技术(比如:PARAFAC)在行为矩阵上很感兴趣。我们的方法可以认为是一个tensor factorization上unfolding-based方法的扩展。
另外,我们想直接部署该框架到现实的推荐系统上,并通过在线实验来评估。
参考
https://static.googleusercontent.com/media/research.google.com/zh-CN//pubs/archive/43807.pdf