介绍
从历史行为中建模用户的动态偏好,对于推荐系统来说是个挑战。之前的方法采用序列神经网络以从左到右的方式将用户历史交互编码成隐表示,来生成推荐。尽管它们是有效的,这种从左到右的单向模型是次优的,我们对此仍有争论,因为有以下的限制:
- a) 单向结构限制了在用户行为序列中的隐表示的能力(power)
- b) 通常这样的一个严格排序的序列,并不总是实际可行的
为了解决这样的限制,我们提出了一个序列推荐模型,称为:BERT4Rec,它采用deep bidirectional self-attention机制来建模用户行为序列。为了避免信息泄漏,以及对双向模型的有效训练,我们采用了Cloze objective到序列推荐中,通过联合条件(从左到右的context)预测在序列中随机的masked items。这种方式下,通过允许在用户历史行为中的每个item以及融合从左到右的信息,我们学习了一个bidirectional表示模型来做出推荐。我们在4个benchmark数据集上进行了大量实验,表明我们的模型要胜过state-of-art的序列模型。
1.介绍
用户兴趣的准确表征是一个推荐系统的核心。在许多真实应用中,用户当前兴趣是天然动态和演化的,受他们历史行为的影响。例如,一个用户可能在购买一个任天堂(Nintendo) Switch后,购买配件(比如:Joy-Con controller);但是在正常情况下他不会单买配件。
为了建模这样的序列动态性,提出了许多方法[15,22,40]基于用户历史交互来做出序列化推荐(sequential recommendations)。他们的目标是:在给定一个用户的过往历史交互后,预测他可能会交互的后继item(s)。最近,大量工作采用序列化神经网络(比如:RNN)来建模[14,15,56,58]。这些工作的基本模式是:将用户历史行为编码成一个vector(例如:用户偏好的表示),并使用一个从左到右的序列模型基于隐表示来做出推荐。
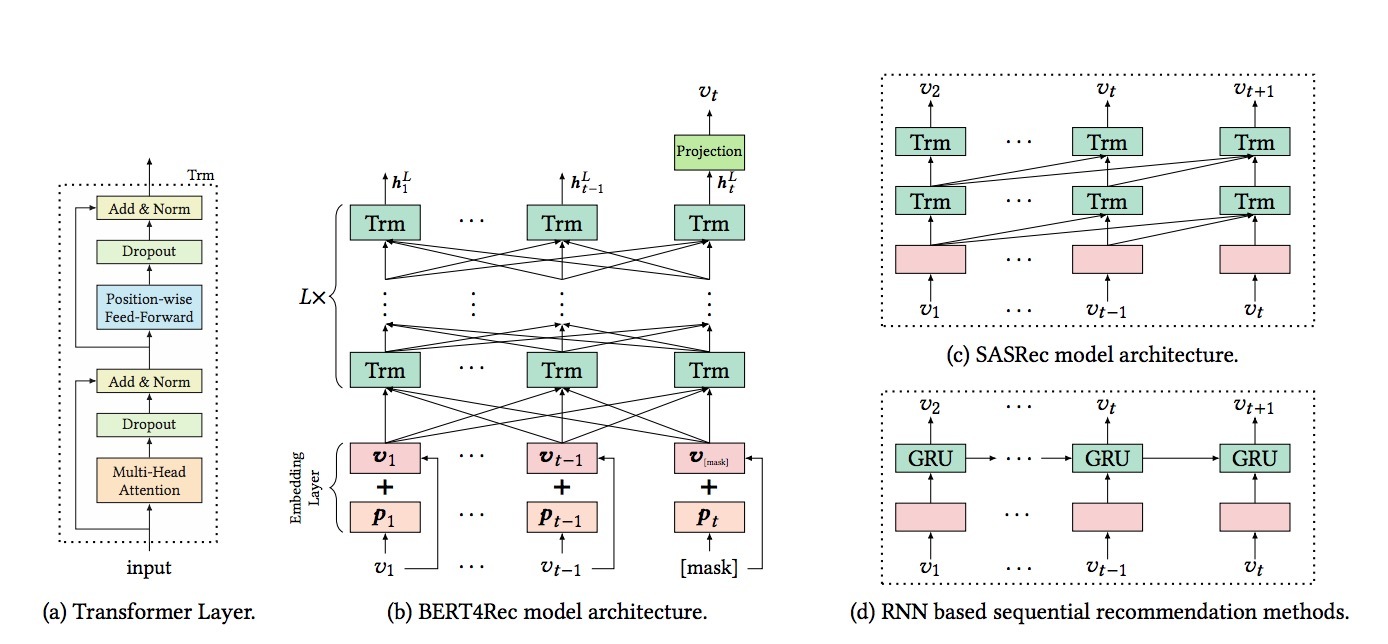
图1 序列推荐模型架构的不同。BERT4Rec可以通过Cloze task来学习一个双向模型,而SASRec和RNN-based模型是从左到右的单向模型,只能顺序预测next item
尽管这些方法很流行并且是有效的,我们仍有争论:这种从左到右的单向模型不足够学到关于用户行为序列的最优表示。主要限制(如图1c和1d所示),这样的单向模型限制了历史行为序列中的items的隐表示的能力,其中每个item只能从之前的items的信息中进行编码(encode)。另一个限制是,之前提出的单向模型最初引入是为了使用原始顺序的序列数据,比如:文本(text)和时序数据。他们通常假设在数据上有一个严格有序的序列,但对于真实应用中的用户行为来说并不总是正确的。实际上,由于存在许多不可观察的外部因素,在一个用户历史交互行为中的items选择,可能不会遵循一个严格的顺序假设。在这种情况下,在用户行为序列建模中在两个方向上包含上下文(context)很重要。
为了解决上述限制,我们使用一个双向模型来学习用户历史行为序列的表示。特别的,受BERT的成功启发,我们提出使用深度双向self-attention模型到序列推荐中,如图1b所示。对于表征能力(representation power),在文本序列建模的深度双向模型的良好结果,表明对于序列表示学习的两个方向包含context很有意义。对于更严格的顺序假设,比起在建模用户行为序列上使用单向模型,我们的模型更适合,因为在双向模型中所有items都可以利用两侧的context。
然而,对于序列化推荐(sequential recommendation)来说训练双向模型并不简单和直接。常见的序列推荐模型通常以从左到右方式训练,并在输入序列中为每个位置预测下一个item。如图1所示,在一个深度双向模型中同时在左向到右向上联合上context,可能会造成信息泄露,例如:允许每个item间接地“看到target item”。这会使得预测future项变得不重要,该网络可能不能学到任何有用的东西。
为了解决该问题,我们引入了Cloze task[6,50]来取代在单向模型(例如:序列化预测next item)中的目标函数。特别的,我们在输入序列中随机将一些items进行遮掩(mask)(例如:使用一个特别token[mask]进行替代),接着基于围绕他们的context来预测这些masked items的ids。这种方式下,我们可以避免信息泄露,并通过允许在输入序列中的每个item的表示融合(fuse)左和右的context,学到一个双向表示模型。除了训练一个双向模型外,Cloze objective的另一个优点是,它可以生成更多样本(samples)在多个epochs上训练一个更强大的模型。然而,Cloze task的缺点是,对于最终任务(例如:sequential recommendation)不一致。为了解决该问题,在测试期间,我们会在输入序列的末尾添加特殊token “[mask]”来表示我们需要预测的item,接着基于它的最终hidden vector来作出推荐。实验表明,我们的模型要更好。
主要贡献有:
- 提出了使用双向self-attention网络,通过Cloze task来建模用户行为序列。据我们所知,这是首个在推荐系统中引入双向序列建模和Cloze objective的研究。
- 比较了该模型与state-of-the-art方法
- 分析了在提出模型中的关键构成
2.相关工作
回顾下相关工作。
2.1 通用推荐
推荐系统的早期工作通常会使用CF,并基于它们的历史交互来建模用户偏好。在众多CF方法中,MF是最流行的方法,它会将users和items投影到一个共享的向量空间中,并通过两个向量间的内积来估计一个用户对该item的偏好。item-based的最邻近方法有[20,25,31,43]。他们会通过使用一个预计算好的i2i相似矩阵,结合它们历史交互上的items间的相似度,来估计一个用户在一个item上的偏好。
最近,深度学习已经重构了推荐系统。早期的工作是两层的RBM CF。
基于深度学习的另一条线是,通过集成辅助信息(比如:文本[23,53]、图片[21,55]、音频特征[51])到CF模型中来学习item的表示来提升推荐效果。另一条线是,替代常用的MF。例如,NCF会通过MLP替代内积来估计用户偏好,而AutoRec和CDAE则使用auto-encoder框架来预测用户评分。
2.2 序列化推荐
不幸的是,上述方法中没有一个是用于序列化推荐(sequential recommendation)的,因为他们会忽略用户行为中的顺序。
在序列化推荐中的早期工作,通常会使用MC(markovchains)来捕获用户历史交互。例如,Shani[45]将推荐生成公式化为一个序列优化问题,并采用MDP(Markov Decision Process)来求解它。之后,Rendle结合MC和MF通过FPMC来建模序列化行为和兴趣。除了一阶MC外,更高阶的MC也可以适用于更多之前的items。
最近,RNN和它的变种,Gated Recurrent Unit(GRU)[4]和LSTM(LSTM)在建模用户行为序列上变得越来越流行。这些方法的基本思想是,使用多种recurrent架构和loss function,将用户之前的记录编码成一个vector(例如:用户偏好的表示,可用于预测),包含:GRU4Rec、DREAM、user-based GRU、attention-based GRU(NARM))、improved GRU4Rec(BPR-max/Top1-max),以及一个有提升的抽样策略[14]。
与RNN不同,许多深度模型也被引入进序列化推荐中。例如,Tang[49]提出了一个卷积序列网络(Caser)来学习序列模式,它同时使用水平和垂直卷积filters。Chen[3]和Huang[19]采用Memory Network来提升序列化推荐。STAMP使用一个带attention的MLP来捕获用户的通用兴趣和当前兴趣。
2.3 Attention机制
Attention机制在建模序列化数据(例如:机器翻译、文本分类)中展示了令人满意的潜能。最近,一些工作尝试采用attention机制来提升推荐效果和可解释性[28,33]。例如,Li[28]将attention机制引入到GRU中来捕获用户序列行为以及在session-based推荐中的主要目的。
上述提到的工作基本上将attention机制看成是对于原始模型的一种额外的组件。作为对比,Transformer[52]和BERT[6]在multi-head self-attention上单独构建,并在文本序列建模中达到了state-of-the-art的效果。最近,对于在建模序列化数据中使用纯attention-based网络有上升的趋势。对于序列化推荐来说,Kang[22]引入了一个二层的Transformer decoder(例如:Transformer语言模型)称为SASRec来捕获用户的序列化行为,并在公开数据集上达到了state-of-the-art的效果。SASRec与我们的工作紧密相关。然而,它仍是一个单向模型,并使用了一个非正式的(casual) attention mask。而我们使用Cloze task以及一个双向模型来编码用户的行为序列。
3.BERT4Rec
我们首先引下研究问题、基本概念。
3.1 问题声明
在序列化推荐中,假设:
- \(U=\lbrace u_1, u_2, \cdots, u_{\mid U \mid}\rbrace\) :表示一个用户集合
- \(V=\lbrace v_1, v_2, \cdots, v_{\mid V \mid}\rbrace\)表示一个items集合
- \(S_u=[v_1^{(u)}, \cdots, v_5^{(u)}, \cdots, v_{n_u}^{(u)}]\):表示对于用户\(u \in U\)按时间顺序的交互序列,其中\(v_t^{(u)} \in V\)是用户u在timestep t上交互的item,\(n_u\)是用户u交互序列的长度。
给定交互历史\(S_u\),序列化推荐的目标是预测:用户u在timestep \(n_u + 1\)的交互的item。它可以公式化为,为用户u在timestep \(n_u + 1\)上建模所有可能items的概率:
\[p(v_{n_u + 1}^{(u)} = v | S_u)\]3.2 模型结构
这里,我们引入了一个新的序列化推荐模型,称为BERT4Rec,它采用Transformer中的双向编码表示到一个新任务(sequential Recommendation)中。它在流行的self-attention layer上构建,称为“Transformer layer”。
如图1b所示,BERT4Rec通过L个双向Transformer layers进行stack组成。每个layer上,它会通过使用Transformer layer并行地跨之前层的所有positions交换信息,来迭代式地修正每个position的表示。通过如图1d的方式,以step-by-step的RNN-based的方式来前向传播相关信息进行学习,self-attention机制会赋予BERT4Rec直接捕获任意距离间的依赖。该机制会产生一个全局的receptive field,而CNN-based方法(比如:Caser)通常有一个受限的receptive field。另外,对比RNN-based方法,self-attention更容易并行化。
对比图1b, 1c, 1d,大多数显著的不同之处是,SASRec和RNN-based方法都是从左到右的单向结构,而BERT4Rec使用双向self-attention来建模用户的行为序列。这种方式下,我们提出的模型可以获取关于用户行为序列的更强大表示,来提升推荐效果。
3.3 Transformer Layer
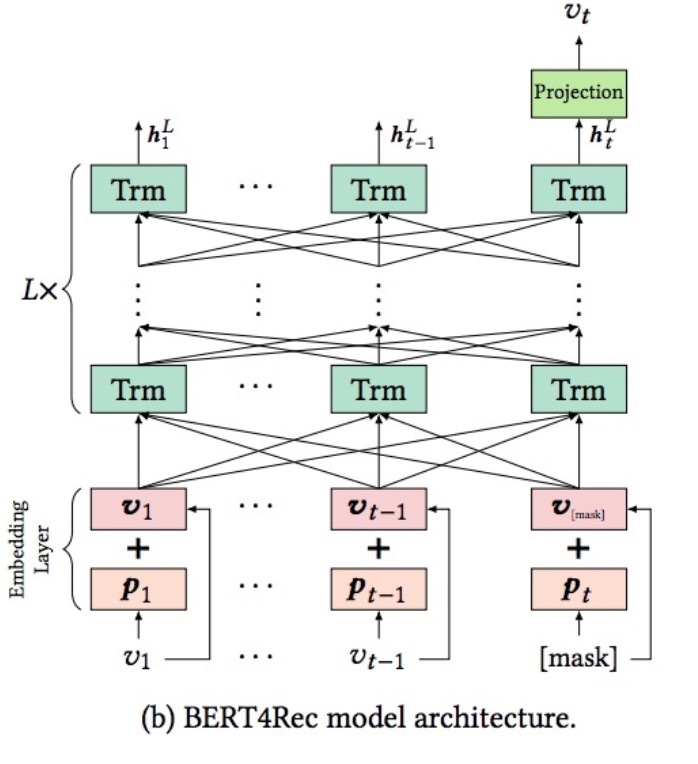
如图1b所示,给定一个长度为t的输入序列,我们在每一层l的每个position i上同时使用transformer layer来迭代式地计算隐表示\(h_i^l\)。这里,我们将\(h_i^l \in R^d\)进行stack在一起来形成一个矩阵(matrix) \(H^l \in R^{t \times d}\),因为我们会在实际上同时计算所有positions的attention function。如图1a所示,Transformer layer Trm包含了两个sub-layers:一个Multi-head self-attention sub-layer以及一个position-wise feed-forward network。
Multi-Head self-Attention. Attention机制在许多任务中变为序列建模的一部分,它可以捕获在representation pairs间的依赖,无需关注序列中的距离。之前的工作表明,在不同positions上的不同表征子空间上的信息进于jointly attend是有用的[6,29,52]。因而,我们可以采用multi-head self-attention来替代执行单一的attention函数。特别的,multi-head attention会首先使用不同的、可学习的线性投影,将\(H^l\)线性投影到h个子空间(subspaces)上,接着以并行的方式使用h个attention functions来生成output表示,它们可以进行拼接,然后进行再次投影:
\[MH(H^l) = [head_1; head_2; \cdots; head_h] W^O \\ head_i = Attention(H^l W_i^Q, H^l W_i^K, H^l W_i^V)\]…(1)
其中,每个head的投影矩阵是可学习的参数。
- \[W_i^Q \in R^{d \times d / h}\]
- \[W_i^K \in R^{d \times d /h}\]
- \[W_i^V \in R^{d \times d /h}\]
- \[W_i^O \in R^{d \times d}\]
这里,出于简洁性,我们忽略掉layer上标l。实际上,这些投影参数并不是跨网络共享的。这里,Attention函数是scaled dot-product attention:
\[Attention(Q,K,V) = softmax(\frac{QK^T}{\sqrt{d/h}}) V\]…(2)
这里,query Q, key K 和value V使用等式(1)中不同学到的投影矩阵从相同的矩阵\(H^l\)进行投影。 temperature \(\sqrt{d/h}\)被引入用来生成一个softer attention分布,以避免极小的梯度。
Position-wise feed-forward网络。
如上所述,self-attention sub-layer主要基于线性投影。为了使该模型具有非线性以及不同维度间的交叉,我们在self-attention sub-layer的outputs上使用一个Position-wise Feed-forward network,每个position独立且相同。它包含了两个仿射变换(affine transformations),两者间具有一个GELU activation(Gaussian Error Linear Unit):
\[PFFN(H^l) = [FFN(h_1^l)^T; \cdots; FFN(h_t^l)^T]^T \\ FFN(x) = GELU(xW^{(1)} + b^{(1)}) W^{(2)} + b^{(2)} \\ GELU(x) = x \phi(x)\]…(3)
其中:
- \(\phi(x)\)是标准gaussian分布的累积分布函数,
- \(W^{(1)} \in R^{d\times 4d}, W^{(2)} \in R^{4d\times d}, b^{(1)} \in R^{4d}, b^{(2)} \in R^d\)是可学习参数,并且跨所有positions共享
出于便利我们忽略layer上标l。事实上,这些参数在layer与layer间是不同的。在本工作中,根据OpenAI GPT和BERT,我们使用一个更平滑的GELU activation而非标准的ReLU activation。
Stacking Transformer layer
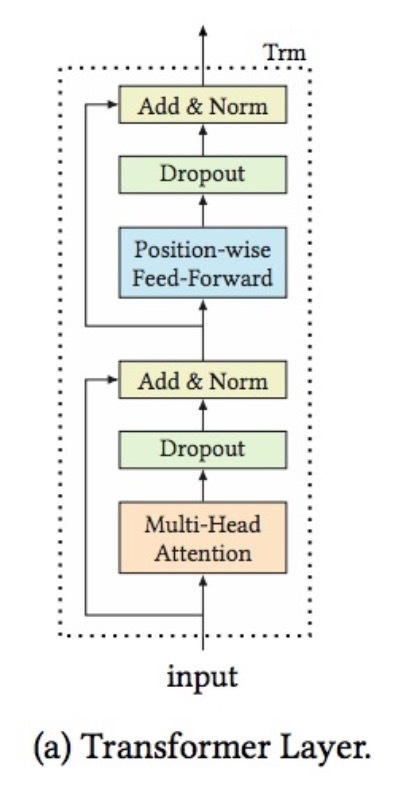
如上所述,我们可以使用self-attention机制,来很轻易地捕获跨整个行为序列的item-item交叉。然而,通过将self-attention layers进行stacking来学习更复杂的item transition patterns是有利的。然而,该网络会随着更深而变得更难训练。因此,我们两个sublayers的每一个周围都采用一个residual连接,如图1a所示,并使用layer normalization。另外,在它们被normalized后,我们会在每个sub-layer的output上采用dropout[47]。也就是说,每个sub-layer的output是:\(LN(x + Dropout(sublayer(x)))\),其中:\(sublayer(\cdot)\)是通过sublayer自身实现的函数,LN是由[1]定义的layer normalization function。我们会使用LN来在相同layer上的所有hidden units上归一化inputs,以便加速网络训练。
总之,BERT4Rec以如下形式重新定义了每个layer的hidden表示:
\[H^l = Trm(H^{l-1}), \forall i \in [1, \cdots, L] \\ Trm(H^{l-1}) = LN(A^{l-1} + Dropout(PFFN(A^{l-1})) \\ A^{l-1} = LN(H^{l-1} + Dropout(MH(H^{l-1})))\]3.4 Embedding Layer
所上所述,由于不使用任何recurrence或convolution模块,Transformer layer Trm不会意识到输入序列的顺序。为了利用输入的顺序信息,我们在Transformer layer stacks的底部,将position embeddings引入到input item embeddings中。对于一个给定的item \(v_i\),它的输入表示\(h_i^0\)通过对相应的item embedding和positinal embedding进行求和来构成:
\[h_i^0 = v_i + p_i\]其中,\(v_i \in E\)对于item \(v_i\)是第d维的embedding,\(p_i \in P\)是position index=i上的d维positional embedding。在本模型中,我们使用可学习的positional embeddings来替代确定的sinusoid embedding以提升更高的效果。positional embedding matrix \(P \in R^{N \times d}\)允许我们的模型来标识要处理哪一部分的input。然而,它也在最大句长N上做了限制。因而,我们需要将输入序列\([v_1, \cdots, v_t]\)截断取最近的N个items \([v_{t-N+1}^u, \cdots, v_t]\) (如果t>N)。
3.5 Output layer
在L layers后,会跨之前层上的所有positions来层次化交换信息,对于input序列的所有items,我们会获得最终的output \(H^L\)。假设我们将item \(v_t\)在timestep t上进行mask,我们接着基于图1b的\(h_t^L\)来预测masked items \(v_t\)。特别的,我们会应用一个两层的feed-forward网络,并使用GELU activation来生成一个在target items上的output分布:
\[P(v) = softmax(GELU(h_t^L W^P + b^P) E^T + b^O)\]…(7)
其中:
- \(W^P\)是可学习的投影矩阵
- \(b^P\)和\(b^O\)是bias项
- \(E \in R^{\mid V \mid \times d}\)是对于item set V的embedding矩阵
我们在input layer和output layer上使用共享的item embedding matrix来减缓overfitting并减小模型size。
3.6 模型学习
训练
常见的单向序列推荐模型通常通过为输入序列中的每个position预测next item的方式来进行训练(如图1c和1d)。特别的,input序列\([v_1, \cdots, v_t]\)的target是一个shfited版本 \([v_2, \cdots, v_{t+1}]\)。然而,如图1b所示,在双向模型中的left context和right context进行联合,可能会造成:每个item的最终output表示会包含target item的信息。这会使得预测将来项变得更平凡,网络不会学到任何有用的东西。对于该问题一种简单的解法是,从长度为t的原始行为序列中创建t-1个样本(带有next items的子序列,形如:\(([v_1],v_2)\)、\(([v_1,v_2],v_3)\)),接着使用双向模型将每个历史子序列进行encode,以预测target item。然而,该方法非常耗时、耗资源,因为我们必须为在序列中的每个position创建一个新样本并进行单独预测。
为了高效地训练我们的模型,我们使用了一个新的objective:\(Cloze ask\) [50](在[6]中被称为“Masked Language Model”)来序列推荐中。它是一种测试(test),由将某些词移除后的语言的一部分组成,其中参与者(participant)会被要求填充缺失的词(missing words)。在我们的case中,对于每个training step,我们对输入序列中的所有items的一部分\(\rho\)进行随机遮掩(randomly mask)(通过使用特殊token “[mask]”进行替代),接着只是基于它的left context和right context来预测masked items的原始ids。例如:
Input: \([v_1, v_2, v_3, v_4, v_5]\) —-> \([v_1, [mask]_1, v_3, [mask]_2, v_5]\)
labels: \([mask]_1 = v_2, [mask]_2 = v_4\)
对应于”[mask]”的最终的hidden vectors,会被feed给一个在item set上的output softmax,这与常规的序列推荐相同。事实上,我们会为每个masked input \(S_u'\)定义loss来作为关于该masked targets的负log似然:
\[L = \frac{1}{ |S_u^m|} \sum\limits_{v_m \in S_u^m} -log P(v_m = v_m^* | S_u')\]…(8)
其中,\(S_u'\)是用户行为历史\(S_u\)的masked版本,\(S_u^m\)是在它上的random masked items,\(v_m^*\)是masked item \(v_m\)的true item,概率\(P(\cdot)\)如等式(7)定义。
Cloze task的一个额外优点是,它可以生成更多样性来训练模型。假设一个长度为n的序列,如图1c和图1d所示的常规序列预测可以为训练生成n个唯一的样本,而BERT4Rec在多个epochs上可以获得\((_k^n)\)的样本(如果我们随机mask k个items)。它允许我们训练一个更强大的单向表示模型。
Test
如上所述,我们会在训练和最终序列推荐任务间不匹配(mismatch),因为Cloze objective是为了预测当前maskted items,而序列推荐的目标是预测the future。为了解决该问题,我们会在用户行为序列的结尾添加特殊token “[mask]”,接着,基于该token的最终hidden表示预测next item。为了更好匹配(match)序列推荐任务(例如:预测last item),我们也可以在训练期间生成只在输入序列中mask最后一个item的抽样。它与序列推荐的fine-tuning相似,可以进一步提升推荐效果。
3.7 讨论
这里,我们会讨论我们的模型与之前的工作的关系。
SASRec
很明显,SARRec是从左到右的单向版本的Bert4Rec,它使用单个head attention以及causal attention mask。不同的结构导至不同的训练方法。SASRec会为序列中的每个position预测next item,而Bert4Rec会使用Cloze objective预测序列中的masked items。
CBOW & SG
另一个非常相似的工作是CBOW(Continuous Bag-of-Words)和(SG)Skip-Gram。CBOW会使用在context(包含左和右)中的所有word vectors的平均来预测一个target word。它可以看成是一个简版的BERT4Rec:如果我们在BERT4Rec中使用一个self-attention layer,并在items上具有均匀的attention weights,不共享的item embeddings,移除positional embedding,并将中心项mask住。与CBOW相似,SG也可以看成是BERT4Rec的简版(mask所有items,除了它自身)。从该角度看,Cloze可以看成是CBOW和SG的objective的一个通用格式。另外,CBOW使用一个简单的aggregator来建模word序列,因为它的目标是学习好的word representations,而非sentence representations。作为对比,我们会寻找一个更强大的行为序列表示模型(deep self-attention network)来作出推荐。
BERT
尽管我们的BERT4Rec受NLP中BERT,它与BERT仍有许多不同之处:
- a) 大多数主要区别是,BERT4Rec是一个用于序列推荐的end-to-end模型,而BERT是一个用于句子表示的pre-training模型。BERT会利用大规模task-independent语料来为许多文本序列任务pre-train句子表示模型,因为这些任务会共享关于该语言的相同背景知识。然而,在推荐任务中不受该假设约束。这样,我们可以为不同的序列化推荐datasets训练BERT4Rec end-to-end。
- b) 不同于BERT,我们会移除next sentence loss和segment embeddings,因为BERT4Rec会建模一个用户的历史行为,只有在序列推荐中有一个序列
4.实验
评估了三个数据集:
- Amazon Beauty:Amazon.com收集的产品review数据集。
- Steam:从在线视频游戏发生商Steam中收集得到,
- MovieLens:MovieLens电影数据集