1. Pipeline的主要概念
MLlib为机器学习算法提供了标准API,使得它们很容易将多个算法相互组合到一个pipeline中,或者workflow中。该部分覆盖了Pipeline API的关键概念,pipeline的概念中的大多数灵感主要来自于sklearn项目。
- DataFrame: 该ML API使用Spark SQL的DataFrame作为ML的数据集,它可以存储许多类型的数据。比如:一个DataFrame可以具有不同列的存储文本,特征向量,true labels以及predictions。
- Transformer: 一个Transformer是这样一个算法:它可以将一个DataFrame转换成另一个DataFrame。比如:一个ML的model就是一个Transformer,它将一个带有features的DataFrame转换成一个带有predictions的DataFrame。
- Estimator:一个Estimator是这样的一个算法:它可以在一个DataFrame进行fit操作,生成一个Transformer。比如:一个学习算法就是一个Estimator,它可以在一个DataFrame里进行训练,生成一个model。
- Pipeline:Pipeline可以将多个Transformer和Estimator进行链式串联在一起,形成一个ML workflow。
- Parameter: 所有的Transformer和Estimator现在都共享一个公共的API来指定参数。
2.DataFrame
机器学习算法可以被应用在许多种数据类型上,比如:vector, text, image和结构化数据。该API复用了Spark SQL中的DataFrame,为了支持多种类型的数据。
DataFrame支持许多基本类型和结构化类型:可以详见Spark SQL datatype reference。除了Spark SQL guide列出的类型外,DataFrame还可以使用ML中的Vector类型。
DataFrame可以从一个常规的RDD进行显式或隐式的创建,示例代码详见[Spark SQL programming guide] (http://spark.apache.org/docs/latest/sql-programming-guide.html)
DataFrame的列可以带有名字。下面的示例代码中会使用这样的名字:”text”, “features”, “label”。
3.Pipeline components
3.1 Transformer
Transformer是一个抽象,它包含:特征转换器(feature transformer)和机器学习模型(learned model).技术上,一个Transformer实现了一个transform()方法,它可以将一个DataFrame转换成另一个,通常会附加一或多列。例如:
- feature transformer:可以采用一个DataFrame作为参数,读取一列(比如:text),将它映射到一个新列上(比如:feature vectors),输出一个新的带有新映射列的DataFrame。
- learning model:可以传入一个DataFrame参数,读取包含feature vectors的列,预测每个feature vector的label,输出一个新的带有预测label附加列的DataFrame。
3.2 Estimator
Estimator抽象了一个学习算法或其它可以在数据上进行fit或train的算法。技术上,一个Estimator实现了fit()方法,它接受一个DataFrame作为参数,并产生一个Model,该Model是一个Transformer。例如,像LogisticRegression这样的学习算法就是一个Estimator,调用fit()方法训练得到一个LogisticRegressionModel,该Model就是一个Transformer。
3.3 pipeline组件的属性
Transformer.transform() 和 Estimator.fit()都是无状态的。在后续的版本中,会通过其它概念支持有状态的算法。
Transformer 或 Estimator的每个实例都有一个唯一ID。它在特定参数上很有用。
4 Pipeline
在机器学习中,运行一串算法来处理和学习数据是很常见的。比如:一个简单的文本文档处理工作流就可能包含几个阶段(Stage):
- 将每个文档的text分割成words
- 将每个文档的words转换成numerical feature vector
- 使用该feature vectors和labels学习一个预测模型
MLlib将这样的工作流表示成Pipeline,它包含了一串PipelineStage(Transformer 和 Estimator),以指定的顺序运行。我们将使用一个简单的workflow来运行一个示例。
4.1 工作机制
Pipeline可以指定一串stage,每个stage可以是一个Transformer 或 Estimator。这些stage会顺序运行,输入的DataFrame被转换,然后传到下一stage。对于Transformer的stage,它会在DataFrame上调用transform()方法。对于Estimator的stage,会调用fit()方法来产生Transformer(它成为PipelineModel的一部分,或成为Pipeline.fit的参数),接着Transformer会在DataFrame上调用transform() 方法。
我们演示了这样的一个工作流,下图就是Pipeline的训练时的阶段:
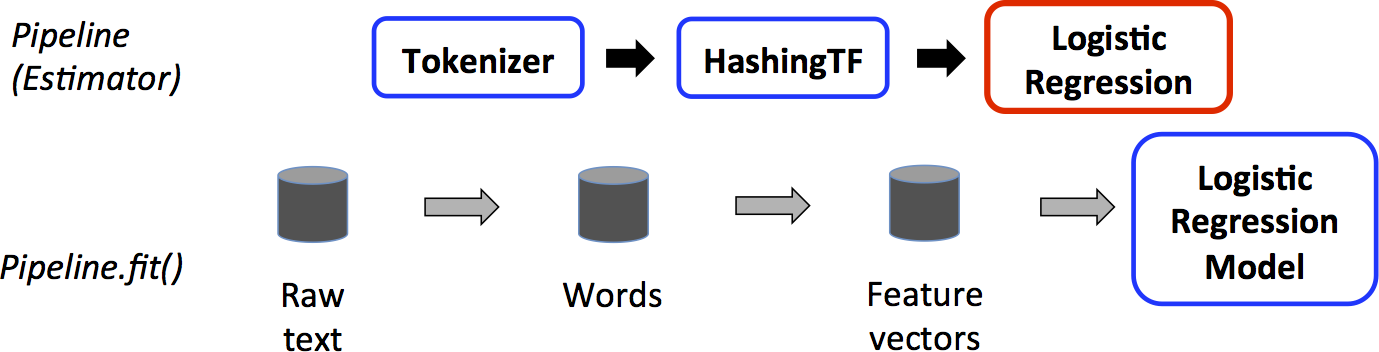
上图中,顶行表示了一个包含三个stage的Pipeline。前两个为(Tokenizer 和 HashingTF)是Transformer(蓝色),第3个(LogisticRegression)是一个Estimator(red)。底行表示整个pipeline的数据流,圆柱型表示DataFrame。Pipeline.fit()方法会被原始的DataFrame进行调用,它具有原始的文本文档和label。接着Tokenizer.transform()会将原始文本文档分割成words,添加一个关于words的新列到DataFrame上。HashingTF.transform()方法将words列转换成feature vector,会另添加一行关于该vectors的新列到DataFrame上。由于LogisticRegression是一个Estimator,Pipeline会首先调用LogisticRegression.fit() 产生一个LogisticRegressionModel。如果Pipeline具有多个stage,它可以在DataFrame上调用LogisticRegressionModel的transform()方法,然后将DataFrame传到下一stage。
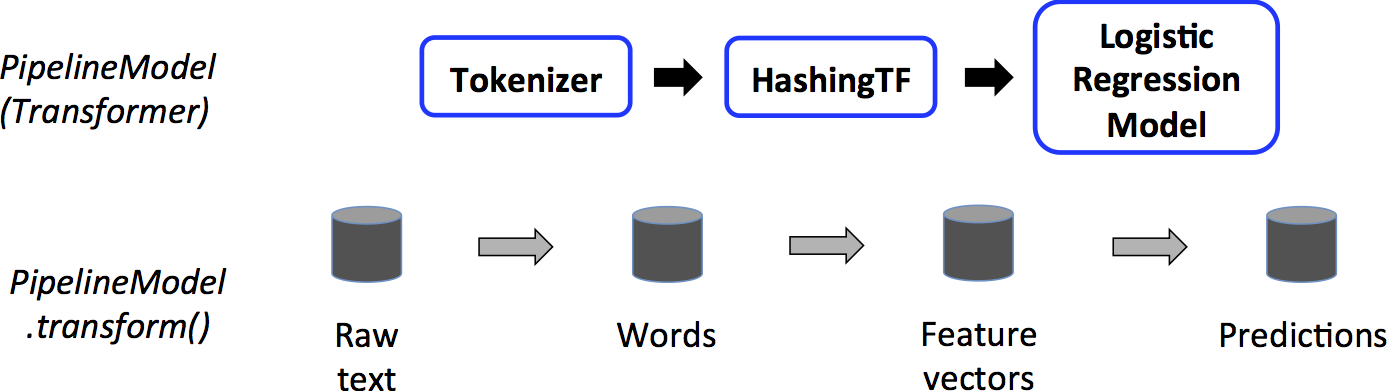
在上图中,和原先的Pipeline相比,PipelineModel具有相同数量的stage,但是在原先Pipeline上的所有Estimator都变成了Transformer。当在一个测试数据集上调用PipelineModel的transform() 方法时,传入的数据按顺序通过fit后的Pipeline。每一stage的transform() 方法会更新数据集,并将它传到下一stage。
Pipelines 和 PipelineModel帮助确保训练和测试数据传到feature处理阶段顺利进行。
4.2 细节
DAG Pipeline:一个Pipeline的stage以一个有序数组的方式实现。这里给的示例都是线性Pipeline。如果数据流图形成了一个DAG(有向无环图),也有可能创建非线性Pipeline。这种图在当前版本中,需要通过在每个stage上的输入和输出列名上进行隐式指定(通常作为参数)。如果一个Pipeline形成了一个DAG,接着,相应的stage必须以拓扑顺序进行指定。
Runtime checking:由于Pipeline可以在DataFrame上操作多种类型,它们不能使用compile-time类型检查。在实际运行Pipeline时,Pipeline和 PipelineModel会做runtime-checking。该类型的checking使用DataFrame schema来完成。
Unique Pipeline stages:一个Pipeline的各stage都应该是唯一的实例。例如:myHashingTF的相同实例不应该被两次插入到Pipeline,因为Pipeline的stage必须具有唯一的ID。然而,myHashingTF1和myHashingTF2是不同实例(都是HashingTF类型),可以放到相同的Pipeline上,因为它们通过不同的ID进行创建。
4.3 参数
MLlib的Estimator和Transformer使用一个统一的API来指定参数。
Param是一个具有自包含文档的有名参数。一个ParamMap是一个(param,value) pairs的集合。
有两种主要方法来传参给一个算法:
- 1.给一个实例设置参数。比如:如果lr是LogisticRegression的一个实例,你可以调用lr.setMaxIter(10),让lr.fit()时使用至多10次迭代。该API可以在spark.mllib包中提供。
- 2.传递一个ParamMap来进行fit()或transform()。ParamMap的任何参数都会覆盖之前通过setter方法指定的参数。
Estimator和Transformer的特定实例需要参数。例如:LogisticRegression具有两个实例:lr1和lr2,我们需要构建一个ParamMap,两者都需要maxIter参数:ParamMap(lr1.maxIter -> 10, lr2.maxIter -> 20)。如果一个Pipeline中有两个带有maxIter参数的算法时,会很管用。
4.4 保存和加载Pipeline
通常,保存一个模型,或者一个Pipeline到磁盘中会很有用。在Spark 1.6中,在Pipeline API中添加了一个模型的import/export函数。大多数基本的transformer都支持,还有一些基本的ML model也支持,详见算法的API文档。
4.5 代码示例:
示例:Estimator/Transformer/Param
import org.apache.spark.ml.classification.LogisticRegression
import org.apache.spark.ml.linalg.{Vector, Vectors}
import org.apache.spark.ml.param.ParamMap
import org.apache.spark.sql.Row
// Prepare training data from a list of (label, features) tuples.
val training = spark.createDataFrame(Seq(
(1.0, Vectors.dense(0.0, 1.1, 0.1)),
(0.0, Vectors.dense(2.0, 1.0, -1.0)),
(0.0, Vectors.dense(2.0, 1.3, 1.0)),
(1.0, Vectors.dense(0.0, 1.2, -0.5))
)).toDF("label", "features")
// Create a LogisticRegression instance. This instance is an Estimator.
val lr = new LogisticRegression()
// Print out the parameters, documentation, and any default values.
println("LogisticRegression parameters:\n" + lr.explainParams() + "\n")
// We may set parameters using setter methods.
lr.setMaxIter(10)
.setRegParam(0.01)
// Learn a LogisticRegression model. This uses the parameters stored in lr.
val model1 = lr.fit(training)
// Since model1 is a Model (i.e., a Transformer produced by an Estimator),
// we can view the parameters it used during fit().
// This prints the parameter (name: value) pairs, where names are unique IDs for this
// LogisticRegression instance.
println("Model 1 was fit using parameters: " + model1.parent.extractParamMap)
// We may alternatively specify parameters using a ParamMap,
// which supports several methods for specifying parameters.
val paramMap = ParamMap(lr.maxIter -> 20)
.put(lr.maxIter, 30) // Specify 1 Param. This overwrites the original maxIter.
.put(lr.regParam -> 0.1, lr.threshold -> 0.55) // Specify multiple Params.
// One can also combine ParamMaps.
val paramMap2 = ParamMap(lr.probabilityCol -> "myProbability") // Change output column name.
val paramMapCombined = paramMap ++ paramMap2
// Now learn a new model using the paramMapCombined parameters.
// paramMapCombined overrides all parameters set earlier via lr.set* methods.
val model2 = lr.fit(training, paramMapCombined)
println("Model 2 was fit using parameters: " + model2.parent.extractParamMap)
// Prepare test data.
val test = spark.createDataFrame(Seq(
(1.0, Vectors.dense(-1.0, 1.5, 1.3)),
(0.0, Vectors.dense(3.0, 2.0, -0.1)),
(1.0, Vectors.dense(0.0, 2.2, -1.5))
)).toDF("label", "features")
// Make predictions on test data using the Transformer.transform() method.
// LogisticRegression.transform will only use the 'features' column.
// Note that model2.transform() outputs a 'myProbability' column instead of the usual
// 'probability' column since we renamed the lr.probabilityCol parameter previously.
model2.transform(test)
.select("features", "label", "myProbability", "prediction")
.collect()
.foreach { case Row(features: Vector, label: Double, prob: Vector, prediction: Double) =>
println(s"($features, $label) -> prob=$prob, prediction=$prediction")
}详见代码:examples/src/main/scala/org/apache/spark/examples/ml/EstimatorTransformerParamExample.scala
示例:Pipeline
import org.apache.spark.ml.{Pipeline, PipelineModel}
import org.apache.spark.ml.classification.LogisticRegression
import org.apache.spark.ml.feature.{HashingTF, Tokenizer}
import org.apache.spark.ml.linalg.Vector
import org.apache.spark.sql.Row
// Prepare training documents from a list of (id, text, label) tuples.
val training = spark.createDataFrame(Seq(
(0L, "a b c d e spark", 1.0),
(1L, "b d", 0.0),
(2L, "spark f g h", 1.0),
(3L, "hadoop mapreduce", 0.0)
)).toDF("id", "text", "label")
// Configure an ML pipeline, which consists of three stages: tokenizer, hashingTF, and lr.
val tokenizer = new Tokenizer()
.setInputCol("text")
.setOutputCol("words")
val hashingTF = new HashingTF()
.setNumFeatures(1000)
.setInputCol(tokenizer.getOutputCol)
.setOutputCol("features")
val lr = new LogisticRegression()
.setMaxIter(10)
.setRegParam(0.01)
val pipeline = new Pipeline()
.setStages(Array(tokenizer, hashingTF, lr))
// Fit the pipeline to training documents.
val model = pipeline.fit(training)
// Now we can optionally save the fitted pipeline to disk
model.write.overwrite().save("/tmp/spark-logistic-regression-model")
// We can also save this unfit pipeline to disk
pipeline.write.overwrite().save("/tmp/unfit-lr-model")
// And load it back in during production
val sameModel = PipelineModel.load("/tmp/spark-logistic-regression-model")
// Prepare test documents, which are unlabeled (id, text) tuples.
val test = spark.createDataFrame(Seq(
(4L, "spark i j k"),
(5L, "l m n"),
(6L, "mapreduce spark"),
(7L, "apache hadoop")
)).toDF("id", "text")
// Make predictions on test documents.
model.transform(test)
.select("id", "text", "probability", "prediction")
.collect()
.foreach { case Row(id: Long, text: String, prob: Vector, prediction: Double) =>
println(s"($id, $text) --> prob=$prob, prediction=$prediction")
}参考: