我们来看下gravityR&D提出的《SESSION-BASED RECOMMENDATIONS WITH RECURRENT NEURAL NETWORKS》。
2.相关工作
2.1 session-based的推荐
推荐系统领域的大多数工作主要关注于建模:当提供一个用户id时,可以为它构建一个明确的user profile。在该setting中,相应的文献主要是MF方法和基于近邻的模型。这些方法可以在session-based recommendation中采用;当缺失user profile时,一个很自然的解决方案是:item-to-item推荐方法。在该setting中,会从提供的session数据中预计算好item-to-item的相似度矩阵,也就是说:经常在sessions中一起被点击的这些items,被认为是相似的。相似矩阵接着在session期间被简单用于:为一个当前用户所点击的项推荐最相似的items。该方法被证明是有效的,并被广泛使用。这些方法只能说明用户的最近点击行为,实际上忽略了过去点击的行为。
对于session-based推荐,一些不同的方法有:Markov决策过程(MDP: Markov Decision Processes)。MDP是顺序随机决策问题的模型。
一个MDP被定义成一个4元组 \(<S, A, Rwd, tr>\),其中:
- S是状态集(state)
- A是动作集(action)
- Rwd是一个reward函数
- tr是状态转移函数
在推荐系统中,动作(action)等价于推荐,最简单的MPDs本质上是一阶Markov链,其中下一个推荐可以根据item间的转移概率被简单计算。在session-based推荐中使用Markov链的主要问题是:当尝试包含所有可能的用户选择序列时,状态空间很快变成不可管理。
通用因子分解框架(GFF: General Factorization Framework)的扩展版本可以使用session data进行推荐。它会通过将这些事件进行求和(sum)来建模一个session。它使用两种类型的隐表示:一种用于表示item自身,另一种用于将item表示成一个session的部分。session接着被表示成关于part-of-a-session的item表示的feature vectors的平均。然而,该方法不会考虑任何在session中的顺序。
2.2 Deep learning推荐
最近在神经网络文献中的一个相关方法,它使用受限波尔茨曼机(RBM)进行CF计算(Salakhutdinov et al., 2007)。在该工作中,一个RBM被用于建模user-item交互并执行推荐。该模型已经被证明是最好的CF模型之一。Deep模型已经被用于从非结构化内容中(比如:音乐、图片)抽取特征,接着被一起用于更通用的CF模型。在(Van den Oord et al.2013) 中,使用一个CNN来从音乐文件中抽取特征,接着被用在一个因子模型中(factor model)。最近(Wang et al.2015)引入了一个更通用的方法,它使用一个深度网络来从任意类型的items中抽取通用内容特征,这些特征接着被合并到一个标准的CF模型中来增强推荐效果。该方法看起来特别有用,尤其是在没有足够多的user-item交互信息时。
3.使用RNN的推荐
RNN可以建模变长序列数据。在RNN和传统前馈深度模型间的主要不同之处是,在构成网络的units中存在一个内部隐状态(hidden state)。标准RNN会更新它们的隐状态h,它使用以下的更新函数:
\[h_t = g(W x_t + U h_{t-1})\]…(1)
其中:
- g是一个平滑边界函数(比如:使用一个logistic sigmoid函数)
- \(x_t\)是在时间t上unit的input
- 给定它的当前状态\(h_t\), 一个RNN会输出:关于该序列的下一个元素的一个概率分布
GRU是一个关于一个RNN unit的更精巧的模型。它的目标是,解决梯度消失问题(vanishing gradient problem)。GRU gate本质上会学习何时(when)以及多大(how much)进行更新unit的hidden state。GRU的activation是一个在之前activation和候选activation \(\hat{h_t}\)上的线性插值。
\[h_t = (1-z_t) h_{t-1} + z_t \hat{h}_t\]…(2)
其中update gate为:
\[z_t = \sigma(W_z x_t + U_z h_{t-1})\]…(3)
其中,cadidate activation函数\(\hat{h}_t\)以相似方法进行计算:
\[\hat{h}_t = tanh(W x_t + U(r_t \odot h_{t-1}))\]…(4)
最后,reset gate的\(r_t\)为:
\[r_t = \sigma(W_r x_t + U_r h_{t-1})\]…(5)
3.1 定制GRU模型
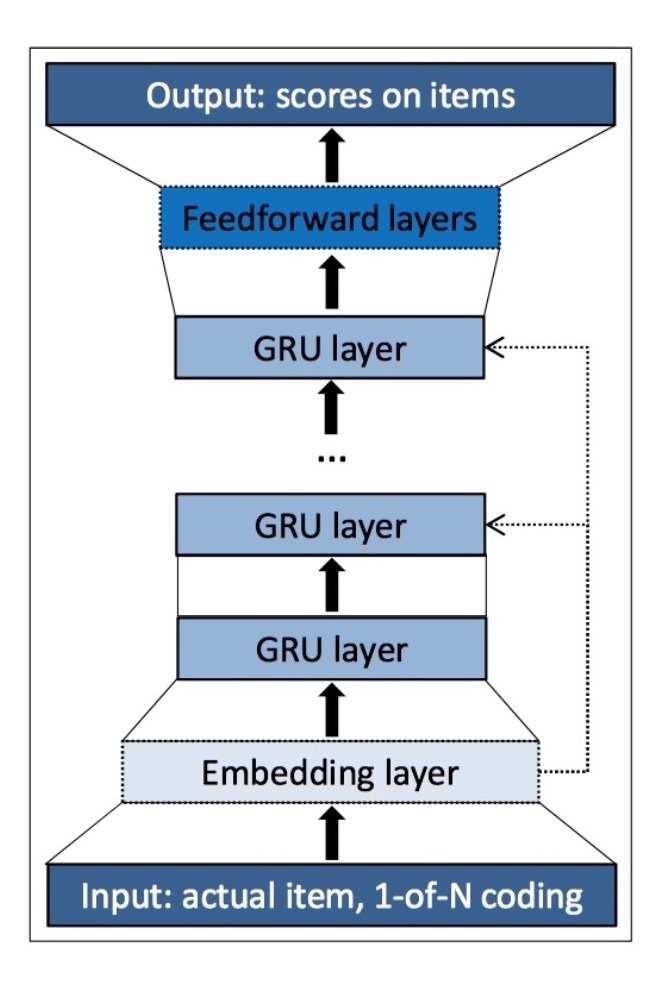
图1: 网络的通用结构。一次只处理事件流中的一个事件(event)
我们在我们的模型中使用GRU-based RNN来进行session-based推荐。网络的输入是该session的实际状态(state),而输出为在session中item的下一个事件(event)。到目前为止,该session的state可以是item的实际event或在session中的events。在前面的case中使用1-of-N的编码,例如,输出向量的长度实际为items数目,只有在对应于实际item的位置上为1,其它为0。后面的setting中会使用一个关于这些表示(representations)的加权和,如果events在更早前发生,那么它会降权(discounted)。出于稳定,输出向量接着会被归一化(normalized)。我们期望这会有帮助,因为它增强了记忆效应(memory effect):而非常局部顺序限制(very local ordering constraints)的增强则并不能被RNN的更长期记忆所捕获。我们也实验了其它方法: 通过增加一个额外的embedding layer,但1-of-N encoding的效果更好。
该网络的核心是:GRU layer(s)、以及额外的feed-forward layers(可以在最后一层和output间进行添加)。输出为items的预测偏好,例如,在session中对于每个item成为下一个被推荐的似然。当使用多个GRU layers时,前一layer的hidden state是下一layer的input。该input也可以可选地被连接到在网络中更深的GRU layers上,我们发现这确实能提升性能。整体架构如图1所示,它描述了单个event在events时间序列中的表示(representation)。
由于推荐系统并不是RNN的主要应用领域,我们修改了基础网络让它更好地适合推荐任务。我们也考虑到实际点以便我们的解决方案可以应用到一个现实环境上。
3.1.1 session-parallel mini-batches
NLP任务中的RNN通常使用in-sequence mini-batches。例如,很常用的是使用一个slide window来滑过句子中的词,并将这些window化的片段相互挨着来构成mini-batches。这种方法对于我们的任务来说不合适,因为:
- (1) sessions的长度可能非常不同,甚至比句子还要更不同:一些sessions可能只有2个events,而其它可能有上百个;
- (2) 我们的目标是,捕获一个session在时序上的演进,因此将它们分割成片段可能会没有意义
因此,我们使用session-parallel mini-batches。首先,我们为该sessions创建一个顺序(order)。接着,我们使用前X个sessions的第一个event来形成首个mini-batch的input(期望的output为我们的active sessions的第二个events)。第二个mini-batch会从第二个events来生成,自此类推。如果sessions的任意一个结束,下一个可提供的session会补上它的位置。Sessions被认为是相互独立的,因此,当该切换发生时,我们会重置(reset)合适的hidden state。如图2所示。
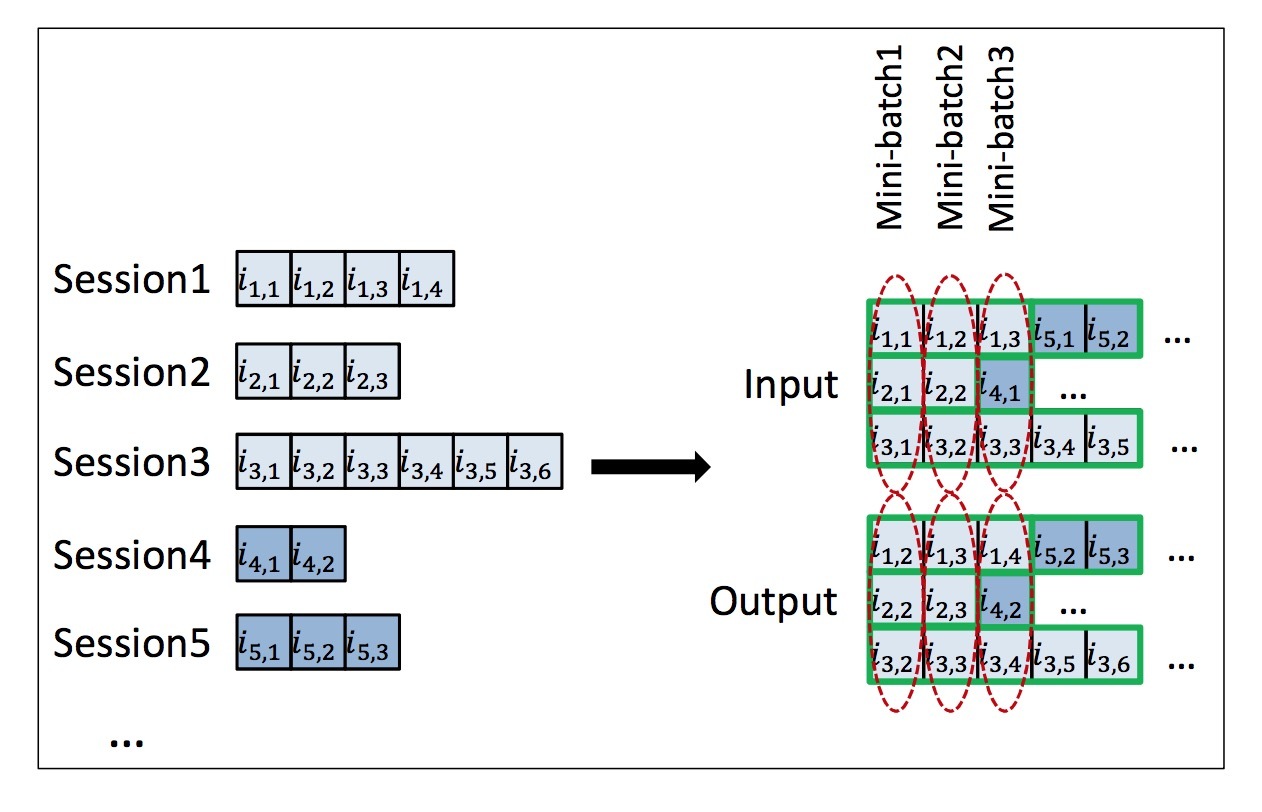
图2: session-parallel mini-batch creation
3.1.2 在output上进行sampling
当items数目很大时,推荐系统特别有用。对于一个中级规模(medium-sized)的网上商店来说,它的items范围可能是成千上万,但对于一个更大网络来说,可能有上百万items。在每一step为每个item计算一个score,会让算法与items数和events数的乘积成比例增长。这在实际上是不可行的。因此,我们必须对output进行抽样,只对items某个子集计算score。这也只有一些权重会被更新。除了期望的output之外,我们需要为一些负样本计算scores,并修改权重以便期望的output的排序更靠前。
对于一个任意missing event的天然解释是,用户不知道该item的存在,因而没有任何交互。然而,如果某用户不知道该item并选择不与之交互,是因为她不喜欢(dislike)该item,这种情况的概率很低。item越流行,用户越可能知道它,因此一个missing event更可能会传达dislike的意味。因此,我们应根据它们的流行度成比例抽样。我们并不会为每个训练样本(training example)生成独立(separate)的抽样(samples),而是选择:使用从该mini-batch中的其它训练样本的items来当成负样本。该方法的好处是,我们可以通过跳过抽样(sampling)来进一步减小计算时间。另外,这也可以从实现侧受益,可以让该代码更简单些,以便进行更快的矩阵操作。同时,该操作也是一个基于流行度的抽样(popularity-based sampling),因为一个item成为该mini-batch中的其它训练样本的似然概率(likelihood),与它的流行度成正比。
3.1.3 ranking loss
推荐系统的核心是items的相关度排序(relevance-based)。尽管该任务可以被解释成一个分类任务,l2r方法通常要好于其它方法。ranking可以是pointwise,pairwise和listwise。pointwise ranking会独立的估计items的score或者rank,它的loss定义的目的是相关items的rank应较小(low)。pairwise ranking会比较一个positive和一个negative item pairs的score或rank,该loss会增强:positive item的rank应低于negative item的rank。Listwise ranking使用所有items的scores和ranks,并比较它们的顺序。由于它包含了排序(sorting),通常计算开销更大,并不常使用。同时,如果只有一个相关item(例如:在我们的case中)——listwise ranking可以通过pairwise ranking进行解决。
我们在我们的解决方案中包含了一些pointwise和pairwise ranking losses。我们发现,pointwise ranking对于网络不是稳定的(见第4节)。pairwise ranking losses在其它方法更胜一筹。我们使用以下的两个:
- BPR:Bayesian Personalized Ranking (Randle et al., 2009)是一个矩阵因子方法,它使用pairwise ranking loss。它会比较一个positive和一个sampled negative item的score。这里,我们比较了positive item与一些sampled items的scores,并使用它们的平均作为loss。在一个session中对于某个结定点的该loss定义如下:
其中,\(N_s\)是sample size,\(\hat{r}_{s,k}\)是在item k上在该session的给定点的score,i是期望的item(在session中下一item),j是负样本(negative samples)。
- TOP1: 该ranking loss由我们提出。它是关于相关项的相对rank的正则近似。相关item的相对rank由\(\frac{1}{N_s} \cdot \sum\limits_{j=1}^{N_s} I\lbrace \hat{r}_{s,j} > \hat{r}_{s,i} \rbrace\)给定。我们使用一个sigmoid来近似\(I\lbrace \cdot \rbrace\)。这的最优化可以修改参数,以便i的score能高些。然而,这是不稳定的,因为特定positive items也扮演着负样本的角色,因为scores趋向于变得增长更高。为了避免这种情况,我们希望强制负样本的scores在零周围。这是对negative items的scores的一种自然期望。因而,我们添加到一个正则项到该loss中。很重要的是,在相同范围内的该term作为相对rank很重要,。最终的loss function如下所示:
4.实验
我们在两个数据集上,对rnn与其它流行的baslines进和对比。
第一个数据集是RecSys Challenge 2015. 该数据集包含了一个商业网站的click-streams,有时以购买事件结尾。我们会使用该比赛的trainset,只保留点击事件。我们过滤掉了长度为1的session。该网络使用〜6个月的数据进行训练,包含了7,966,257 sessions,在37,483个items上的31,637,239 clicks。我们使用后续天的sessions进行testing。每个session被分配给trainset或testset两者之一。由于CF方法的天性,我们会从testset中过滤出那些item点击并不在trainset中的点击。长度为1的Session也会从testset中移除。在预处理后,对于testset,我们留下了大约15324个session,它具有71222个events。该数据集被称为RSC15.
第二个数据集从Youtube-like OTT视频服务平台上收集。我们收集了在一段时间内关于观看vidio的events。只有特定范围会被归到该collection中:最近2个月。在这段时间内,每个视频后的屏幕左侧会提供item-to-item的推荐。这些items由不同算法选择得到,它们受用户行为的影响。预处理阶段与其它数据集相似,会过滤非常长的sessions,因为它们可能由机器生成。训练数据包含了所有,上述周期的最后一天。具有300w的sessions,具有在33w视频上的13w的watch events。testset包含了之前提的,具有~3.7w的sessions,~18w的watch events。该数据集被称为“VIDEO”。
评估(evaluation)通过挨个提供一个session的events,并确认下一event中该item的rank来完成。GRU的hidden state在一个session完成后会被重置为0. items通过它们的score以降序排序,在该list中它们的位置就是它们的rank。对于RSC15数据集, trainset中所有37483个items会被排序。然而,这对于VIDEO数据集是不现实的,因为items的数目很大。这里我们会对期望的item vs. 最流行的30000 items进行排序。这对于evaluation会有很小的影响,很少被访问的items经常获得较低分数。同时,基于流行度的预过滤在实际的推荐系统中很常见。
由于推荐系统一次只会推荐很少的items,一个用户可能选取的实际item应与在列表中的头几个items之中。因此,我们主要的评估指标是recall@20,也就是说,在所有test cases中,所期望item在top20之内的cases的比例。recall不考虑item的实际rank,只需要topN之内即可。这会建模实际场景,其中没有强调推荐,不关心绝对顺序。recall也通常与重要的online KPIs(比如:CTR)相关。第二个在实验中使用的metric是MRR@20 (Mean Reciprocal Rank)。这是关于所期望items的相互排序(reciprocal ranks)的平均。如果该rank超过20, 则reciprocal rank被置为0. MRR会解释该item的rank,在推荐顺序比较关注的情况下,这指标是重要的。(例如:低rank的items只会在滑动后可见)
4.1 Baselines
我们比较了该网络与一些其它baselines。
- POP: 流行度预测,总是推荐训练集中最流行的items。它通常在特定领域内是一个较强的baseline。
- S-POP:该baseline会推荐当前session的最流行items。推荐列表会在session期间随着items获得更多events而进行变化。使用全局流行度值可以突破束缚。该baseline在该领域很强,有较高的重复性。
- Item-KNN:与实际item相似的Item可以通过该baseline被推荐,相似度的定义通过他们sessions向量间的cosine相似度来定义,例如:在sessions中两个items的共现次数,除以各自单个items出现所在的sessions数目的乘积的平方根。可以进行正则化,避免较少访问items的高相似度。该baseline是在实际系统中最常用的item-to-item解决方案,它提供给推荐系统这样的setting:观看了该item的其它人也会观看这些item。尽管它很简单,但它通常是一个较强的baseline。
- BPR-MF:BPR-MF是一个常用的MF方法。它会为一个pairwise ranking目标函数通过SGD进行最优化。矩阵分解不能直接应用到session-based推荐上,因为新的sessions不会具有预计算好的特征向量。然而,我们可以通过使用在session中出现过的item的feature vectors的平均向量来克服这个问题。换句话说,在一个可推荐item和session的items间的特征向量的相似度进行求平均。