我们来看下Wojciech Zaremba和google brain的人在ICLR 2015提出了《recurrent neural network regularization》,在rnn上使用dropout。
摘要
我们发表了一种简单的regularization技术用于LSTM units的RNNs中。Dropout是神经网络正则化中最成功的技术,但它不能与RNNs和LSTMs有效运行。在本paper中,我们展示了如何将dropout正确应用到LSTMs中,并展示了在多个任务上dropout实质上可以减小overfitting。这些任务包含:语言建模、语音识别、图片标题生成、机器翻译。
1.介绍
RNN是神经序列模型,并在多个重要任务上达到了state-of-the-art的效果。我们知道,神经网络的成功应用需要好的正则化(regularization)。不幸的是,对于前馈神经网络最重要的regularzation:dropout(Srivastava 2013),却不能与RNNs有效运行。因而,RNNs的实际应用经常使用很小的模型,因为大的RNNs会趋向于overfit。已经存在的regularization方法对于RNNs的相对提升较小。在本文中,我们展示了正确使用dropout时可以极大减小在LSTMs中的overfitting,并在三个不同问题上进行了evaluate。
本文代码可在:https://github.com/wojzaremba/lstm找到。
2.相关工作
略
3.LSTM cells RNN的正则化
在本节中,我们描述了deep LSTM。接着,展示了如何对它正则化,并解释了我们的regularization scheme。
我们假设下标表示timesteps,上标表示layers。所有我们的states都是n维的。假设:
- \(h_t^l \in R^n\)是在timestep t时在layer l上的一个hidden state。
- \(T_{n,m}: R^n \rightarrow R^m\)是一个仿射变换(Wx+b, 对于一些W和b)。
- \(\odot\)是element-wise乘法,
- \(h_t^0\)是一个在timestep t上的input word vector。
我们使用activations \(h_t^L\)来预测\(y_t\),因为L是在我们的deep LSTM中的layers数目。
3.1 LSTM units
RNN的动态性可以使用从前一hidden states到当前hidden states上的确定转换(deterministic transitions)来描述。deterministic state transition是一个函数:
\[RNN: h_t^{l-1}, h_{t-1}^l \rightarrow h_t^l\]对于经典的RNNs,该函数可以通过下式给出:
\[h_t^l = f(T_{n,n} h_t^{l-1} + T_{n,n} h_{t-1}^l), where \ f \in \lbrace sigm, tanh \rbrace\]LSTM具有复杂的动态性,使得它对于可以轻易地“记住(memorize)” 一段时间内的信息。“long term” memory被存储在memory cells \(c_t^l \in R^n\)的一个vector中。尽管许多LSTM的架构在它们的连接结构和激活函数上有所区别,所有的LSTM结构都具有显式的memory cells来存储长期的信息。LSTM可以决定是否overwrite memory cell,或者检索它,或者在下一time step上继续保留它。LSTM的结构如下:
\[LSTM: h_t^{l-1}, h_{t-1}^l, c_{t-1}^l \rightarrow h_t^l,c_t^l \\ \begin{pmatrix} i \\ j \\ o \\ g \end{pmatrix} = \begin{pmatrix} sigm \\ sigm \\ sigm \\ tanh \end{pmatrix} T_{2n, 4n} \begin{pmatrix} h_t^{l-1} \\ h_{t-1}^l \end{pmatrix} \\ c_t^l = f \odot c_{t-1}^l + i \odot g \\ h_t^l = o \odot tanh(c_t^l)\]在这些等式中,sigm和tanh是element-wise。图1展示了LSTM的等式。
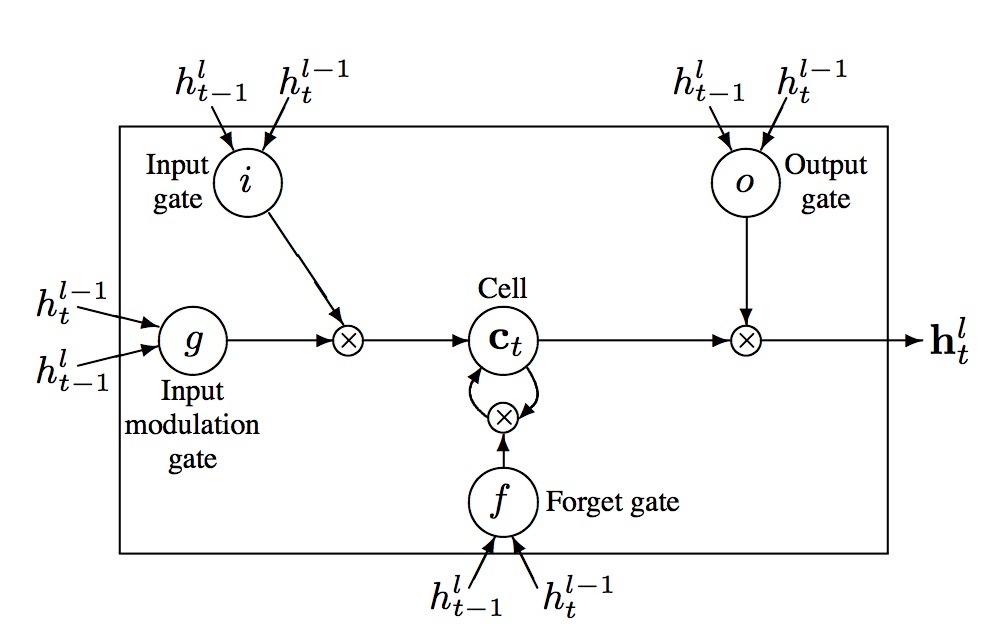
图1: LSTM memory cells的图形化表示
3.2 使用dropout正则化
该paper的主要贡献是:应用dropout到LSTMs中,并成功地减小了overfitting。主要思想是:将dropout operator只应用在非递回连接(non-recurrent connections)(图2)上。
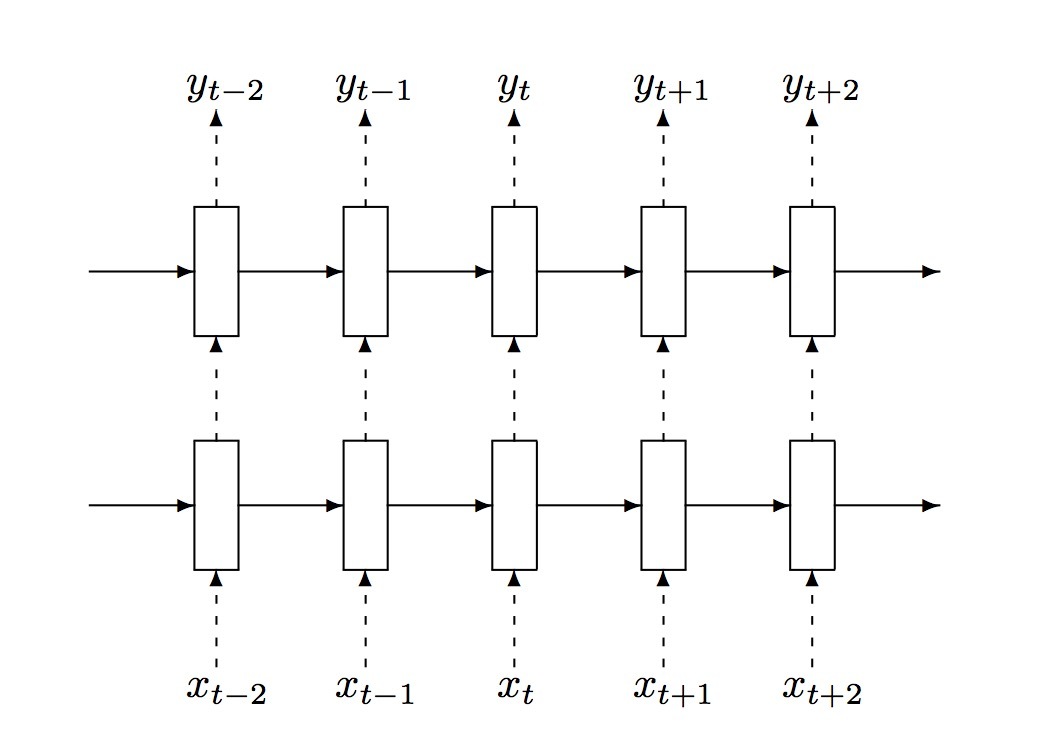
图2: 多层RNN的正则化。虚线键头表示dropout所应用的connections,实线表示不使用dropout的connections
下面的等式可以更精确地描述该过程。其中D是dropout operator,它会将参数的一个随机子集设置为0:
\[\begin{pmatrix} i \\ j \\ o \\ g \end{pmatrix} = \begin{pmatrix} sigm \\ sigm \\ sigm \\ tanh \end{pmatrix} T_{2n, 4n} \begin{pmatrix} D(h_t^{l-1}) \\ h_{t-1}^l \end{pmatrix} \\ c_t^l = f \odot c_{t-1}^l + i \odot g \\ h_t^l = o \odot tanh(c_t^l)\]我们的方法如下运行。dropout operator会使得units所携带的信息不纯(corrupts),强制它们更健壮地执行它们的中间计算。同时,我们不希望抹掉来自该units的所有信息。特别重要的是,该units会记住:过去多个timesteps上发生的events。图3展示了在我们的dropout实现中,信息是如何从timestep t-2发生的event流向在timestep t+2上的预测的。我们可以看到,通过dropout operator所corrupt的信息也恰好是L+1 times,该数目与该信息所经过的timesteps数目是相互独立的。标准的dropout会扰乱(perturb)recurrent connections,这使得使用标准dropout的LSTM很难学习如何来存储长期信息。通过不在recurrent connections上使用dropout的这种方式,LSTM可以受益于dropout regularization、又可以不牺牲它的记忆特质。
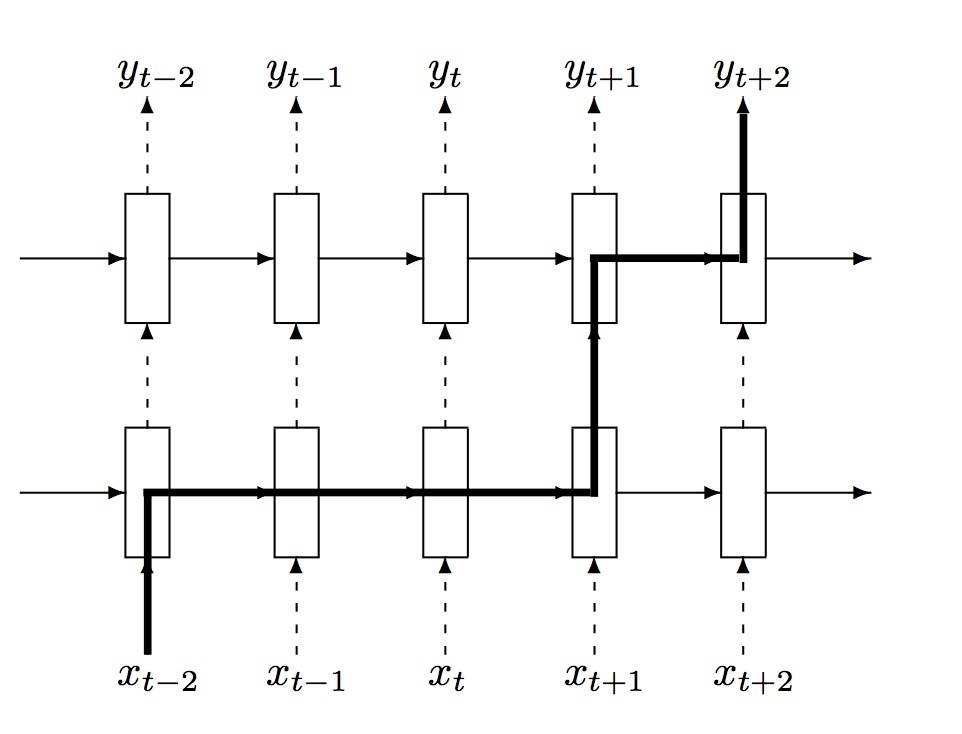
图3 厚线展示了在LSTM中的信息流的一个典型路径。该信息会被dropout影响L+1次,其中L是网络深度
4.实验
略
5.理论
可以参考:《A Theoretically Grounded Application of Dropout in Recurrent Neural Networks》