介绍
该文档和相关脚本会详细说明如何构建高可扩展性模型,来面向众多的系统类型和网络拓朴。文档中的相关技术会利用一些低级TensorFlow python原语。在未来,许多这些技术会替换成高级APIs。
一、Input Pipeline
性能指南解释了如何来标识可能的input pipeline问题以及最佳实践。当使用大的输入(large input),并且每秒处理更多样本时(比如使用AlexNet训练ImageNet时),我们发现使用tf.FIFOQueue 和tf.train.queue_runner 不能充分利用多个新一代GPU。这是因为python线程和它的底层实现效率低。python线程的开销太大。
另一种方法是(在脚本中有实现),使用Tensorflow的原生并行机制(native parallelism)来构建一个input pipeline。我们的实现由3个stages组成:
- I/O reads:从磁盘中选择和读取image文件
- 图片处理:将图片records解码成图片,进行预处理,并组织成mini-batches。
- CPU-to-GPU数据转换:将图片从CPU转到GPU
每个stage的主要部分会被并行执行,其它stages则使用data_flow_ops.StagingArea。StagingArea是一个类似队列的操作,与tf.FIFOQueue相类似。不同之处是,StagingArea不会保障FIFO的顺序,但会提供更简单的功能,可以与其它stages并行地在CPU和GPU上执行。将input pipeline划分成3个stages,以并行方式独立操作是可扩展的,可以充分利用多核环境。这节的其余部分会详细介绍使用data_flow_ops.StagingArea的stages。
1.1 并行I/O读
data_flow_ops.RecordInput用于从磁盘中并行读取。给定一列表示成TFRecords的输入文件列表,RecordInput可以连续地使用后台线程读取records。当它至少加载了一半容量时,这些records会被放置到它自己的大内部池中(internal pool),然后会产生output tensors。
该op具有它自己的内部线程,可以通过消耗最小CPU的I/O时间来支配,这可以使得模型的其余部分可以并行的方式平滑运行。
1.2 并行图片处理
在图片从RecordInput读取后,它们作为tensors被传递给图片处理的pipeline。为了让图片处理pipeline更容易解释,假设input pipeline是面向8个GPUs,batch_size=256(每个GPU为32个)
256条记录会被并行地单独读取和处理。在graph中,会启动256个独立的RecordInput读ops。每个读op跟在用于图片预处理的一个相同的ops集合后,被认为是独立和并行执行。图片预处理ops包含了:图片解码(image decoding),扭曲(distortion),以及大小调整(resizing)。
一旦图片通过预处理,它们会一起串联成8个tensors,每个具有batch-size=32。我们并不需要使用tf.concat,该操作可以被实现成单个op,等待所有inputs准备好,然后将它们串联起来。作为替代,我们使用的是tf.parallel_stack来分配一个未初始化的tensor作为output,只要input有数据提供,每个input tensor会被写到output tensor的指定部分。
当所有的input tensors被完成时,output tensor在graph中会沿着图传递。这有效地隐藏了所有的内存延迟,因为产生所有input tensors是长尾。
1.3 并行CPU-to-GPU数据转移
我们继续假设,目标是8个GPU,batch_size=256(每个GPU为32)。一旦输入的图片被处理,并通过CPU进行串联,我们会具有8个tensors,每个具有一个batch_size=32.
TensorFlow可以让在一个设备上的tensors直接在另一个设备上被使用。TensorFlow引入了隐式拷贝(implicit copies),可以让tensors在其它设备上被使用。在该tensors在实际使用之前,运行时(runtime)会在设备间对拷贝进行调度。然而,如果copy 不能按时完成,需要这些tensors参与的计算将停转(stall),并产生性能下降。
在该实现中,data_flow_ops.StagingArea被用于显式并行地调度该copy。产生的结果是,当计算在GPU上启动时,所有tensors都已经可提供。
1.4 软件Pipeline
所有的stages都能通过不同的处理器进行驱动,data_flow_ops.StagingArea在这些处理器间被使用,以便能并行运行。
在模型启动运行所有stages之前,input pipeline会预热(warm up),使staging buffers在数据的集合间准备好。在每个运行step期间,在每个stage的开始阶段,数据的某个集合(one set of data)会从staging buffers读取,该set最终会被推进。
例如:如果存在三个stages:A, B和C。在之间存在两个staging areas:S1和S2。在预热期间(warm up),我们运行:
1
2
3
4
5
6
7
8
Warm up:
Step 1: A0
Step 2: A1 B0
Actual execution:
Step 3: A2 B1 C0
Step 4: A3 B2 C1
Step 5: A4 B3 C2
在预热期间,在S1和S2中,每个都会有一个数据集合。在实际运行的每个step,数据的某个集合会从每个staging area上被消费,另一个集合被添加进该step。
使用这种scheme的好处:
- 所有stages都是非阻塞的,因为在预热之后,staging areas总是会具有数据的某个集合。
- 每个stage可以并行运行,因为他们所有都可以立即启动
- staging buffers具有一个固定的内存开销。它们至多有一个额外的数据集合。
- 只有单个session.run()调用被需要来运行该step的所有stages,这可以使得分析和调试(profiling & debugging)更简单。
二、最佳实践
下面收集了一些最佳实践来提升性能和增加模型的可扩展性。
2.1 同时使用NHWC 和 NCHW构建模型
大多数被用于CNN的TensorFlow操作,同时支持NHWC和NCHW数据格式。在GPU上,NCHW更快。但在CPU上,NHWC有时更快。
构建一个模型来支持两种数据格式,可以让模型更灵活,能够进行忽略平台进行可选操作。大多数被用于CNN的TensorFlow操作同时支持NHWC和NCHW数据格式。benchmark script被写成同时支持NCHW和NHWC。
2.2 使用Fused Batch-Normalization
在TensorFlow中,缺省的batch-normalization被实现成组合操作(composite operations)。这很常见,但通常会导致次优性能。另一种方案是使用fused batch-normalization,它通常在GPU上具有更好的性能。下面是使用tf.contrib.layers.batch_norm的一个示例,它实现了fused batch-normalization。
bn = tf.contrib.layers.batch_norm(
input_layer, fused=True, data_format='NCHW'
scope=scope)三、变量分布与梯度聚合
在训练期间,训练变量值使用聚合梯度和deltas进行更新。在bechmark script中,我们演示了使用灵活的、通用目的的tensorflow原语,多种高性能分布和聚合schemes会被构建。
该脚本中变量分布和聚合的三个示例:
- parameter_server: 其中训练模型的每个replica会从一个参数服务器上读取变量,并独立地更新该变量。当每个模型需要该变量时,他们会通过由tensorflow runtime被添加的标准隐式拷贝进行copy。该示例script展示了使用该方法进行本地训练,分布式同布训练,以及分布式异步训练。
- replicated: 会在每个GPU上为每个训练变量放置一个相同copy。forward和backward计算可以随着这些变量数据的提供而立即启动。梯度会跨多个GPUs进行累积,聚合总梯度会被应用到每个GPU的变量拷贝上,同步保持他们。
- distributed_replicated:会在每个GPU上放置训练参数的一个相同copy,在参数服务器上有一个主copy(master copy)。forward和backward计算可以随着提供数据的到位而立即启动。梯度在每个server上跨所有GPUs被累积,接着每个server聚合梯度,然后应用到主copy上。在所有workers完成后,每个worker会从主copy上更新该变量的所有copy。
下面是每种方法的详情
3.1 参数服务器变量
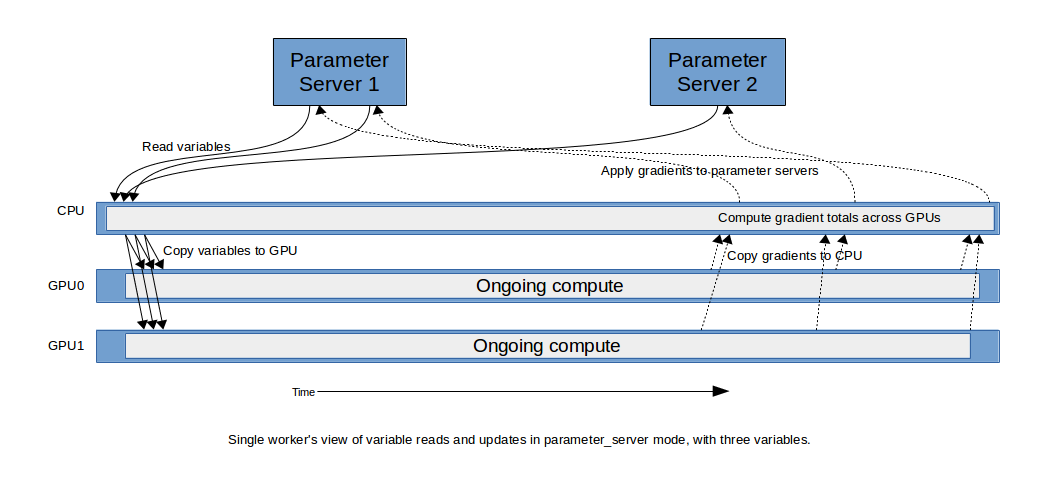
在tensorflow中,关于管理训练变量,最常用的方法是参数服务器模式(parameter server mode)。
在一个分布式系统中,每个worker进行运行着相同的模型,参数服务器处理着着变量的主拷贝(master copies)。当一个worker需要在一个参数服务器上的变量,它可以直接引用它。TensorFlow runtime会添加隐式拷贝到graph中,以便该变量值在所需要的计算设备上可提供。当一个梯度在一个worker上被计算时,它会发送到拥有该变量的参数服务器上,相应的优化器被用于更新该变量。
有一些技术来提升吞吐量:
- 这些变量会基于它们的size在参数服务器间进行传播,以便负载均衡。
- 当每个worker具有多个GPUs时,梯度跨GPU累积,单个聚合梯度被发送给参数服务器。这减小了网络带宽,以及参数服务器的工作量。
为了在workers间协调,一种常用的模式是异步更新(async updates),其中每个worker会更新该变量的主拷贝,无需与其它workers进行同步。在我们的模型中,我们展示了,在跨wokers间引入同步机制(synchronization)相当简单,以便所有workers的更新在下一个step启动前,在一个step内完成。
参数服务器方法可以被用于本地训练(local training),在该case中,我们不使用跨参数服务器间传播变量主拷贝,它们在跨CPUs或GPUs进行传播。
由于该setup的简单特性,该架构已经在社区受到欢迎。
在该script中所使用的模式,可以通过–variable_update=parameter_server 进行设定。
3.2 复制变量(Replicated Variables)
在该设计中,在server上的每个GPU都拥有属于自己的每个变量的拷贝。这些值跨GPUs进行同步保持,通过使用每个GPU上关于变量拷贝的完全聚合梯度(fully aggregated gradient)来进行。
这些变量和数据在训练开始处被提供,因此训练的前向传递(forward pass)可以立即启动。梯度跨设备进行聚合,完全聚合梯度(fully aggregated gradient)接着被应用到每个本地copy上。
跨server的梯度聚合以不同的方式被完成:
- 使用标准TensorFlow操作,在单设备(CPU或GPU)来累积总梯度,接着将它拷贝回所有GPUs上
- 使用NVIDIA® NCCL ,在NCCL这一节描述
该模式可以在script中通过传递–variable_update=replicated来使用。
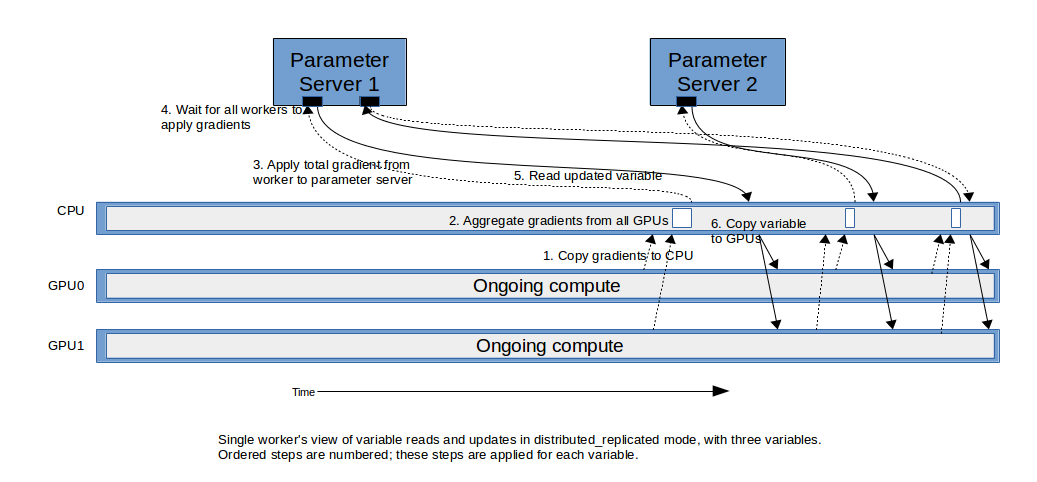
3.3 在分布式训练中的Replicated Variables
变量的replicated方法可以扩展到分布式训练中。一种方法与replicated模式相类似:跨集群进行梯度完全聚合,并将它们应用到每个本地变量拷贝上。这可以在该脚本的将来版本中进行展示:该脚本会表示一个不同的变种,在这里描述。
在该模式中,除了每个GPU具有变量拷贝外,会在参数服务器上存储一个主拷贝(master copy)。如同replicated模式,训练可以使用变量的本地拷贝立即启动。
随权重的梯度变得可用,他们会被发送回给参数服务器,所有本地拷贝会被更新:
- 1.在相同worker上的GPU上的所有梯度,会被一起聚合
- 2.从每个worker上的聚合梯度会被发送到拥有该变量的参数服务器上,其中,指定的优化器被用于更新变量的主拷贝。
- 3.每个worker会从主copy上更新它的变量本地copy。在示例模型中,这通过一个cross-replica barrier来完成,它会等待所有workers完成更新变量,然后在该barrier被所有replicas释放后去fetch新的变量。一旦该copy完成所有变量时,会在一个训练step的未尾进行标记,然后启动一个新的step。
尽管这听起来与参数服务器的标准使用方式相类似,但该性能在许多情况下通常更好。这大部分归功于:计算的发生没有任何延迟,许多早期梯度的拷贝延迟可以通过后续的计算层进行隐藏。
该模式可以在脚本上通过传递–variable_update=distributed_replicated来完成。
四、NCCL
为了在相同的宿主机上,跨不同的GPU进行广播变量和聚合梯度,我们会使用缺省的TensorFlow隐拷贝机制(implicit copy mechanism)。
然后,我们可以可选地使用NCCL(tf.contrib.nccl) 。NCCL是一个NVIDIA® 库,可以有效地跨GPU进行广播和聚合数据。它会在每个GPU上调度一个协同kernel(cooperating kernel),这些GPU知道如何最好地利用底层硬件拓朴;该kernel会使用该GPU的单个SM。
在我们的实验中,我们演示了,尽管NCCL经常会导致更快的数据聚合,但它不会产生更快的训练。我们的假设(hypothesis)是,隐式拷贝本质上是自由的,因为它们会进入GPU的copy引擎,只要它的延迟可以通过主计算(main computation)本身进行隐藏。尽管NCCL可以更快地转移数据,它会取走一个SM,添加更多压力给底层的L2 cache。我们的结果展示,对于8-GPUs,NCCL经常会产生更好的性能。然而,对于更少的GPUs,隐式copy通常效果更好。
Staged Variables
我们进一步引入了一个staged-variable模式,其中,我们使用变量读(reads)和更新(updates)的staging areas。与input pipeline的software pipelining相类似,这可以隐藏数据拷贝延迟。如果计算时间比拷贝和聚合花费更长的时间,copy自身基本上是免费的。
下面部分是关于,所有的权重读取都来自于之前的训练阶段。因此,它与SGD是一个不同的算法。但通过调整learning rate以及其它超参数可能提升它的收敛速度。
执行该脚本
该节列出了核心命令行参数,以及一些基本示例来执行该脚本(tf_cnn_benchmarks.py)
注意:tf_cnn_benchmarks.py使用配置的force_gpu_compatible,它在tensorflow 1.1之后被引入。在tensorflow 1.2中被release,推荐从源码进行构建
基本命令行参数:
- model:所使用的模型,比如:resnet50, inception3, vgg16, 和 alexnet
- num_gpus:使用的gpu数目
- data_dir:要处理的数据路径。如果没有设置,使用人造数据。为了使用ImageNet数据,可以使用这些指引。
- batch_size:每个GPU的batch size
- variable_update:管理变量的方法:parameter_server ,replicated, distributed_replicated, independent
- local_parameter_device:作为参数服务器使用的设备:cpu或gpu。
一些示例:
# VGG16 training ImageNet with 8 GPUs using arguments that optimize for
# Google Compute Engine.
python tf_cnn_benchmarks.py --local_parameter_device=cpu --num_gpus=8 \
--batch_size=32 --model=vgg16 --data_dir=/home/ubuntu/imagenet/train \
--variable_update=parameter_server --nodistortions
# VGG16 training synthetic ImageNet data with 8 GPUs using arguments that
# optimize for the NVIDIA DGX-1.
python tf_cnn_benchmarks.py --local_parameter_device=gpu --num_gpus=8 \
--batch_size=64 --model=vgg16 --variable_update=replicated --use_nccl=True
# VGG16 training ImageNet data with 8 GPUs using arguments that optimize for
# Amazon EC2.
python tf_cnn_benchmarks.py --local_parameter_device=gpu --num_gpus=8 \
--batch_size=64 --model=vgg16 --variable_update=parameter_server
# ResNet-50 training ImageNet data with 8 GPUs using arguments that optimize for
# Amazon EC2.
python tf_cnn_benchmarks.py --local_parameter_device=gpu --num_gpus=8 \
--batch_size=64 --model=resnet50 --variable_update=replicated --use_nccl=False分布式命令行参数:
- ps_hosts: 逗号分割的hosts列表,用于参数服务器,格式为:
:port, 例如:10.0.0.2:50000 - worker_hosts:逗号分割的hosts列表,用于workers,格式为:
:port, 例如:10.0.0.2:50001 - task_index:ps_hosts或者worker_hosts的host列表索引
- job_name:job的类型,比如:ps或者worker
分布式示例
下面是一个在2台hosts上训练ResNet-50的示例:host_0 (10.0.0.1) and host_1 (10.0.0.2). 示例使用人造数据。为了读取真实数据可以通过参数–data_dir来实现。
# Run the following commands on host_0 (10.0.0.1):
python tf_cnn_benchmarks.py --local_parameter_device=gpu --num_gpus=8 \
--batch_size=64 --model=resnet50 --variable_update=distributed_replicated \
--job_name=worker --ps_hosts=10.0.0.1:50000,10.0.0.2:50000 \
--worker_hosts=10.0.0.1:50001,10.0.0.2:50001 --task_index=0
python tf_cnn_benchmarks.py --local_parameter_device=gpu --num_gpus=8 \
--batch_size=64 --model=resnet50 --variable_update=distributed_replicated \
--job_name=ps --ps_hosts=10.0.0.1:50000,10.0.0.2:50000 \
--worker_hosts=10.0.0.1:50001,10.0.0.2:50001 --task_index=0
# Run the following commands on host_1 (10.0.0.2):
python tf_cnn_benchmarks.py --local_parameter_device=gpu --num_gpus=8 \
--batch_size=64 --model=resnet50 --variable_update=distributed_replicated \
--job_name=worker --ps_hosts=10.0.0.1:50000,10.0.0.2:50000 \
--worker_hosts=10.0.0.1:50001,10.0.0.2:50001 --task_index=1
python tf_cnn_benchmarks.py --local_parameter_device=gpu --num_gpus=8 \
--batch_size=64 --model=resnet50 --variable_update=distributed_replicated \
--job_name=ps --ps_hosts=10.0.0.1:50000,10.0.0.2:50000 \
--worker_hosts=10.0.0.1:50001,10.0.0.2:50001 --task_index=1