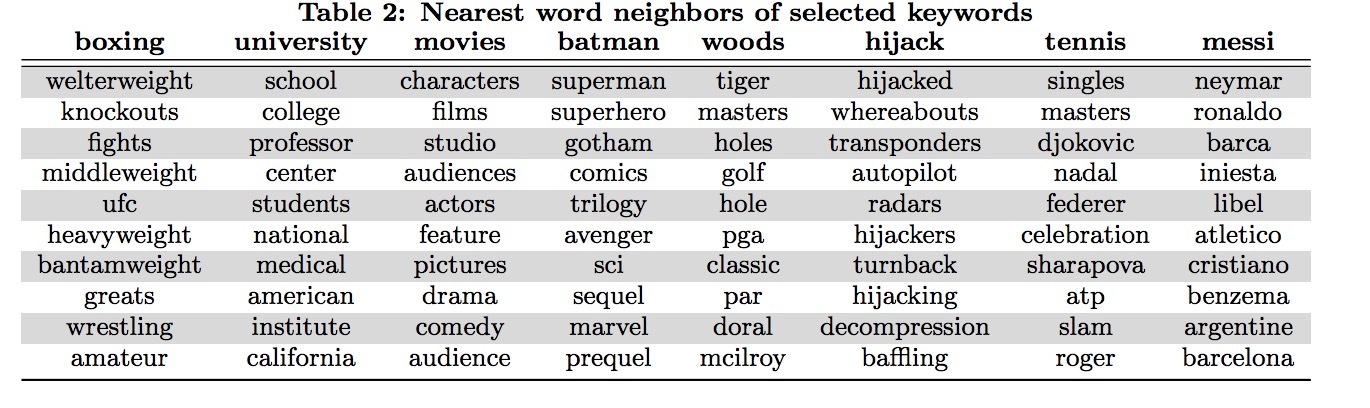
我们来看下prod2vec作者Mihajlo Grbovic†等人提出的HDV《Hierarchical Neural Language Models for Joint Representation of Streaming Documents and their Content》中提出的新方法:
介绍
考虑为数据流中的文档学习分布式表示的问题。文档(documents)被表示成低维向量,与word tokens的分布式向量,使用两个embedded神经语言模型的层次结构框架,通过联合学习得到。特别的,我们会利用在streams中的文档内容,并使用一个语言模型来建模文档序列,另一个模型则建模在它们中的词序列。该模型(the models复数)会为word tokens和documents学习两者的连续向量表示,以便语义相近的documents和words在同一向量空间中更接近。我们讨论了该模型的扩展,通过进一步添加user layers到该结构中,就可以被应用于个性化推荐、以及社交关系挖掘中,这样可以学到用户的向量来表示私人偏好。我们在公共电影评分数据集MovieLens和Yahoo News三个月数据集上进行了验证。结果表明,提出的模型可以学到文档和word tokens的有效表示,效果要好于当前state-of-art的方法一大截。
3.层次化语言模型
本节中,提出的算法会对streaming documents和在它内的words进行联合建模,其中学到的documents和words向量表示会在一个共享的、低维的embedding空间内。该方法受[14]的启发。然而,与[13]的不同之处是,我们会利用steaming documents中的时序邻居(temporal neighborhood)。特别的,我们会建模一个特定文档的概率,会考虑上时序上更接近(temporally-close)的文档,另外还会考虑文档内容。
3.1 模型结构
我们假设,训练文档会以序列形式给定。例如,如果该文档是新闻文章,那么document序列可以是:用户根据阅读时间按前后顺序排列的新闻文章序列。更特别的,我们会假设,设置S个document序列的集合\(S\),每个序列\(s \in S\)包含了\(N_s\)个文档,\(s = (d_1, d_2, ..., d_{N_s})\)。接着,在一个stream \(d_m\)中的每个文档是一个由\(T_m\)个词组成的序列,\(d_m = (w_{m_1}, w_{m_2}, ..., w_{m, T_m})\)。我们的目标是,在同一个向量空间中同时学习streaming documents和language words的低维表示,并将每个document和word表示成D维的连续特征向量。如果我们假设,在训练语料中存在M个唯一的文档(doc),以及在词汇表中存在W个唯一的词(words),那么在训练期间,我们的目标是学习\((M+W) \cdot D\)个模型参数。
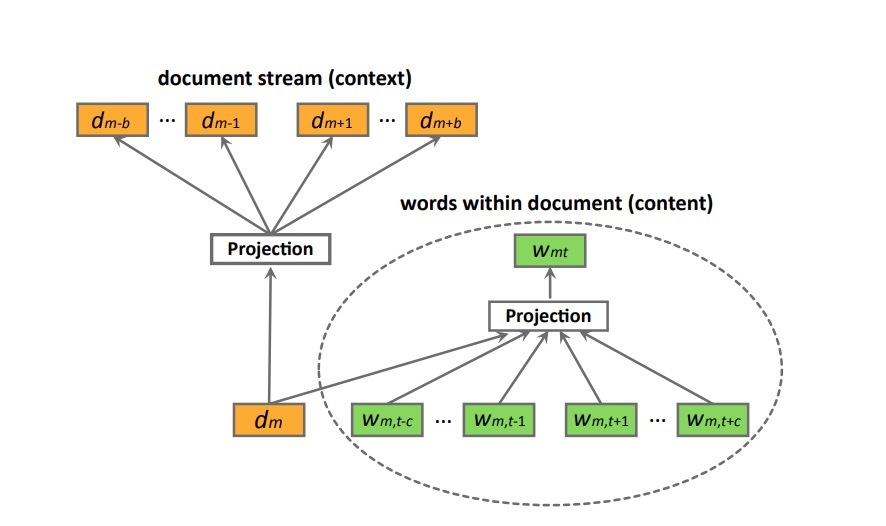
图1: hierarchical模型结构,有两个embedded神经语言模型(橙色:左:文档向量;绿色/右:词向量)
一个文档序列的上下文和自然语言上下文,会使用提出的HDV方法进行建模,其中documents向量不光只看成是预测周围documents的单元,同时也看成是在它之间包含的word序列的全局上下文。该结构包含了两个embedded layers,如图1所示。upper layer可以学到一个文档序列的时序上下文,基于假设:在文档流(document stream)中时序更接近的文档在统计学上相互依赖性更强。我们注意到,时序不需要指文档的创建时间,而是用户阅读文档的时间,在我们的实验中使用该定义。bottom layer会建模word序列的上下文信息。最后,我们采用paragraph vectors的思想,将这两个layer进行连接,并将每个文档token看成是在该文档内所有词的一个全局上下文。
更正式的,给定文档序列集合S,hierarchical模型的目标函数是:最大化streaming data的log似然:
\(L = \sum_{s \in S} (\alpha \sum_{d_m \in s} \sum_{w_{mt} \in d_m} log P(w_{mt} | w_{m,t-c}: w_{m,t+c}, d) + \\ \sum _{d_m \in s} (\alpha log P(d_m | w_{m1}: w_{mT}) + \sum_{-b \le i \le b, i \neq 0} log P(d_{m+i} | d_m)))\) …(8)
其中,\(\alpha\)是权重,它会在文档序列的log似然、以及词序列的log似然的最小化之间做一个权衡(在实验中会设置\(\alpha=1\)),b是文档序列的训练上下文长度,c是词序列的训练上下文长度。在该特定架构中,我们对于下面的setence layer使用cbow模型,对于上层的document layer使用skip-gram模型。然而,我们注意到,两个模型的任一个可以被用于该hierarchy的任意层上,具体选择取决于目前手头的问题形态。
给定如图1的架构,基于当前文档\(P(d_{m+i} \mid d_m)\),观察到某一周围文档的概率,可以使用下面的softmax函数定义:
\(P(d_{m+i} | d_{m}) = \frac{exp(v_{d_m}^T v_{d_{m+i}}')} {\sum_{d=1}^{M} exp(v_{d_m}^T v_d')}\) …(9)
其中\(v_d\)和\(v_d'\)是文档d的输入和输出向量表示。更进一步,观察到一个词的概率不仅依赖于周围的词,也依赖于该词所属的文档。更准确的,概率\(P(w_{mt} \mid w_{m,t-c} : w_{m,t+c},d_m)\)被定义成:
\(P(w_{mt} | w_{m,t-c}: w_{m,t+c}, d_m) = \frac{exp(\bar{v}^T v_{w_{mt}}')} {\sum_{w=1}^{W} exp(\bar{v}^T v_w')}\) …(10)
其中,\(v_{w_{mt}}'\)是\(w_{mt}\)的输出向量表示,其中\(\bar{v}\)是该上下文(包含指定的文档\(d_m\))的平均向量表示,定义如下:
\(\bar{v} = \frac{1}{2c+1} (v_{d_m} + \sum_{-c \leq j \leq c, j \neq 0} v_{w_{m,t+j}})\) …(11)
最后,我们通过复用等式(10)和(11)来替换合适的变量,定义了以一个相同方式在\(P(d_m \mid w_{m1}: w_{m,{T_m}})\)。
3.2 模型变种
前面提到了一个典型结构,其中我们指定了在hirerachy上每一层的语言模型。然而,在真实应用中,我们会以一种更简单的方式来为不同目的区分语言模型。例如,一个新闻网站可能会对预测即时性感兴趣,即:对于个性化新闻信息流,一个用户在点击了一些其它新闻故事后接下去会阅读什么。接着,它可以使用直接的前馈模型来估计\(P(d_m \mid d_{m-b}: d_{m-1})\),即:给定了它的b个之前文档,在序列中第\(m^{th}\)个文档的概率。或者,相同的,如果我们想建模哪个文档会在读取前面序列后被读取,我们可以使用前馈模型:它可以估计\(P(d_m \mid d_{m+1}: d_{m+b})\),它是给定前b个文档的第m个文档的概率。
另外,很方便扩展该描述,但也很容易具有超过两个layers。假设我们具有一个streaming documents的数据集,它面向一个不同的用户集合(例如:对每个文档我们希望知道哪个用户生成或阅读了该文档)。接着,我们可以构建更复杂的模型, 通过在document layer的顶部添加user layer来同时学习用户的分布式表示。在该setup中,一个用户向量可以看成是指定用户的steaming documents的一个全局上下文, 一个文档向量则看成是指定文档的words的一个全局上下文。更特殊的,我们可以预测一个文档,它基于周围文档和它的内容来预测一个文档,同时也只对某一指定用户。该变种模型\(P(d_m \mid d_{m-b}:d_{m-1},u)\),其中u是对于某一用户的一个指示变量。对于提升个性化服务来说,学习用户的向量表示是一个开放问题,其中个性化会降维到:在联合embedding空间中的最简单的最近邻搜索。
3.3 模型最优化
该模型使用SGA(随机梯度上升法),很适合大规模问题。然而,在(8)中的梯度的计算 \(\delta log P(w_{mt} \mid w_{m,t-c} : w_{m,t+c},d_m)\)与词汇size W成比例,梯度\(\Delta log P(d_{m+i} \mid d_m)\)和\(\Delta log P(d_m \mid w_{m1}: w_{m,T_m})\)与训练的文档数M成比例。这在实例上很昂贵,因为W和M两者都可以很容易达到上百万的规模。
我们使用的一种有效替换方法是,hirarchical softmax,它可以将时间复杂度减小到\(O(R log(W) + bM log(M))\),其中R是在文档序列中的总词汇数。为了计算等式(9)和等式(10)中的求和,我们并不用在每次梯度step期间评估每个不同词或文档,hirarchical softmax会使用两个二叉树,一棵树将不同文档作为叶子,另一棵树将不同的词作为叶子。对于每个叶子节点,从该根节点出发的路径(path)会有一个唯一分配,它使用二进制数字进行编码。为了构建一个树结构,通常用使用Huffman编码,其中,在数据集中更常见的文档(或词)会具有更短的编码。更准确的,hierarchical softmax表示在该序列中当前文档(或词)被观察到的概率,它作不二叉树的概率积,通过文档的Huffman编码如下:
\(P(d_{m+i} \mid d_m) = \prod_l P(h_l \mid q_l, d_m)\) …(12)
其中\(h_l\)是编码中第l位的码,对应于\(q_l\),它是指定树路径\(d_{m+i}\)中的第l个节点。每个二叉树的概率定义如下:
\(P(h_l = 1 \mid q_l, d_m) = \sigma(v_{d_m}^T V_{q_l})\) …(13)
其中\(\sigma(x)\)是sigmoid函数,\(v_{q_l}\)是节点\(q_l\)的向量表示。它可以通过\(\sum_{d=1}^M P(d_{m+i}=d \mid d_m) = 1\)进行验证,因而概率分布的属性会被保留。我们可以以同样的方式计算\(P(d_m \mid w_{m1} : w_{m, T_m})\)。更进一步,我们相似地表示\(P(w_{mt} \mid w_{m,t-c}: w_{m,t+c}, d_m)\),但独立的Huffman树的构建会与词有关。