我们来看下youtube RNN: Alex Beutel等提出的《Latent Cross: Making Use of Context in Recurrent Recommender Systems》。
1.介绍
对一个推荐(recommendation)的上下文(context)进行建模很重要,上下文包括:正搜索一个想看的视频的该用户、当前时间(the time of day)、位置(location)、用户设备等。在因子分解setting中提出了许多模型,比如:对位置进行张量分解[17]、对不同类型的用户动作进行(unfolding tensors)[46]、或者对时间进行人工特征工程。
随着深度学习的进展,在神经网络推荐系统(neural recommender systems)中,如何合并这些context feature很少直接被研究。之前在DNN推荐系统上的工作,就大量依赖将上下文建模成直接特征,或者具有一个多任务目标(multi-task objective)[11],一个值得注意的例外是,利用RNN来建模时序模式(temporal patterns)【25,39,43】。在本paper中,我们会借鉴contextual CF文献和神经网络推荐系统文献。我们会探索在深度神经推荐系统中(特别是RNN模型中)如何利用context数据,并展示了流行的技术。
我们探索了在youtube RNN-based推荐系统中,利用context数据的能力。大多数生产环境中,我们具有大量重要的context数据:请求时间、观看时间、设备类型、网页端还是移动app端。在本paper中,首先,我们从理论上解释对将上下文建模成直接特征的限制,特别是使用前馈神经网络时(做为示例baseline: DNN)。我们接着提供了一种很容易使用的技术,在一个更复杂的RNN模型上合并这些特征,来产生对预测accuracy上的提升。
我们的贡献有:
- 一阶挑战(first-order):我们展示了一阶神经网络来建模低秩关系的挑战
- 产品模型(Production Model):我们描述了在youtube中如何来构建一个大规模的RNN推荐系统。
- Latent Cross: 我们提供了一个简单技术,称为:“Latent Cross”,来在我们的模型上以更有表达力的方式来包含context特征。特别的,latent cross会在context embedding和神经网络的hidden states间执行一个element-wise product。
- 经验结果:我们提供了经验结果来验证在推荐accuracy上的提升。
2.相关工作
我们做了许多相关研究的调查。见表1.

表1: 有关的推荐系统的关系:
上下文推荐(Contextual Recommendation):大量研究集中于在推荐期间使用上下文数据。特别的,特定类型的上下文数据已经深入进行探索,其它类型都还比较抽象。例如,推荐中的时序动态性(temporal dynamics)已经被广泛探索[6]。在Netflix Price期间,Koren[29]在netflix数据集上发现了大量长范围的时序动态性(long-ranging temporal dynamics),并添加了时序特征到它的CF模型中以提升效果。研究者们也探索过在短时范围内(例如:session)的偏好是如何演进的【39】。更多通用的抽象已经被用于建模推荐的偏好演进,例如:点进程(point processes)[15]和RNN网络【43】。相似的,建模用户动作与人口属性数据也在概率模型、MF(矩阵分解)、TF(张量分解)、中被广泛探索,许多方法在MF和TF上构建了交叉学习(cross-domain)。像FM等方法[34]和其它上下文推荐[22,37,48]已经提供了这些CF方法的泛化。
神经推荐系统:随着NN的流行,推荐系统研究者开始应用DNN到推荐中。早期的迭代主要关注将CF的思想应用的神经网络中,比如:auto-encoder[36]或者 joint deep&CF模型[20]。另外也设计了更复杂的网络来合并更多类型的输入特征[11]。Cheng [7]在DNN模型外,通过一个线性模型来处理上下文的特征交叉。
最近使用RNN的推荐系统多了许多[21,25,39,43]。其中,[25,43]包含了时序信息作为特征,并在它们的模型中进行管理,[41]包含了通用的上下文特征。然而,在这些case中,这些特征都与输入进行拼接(concatenated),我们在后面会展示这样做的限制。[49]改进了LSTMs,通过用乘法来合并时序信息,但不能将它们泛化到其它上下文数据上。
二阶神经网络:本paper的一个主要点是,乘积关系(multiplicative relations)在神经推荐的重要性。这些二阶单元在神经网络中的许多地方出现。recurrent units(例如:LSTMs和GRUs)是通用的使用gating机制的二阶units,会使用element-wise乘法。更复杂的教程可以在[18]中找到。
另外,网络顶部用于分类的softmax layers是显式的bi-linear layers,它位于DNN产生的embedding与label classes的embeddings之间。该技术在多篇paper上被提及,包含DNN顶部的:user-item bi-linear layers[20,41,43,47]。
与本paper中描述的技术相似的是,乘法模型[27,44]。这些乘法结构大多数在NLP中被使用[14,27]。该NLP方法被应用于个性化建模中[40](使用一个有些不同的数学结构)。最近, [25]提出的乘法技术,不仅用在上下文数据上,也直接用在用户层面上,它与TF方法相似。PNN[33]和NFM[19]将该思想放在了在输入侧采用将所有特征对进行乘积,接着对结果拼接(concatenating)或者平均(averageing),然后传给一个前馈网络。这些模型的思想与我们类似,但区别是:我们更关注在上下文数据和用户动作间的关系,我们的latent crossing机制可以在整个模型中使用,我们演示了在一个RNN推荐系统中这些交叉的重要性。
更复杂的模型结构例如attention模型[3],记忆网络(memory networks)[38],元学习(meta-learning)[42]也依赖于二阶关系,正变得流行。例如:attention模型利用attention vectors来构建hidden states和一个乘法。然而,这些方法结构上更复杂,很难进行训练。相反的,latent cross技术很容易训练,在实践中很有效。
3.Preliminaries
假设,一个推荐系统有一个数据库 \(\varepsilon\):它由事件e(events)构成,而e则由许多k元组(k-way tuples)组成。\(e_l\)表示tuple中的第l个值,\(e_{\bar{l}}\)表示在tuple中其它k-1个值。

表2:
例如,Netflix Prize setting中,使用三元组tuples \(e \equiv (i,j,R)\),表示用户i对电影j有个评分R。我们可以在此基础上加上context信息(比如:时间和设备):\(e \equiv (i,j,t,d)\),表示用户i观看了视频j,在时间点t设备类型d上。注意,每个值即可以是离散化的类别型变量(比如在其中有N个用户,其中\(i \in I\)),也可以是连续型(比如:t是一个unix timestamp) 。连续型变量在预处理阶段被离散化很常见,比如:将t转换成event发生的天数。
有了该数据,我们可以构建推荐系统:在给定event的其它值时,预测event的一个值。例如:Netflix Prize说,一个tuple \(e=(i,j,R)\),它使用(i,j)来预测R。从机器学习的角度,我们可以将我们的tuple e分割成特征x和label y,比如:\(x=(i,j)\)和label y=R。
我们可以进一步对推荐问题进行重设计(reframe):预测在某个给定时间点,一个用户会观看哪个视频;定义了\(x=(i,t)\)以及\(y=j\)。注意,如果label是类别型随机值(比如:视频ID),可以将它看成是一个分类问题;如果label是真实值(比如:rating),可以将它看成是一个回归问题。
在因子分解模型中,所有输入值被认为是离散的,接着被嵌入、然后进行乘积。当我们“嵌入”一个离散值时,我们就学到了一个dense latent表示,例如:用户i通过dense latent vector \(u_i\)进行描述,item j通过dense latent vector \(v_j\)进行描述。在矩阵分解模型中,预测总是基于内积\(u_i \cdot v_j\)。在张量分解(TF:tensor factorization)模型中,预测基于\(\sum\limits_r u_{i,r} v_{j,r} w_{t,r}\),其中\(w_t\)是一个关于时间或其它上下文信息的dense vector embedding。FM[34]是这些类型模型的一个简洁抽象。出于简洁性,我们将\(\langle \cdot \rangle\)看成是一个多维的内积,例如:\(\langle u_i, v_j, w_t \rangle = \sum\limits_r u_{i,r} v_{j,r} w_{t,r}\)。
神经网络通常也会嵌入离散输入。也就是说,给定一个输入\((i,j)\),网络的输入可以是\(x=[u_i;v_j]\),其中\(u_i\)和\(v_j\)被拼接到一起,参数是可训练的(通过BP)。因而,我们将NN的形式定义为:\(e_l=f(e_{\bar{l}})\),其中,该网络会采用tuple的所有值、而非一个值来当成输入,接着我们训练f来预测tuple的最后一个值。后续我们会将该定义展开,以允许模型来采用相关的之前事件来作为该网络的输入,正如在序列模型中一样。
4.一阶挑战
为了理解神经推荐系统是如何利用拼接特征(concatenated features)的,我们研究了一些典型的网络构建块。如上所述,神经网络(特别是前馈DNNs),通常会在一阶操作(first-order op)上构建。更准确的说,神经网络通常依赖于矩阵向量乘法(\(Wh\)),其中:W是一个通过学习得到的权重矩阵,h是一个input(可以是一个网络的input,也可以是前一layer的output)。在前馈网络中,FC layers可以以这种形式描述:
\[h_{\tau} = g(W_{\tau} h_{(\tau-1)} + b_{\tau})\]…(1)
其中,g是一个element-wise操作(比如:一个sigmoid或ReLU),\(h_{(\tau-1)}\)是前一层的output,而\(W_{\tau}\)和\(b_{r}\)是要学的参数。我们将它认为是一个在\(h_{(\tau-1)}\)上的一阶单元(first-order cell),\(h_{(\tau-1)}\)是一个k维向量,不同的值会基于W的权重一起求和,而非相乘。
尽管神经网络可以使用多个layers来逼近任意函数,它们的核心计算与过去的CF的思想在结构上有很大不同。矩阵分解模型会采用通用形式\(u_i \cdot v_j\),从不同类型的输入(users, items, time)产生模型学习低秩关系。这样的低秩模型在推荐系统中已经很成功,我们会问以下问题:使用一阶单元的神经网络如何去建模低秩关系?
4.1 建模低秩关系
为了测试一阶神经网络能否建模低秩关系,我们可以生成人工合成的低秩数据,并研究不同size的神经网络是如何拟合数据的。确切的说,我们可以考虑一个m-mode的tensor(相当于:m元组),其中它的每个维度(比如:元组i)都是size N。对于\(mN\)个离散特征,我们会使用下面的简单等式来生成长度为r的随机向量\(u_i\):
\[u_i \sim \mathcal{N}(0, \frac{1}{r^{(1/2m)}} I)\]…(2)
最后产生的结果数据(\(u_i\))是一个近似相同规格(它的均值为0, 经验方差接近为1)的rank为r的matrix或者tensor。例如,对于m=3,我们可以使用多个这些生成的embeddings(即:生成的matrix或tensor)来表示形式为(i, j, t, \(\langle u_i, u_j, u_t \rangle\))的events。
我们使用该数据来尝试拟合不同size的模型。特别的,我们会考虑这样一个模型:它使用离散特征进行嵌入同时拼接(concatenated)在一起做为输入。该模型只有一个hidden layer,它使用ReLU activation,接着跟最后一个线性层。该模型使用tensorflow编写,使用MSE训练,并使用Adagrad optimizer训练直到收敛。我们在训练数据和模型预测间使用Pearson correlation(R)来衡量并上报了模型的accuracy。我们使用Pearson相关系数,以便在数据的方差上有细微的不同可以认为是不变的。我们在训练数据中上报了accuracy,因为我们会测试这些模型结构对于拟合低秩模式的好坏程度(例如:是否可以从它进行泛化)。
为了建模低秩关系,我们希望看到,模型逼近单个乘法(它可以表示变量之间的交叉)的好坏程度。所有数据均使用N=100生成。对于m=2,我们会检查为让两标量(scalar)相乘hidden layer需要的大小;对于m=3,我们会检查为让三个标量相乘hidden layer需要的大小。我们会使用\(r \in \lbrace 1,2 \rbrace\)来观察,模型size随所需乘法数是如何增长。我们将每个离散特征作为一个20维向量进行嵌入,它比r大很多(但我们发现:模型的accuracy会与该size独立)。我们测试了hidden layers数目 \(\in \lbrace 1,2,5,10,20,30,50 \rbrace\)。
经验查找(Empirical Findings)。如表3和图2所示,我们发现,该模型会随着hidden layer的size增长,连续逼近数据。直觉上该网络正逼近乘法,一个更宽网络应给出一个更好的近似。第二,我们观察到,随着rank r从1增加到2,hidden layer size近似二倍可以达到相同的accuracy。这与我们的直觉很相近,随着r的增加,意味着增加了更多交叉。
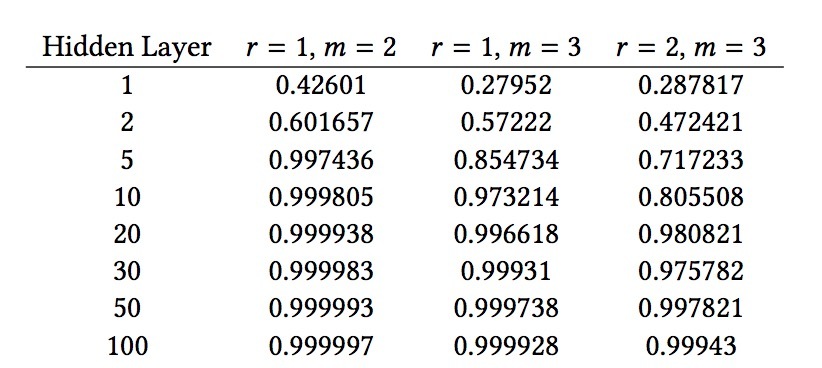
表3:
更有趣的是,我们发现,对于r=1和m=2, 它会采用一个hidden layer size=5来获得一个“较高”的accuracy估计。考虑到CF模型通常会发现rank 200关系[28],这直觉上建议,对于单个two-way关系的学习,真实世界模型需要非常宽的layers。
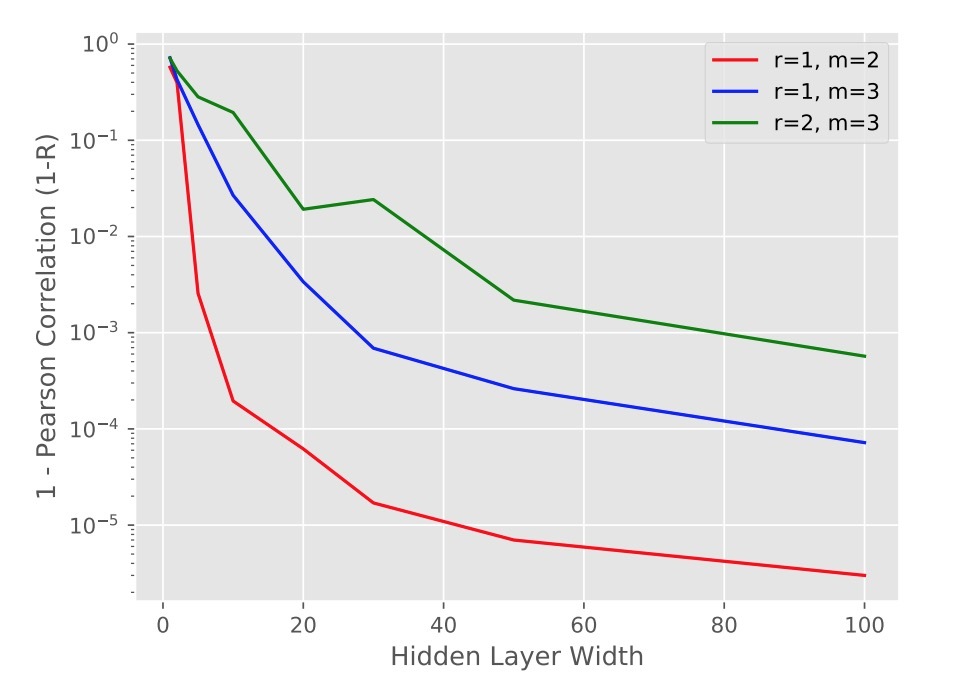
图2
另外,我们发现建模超过2-way的关系会增加逼近这种关系的难度。也就是说,当我们从m=2到m=3时,我们会发现该模型会需要一个宽度为5的hidden layer到一个宽度为20的hidden layer,来获取MSE=0.005或Pearson相关度=0.99.
总之,我们观察到ReLU layers可以逼近乘法交叉,但这样做还相当不够。这会激发模型的需求:是否可以更轻易来表达和处理乘法关系。我们将我们的关注点转向使用一个RNN做为baseline;它是一个更强的baseline,对比前馈DNN,它可以更好地表示乘法关系。
5.youtube RNN推荐
有了上述分析,我们描述了在Youtube RNN推荐上的提升。RNN看成是一个baseline模型,因为他们已经是二阶神经网络,比一阶模型要复杂很多。
我们会做个介绍,并在第6节描述如何利用上下文数据进行提升。
5.1 公式描述
在我们的setting中,我们会观察:user i已经观看了video j(该视频由user \(\phi(j)\)上传)的events,在时间t时(我们后续会引入额外的上下文特征)。为了建模用户偏好和行为的演进,我们使用一个RNN模型,其中模型的输入是:
- \(X_i=\lbrace e=(i,j,\phi(j),t) \in \epsilon \mid e_0 = i \rbrace\):它表示用户的events集合。
我们使用\(X_{i,t}\)来表示用户\(X_i\)在在时间t之前的所有观看
\[X_{i,t} = \lbrace e = (i,j,t) \in \epsilon | e_0 = i \wedge e_3 < t \rbrace \subset X_i\]…(3)
该训练模型的目标是为了生成顺序预测概率 \(Pr(j \mid i,t,X_{i,t})\),即:user i根据给定时间t之前所有观看行为,会观看的video j。出于简洁性,我们会使用:
- \(e^{(\tau)}\)来表示在序列中的第\(\tau\)个事件,
- \(x^{(\tau)}\)用来表示对于\(e^{(\tau)}\)的转移输入,
- \(y^{(\tau)}\)表示尝试对第\(\tau\)个event所预测的label。
在上述示例中,如果:
- \[e^{(\tau)} = (i,j,\phi(j),t)\]
- \[e^{(\tau+1)} = (i,j',\phi(j'),t')\]
那么输入\(x^{(\tau)} = [v_j; u_{\phi(j)}; w_t]\),它被用于预测\(y^{(\tau+1)} = j'\),
其中:
- \(v_j\)是视频embedding
- \(u_{\phi(j)}\)是上传者embedding
- \(w_t\)是上下文embedding
当预测\(y^{\tau}\)时,我们当然不能使用对应event \(e^{(\tau)}\)的label作为输入,但我们可以使用\(e^{(\tau)}\)的上下文,它可以通过\(c^{(\tau)}\)来表示。例如:\(c^{(\tau)} = [w_t]\)。
5.2 Baseline RNN的结构
我们的RNN模型图如图1所示。RNN网络会建模一个动作序列。对于每个event \(e^{(\tau)}\),该模型会采用一个step forward,处理\(x^{(\tau)}\)并更新一个hidden state vector \(z^{(\tau-1)}\)。为了更精准,每个event首先会通过一个神经网络\(h_0^{(\tau)} = f_i(x^{(\tau)})\)。在我们的setting中,这将会是一个identity函数或者fully-connected ReLU layers。
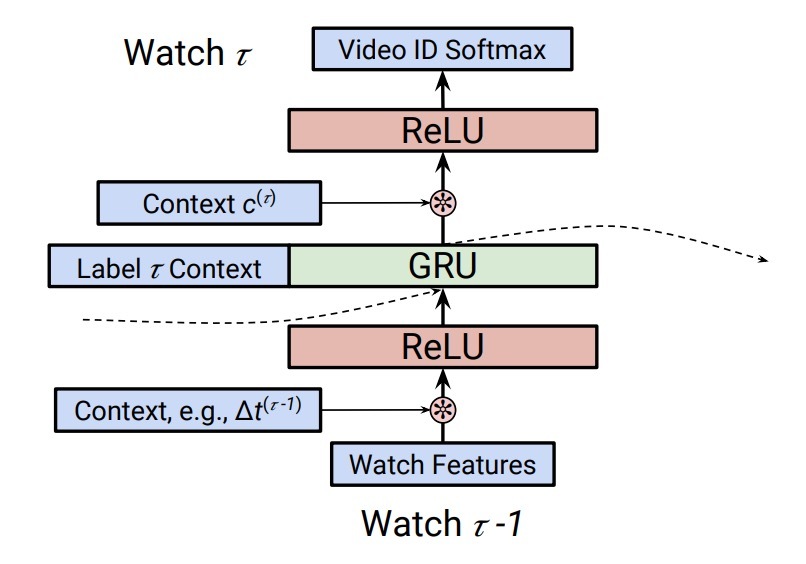
图1:
该网络的recurrent部分是一个函数\(h_1^{(\tau)}\),\(z^{(\tau)} = f_r(h_0^{(\tau)}, z^{(\tau-1)})\)。也就是说,我们会使用一个recurrent cell,比如一个LSTM或GRU,它会采用state。
为了预测\(y^{(\tau)}\),我们使用\(f_o(h_1^{(\tau-1)}, c^{(\tau)})\),它是另一个可训练的神经网络可以产生在可能值\(y^{\tau}\)上的一个概率分布。在我们的setting中,该网络会采用RNN的output作为它的输入以及将来预测的上下文,最后会以一个在所有视频上的softmax layer做为结尾。该网络可以包含多个FC layers。
5.3 上下文特征
该模型成功的核心是,除了视频观看序列之外,会合并上下文特征。我们会讨论如何使用这些特征。
TimeDelta。在我们的系统中,有效对时间进行合并,对于RNN的accuracy很重要。历史上,时间上下文已经以多种方法合并给CF模型中。这里我们使用一种称为timedelta的方法:
\[\Delta t^{(\tau)} = log( t^{(\tau+1)} - t^{(\tau)})\]…(4)
也就是说,当事件\(e^{(\tau)}\)发生时,到下一事件时或者到做出预测时有多久。这与[25]和[49]中对时间表示大致相同。
软件客户端:youtube视频会在多种设备上进行观看:在浏览器端、IOS、Android、Roku、chromecast,等等。将这些上下文看成是等价缺失的相关关联。例如,用户在手机端完整观看一个电影的可能性要比在一个Roku设备上更低。相似的,像trailers这样的短视频更可能在手机端观看。对软件客户端建模,特别是它是如何与观看决策相交互的,十分重要。
页面(Page)。我们也会记录一个观看初始来自于系统的哪个地方。例如,我们会区分是来自主页的观看(例如:home page watches),还是来自用户观看了一个视频后由推荐带来的观看(例如:Watch Next Watches)。这很重要,因为来自主页的观看可能对新内容更开放,而从一个之前观看后接着观看很可能归因于用户想对一个主题更深入。
Pre-Fusion和Post-Fusion。我们可以使用这些上下文特征,可以称为\(c^{(\tau)}\),以两种方式作为直接输入。如图1所示,我们可以将context当成是在该网络底部的一个输入,或者与RNN cell的output进行拼接。我们将在RNN之前的context features包含机制称为“pre-fusion”,在RNN cell之后的context features包含机制称为“post-fusion”[12]。尽管很微妙,该决策对RNN的影响很大。尤其是,通过将pre-fusion中包含一个feature,该feature会在修改RNN的state期间影响预测。然而,通过在post-fusion期间包含一个特征,该特征可以更直接的影响在该step上的预测。
为了管理这个问题,当预测\(y^{(\tau)}\)时,我们通常会使用\(c^{(\tau)}\)作为一个post-fusion特征,并使用\(c^{(\tau-1)}\)作为一个pre-fusion特征。这意味着,\(c^{(\tau-1)}\)会影响RNN state,而\(c^{(\tau)}\)会用于预测\(y^{(\tau)}\)。接着,在下一step,当预测\(y^{(\tau-1)}\)时,\(c^{(\tau)}\)会是一个pre-fusion特征,它会从该time forward上影响RNN的state。
5.4 实现&训练
我们的模型在tensorflow上实现,并在多个分布式workers和parameter servers上进行训练。训练过程会使用提供的BP mini-batch SGD算法,或者Adagrad、ADAM。在训练期间,我们会使用:在\((t_0 - 7days, t_0]\)期间,监控最近100个观看行为,其中\(t_0\)是训练时间。这会对最近观看行为区分次序,因为:当学到的模型应用于线上流量时,该行为与预测任务更相似。
由于存在大量视频,我们会限定要预测的可能视频集合、以及所建模的这些视频的上传者数目。在以下实验中,这些集合的size范围从50w到200w。softmax layer,会覆盖候选视频的所有集合,在每个batch上可以使用sampled softmax使用2w个负例进行训练。我们会使用该sampled softmax在cross entropy loss上进行预测。
6.使用latent cross进行上下文建模
我们的baseline模型的描述已经很清楚了,使用上下文特征通常作为拼接输入到简单的FC layers中。然而,正如第4节所述,神经网络在对拼接输入特征间的交叉建模效率很低。这里我们提出了一种可选方案。
6.1 单个Feature
我们以单个context feature的一个示例开始。我们将使用时间作为一个示例版的context feature。我们不会将特征合并成另一个输入与其它相关特征进行拼接,我们会在网络中执行一个element-wise product。也就是说,我们会执行:
\[h_0^{(\tau)} = (1+w_t) * h_0^{(\tau)}\]…(5)
其中,我们通过一个零均值的Gaussian分布对\(w_t\)进行初始化(注意:w = 0 是一个单位矩阵identity)。这可以被解释成:上下文在hidden state上提供了一个掩码(mask)或attention机制。然而,它也可以允许在输入选前watch和时间(time)间的低秩关系。注意,我们可以在RNN之后应用该操作:
\[h_1^{(\tau)} = (1+w_t) * h_1^{(\tau)}\]…(6)
在[27]中提供的技术可以被看成是一种特殊case,其中乘法关系会在网络的高层(沿着softmax function)上被包含,来提升NLP任务。在这种情况下,该操作被认为是TF,其中一个modality对应的embedding由一个神经网络产生。
6.2 使用多种Features
在许多case中,我们会希望包含多个contextual feature。当包含多个contextual features时(比如:time t和device d),我们会执行:
\[h^{(\tau)} = (1+w_t + w_d) * h^{(\tau)}\]…(7)
我们使用该公式出于以下几个原因:
- (1) 通过使用0均值高斯分布对\(w_t\)和\(w_d\)进行初始化,乘法项具有均值为1, 这样可以在hidden state上扮演着mask/attention机制
- (2) 通过一起添加这些项,我们可以捕获在hidden state和每个context feature间的2-way关系。这会遵循FM的设计。
- (3) 使用一个简单的加法函数很容易训练。
一个像\(w_t * w_d * h^{(\tau)}\)这样的更复杂函数,使用每个额外的contextual feature将可以极大地增加非凸性。相似的,我们可以很难通过训练来学习一个函数(\(f([w_t;w_d])\)),可能会得到更差的结果。包含这些特征的总览可以见图1.
效率(efficiency):使用latent crosses的一个很大好处是,它的简洁性和计算效率。有了N个context features和d维的embeddings,latent cross可以以O(Nd)的复杂度被计算,不需要增加后续layers的宽度。
7.实验
7.1 比较分析
…
7.2 Youtube模型
第二,我们研究了生产模型的多个变种。
7.2.1 setup
这里我们使用用户观看行为的一个产品数据库,它比上述的setting要不严格些。我们的序列由被看过的视频、该视频的上传者组成。我们使用了一个更大的(百万级)的词汇表,它包含了最近流行的上传视频与上传者。
我们基于users和time,将数据集分成一个训练集和一个测试集。首先,我们将用户分割成两个集合:在训练集中90%的用户,测试集10%。第二,为了通过时间进行split,我们选择了一个时间cut-off \(t_0\)以及在训练期间只考虑在\(t_0\)之前的观看。在测试期间,我们会考虑\(t_0+4\)小时后的观看行为。相似的,视频的词汇表基于在\(t_0\)之前的数据。
我们的模型由embedding和对所有features进行拼接作为输入组成,接着跟一个256维的ReLU layer,一个256维的GRU cell,接另一个256维ReLU layer,接着feed给softmax layer。如前所述,我们使用在\((t_0 -7, t_0]\)期间的100个最近观看行为作为观察。这里,我们使用Adagrad优化器在多个workers和parameter servers上进行训练。
为了测试我们的模型,我们接着会measure MAP@k(mean-average-precision-at-k)。对于不在我们的词汇表中的观看行为,我们总是会将该预测标记为incorrect。MAP@k的评估分可以使用近似45000个观看来measure。
7.2.2 PV作为context
我们开始分析通过以不同方式合并Page带来的accuracy提升。特别的,我们比较了不使用Page,使用Page作为输入与其它输入进行拼接,并执行一个post-fusion latent cross With Page。(注意,当我们将page作为一个拼接特征包含进去后,在pre-fusion和post-fusion期间它都是拼接的)
如图3所示,使用Page与一个latent cross提供了最好的accuracy。别外,我们看到,使用latent cross和拼接输入在accuracy上不会提供额外提升,建议latent cross足够捕获相关信息,它可以通过使用该特征做为一个直接输入进行捕获。
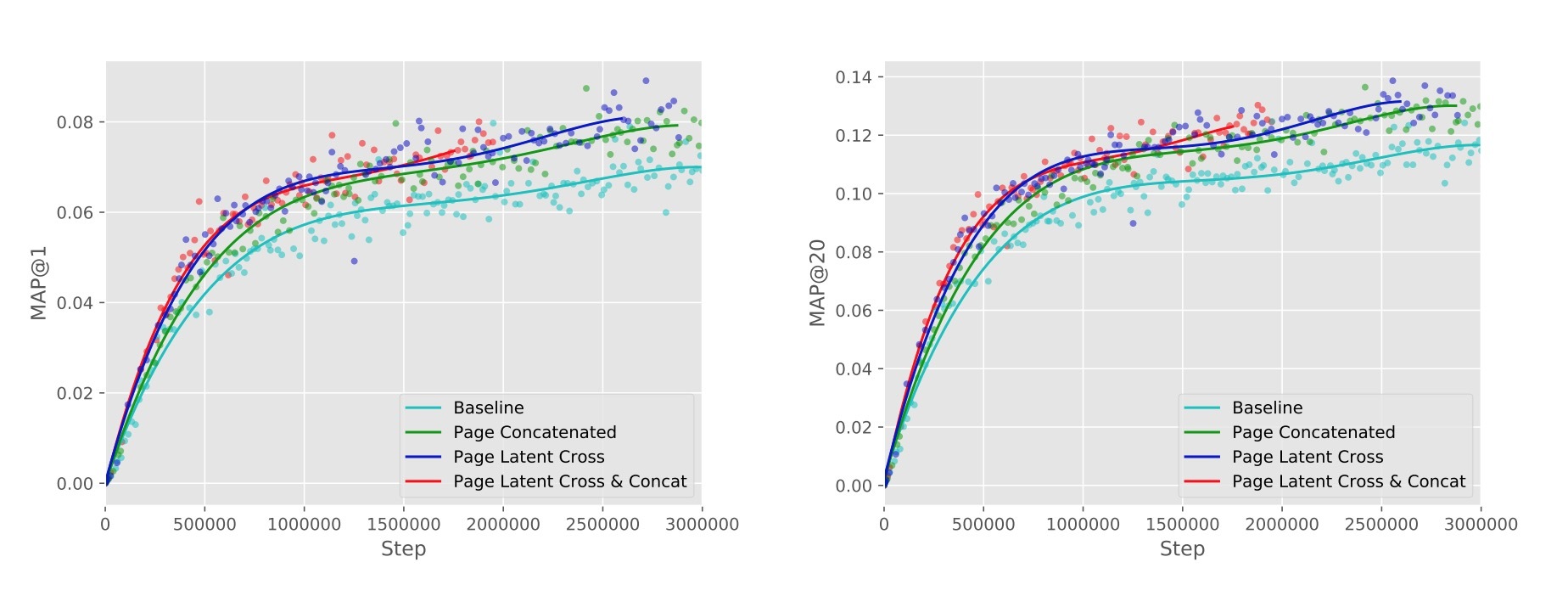
图3
7.2.3 总提升
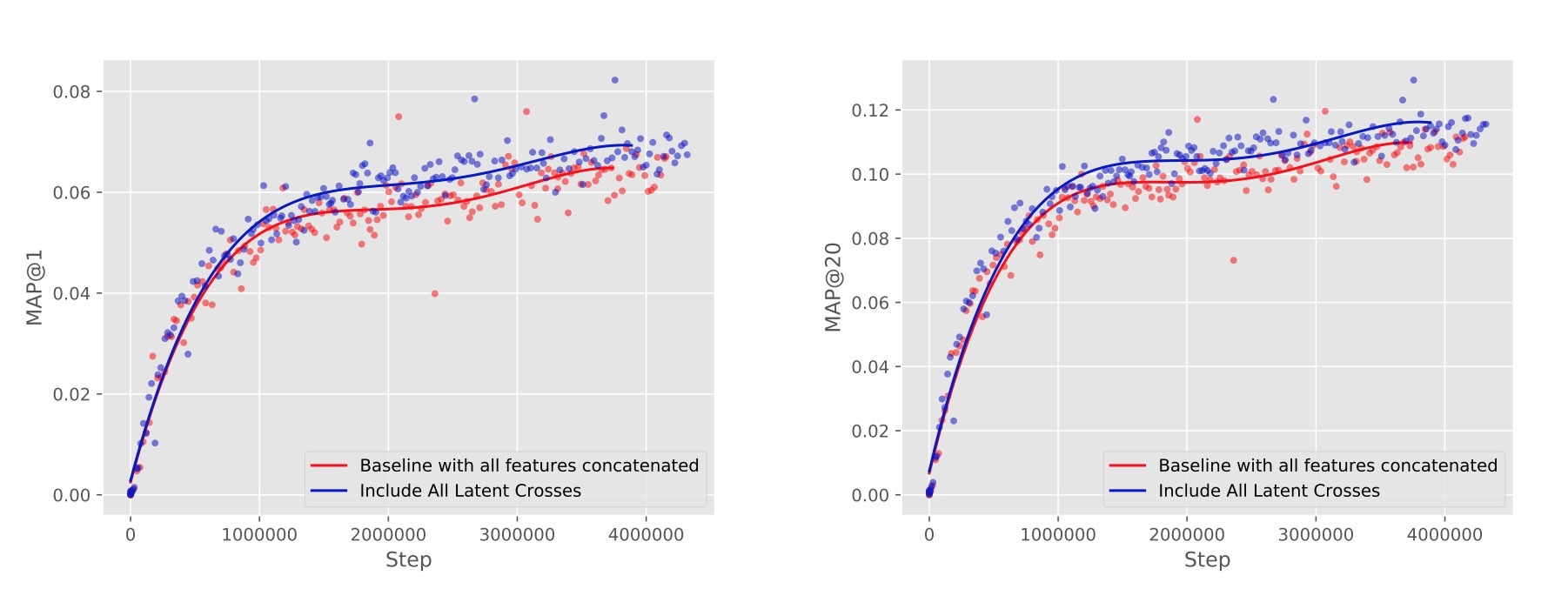
最后,我们测试了如何在完整产品模型上顶层添加latent crosses来影响accuracy。在这种case中,对于每个观看,模型都知道page、device type、time、视频观看时长、该观看行为离现在多久了(watch age)、uploader。特别的,我们的baseline Youtube模型会使用page、device、watch time、以及timedelta values作为pre-fusion拼接特征,也可以使用page、device、watch age作为post-fusion拼接特征。
我们测试了将timedelta和page作为pre-fusion的latent crosses,同时将device type和page作为post-fusion latent crosses。如图4所示,尽管所有这些特征已经通过拼接被包含进去,将它们做为latent crosses进行包含,对比起baseline可以提供提升。这也演示了:对于pre-fusion和post-fusion,使用多个features来一起工作的的能力,可以提供较强的accuracy提升。
8.讨论
下面有一些问题提出,期待后续解决。
8.1 DNN中的离散关系
许多paper关注点是:允许在特征间的多种交叉,我们发现NN也可以逼近离散交叉,该领域因子分解模型更难。例如,在[46]中,作者发现当user i在item j上执行一个action a时,\(<u_{(i,a)}, v_j>\)比\(<u_i,v_j, w_a>\)具有更好的accuracy。然而,一起发现这样的索引用户和actions,想做到效果好很困难,需要对数据的洞察。
与第4节中的实验相似,我们会根据模式 \(X_{i,j,a}=<u_{(i,a)},v_j>\)生成人造数据,并测试不同的网络结构对于在给定i,j,a并只有拼接特征作为独立输入来预测\(X_{i,j,a}\)是否ok。我们初始为\(u \in R^{10000}\)和\(v \in R^{100}\)作为向量,这样X是一个rank-1矩阵。我们和第4节使用相同的实验过程,为不同隐层和不同隐层宽度的网络测试Pearson相关度(R)。(我们使用learning rate=0.01的这些网络,比使用的learning rate要小10倍)。作为baseline,我们也测试了对于TF(\(<u_i, v_j, w_a>\))对不同ranks的Pearson相关度。
如图5所示,在某些cases中,deep模型可以实现一个合理的高Pearson相关度,事实上可以逼近离散交叉。同时有意思的是,学习这些交叉需要深度网络使用宽的hidden layers,特别是对于数据size很大时。另外,我们发现这样的网络很难训练。
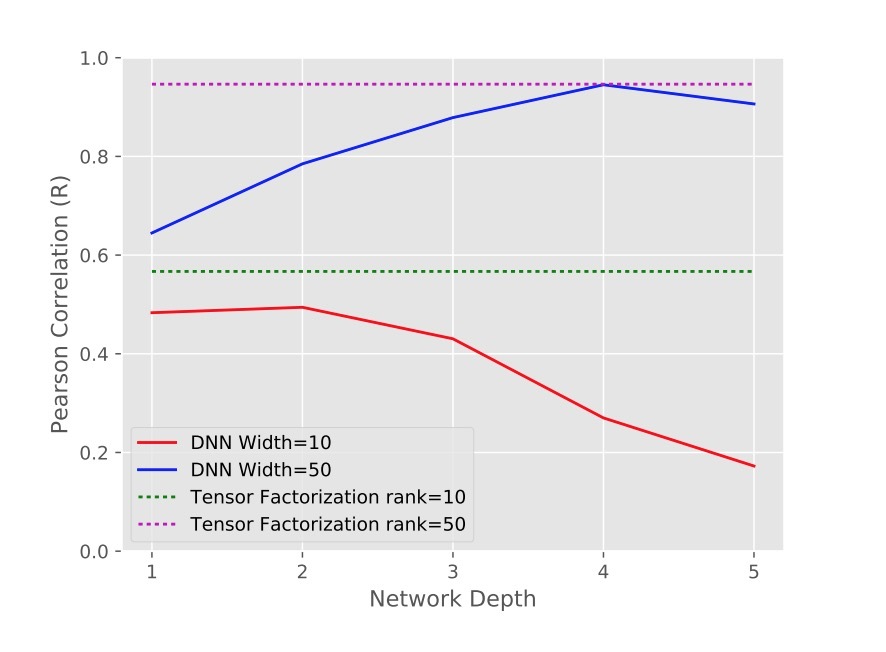
对比baseline TF的效果,这些数字很有意思。我们观察到因子模型可以合理逼近数据,但需要相当高的rank。(注意,即使底层tensor是满秩的,rank 100的因子分解足够描述它)然而,即使在这么高的rank上,TF模型比起DNN需要更少的参数,更容易训练。因此,随着在第5节中的结果,DNN可以逼近这些模式,但这么做很难,包含低秩交叉可以提供很容易训练的逼近。
8.2 二阶DNN
读这篇paper时,一个很自然的问题是,为何不尝试更宽的layers,让模型更深,或者更多二阶units,比如:GRUs和LSTMs?所有这些是合理的建模决策,但在我们的实验中,模型训练更难。该方法的一个优点是,很容易实现和训练,当配合使用其它二阶units(比如:LSTMs和GRUs)时,并且仍能提供明显的性能提升。
深度学习的成长趋势明显会使用更多二阶交叉。例如,常见的attention模型和记忆网络,如列表所示。而其它则更难被训练,我们相信该工作对神经推荐系统在方向上有一定的指导意义。
参考
https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/46488.pdf