介绍
tensorflow计算图(computation graphs)很强大,但很复杂。graph可视化可以帮助我们理解和调试他们。这里有个可视化示例。

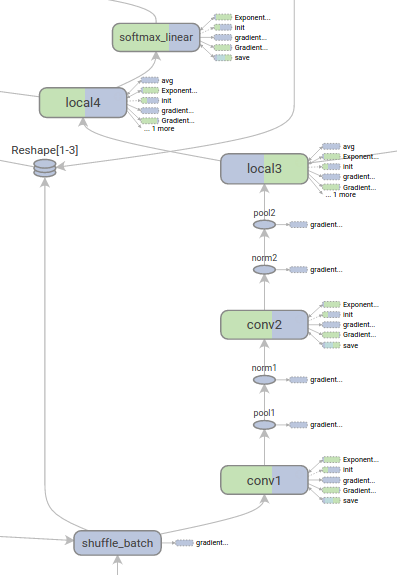
图1: 一个tensorflow graph的可视化
为了看到你自己的graph,运行tensorboard,并指向你的job的log目录,点击顶部面板的graph tab,使用左上角的菜单,选择合适的参数运行。
1.Name scoping和nodes
常见的tensorflow graph具有几千个节点————一次性看不了那么多,也布局不了那么多。为了简化,变量名会用于指定范围(scope),可视化时会使用该信息在graph中定义一个层级结构。缺省的,只有顶层结构会可见。这里给出了在hidden名下的一个示例:
import tensorflow as tf
with tf.name_scope('hidden') as scope:
a = tf.constant(5, name='alpha')
W = tf.Variable(tf.random_uniform([1, 2], -1.0, 1.0), name='weights')
b = tf.Variable(tf.zeros([1]), name='biases')该结果有以下三个op名:
- hidden/alpha
- hidden/weights
- hidden/biases
缺省的,可视化会折叠这三个op到一个hidden的label下。其它细节则不展示。你可以双击或者点击橙色”+”号来展开它,这样你可以看到三个子节点(subnodes):alpha,weights,biases.
这里是一个真实的示例,有一个在初始化和展开状态上更复杂的节点。
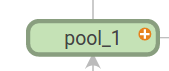
说明:顶层name scope为pool_1的初始视图。点击橙色+按钮,或者双击可以展开它
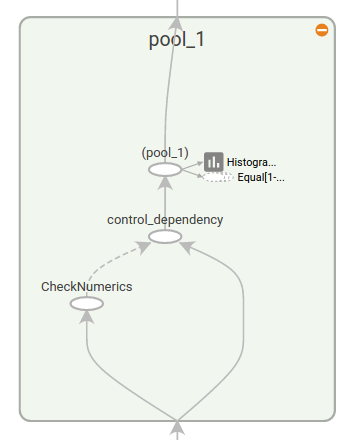
说明:pool_1的展开视图。点击-按钮可以折叠它
通过name scopes对节点进行分组,是生成一个清晰graph的关键。如果你正构建一个模型,name scopes可以控制生成的可视化好坏。你的name scope命名的越好,你的可视化就越好。
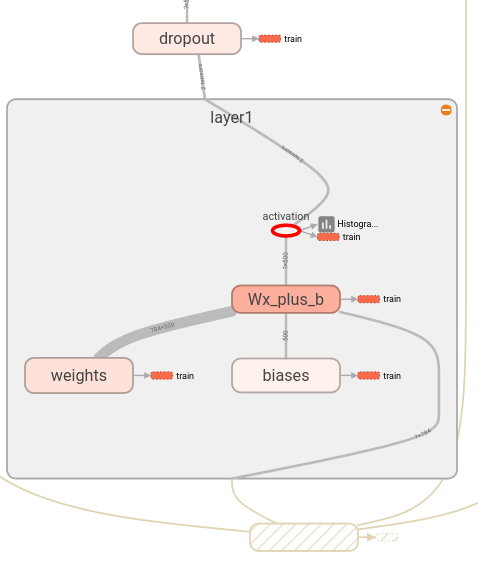
上图展示了可视化的第二好处。tensorflow graph具有两类连接(connection):数据依赖(data dependencies)和控制依赖(control dependencies)。数据依赖展示了两个op间的tensor流,用实线表示;控制依赖使用点划线表示。在展开视图中(右边),除了CheckNumerics和control_dependency间的连接是点划线外,其它所有连接是数据依赖。
第二个技巧是,简化layout。大多数tensorflow graph有少量节点会比其它节点有更多连接。例如,许多节点在初始化step时具有一个控制依赖。在init节点和它的依赖间的所有边,会创建一个非常杂乱(clutter)的视图。
为了降低杂乱程度,可视化将所有高度(high-degree)的节点划分到一个右侧的辅助区域(auxiliary area),并且不会绘制用于表示边(edge)的线。作为线的替代,我们会绘制小节点图标(small node icons)来表示连接。将辅助节点(auxiliary nodes)相分离通常不会移除关键信息,因为这些节点通常与记帐函数(bookkeeping function)相关。参见下面的Interaction部分来看如何移除main graph与auxiliary area间的节点。
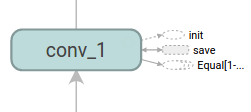
说明:conv_1与save相连接。注意,在右侧的save节点。
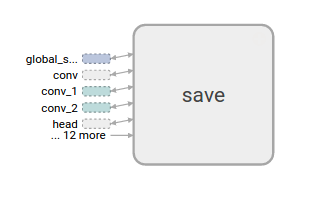
说明:save具有一个高的degree,将会以一个辅助节点(auxiliary node)形式显示。与conv_1的连接被看成是一个在左侧的node icon。为了进一步减小杂乱度,由于save具有许多连接,我们展示了前5个,将其它标为… 12 more。
最后一个结构化简化是系列折叠(series collapsing)。序列图案(即,它们的节点名通过后缀的一个数字进行区别,具有相同的结构)会被折叠成单个stack的节点,如下所示。对于长序列的网络,这可以极大简化视图。有了层级节点,双击可以展开该series。
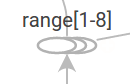
说明:一个节点序列的折叠视图
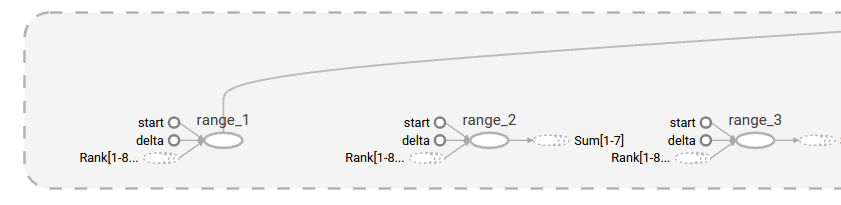
说明:双击后,展开视图的一小部分
最后,为了帮助可读性,可视化会使用特殊的图标来表示constants node和summary nodes。为了归纳,这里提供了一个节点符号表:

2.交互(Interaction)
通过panning和zooming进行导航。点击和拖动pan,并使用一个scroll姿式进行缩放。双击一个节点,并点击它的加号(+)按钮,来展开一个name scope(它表示一组操作)。为了能轻易地跟踪zooming和panning时的当前视角(viewpoint),在右下角有一个小地图(minimap)。
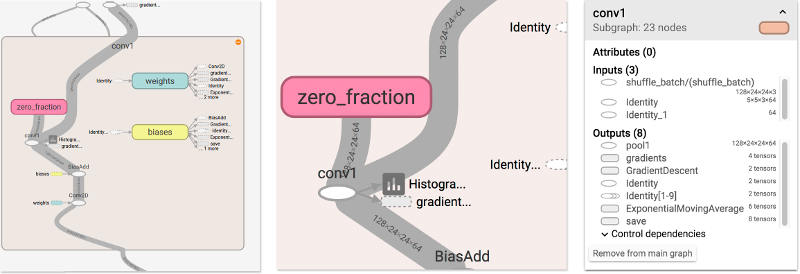
为了关闭一个已打开的node,再次双击它,并点击它的减号(-)按钮。你也可以点击一次来选择一个节点。它会变成一个更暗的色,有关于它和连接到该节点的详情,出现在右上角的info card。
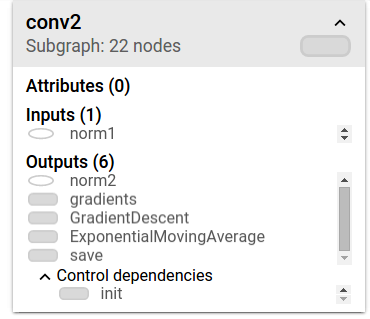
说明:info card展示了关于name scope名为conv2的详情。inputs和outputs的组合来自于该name scope内的op节点的input和output。name scope本身没有属性
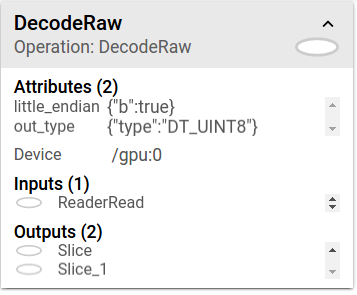
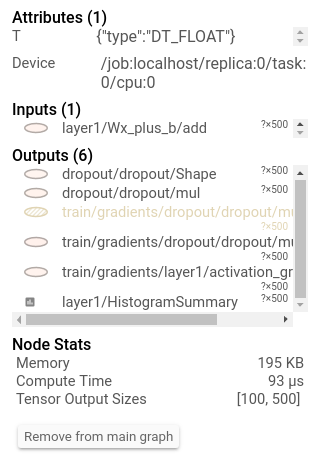
说明:info card展示了DecodeRaw op节点的详情。除了inputs和outpus外,该card展示了与当前op相关的device和attributes
tensorboard提供了多种方式来更改graph的layout可视化。这不会更改graph的计算语义,但它为网络结构带来更清晰一些。通过右击一个节点,或者按住info card底部的按钮,可以得到关于layout的如下变更:
- 在主图(main graph)和auxiliary area间的节点可以被移除
- 一个列系节点可以被解除分组(ungroup),从而使在该series中的节点不会再以分组的形式出来。解除分组后的series可以被重新分组(regroup)。
选中(selection)操作对于理解高度节点(high-degree node)很有用。选中任意的高度节点,相应节点连接的图标也会被选中。对于想看哪个节点被保存与否,会变得很方便。
点击在info card上的一个节点名,也会选中它。如果有必要,视角(viewpoint)会自动压平(pan),从而使该节点可见。
最终,你能为你的graph选择两种颜色scheme,使用color菜单。缺省的Structure View 会展示结构:当两个高度节点具有相同的结构时,它们会具有相同的彩虹颜色。唯一结构的节点是灰色的。第二个图中,它展示了不同op所运行的设备(device)。Name scope会根据在其中op的设备比例进行标色。
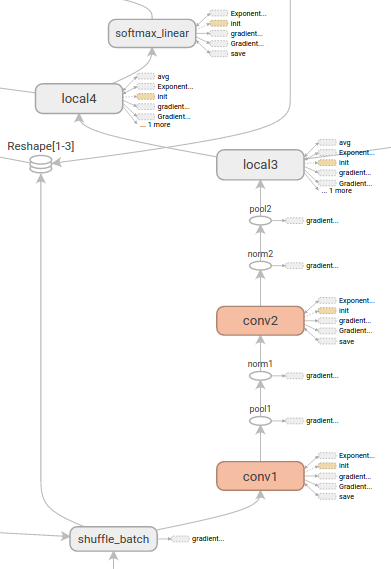
Tensor shape信息
当序列化的GraphDef包含了tensor shapes时,graph visualizer会对tensor dimensions上的边进行标记(label),边的粗细反映了总的tensor的size。当对graph进行序列化时,为了在GraphDef包含tensor shapes,需要将实际的graph对象(在sess.graph中)传递给FileWriter。下图展示了带有tensor shape信息的CIFAR-10模型。
Runtime统计
通常,对于一个run来说,收集runtime元数据是有用的,比如:总内存使用,总计算时长,节点的tensor shapes。下面的示例代码是simple MNIST tutorial中代码修改版关于train和test部分的一个片段,其中会记录summaries和runtime statistics。关于如何记录summaries详见Summaries Tutorial 。
# Train the model, and also write summaries.
# Every 10th step, measure test-set accuracy, and write test summaries
# All other steps, run train_step on training data, & add training summaries
def feed_dict(train):
"""Make a TensorFlow feed_dict: maps data onto Tensor placeholders."""
if train or FLAGS.fake_data:
xs, ys = mnist.train.next_batch(100, fake_data=FLAGS.fake_data)
k = FLAGS.dropout
else:
xs, ys = mnist.test.images, mnist.test.labels
k = 1.0
return {x: xs, y_: ys, keep_prob: k}
for i in range(FLAGS.max_steps):
if i % 10 == 0: # Record summaries and test-set accuracy
summary, acc = sess.run([merged, accuracy], feed_dict=feed_dict(False))
test_writer.add_summary(summary, i)
print('Accuracy at step %s: %s' % (i, acc))
else: # Record train set summaries, and train
if i % 100 == 99: # Record execution stats
run_options = tf.RunOptions(trace_level=tf.RunOptions.FULL_TRACE)
run_metadata = tf.RunMetadata()
summary, _ = sess.run([merged, train_step],
feed_dict=feed_dict(True),
options=run_options,
run_metadata=run_metadata)
train_writer.add_run_metadata(run_metadata, 'step%d' % i)
train_writer.add_summary(summary, i)
print('Adding run metadata for', i)
else: # Record a summary
summary, _ = sess.run([merged, train_step], feed_dict=feed_dict(True))
train_writer.add_summary(summary, i)该代码会从99 step开始,每100次触发runtime statistics。
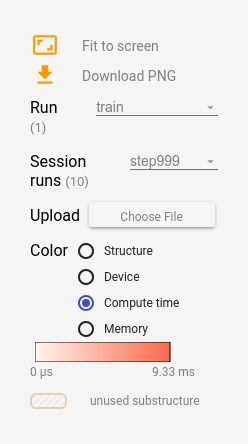
当你开启tensorboard时,进入到Graph tab,你将看到在“Session runs”下的选项,它会对应着运行metadata的steps。选择这些runs的其中之一,将会展示出在该step的网络快照,未被使用的节点会淡出。在左侧的控制面板上,你可以通过总内存或总的计算时间来开启节点着色。另外, 点击一个节点将展示额外的总内存量,计算时间,以及tensor output size。