yahoo japan在kdd 2017的《Embedding-based News Recommendation for Millions of Users》提出了关于新闻推荐的一些方法:
#
理解文章内容和用户偏好,对于做出有效新闻推荐来说很必要。而基于ID的方法,比如:CF和低秩因子分解,也可以做出推荐,但它们不适用于新闻推荐,因为候选文章会快速超期,在短时内被更新的替代。Word-based方法,常用于信息检索,是很好的候选方法,但它们只与用户历史动作的”queries”同义相关。该paper提出了一种embedding-based方法,它使用分布式表示,以一个3-step end-to-end的方式进行:
- i) 基于一个denoising autoencoder的变种生成文章的分布式表示
- ii) 使用一个RNN,将用户浏览历史作为输入序列,生成用户表示
- iii) 基于内积(inner-product)操作为用户匹配(match)和列出(list)对应文章,并考虑上系统性能。
提出的方法在Yahoo! Japan的主页上的历史访问数据进行评估和实验,并表现良好。我们基于实验结果,在我们实际的新闻分发系统上实现了它,并比较它的在线效果。CTR的提升有23%,总时长(total duration)提升了10%,对比起常用的方法。我们提出的方法已经开放给所有用户,并每天提供推荐给超过1000w个人用户,每月访问次数超10亿。
1.介绍
对于用户来说,读取所有存在的文章的新闻分布是不可能的,这受限于时间。因而,用户喜欢新闻服务可以选择性地提供文章。这种选择通常由编辑人工完成,所选故事的公共集合会在传统媒体上(比如:电视新闻节目、报纸)被提供给用户。然而,在互联网上,我们可以使用以下信息:user ID cookies、单个用户的个性化阅读文章等等,从而对用户进行标识来更好地选择文章。
ID-based方法,比如CF或低秩因子分解,可以很好地做出推荐。然而,[22]建议,这样的方法不适合于新闻推荐,因为候选文章很快会过时。因而,新闻推荐需要有三个关键点:
- 理解文章内容
- 理解用户偏好
- 基于内容和偏好为用户列出挑选的文章
另外,在现实中能快速响应扩展性和噪声并做出推荐很重要[14]。应用也需要在数百ms内返回响应给每个用户。
覆盖上面三个关键点的一个baseline实现如下。一篇文章被看成是关于它的文本的一个词集合(words collection)。一个用户可以看成是他/她浏览的多篇文章的一个词集合(words collection)。该实现会使用文章集和它的浏览历史之间的词共现作为特征来学习点击概率。
该方法有一些实际优点。它可以快速响应最新趋势,因为模型很简单,可以很快进行学习和更新。优先级的估计可以使用已经存在的搜索引擎和词的倒排索引进行快速计算。
出于这些原因,我们的之前版本实现基于该方法。然而,有一些要点可能会对推荐质量有负面影响。
第一个是词的表征(representation of words)。当一个词只当成一个feature使用时,两个具有相同意思的词会被看成是完全不同的feature。该问题会趋向于出现在在新闻文章中当两个提供者对于相同的事件提交文章时。
第二个问题是,浏览历史的处理。浏览历史在该方法中被处理看一个集合(set)。然而,他们实际上是一个序列,浏览的顺序应能表示用户兴趣的转移。我们也必须注意,用户在历史长度上分别很大的,从私人浏览,到那些每小时多次访问。
基于深度学习的方法已经在多个领域取得效果。词的分布式表示可以捕获语义信息。RNN已经为处理不同长度的输入序列提供了有效结果【9,15,17】。
如果我们使用一个RNN来构建一个深度模型来估计用户和文章间的兴趣度,另一方面,很难满足在实时系统中的响应限制。该paper提出了一个embedding-based方法,它使用一个在3-step end-to-end中使用分布式表示的方法,基于相关性和重复性,来为每个用户表示文章列表中的每篇文章。
- 基于一个denoising autoencoder的变种来生成文章的分布式表示
- 通过使用一个RNN,使用浏览历史作为输入序列,来生成用户表示
- 为每个用户基于用户-文章的内积,根据相关性和文章间的去重性,来匹配和列出文章
我们的方法的关键点是估计文章-用户间(article-user)的相关性。我们可以在用户访问足够时间之前,计算文章表示和用户表示。当一个用户访问我们的服务时,我们只选择他/她的表示,它计算候选文章和该表示间的内积。我们的方法可以表达包含在用户浏览历史中的复杂关系,并能满足实时性限制。
提出的方法被用到新闻分发服务中。我们比较了我们的方法和其它方法,结果表明,提出的方法要好于常用方法,不管是在实时服务上还是静态实验数据上,缺点是,增加了学习时间,模型更新延迟,但都在允许范围内。
2.服务和处理流
在该paper中讨论的方法被用在Yahoo!Japan上。第6节描述的在线实验也在该页上进行。
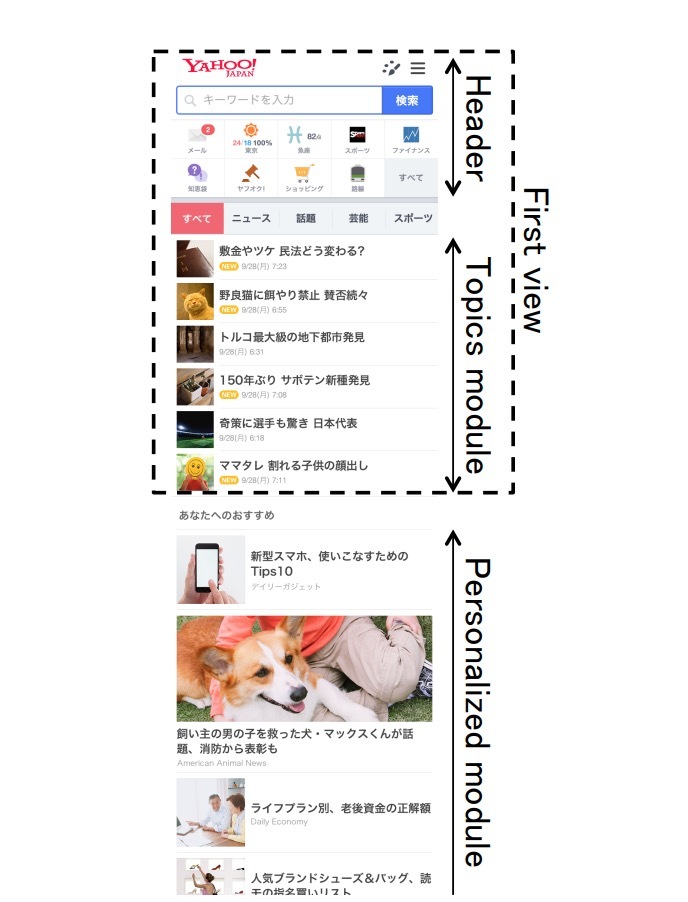
图1: Yahoo!Japan在移动端的主页示例。该paper讨论了关于个性化模块中的文章的方法
图1展示了一个我们的服务的实物,可以在May 2015复现。在顶部header有一个搜索窗口和其它服务的链接。中间部分,称为“Topics module”,提供了在主要新闻上通过人工专家为读者群精心挑选的的6篇文章。底部,称为“个性化模块(Personalized module)”,提供了许多文章和广告,它们对于用户是个性化的。在个性化模块中的用户,可以随着他们的滚动看尽可能多的文章。典型的读者基本上会浏览20篇文章。该paper描述了个性化文章提供的最优化。
会执行5个过程来为数百万用户进行个性化选择文章。
- Identify:通过用户之前的历史行为计算获取user features
- Matching:使用user features抽取匹配上的文章
- Ranking: 以特定优先级对文章列表重排序
- De-duplication:去重,移除包含相似信息的文章
- Advertising: 如果有必要,插入广告
从用户发起请求到展示文章,这些过程必须在数百ms内完成,因为文章是经常变化的。事实上,在我们服务中的所有文章,超过24小时就失去了新鲜度,每天会发表上万的新文章,同样的,相同数目的老文章会因为超期被移除。因而,每个过程都会采用较轻计算开销的方法,它会使用预计算好的文章的分布式表示(第3节描述)和用户表示(第4节)。
我们使用一个用户的分布式向量和候选文章向量间的内积,来匹配相关性和选择满意的候选。我们通过考虑额外因子(比如:PV的期望数目,每篇文章的新鲜度,以及匹配的相关度)来决定排序的优先顺序。我们会以贪婪的方式基于分布式表示的cosine相似度去复相似文章。当带有更高优先级的文章的cosine相似度的最大值,超出一定阀值时,我们会跳过该文章。在真实新闻分发服务中这是一个重要的过程,因为相似文章在排序时具有相似的分数。如果相似文章的展示相互挨着,用户满意度会下降,因为在展示时缺少多样性。广告也很重要,但许多研究表明广告与用户满意度间的关系,这里我们省略这一块的讨论。
3.文章表示
第1节介绍了一种使用words作为一篇文章的features的方法,它在特定的关于抽取和去重的cases中不一定能工作良好。这一节会描述一种方法来将文章表示成分布式表示。我们提出了之前的一种方法[12]。
3.1 生成方法
我们的方法会基于一个denoising autoencoder,并使用弱监督的方法来生成分布式表示向量。常见的denosing autoencoder可以公式化:
\[\hat{x} \sim q(\hat{x} | x) \\ h = f(W \hat{x} + b) \\ y = f(w'h+b') \\ \theta = argmin_{W,W',b,b'} \sum_{x \in X} L_R(y,x)\]其中\(x \in X\)是原始input vector,\(q(\cdot \mid \cdot)\)是加噪声混淆分布(corrupting distribution)。stochastically corrupted vector, \(\hat{x}\),从\(q(\cdot \mid x)\)中获取。隐表示,h,从\(\hat{x}\)映射穿过该网络,它包含了一个激活函数,\(f(\cdot)\),参数矩阵W,参数向量b。在相同的方式下,reconstructed vector,y, 也从h映射,带有参数\(W'\)和\(b'\)。使用一个loss函数,\(L_R(\cdot, \cdot)\),我们学习这些参数来最小化y和x的reconstruction errors。
h通常被用于一个对应于x的向量表示。然而,h只持有x的信息。我们希望解释,如果\(x_0\)与\(x_1\)更相似时,两个表示向量的内积 \(h_0^T h_1\)更大。为了达到该目的,我们使用了一个三元组,\((x_0, x_1, x_2) \in X^3\),作为训练的输入,并修改了目标函数,来维持他们的类目相似性:
\[\hat{x}_n \sim q(\hat{x}_n | x_n) \\ h_n = f(W \hat{x}_n + b) - f(b) \\ y_n = f(W' h_n + b') \\ L_T(h_0, h_1, h_2) = log(1 + exp(h_0^T h_2 - h_0 ^T h_1)) \\ \theta = argmin_{W, W', b, b'} \sum_{(x_0,x_1,x_2) \in T} \sum_{n=0}^2 L_R(y_n, x_n) + \alpha L_T(h_0, h_1, h_2)\]其中,\(T \subset X^3\), 以至于\(x_0\)和\(x_1\)具有相同或相似的类目,\(x_0\)和\(x_2\)具有不同的类目。在等式(1)中的h满足该属性,\(x=0 \rightarrow h = 0\)。这意味着,这是一篇与其它文章都不相似的文章。该概念,\(L_T(\cdot, \cdot, \cdot)\)是一个关于文章相似度的罚项函数,它对应于类别相似度(categorical similarity),其中\(\alpha\)是一个用于权衡的超参数。图2提供了该方法的一个总览。
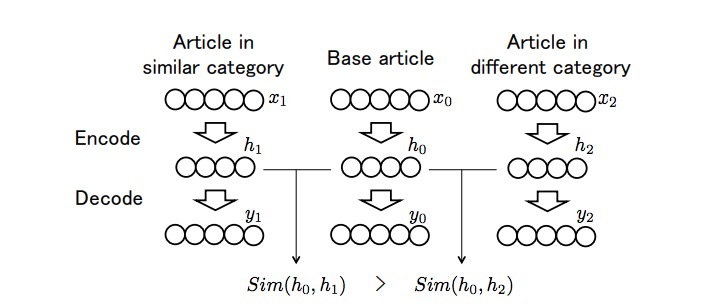
图2: 文章三元组有encoder
我们使用elementwise sigmoid 函数,\(\sigma(x)_i = \frac{1}{1+exp(-x_i)}\)作为\(f(\cdot)\),elementwsie cross entropy为\(L_R(\cdot, \cdot)\),masking noise为\(q(\cdot \mid \cdot)\)。我们训练该模型,\(\theta = \lbrace W, W', b, b' \rbrace\),通过使用mini-batch SGD进行最优化。
我们在应用阶段(application phase)通过使用常数衰减来构建\(\hat{x}\),在训练阶段(training phase)则使用stochastic corruption作为替代:
\[\hat{x} = (1-p) x \\ h = f(W \hat(x) + b) - f(b)\]其中,p是训练阶段的corruption rate。因而,h是应用时唯一确定的。乘以(1-p)对于将输入分布均衡到在middle layer中的每个神经元有影响,在masking noise和没有该noise间进行学习(待)。
我们使用在上述三个应用中生成的h作为文章的表示:
- (i) 可作为user-state函数的输入
- (ii) 可以衡量user和article间匹配的相关度
- (iii) 衡量在去重时文章间的相似度
4.用户表示
本节描述了通过用户浏览历史进行计算用户偏好的多种方法。首先,我们对问题进行公式化,并生成一个简单的基于word的baseline方法。接着描述使用文章的分布式表示的一些方法。
4.1 概念
假设:A是关于文章的所有集合。元素\(a \in A\)的表示依赖于该京城。在4.2节中,a是一个描述的word-based方法的稀疏向量,向量中的每个元素对应于词汇表中的每个词。然而,在4.3节和4.4节中,a是一个关于文章的分布式向量表示。
浏览(Browse)意味着用户访问一篇文章的URL。假设\(\lbrace a_t^u \in A \rbrace_{t=1,...,T_u}\)是用户\(u \in U\)的浏览历史。
会话(Session)意味着用户访问推荐服务并在推荐列表中点击某篇文章。
当用户u点击在我们的推荐服务中的一篇文章时(发生一次会话),他/她会立即访问被点文章的URL(发生一次浏览)。这样,对于浏览\(a_t^u\)和\(a_{t+1}^u\)之间,从不会超过一个session;因此,该session被称为\(s_t^u\)。然而,用户u也可以不经过我们的服务而访问一篇文章的URL,例如:通过一次Web search。因此,\(s_t^u\)并不总是存在。
由于一个session会对应提供给u的列表,我们通过一个文章列表\(\lbrace s_{t,p}^u \in A\rbrace_{p \in P}\)来表示一个session: \(s_t^u\)。\(p \subset N\)是推荐列表位置的集合,它实际上对应于在该session中屏幕上的展示位置。假设:\(P_{+} \subseteq P\)是点击位置,而\(P_{-} = P \backslash P_{+}\)是非点击位置。尽管P, \(P_{+}\), \(P_{-}\)取决于u和t, 我们会忽略这些下标以简化概念。图3展示了这些概念间的关系。
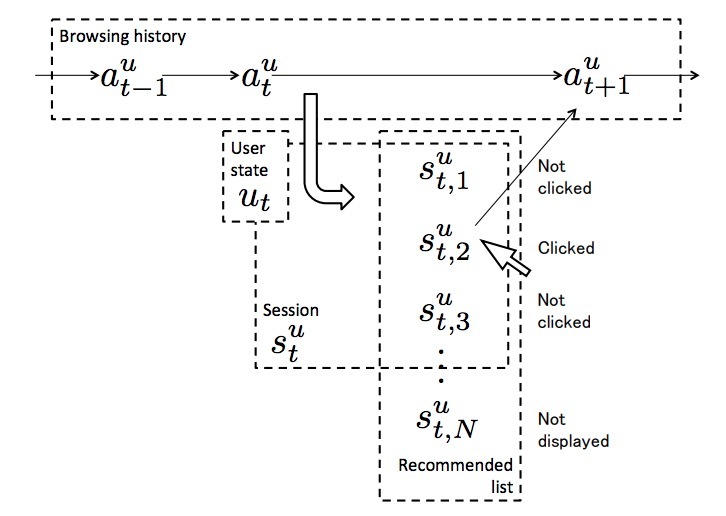
图3: 浏览历史和session
假设\(u_t\)是user state,它取决于\(a_1^u, ..., a_t^u\)等等,\(u_t\)表示在浏览\(a_t^u\)之后u的即时偏好。假设:\(R(u_t, a)\)是user state \(u_t\)与文章 a间的相关度,它表示了用户u在时间t上对于文章a的兴趣强度。我们的目标是,构建user-state function:\(F(\cdot, ..., \cdot)\)以及相关度函数:\(R(\cdot, \cdot)\),它们需满足下面属性:
\(u_t = F(a_1^u, ..., a_t^u) \\ \forall_{s_t^u} \forall_{p_{+} \in P_{+}} \forall_{p_{-} \in P_{-}} R(u_t, s_{t,p_{+}}Yu) > R(u_t, s_{t,p_{-}^u})\) …(2)
我们考虑下:请求量很大的真实新闻分发系统的受限响应时间,\(R(\cdot, \cdot)\)必须是一个简单函数,并能快速计算。对于所有用户\(\lbrace u_t \mid u \in U\rbrace\),以及所有文章\(\brace a \in A \rbrace\),由于候选文章会很频繁更新,对相关得分进行预计算是不可能的。因此,有必要在很短的时间内计算它(从访问我们的服务页面到推荐列表到被展示)。然而,我们具有足够多的时间来计算user state function:\(F(\cdot, ..., \cdot)\)(从浏览一些文章页面到下一次session发生)。
我们的受限相关函数(restrict relevance function):\(R(\cdot, \cdot)\),表示一个简单的内积关系,\(R(u_t, a) = u_t^T a\),出于这些原因,只有对user state function: \(F(\cdot,...,\cdot)\)来最小化目标函数:
\[\sum_{s_t^u} \sum_{p_{+} \in P_{+}, p_{-} \in P_{-}} - \frac{log( \sigma( R(u_t, s_{t,p_{+}}^u) - R(u_t, s_{t,p_{-}^u}))} { |P_{+}| |P_{-}|}\]…(3)
其中\(\sigma(\cdot)\)是logistic sigmoid function。等式4.1是等式(2)的一个宽松版本。实际上,在点击率上存在一个bias,具体取决于文章的展示位置,我们使用以下包含bias项\(B(\cdot,\cdot)\)的目标函数,来纠正这种影响。尽管\(B(\cdot, \cdot)\)是一个通过学习决定的参数,它的描述在下面会被忽略,因为它是该模型的一个公共项。
\[\sum_{s_t^u} \sum_{p_{+} \in P_{+}, p_{-} \in P_{-}} - \frac{log( \sigma( R(u_t, s_{t,p_{+}}^u) - R(u_t, s_{t,p_{-}}^u) + B(p_{+}, p_{-})))} { |P_{+}| |P_{-}| }\]4.2 Word-based模型
我们引入第1节所述的word-based模型作为baseline。
回顾下baseline实现的三个steps。
- 一篇文章通过它的文本中的词集合进行表示
- 一个用户通过他/她浏览过的文章所包含的词集合表示
- 用户与文章间的相关度通过关于在两者间的词共现数的一个线性函数表示
如果文件表示为a,用户函数为F,V是词汇表,定义如下:
\[a, u_t \in \lbrace 0, 1 \rbrace ^ V \\ (a)_v = \\ (u_t)_v = (F(a_1^u, ..., a_t^u))_v = a_v max_{1 \leq t' \leq t} (a_{t'}^u)_v\]…(4)
其中\((x)_v\)是x中的第v个元素。接着,相关函数变为一个关于参数\(\lbrace a_v \rbrace\)简单线性模型:
\[R(u_t, a) = u_t^T a \\ = \sum_{v \in V} (u_t)_v (a)_v \\ = \sum_{v \in V} a_v 1_{v \in u_t \cap a}\]该模型有两个缺点,略。
4.3 Decaying Model
我们引入了一个简单模型来解决上述缺点。模型的两点改变是:
- 它会使用由第3节构建的分布式表示作为表示向量,而非纯BOW表示。
- 它会使用根据浏览历史的加权平均,而非最大值。更特别的,我们会增加最近浏览在权重,减小前些天浏览的权重。
总之,\(u_t\)可以表示为:
\[u_t = \alpha \bigodot \frac{1}{\sum_{1 \leq t' \leq t}} \beta^{t-t'} \sum_{1 \leq t' \leq t} \beta^{t-t'} a_{t'}^u\]其中,\(\alpha\)是一个参数向量,它与\(a_t^u\)具有相同维度,\(\bigodot\)是两个向量的elementwise乘法,其中\(0 \leq \beta \leq 1\)是一个标量,它是一个用于表示时间衰减的超参数。如果\(\beta\)是1, 就是简单的平均,无需考虑浏览次序。训练参数只有\(\alpha\),它与baseline模型相似。
4.4 Recurrent Models
4.4.1 simple Recurrent Unit.
尽管decaying model要比word-based model要好,它有局限性,与频次、以及受指数衰减限制的遗忘影响成线性关系。
更常见的,\(u_t\)由前一state\(u_{t-1}\),和前一浏览\(a_t^u\)决定:
\[u_t = f(a_t^u, u_{t-1})\]因而,我们会尝试使用一个RNN来学习该函数。一个简单的RNN可以公式化为:
\[u_t = \phi ( W^{in} a_t^u + W^{out} u_{t-1} + b)\]其中\(\phi(\cdot)\)是激活函数;因而,我们后续使用双曲正切函数:\(tanh(\cdot)\)。训练参数是个方阵\(W^{in}, W^{out}\),bias vector为b,初始state vector \(u_0\),其中\(u_0\)是公共初始值,并不依赖于u。
我们通过end-to-end minibatch SGD的方式对等式 4.1的目标函数进行学习。然而,当输入序列过长时,简单的RNN很难学习,因为会存在梯度消失和爆炸问题。额外的结构被绑定到hidden layer上,以便减轻该问题。
下一部分会介绍使用这些结构的两个模型。
4.4.2 LSTM Unit
LSTM是一种解决梯度消失和爆炸问题的结构。我们可以将LSTM模型公式化为:
\[gi_t = \sigma(W_{gi}^{in} a_t^u + W_{gi}^{out} u_{t-1} + W_{gi}^{mem} h_{t-1}^u + b_{gi}) \\ gf_t = \sigma(W_{gf}^{in} a_t^u + W_{gf}^{out} u_{t-1} + W_{gf}^{mem} h_{t-1}^u + b_{gf}) \\ enc_t = \phi(W_{enc}^{in} a_t^u + W_{enc}^{out} u_{t-1} + b_{enc} \\ h_t^u = gi_t \bigodot enc_t + gf_t \bigodot h_{t-1} ^u \\ go_t = \sigma(W_{go}^{in} a_t^u + W_{go}^{out} u_{t-1} + W_{go}^{mem} h_t^u + b_{go}) \\ dec_t = \phi(W_{dec}^{mem} h_t^u + b_{dec}) \\ u_t = go_t \bigodot dec_t\]其中,\(\sigma(\cdot)\)是elementwise logistic sigmoid函数,\(h_t^u\)是一个hidden memory state。图4是LSTM模型的一个网络结构。
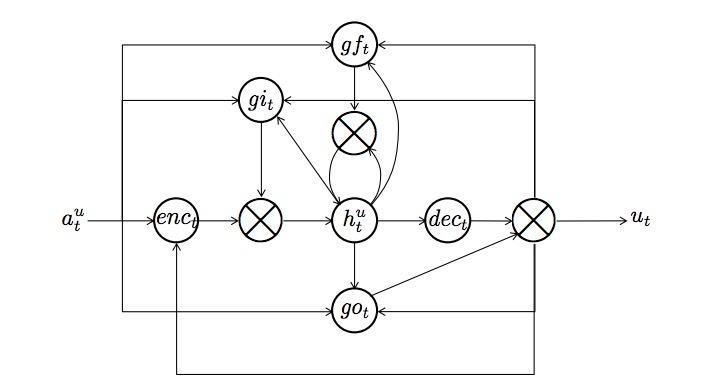
图4
center flows是从输入(浏览过的文章)到输出(user state)的最重要的flows。输入,\(a_t^u\),被编码中从文章向量空间到hidden空间(等式5),会合并之前的hidden state(等式6),并编码成文章向量空间(等式7,等式8)作为user state。
另外,该unit具有三个gates,称为input gate(\(gi_t\)),forget gate(\(gf_t\)),output gate(go_t)。我们假设每个gate都会各尽其职。input gate会过滤掉不必要的输入来构建一个user state,比如:由突然兴趣造成的。forget gate表示用户在兴趣上的下降。它可以表示比指数衰减(exponential decay)更复杂的forget影响。output gate会过滤掉在下一个session中不关注的成分。
训练参数是权重矩阵\(W\),bias向量b,初始化state vectors \(u_0\)和\(h_0^u\),其中\(u_0\)和\(h_0^u\)是不依赖于u的公共初始化值。
4.4.3 Gated Recurrent Unit(GRU)
是另一种避免梯度消失和爆炸的方法。公式如下:
\[gz_t = \sigma(W_{gz}^{in} a_t^u + W_{gz}^{mem} h^{t-1} + b_{gz}) \\ gr_t = \sigma(W_{gr}^{in} a_t^u + W_{gr}^{mem} h^{t-1} + b_{gr}) \\ enc_t = \phi(W_{enc}^{in} a_t^u + W_{enc}^{out}(gr_t \bigodot h^{t-1}) + b_{enc}) \\ h_t^u = gz_t \bigodot enc_t + (1-gz_t) \bigodot h_{t-1}^u \\ dec_t = \phi(W_{dec}^{mem} h_t^u + b_{dec}) \\ u_t = dec_t\]更准确的,该模型使用一个GRU layer和一个fully connected layer来构建,因为等式(1) 在原始GRU配置中不包含。图5展示了GRU-based模型的结构。
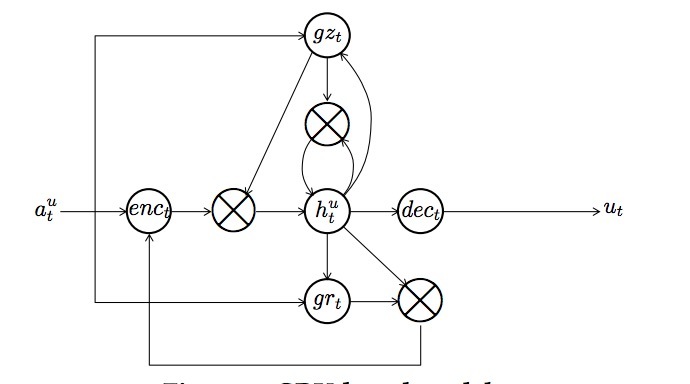
图5
除了省略了一些键头,该结构与LSTM-based模型相似。然而,等式(6)和等式(9)有一个重要的不同点。\(gz_t\)gate会扮演在LSTM-based模型的两个gates的角色:\(gi_t\)和\(gf_t\)。
\(sup_{u} \| h_t^u \|_{infty} =\) …(12)
等式11对于非常长的输入序列具有一个较大值;等式(12)从不会超过该常数。因此,我们认为GRU-based模型比LSTM-based模型能更好地解决梯度爆炸问题。
LSTm-based模型在训练时偶尔会失败,归因于我没在实验中没有使用梯度裁减(gradient clipping)从而造成梯度爆炸。然而,GRU-based模型不需要任何前置处理,不会造成梯度爆炸。
5.实验
5.1 训练数据集
首先,抽样了接近1200w的用户,它们在2016年1月到9月间,在Yahoo!Japan主页上有点击文章的动作。我们会为每个用户抽取一个超过两周时间的日志,随机包含至少一次点击。该抽取方法被用于减轻在特定时间内流行文章的影响。
最后产生的结果,在训练数据中,会有16600w个session,10亿次浏览,200w唯一的文章。我们也创建了相同时期内另一个数据集,并使用它作为验证集来最优化参数。
5.2 测试集
抽样了50w sessions,在2016年10月,用户点击文章超过位置20. 我们为每个session抽取前两周的浏览日志。我们使用位置1到20的文章数据来进行评估,忽略是否实际在屏幕中显示过。这基于我们timeline-based UI的观察。用户会从顶划到底,当点击一篇文章时趋向于离开我们的服务。这就是说,如果我们只使用实际展示的数据进行evaluation,安排实际展示按逆序的方式,进行不成比例地评估也佳。
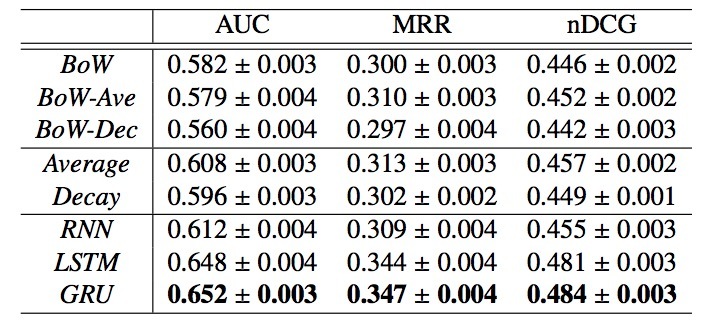
5.3 离线Metrics
AUC、MRR、nDCG
5.5 结果
表