1.介绍
一个embedding是从离散对象(discrete objects, 比如:单词)到实数向量的一个映射。例如,一个关于英文单词的300维的embedding可以是:
blue: (0.01359, 0.00075997, 0.24608, ..., -0.2524, 1.0048, 0.06259)
blues: (0.01396, 0.11887, -0.48963, ..., 0.033483, -0.10007, 0.1158)
orange: (-0.24776, -0.12359, 0.20986, ..., 0.079717, 0.23865, -0.014213)
oranges: (-0.35609, 0.21854, 0.080944, ..., -0.35413, 0.38511, -0.070976)Embeddings可以让你应用机器学习到离散输入中。分类器(通常是神经网络)通常被设计成使用dense continuous vectors,其中所有的值都用来表示一个对象(object)。如果离散对象被编码成离散原子,例如:唯一的id号,它们会成为学习和泛化的阻碍。一种理解embeddings的方法是,将非向量型对象转化成机器学习可用的输入。
Embedding作为机器学习的输出也很有用。因为embeddings会将对象映射成向量,应用(Application)可以在向量空间中使用相似度(例如:欧拉距离 or 向量夹角 )来作为相似度的衡量。一种常见的用法是寻找最近邻。使用上述相同的word embedding,例如,这里对于每个词和相应的夹角只有三个最邻近:
blue: (red, 47.6°), (yellow, 51.9°), (purple, 52.4°)
blues: (jazz, 53.3°), (folk, 59.1°), (bluegrass, 60.6°)
orange: (yellow, 53.5°), (colored, 58.0°), (bright, 59.9°)
oranges: (apples, 45.3°), (lemons, 48.3°), (mangoes, 50.4°)这说明,比起lemons和oranges,apples和oranges在某种程度上是相似的(夹角更小)。
2.训练一个embedding
为了在tensorflow中训练一个word embeddings,我们首先需要将文本split成words,在词汇表中为每个词分配一个integer。让我们假设这一步已经完成,那么word_ids是一个关于这些integers的向量。例如,句子:”I have a cat.”可以分割成[“I”, “have”, “a”, “cat”, “.”] ,接着相应的word_ids tensor具有shape [5],包含了5个integer。为了得到这些word id的embedding,我们需要创建一个embedding变量,并如以下方法使用tf.gather 函数:
word_embeddings = tf.get_variable(“word_embeddings”,
[vocabulary_size, embedding_size])
embedded_word_ids = tf.gather(word_embeddings, word_ids)这之后,tensor embedded_word_ids 将具有[5, embedding_size]在我们的样本中,并为5个词中每个词包含了embeddings (dense vectors)。变量word_embeddings可以被学到,在训练结束后,它会包含在词汇中的所有词的embeddings。该embeddings可以以多种方式被训练,具体取决于提供的数据。例如,给定一个关于句子的大语料,你可以使用一个RNN通过前面的词来预测下一个词,a或者你可以训练两个网络来做多语言翻译。这些方法在word2vec中有描述。在所有的情况下,先声明一个embedding变量,然后再将words通过使用tf.gather进行嵌入。
3.可视化
TensorBoard具有一个内建的visualizer,称为Embedding Projector,用于embeddings的交互可视化。embedding projector将读取你的checkpoint文件,使用PCA将它们投影到3维空间上。另一种有用的投影是:t-SNE.
如果你使用一个embedding,你可能希望将labels/images绑定到数据点上。你可以通过生成一个metadata文件(它包含每个点的labels),通过python API配置projector,在相同的目录下人工构建和保存projector_config.pbtxt作为你的checkpoint文件。
3.1 Setup
关于如何运行TensorBoard以及更多相关信息,详见:TensorBoard: Visualizing Learning
为了可视化你的embeddings,需要做三件事:
1) 创建一个2D tensor来持有你的embedding对象:
embedding_var = tf.get_variable(....) 2) 在LOG_DIR 的checkpoint文件中周期性保存你的模型变量:
saver = tf.train.Saver()
saver.save(session, os.path.join(LOG_DIR, "model.ckpt"), step)3) (可选) 将metadata与你的embedding相关联.
如果你具有任意的metadata (labels, images)与你的embedding相关联,你可以通过在LOG_DIR中保存一个projector_config.pbtxt或者使用我们的python API来告诉TensorBoard。
embeddings {
tensor_name: 'word_embedding'
metadata_path: '$LOG_DIR/metadata.tsv'
}也可以使用下面的代码段来产生相同的配置:
from tensorflow.contrib.tensorboard.plugins import projector
# Create randomly initialized embedding weights which will be trained.
vocabulary_size = 10000
embedding_size = 200
embedding_var = tf.get_variable('word_embedding', [vocabulary_size, embedding_size])
# Format: tensorflow/tensorboard/plugins/projector/projector_config.proto
config = projector.ProjectorConfig()
# You can add multiple embeddings. Here we add only one.
embedding = config.embeddings.add()
embedding.tensor_name = embedding_var.name
# Link this tensor to its metadata file (e.g. labels).
embedding.metadata_path = os.path.join(LOG_DIR, 'metadata.tsv')
# Use the same LOG_DIR where you stored your checkpoint.
summary_writer = tf.summary.FileWriter(LOG_DIR)
# The next line writes a projector_config.pbtxt in the LOG_DIR. TensorBoard will
# read this file during startup.
projector.visualize_embeddings(summary_writer, config)在运行你的模型和训练你的embedding之后,运行TensorBoard,并将log指向LOG_DIR。
tensorboard --logdir=LOG_DIR接着点击在top pane上的Embeddings tab,选中并运行。
Metadata
通常embeddings都具有与它关联的metadata(例如:labels,images)。metadata应该在模型checkpoint文件外以一个独立的文件存储,因为metadata不是一个可训练的参数。格式为一个TSV file (tab分割),第一行包含列名(见粗体)随后的行包含了metadata的值:
1
2
3
4
Word\tFrequency
Airplane\t345
Car\t241
...
在主要的数据文件中没有显式的key;相反的,在metadata中的顺序假设与emebedding tensor中的顺序相匹配。也就是说,第一行是header信息,第(i+1)行对应于checkpoint中存储的第i行的embedding tensor.
注意: 如果TSV metadata文件只具有单列,那就不希望有一个header行,假高每行都是embedding的label。我们包含了该exception,因为它与常用的vocab file格式相匹配
图片
如果你有图片与你的embedding相关联,你需要生成单个图片,它包含了每个data point的小的缩略图(thumbnails)。这被称为是“精灵图(sprite image)”。这种sprite 具有相同的行和列,thumbnails会存在第一行优化的次序上:第一个data point位于左上角,最后一个data point位于右下角。
1
2
3
0 1 2
3 4 5
6 7
注意:在上述的示例中,最后一行没有被填满。关于sprite的一个具体的样本,详见:10,000 MNIST digits (100x100)的sprite image
{kind=link}
**注意:当前我们支持的sprites的上限为:8192px X 8192px **
在构建了sprite之后,你需要告诉Embedding Projector在哪里能找到:
embedding.sprite.image_path = PATH_TO_SPRITE_IMAGE
# Specify the width and height of a single thumbnail.
embedding.sprite.single_image_dim.extend([w, h])交互
Embedding Projector具有三个panels:
-
- Data panel:
-
- Projections panel:
-
- Inspector panel:
Projections
Embedding Projector具有三种方法来降维数据集:两种线性,一种非线性。每个方法可以被用于创建一个2D或3D的view。
- PCA: PCA是一种简单的降维技术。Embedding Projector计算了top 10个主成分。菜单让你投影这些成分到任意的2的组合或3的组合。PCA是一种线性投影,在检查全局几何分布时很有效。
- t-SNE: 一种流行的非线性降维。Embedding Projector 支持2D和3D的t-SNE views。在算法的每一步,在客户端都会执行Layout。 t-SNE经常保存一些本地结构,对于探索局部近邻和寻找聚类很有用。尽管对于可视化高维数据很有用, t-SNE 有时会mysterious和misleading。详见此文
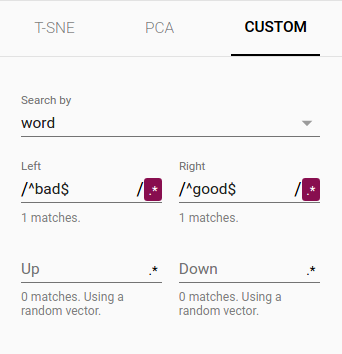
- Custom: 你也可以基于文本搜索构建专有的线性投影,来寻找在空间中有意义的方向。为了定义一个投影轴,输入两个搜索strings或者常规表达式。该程序会计算匹配到这些搜索点集的图心(centroids),在图心间使用不同的vector作为一个投影轴。
Navigation
为了探索一个数据集,你可以以2D或3D模式、缩放、旋转,使用拖放来导航views。在某个点上点击会造成右边面板展示一个显式的关于最近邻的文本列表,以及它与当前点的距离。最近邻点被在投影上高亮。
聚类缩放会给出一些信息,但有时将视图(view)限制到一个点的子集中,并对这些点做投影。你可以用以下方式选择这些点:
- 1.在点击某个点后,它的最近邻也会被选中
- 2.在执行一次搜索后,匹配该query的点也会被选中
- 3.在开启选择后,点中某个点并拖拽它来定义一个选择区
在选中了点集后,你可以在右侧Inspector面板使用“Isolate Points”按钮,来孤立这些点来进一步做分析。
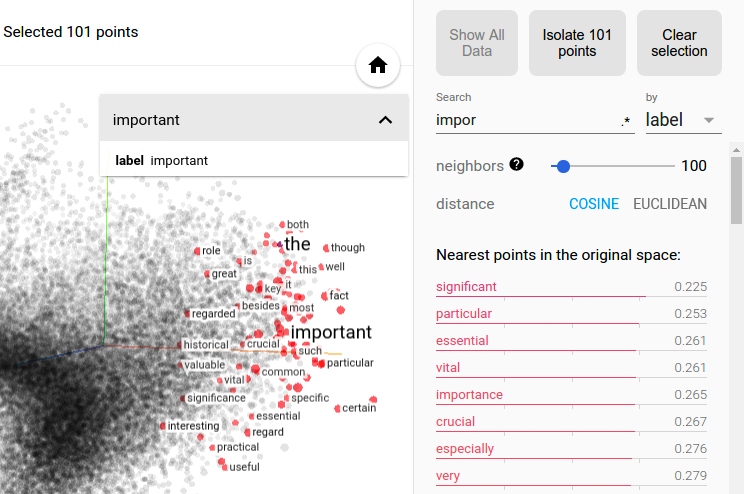
可以用多种过滤组合来定制投影,这十分强大。下面,我们过滤了”politics”的100个最近邻,并将它们投影到“best” - “worst”向量作为一个x轴。y轴是随机的。
你可以见到,在右侧我们具有“ideas”, “science”, “perspective”, “journalism” ,而左侧: “crisis”, “violence” and “conflict”.
协同特征
为了共享你的发现,你可以使用底部右下角的bookmark面板,保存当前状态(包含所有投影的计算坐标)为一个小文件。Projector接着指向一个一或多文件的集合,通过下面的面板产生。其它用户接着可以通过一串bookmarks进行漫步。

FAQ
“embedding”是一个action还是一个thing?
两者都是。在向量空间中的embedding words(action),产生的word embeddings(thing)。
embeddings是高维还是低维?
具体看情况。例如,一个300维的关于words和phrases的向量空间,当对比于包含百万words和phrases时,经常被称为“低维(dense)”。但数学上它是高维的。
embedding与embedding layer相同吗?
不是。一个embedding layer是NN的一部分,而一个embedding更多是个概念。