我们来看下tensorflow的rnn_cell.DropoutWrapper的实现原理:《A Theoretically Grounded Application of Dropout in Recurrent Neural Networks》,在rnn上使用dropout。
摘要
RNN是深度学习许多研究的前研。这些模型的主要难点是容易overfit,直接在recurrent layers上应用dropout会失败。在Bayesian建模和深度学习的交叉研究上,提供了一种通用深度学习技术(比如:dropout)的Bayesian解释。在approximate Bayesian inference上的dropout基础,提供了一种理论扩展,并提供了在RNN模型上使用dropout的见解。我们在LSTM和GRU模型中基于dropout技术来使用这种新的变分推断(variantional inference),并将它应用于语言建模和语义分析任务上。新的方法要好于已存在的技术,并达到最好的效果。
1.介绍
RNN是基于序列的模型,是NLP、语言生成、视频处理、以及许多其它任务上的关键。模型的输入是一个符号序列,在每个timestep上,会将一个RNN unit应用于单个symbol,该网络的输出会使用来自之前的time step的信息。RNN很强,但很容易overfit。由于在RNN模型中缺乏正则化,使得它很难处理小数据,为了避免overfitting,研究者们通常会使用:early-stopping、或者小模型。
Dropout是深度网络中很流行的正则技术,其中在训练期间network units会被随机masked(dropped),但该技术从未在RNNs上成功应用过。经验表明:添加到recurrent layers上的噪声(在RNN units间的connections)会因序列过长而被放大,从而盖过信号本身。因而,一些研究得出结论:该技术只能在RNN的inputs和outputs上使用[4,7,10]。但这种方法在我们的实验中仍会导致overfitting。
最近在Bayesian和深度学习的交叉研究的最新结果提供了:通过Bayesian视角来解释常见的deep learning技术[11-16]。深度学习的Baeysian视度将这些新技术引入到该领域,比如:从深度学习网络中获得原则不确定估计(principled uncertainty estimates)。例如,Gal and Ghahramani展示了dropout可以被解释成一个Bayesian NN的后验的变分近似。这种变化近似分布是两个具有较小方差的高斯分布的混合,其中一个Gaussian的均值固定为0. 在approximate Bayesian inference中的dropout的基础扩展了理论,提供了新的视角来在RNN模型上使用这些技术。
这里我们关注常见的RNN模型(LSTM, GRU),并将它们解释成概率模型,比如:RNN的网络权重看成是随机变量,并定义了likelihood函数。我们接着在这些概率Bayesian模型上执行近似变化推断(我们称之为:Variational RNNs)。使用高斯混合的在权重的后验分布上的近似,会产生一个可跟踪的最优化目标函数。对该objective最优化等同于在各自RNNs上执行一个新的dropout变种。
在新的dropout variant中,我们会在每个timestep上对inputs、outputs、recurrent layers(在每个time step上drop相同的network units)重复相同的dropout mask。与已经存在的专有(ad-hoc)技术相比,在每个timestep上,对inputs、outputs各自采用不同的dropout masks抽样(在recurrent connections上不使用dropout,因为在这些connections上使用不同的masks会导致很差的效果)。我们的方法和与现有技术的关系如图1所示。当使用离散输入(比如:words)时,我们也会在word embeddings上放置一个分布。在word-based模型中的dropout接着会随机drop掉句子中的word types,并被解释成:对于该任务,强制该模型不依赖于单个words。
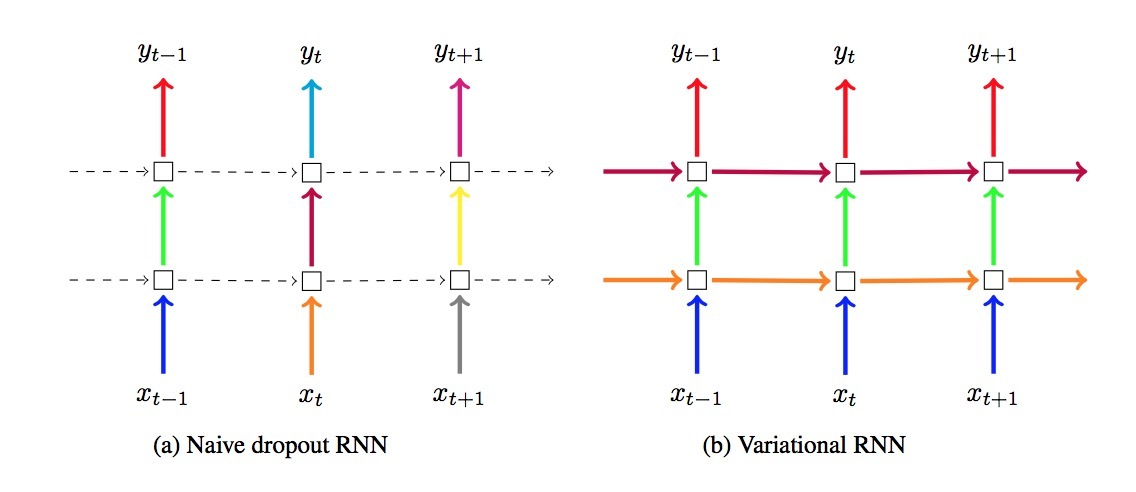
图1 dropout技术。(左):标准dropout (右): Bayesian解释的dropout. 每个方块表示一个RNN unit,水平键头表示时间依存关系(recurrent connections)。垂直键头表示每个RNN unit的input和output。带颜色的连接(connections)表示dropped-out inputs;不同颜色表示不同的dropout masks。虚线表示没有dropout的标准connections。当前技术(naive dropout, 左)在不同time steps上使用不同的masks,而在recurrent layers上没有dropout。提出的技术(Variational RNN, 右)在每个timestep上使用相同的dropout mask,包括recurrent layers
我们接着研究了相关的文献和资料,将我们的Variational RNN的近似推断进行公式化,产生提出的dropout变种。实验结果在随后给出。
2.相关研究
3.背景
我们会回顾下Bayesian神经网络和近似变分推断的背景知识。基于这些思想,在下一节我们提出了在probabilistic RNN中的近似推断,它会产生一个dropout的新变种。
3.1 Bayesian神经网络
给定:
- 训练输入:\(X = \lbrace x_1, \cdots, x_N\rbrace\)
- 相应的输出:\(Y = \lbrace y_1, \cdots, y_N\rbrace\)
在Bayesian(parametrics) regression中,我们希望推断一个函数\(y=f^w(x)\)(用于生成我们的outputs的可能性)的参数w。什么样的参数可能会生成我们的数据?根据Bayesian方法,我们想将一些先验分布放置在参数空间上:\(p(w)\)。该分布表示了先验,表示哪些参数可能会生成我们的数据。我们进一步需要定义一个likelihood分布\(p(y \mid x, w)\)。对于分类任务,我们会假设一个softmax likelihood:
\[p(y=d \mid x,w) = Categorical(\frac{exp(f_d^w(x))} { \sum\limits_{d'} exp(f_{d'}^w(x))})\]或者一个关于regression的高斯似然。给定一个数据集X,Y,我们接着寻找在参数空间上的一个后验:\(p(w \mid X,Y)\)。该分布会捕获多个函数参数生成我们所观察到的数据的可能性。有了它,我们可以为一个新的input point \(x^*\)通过下式连续积分来预测一个output:
\[p(y^* | x^*, X, Y) = \int p(y^*|x^*, w) p(w|X,Y) dw\]…(1)
定义在函数参数集合上的分布的一种方式是:在一个神经网络的权重上放置一个先验分布,生成一个Bayesian NN。对于layer i给定权重矩阵\(W_i\)以及bias vectors \(b_i\),我们经常在该权重矩阵上放置标准矩阵高斯先验分布,\(p(W_i)=N(0,I)\),并出于简洁性经常为bias vectors的假设一个点估计(point estimate)。
3.2 Bayesian NN中的近似变分推断
我们感兴趣的是,发现权重矩阵的分布(参数化我们的参数)来生成我们的数据。这也是在给定我们的观察 \(X,Y: p(w \mid X, Y)\)在权重上的后验。该后验在总体上是不可跟踪的,我们会使用变分推断来近似它。我们需要定义一个近似变分分布\(q(w)\),接着最小化在近似分布和完整后验间的KL divergence:
\[KL(q(w) || p(w|X,Y)) \propto \int q(w) log p(Y|X,w)dw + KL(q(w)||p(w)) \\ = -\sum\limits_1^N \int q(w) log p(y_i | f^w(x_i))dw + KL(q(w)||p(w))\]…(2)
我们接着将该近似变分推断扩展到probabilistic RNNs上,并使用一个\(q(w)\)分布,它会产生在RNNs上的一个dropout新变种。
4.RNN上的变分推断
在本节中,出于概念简洁性,我们将关注在简单RNN模型上。LSTM和GRU与它相类似。给定长度为T的输入序列:\(x=[x_1, \cdots, x_T]\),一个简单的RNN通过对函数\(f_h\)重复使用来形成。这会在每个timestep t上生成一个hidden state \(h_t\):
\[h_t = f_h(x_h, h_{t-1}) = \sigma(x_t W_h + h_{t-1} U_h + b_h)\]\(\sigma\)为非线性函数。该模型可以定义成:\(f_y(h_T) = h_T W_y + b_y\)。我们将该RNN看成是一个概率模型,将参数\(w = \lbrace W_h,U_h,b_h,W_y,b_y \rbrace\)看成是随机变量(遵循正态先验分布)。为了使在w上的依赖更清晰些,我们将\(f_y\)重写成\(f_y^w\),同理\(f_h^w\)。我们定义了我们的概率模型的likelihood。在随机变量w的后验是相当复杂的,我们使用变分推断以及近似分布\(q(w)\)来近似它。
在等式(2)中对每个sum term进行evaluating,我们可以得到:
\[\int q(w) log p(y|f_y^w(h_T)) dw = \int q(w) log p(y|f_y^w (f_h^w(X_T, h_{T-1}))) dw \\ = \int q(w) log p(y | f_y^w (f_h^w(x_T, f_h^w( \cdots f_h^w(x_1,h_0) \cdots )))) dw\]其中:\(h_0 = 0\)。我们使用Monte Carlo(MC)积分、并使用单个样本,将它近似为:
\[\approx p(y | f_y^{\hat{w}} (f_h^{\hat{w}} (x_T, f_h^{\hat{w}}( \cdots f_h^{\hat{w}}(x_1,h_0) \cdots )))), \ \ \ \hat{w} \sim q(w)\]会在每个sum term上产生一个无偏估计。
该estimator可以插入到等式(2)中,来获得最小的objective:
\[L \approx -\sum\limits_{i=1}^N log p(y_i | f_y^{\hat{w}_i} f_h^{\hat{w}_i}(x_{i,T}, f_h^{\hat{w}_i}(x_{i,1},h_0) \cdots )))) + KL(q(w) || p(w))\]…(3)
注意:对于每个序列\(x_i\),我们会抽样一个新的实现\(\hat{w}_i = \lbrace \hat{W}_h^i, \hat{U}_h^i, \hat{b}_h^i, \hat{W}_y^i, \hat{b}_y^i \rbrace\),在序列\(x_i = [x_{i,1}, \cdots, x_{i,T}]\)中的每个symbol会通过函数\(f_h^{\hat{w}_i}\)进行传递,并且在每个timestep \(t \leq T\)上使用相同的weight实现 \(\hat{W}_h^i, \hat{U}_h^i, \hat{b}_h^i\)。
根据[17],我们定义了我们的近似分布来对权重矩阵和在w中的行进行因式分解(factorise)。对于每个权重矩阵的行\(w_k\),近似分布为:
\[q(w_k) = p N(w_k; 0, \sigma^2 I) + (1-p) N(w_k; m_k, \sigma^2 I)\]其中:
- \(m_k\)是变分参数(row vector)
- p为(dropout probability),事先给定
- \(\sigma^2\)较小
我们在\(m_k\)上最优化;这些对应于在标准视图中RNN的权重矩阵。等式(3)的KL可以被近似成在变分参数\(m_k\)上的\(L_2\)正则。
样本\(\hat{w} \sim q(w)\),评估模型的output \(f_y^{\hat{w}}(\cdot)\)对应于在forward pass期间在每个权重矩阵W上的行进行随机零化(masking)——例如:执行dropout。我们的目标函数L等同于标准RNN。在我们的RNN setting中,对于一个序列input,每个权重矩阵行会被随机masked一次,很重要的是:在所有time steps上会使用相同的mask。
预测可以被近似成:即会将每个layer的均值(mean)的传播给下一layer(被称为标准的dropout approximation),或者通过等式(1)中q(w)的后验进行近似:
\[p(y^* | x^*, X, Y) \approx \int p(y^*|x^*, w) q(w) d(w) \approx \frac{1}{K} \sum\limits_{k=1}^K p(y^* | x^*, \hat{w}_k)\]…(4)
以及\(\hat{w}_k \sim q(w)\),例如,通过在test time时执行dropout并对结果求平均(MC dropout)。
4.1 在RNNs中dropout的实现与关系
实现我们的近似推断等同于以这种方式在RNNs中实现dropout:在每个timestep上drop掉相同的network units,随机drop掉:inputs、outputs、recurrent connections。对比起已经存在的技术:在不同的timesteps上drop掉不同的network units、在recurrent connections上不使用dropout(见图1)。
特定RNN模型,比如:LSTMs和GRUs,在RNN units上使用不同的gates。例如:LSTM使用4个gates来定义:”input”、”forget”、“output”、”input modulation”.
\[\underline{i} = sigm(h_{t-1} U_i + x_t W_i) \\ \underline{f} = sigm(h_{t-1} U_f + x_t W_f) \\ \underline{o} = sigm(h_{t-1} U_o + x_t W_o) \\ \underline{g} = sigm(h_{t-1} U_g + x_t W_g) \\ c_t = \underline{f} \circ c_{t-1} + \underline{i} \circ \underline{g} \\ h_t = \underline{o} \circ tanh(c_t)\]其中:
- \(w = \lbrace W_i, U_i, W_f, U_f, W_o, U_o, W_g, U_g\rbrace\)为权重矩阵
- \(\circ\)为element-wise product
这里,内部state \(c_t\)(被称为cell)被求和式的更新。
该模型可以被重新参数化为:
\[\begin{pmatrix} \underline{i} \\ \underline{f} \\ \underline{o} \\ \underline{g} \end{pmatrix} = \begin{pmatrix} sigm \\ sigm \\ sigm \\ tanh \end{pmatrix} ( \begin{pmatrix} x_t \\ h_{t-1} \end{pmatrix} ) \cdot W\]…(6)
其中:\(w = \lbrace W \rbrace\),W是一个2K x 4K的矩阵(K是\(x_t\)的维度)。我们将该参数命名为:tied-weights LSTM(对比于等式(5)中的untied-weights LSTM)
尽管这两个参数会产生相同的deterministic模型,它们会产生不同的近似分布\(q(w)\)。有了第一个参数,对于不同gates可以使用不同的dropout masks(即使当使用相同input \(x_t\)时)。这是因为,近似分布会放在在矩阵上而非inputs上:我们会drop掉一个权重矩阵W中特定的行,并将它应用在\(w_t\)上;在另一矩阵\(W'\)上drop掉不同的行,并应用到\(x_t\)上。第二个参数,我们会在单个矩阵W上放置一个分布。这会产生一个更快的forward-pass,但是会轻微减弱实验的效果。
在更具体的项上,我们会重写我们的dropout变种,使用第二个参数(等式(6)):
\[\begin{pmatrix} \underline{i} \\ \underline{f} \\ \underline{o} \\ \underline{g} \end{pmatrix} = \begin{pmatrix} sigm \\ sigm \\ sigm \\ tanh \end{pmatrix} ( \begin{pmatrix} x_t \circ z_x \\ h_{t-1} \circ z_h \end{pmatrix} \cdot W)\]…(7)
其中,\(z_x, z_h\)会在所有time steps上随机mask(与等式(5)的参数相似)。
作为比较,Zaremba[4]的dropout变种(rnndropout)会将等式(7)中的\(z_x\)替代成时间独立的(time-dependent) \(z_x^t\),它会在每个time step上重新再抽样(其中:\(z_h\)被移除,recurrent connection \(h_{t-1}\)不会被drop掉):
\[\begin{pmatrix} \underline{i} \\ \underline{f} \\ \underline{o} \\ \underline{g} \end{pmatrix} = \begin{pmatrix} sigm \\ sigm \\ sigm \\ tanh \end{pmatrix} ( \begin{pmatrix} x_t \circ z_x^t \\ h_{t-1} \end{pmatrix} \cdot W)\]另外,Moon[20]的dropout变种则将等式(5)进行变化,会采用internal cell:
\[c_t = c_t \circ z_c\]其中,在所有time steps上会使用相同的mask \(z_c\)。注意,不同于[20],通过将dropout看成是一个在权重上的operation,我们的技术可以很容易扩展到RNNs和GRUs上。
4.2 Word Embeddings Dropout
在具有连续输入的数据集中,我们经常将dropout应用到input layer上——例如:input vector本身。这等价于在weight matrix上放置一个分布,它跟着input,并能近似对它求积分(该matrix是可优化的,否则会有overfitting的倾向)
但对于离散输入的模型(比如:words,每个word会被映射到一个连续的vector: word embedding中)却很少这样做。有了word embeddings,input可以看成是word embedding或者是一个“one-hot” encoding。one-hot编码的vector与一个embedding matrix \(W_E \in R^{V \times D}\) 的乘积就给出了一个word embedding。好奇的是,该parameter layer是在大多数语言应用中最大的layer,但它经常不会正则化。因为embedding matrix的优化可能会导致overfitting,因此希望将dropout应用到one-hot encoded vectors。这事实上等同于在输入句子上随机drop掉words。可以解释成:对于它的output,模型不依赖于单个词。
注意,在开始前,我们会将矩阵\(W_E \in R^{V \times D}\)的行随机设置为0. 因为我们会在每个time step上重复相同的mask,我们会在整个序列上drop掉相同的words——例如,我们随机drop掉word types,而非word tokens(例如:句子“the dog and the cat”可能会变为:“- dog and - cat”或者“the - and the cat”,但不会是“- dog and the cat”)。一种可能无效的实现是,需要对V的Bernoullli随机变量进行抽样,其中V可能很大。这可以通过对长度为T的序列,至多有T个embeddings被drop的方式来解决(其它drop掉的embeddings不会对模型output有影响)。对于\(T \ll V\),最有效的方式是,首先将words映射到word embeddings上,接着基于它们的word-type将word embedding进行zero-out。
5.评估
略。
#6.DropoutWrapper
这里再说一下tensorflow中的tf.nn.rnn_cell.DropoutWrapper。里面有一个比较重要的参数:variational_recurrent(缺省为False)。
如果设置为True,它就会在每个step上使用相同的dropout mask,如上面的paper描述。如果设置为False,则会在每个timestep上设置一个不同的dropout mask。
注意,缺省情况下(除排提供一个定制的dropout_state_filter),经过DropoutWrapper 的memory state(LSTMStateTuple中的component c)不会被更改。该行为在上述文章中有描述。