我们来看下yahoo的《Product Recommendations at Scale》中提出的prod2vec方法:
1.介绍
世界上许多人在每天都会浏览email收件箱,大多数时间会与它们的通讯录进行联系,还有一部分时间用于账单确认,读取新信息,以及跟踪购买( tracking purchases)。为了对这种流量进行商业化,email客户端通常会在原生email内容的边上以图片的形式展示广告。说服用户切出”email模式”(即连续处理邮件任务),进入一个新模式让人们愿意去点广告是个挑战。通过有效的个性化和定向(targeting),目标是为单个用户发现与他最匹配的广告展示给他,因而广告需要高度相关,以克服用户只关注email任务的倾向。除了获得财务收益外,为每个消费者的口味量身定制的广告也能改善用户体验,可以增加用户的忠诚度和用户粘性。
对于广告定向(ad targeting),收件箱emails仍未被充分进行explored & exploited。最新研究表明,只有10%的收件量表示是人类生成(非机器生成)的emails。这之外的90%流量中,超过22%表示与在线电商有关。假设整体流量中大部分是有商业目的的,定向广告的一种流行形式是电邮重定位(MRT: mail retargeting),其中,广告主会对之前从特定商业网站(web domain)上接收过邮件的用户进行定向。这些电子邮件对于广告定向来说很重要,它们会给出用户感兴趣的相应商品的一个大图(broad picture)进行展示。最新paper[14]利用聚类方法来生成MRT规则,展示了这样的规则比由人类专家生成的要更精准。
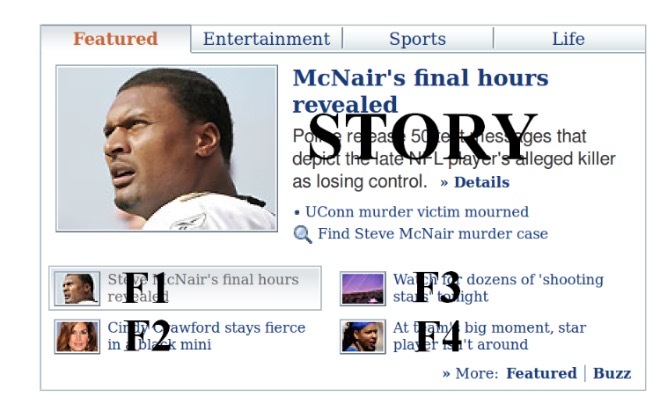
图一:Yahoo Mail中的商品推荐
然而,为了超出MRT规则之外,用户和商业网站的交互,广告商需要更多数据(比如:购买过的商品名和价格,通常是email邮件的一部分)。email客户端与商业网络能很好结合,对电子邮件格式进行标准化,产生的schemas通过schema.org社区进行维护。越来越多的商业网站使用标准schemas,email客户端可以提供更个性化的用户通知,比如:包裹跟踪(package tracking)和 航班详情(flight details)。另外,email receipt extraction带来了赚钱机会,基于客户的购买历史将商品广告带给用户。有了从多个商业email domain上的购买数据,比起其它基于单一商业email domain来说,可以更好地将email provider放置到在唯一的位置上,以便能构建更好的推荐系统。特别的,不同于商业网站可以做出这样的推荐:“买了X的顾客,也会买Y”,email providers可以做出这样的推荐:“从生产商V1处购买了X的顾客,也会从生产商V2处购买Y”,允许更强大和更有效的定向解决方案。
在本paper中,我们为Yahoo Mail提供了一种end-to-end的商品广告开发方案。工作包含了开发一个商品级别的购买预测算法,能扩展到数百万的用户和商品。出于该目的,我们提出了一种方法,使用一个神经语言模型,将它应用到用户购买时间序列上,从而将商品嵌入到real-valued,低维的向量空间中。作为结果,具有相近上下文的商品(它们相邻近的购买行为)可以映射到在embedding空间中更接近的地方。关于下一个要购买的商品,为了做出有意义和更多样的建议,我们会进一步将商品向量进行聚类,并建模聚类间的转移概率。来自可能的聚类在向量空间中更接近的商品,会被用于形成最终推荐。
商品预测模型会使用一个大规模的购买数据集进行训练,由2900w用户的2.8亿购买行为组成,涉及210w个唯一的商品。该模型会在一个held-out month上进行评估,其中,我们在收益率(yield rate)上测试了推荐的有效性。另外,我们会评估一些baseline方法,包含展示流行商品给所有用户,以不同用户分组(称为:分群(cohorts),由用户性别、年龄、地域)展示流行商品,以及展示在一个用户最近购买商品之后历史最常购买的商品。为了减轻冷启动问题,在用户的分群(cohort)中的流行商品会被用于补足那些早期没有购买行为的用户的推荐。
3.方法
本节中,我们描述了该商品推荐任务的方法论。为了解决该任务,我们提出了从历史日志中使用自然语言模型学习在低维空间中的表示。商品推荐可以通过最简单的最近邻搜索得到。
更特别的,给定从N个用户中获取的email receipt日志的一个集合S,其中用户的日志为 \(s = (e_1, ..., e_M) \in S\)被定义成一个关于M个receipts的连续序列,每个email recept \(e_m = (p_{m1}, p_{m2}, ..., p_{mT_m})\)包含了\(T_m\)个购买的商品,我们的目标是发现每个商品p的D维实数表示\(v_p \in R^D\),以便相似的商品可以在向量空间中更近的位置。
我们提供了一些方法来学习商品表示。首先提出了prod2vec方法,它会考虑所有已经购买的商品。接着提出了新的bagged-prod2vec方法,它会考虑在email receipts中一起罗列被购买的一些商品,它们会产生更好、更有用的商品表示。最终,我们会利用上学到的representations来分别表示一个prod2prod和user2prod的推荐模型。
3.1 低维商品embeddings
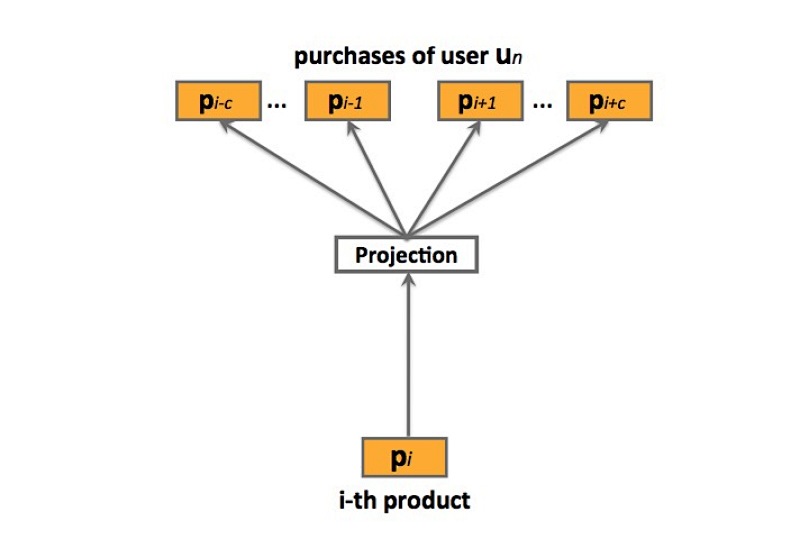
图二:prod2vec skip-gram模型
prod2vec:prod2vec模型会将一个购买序列看成是一个“句子”,在这个序列中的商品看成是“词”。详见图2, 更特殊的,prod2vec使用skip-gram模型来学习商品表示,通过以下的最大化目标函数:
\[L = \sum_{s \in S} \sum_{p_i \in s} \sum_{-c \leq j \leq c, j \neq 0} log p(p_{i+j} | p_i)\]…(3.1)
其中,来自相同email receipt的商品可以是任意顺序。概率\(P(p_{i+j} \mid p_i)\)表示:给定当前商品\(p_i\),观察到一个邻近商品\(p_{i+j}\)的概率,使用softmax函数进行定义如下:
\[P(p_{i+j}| p_i) = \frac{exp({v_{p_i}^T v_{p_{i+j}}'})} {\sum_{p=1}^P exp{(v_{p_i}^T v_p')}}\]…(3.2)
其中,。。。。
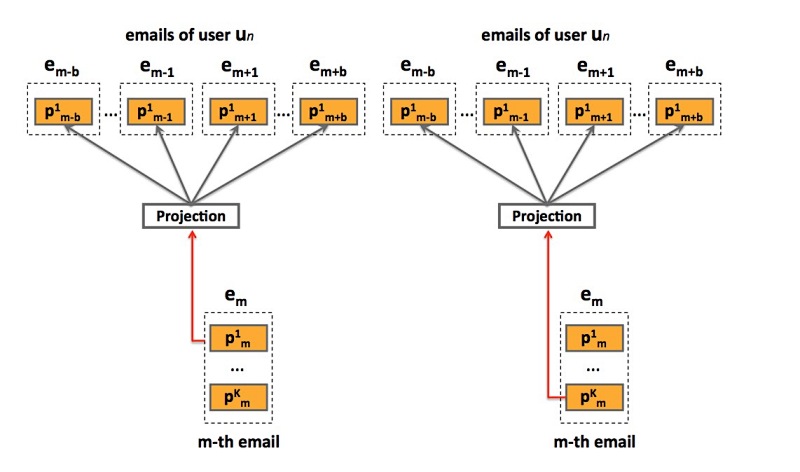
图3: bagged-prod2vec模型更新
bagged-prod2vec:为了对多个商品同时购买的行为做出解释,我们提出了一个修改版本的skip-gram模型,它引入了一个概念:购物袋(shopping bag)。如图3所示,该模型会在email receipts级别进行操作,而非在商品级别。通过对email序列s上的一个修改版目标函数进行最大化,来学习商品向量表示:
\[L = \sum_{s \in S} \sum_{e_m \in s} \sum_{-n \leq j \leq n, j\neq 0} \sum_{k=1,...,T_m} log P(e_{m+j}| p_{mk})\]…(3.3)
商品\(P(e_{m+j} \mid p_{mk})\)是从邻近的email receipt \(e_{m+j}\)上观察到商品的概率,\(e_{m+j}=(p_{m+j,1}, ..., p_{m+j, T_m})\),给定从第m个email receipt的第k-th个商品,到一个商品的概率:
\[P(e_{m+j} \mid p_{mk}) = P(p_{m+j,1} \mid p_{mk} ) \times ... \times P(p_{m+j,T_m} \mid p_{mk})\]每个P的定义使用softmax(3.2)。注意在(3.3)中的第三个求和会随着receipts进行,因而,从相同的email receipt中得到的items在训练期间不会相互预测。另外,为了捕获商品购买的时序特性(temporal aspects),我们提出了使用有向语言模型,我们只使用未来的商品(future product)作为上下文。该修改版允许我们学习商品embeddings来预测将来的购买行为。
learning:该模型使用SGA( stochastic gradient ascent)进行最优化,很适合大规模问题。然而,在(3.1)和(3.3)中的梯度计算\(\Delta L\),很适合词汇size P,实际任务中,计算开销会随着P的增大而变得很昂贵,很容易达到上百万的商品。另一方面,我们使用negative sampling方法,它能显著减小计算复杂度。
3.2 prod-2-prod预测模型
在学习了低维商品表示后,我们考虑了来预测下一商品的购买概率的一些方法。
prod2vec-topK:给定一个购买商品,该方法会为所有在词汇表中的商品计算cosine相似度,并推荐最相似商品的top K
prod2vec-cluster:为了能做出更多样化(diverse)的推荐,我们考虑将相似商品分组成聚类,从与之前购买商品相关的聚类中推荐商品。我们应用K-means聚类算法来在hadoop FS上实现,将商品基于cosine相似度进行聚类。我们假设:在从聚类\(c_i\)上进行一个购买后、再从任意第C个聚类中进行一次购买的行为,符合一个多项式分布(multinomial distribution)\(M_u(\theta_{i1}, \theta_{i2}, ..., \theta_{iC})\),其中\(\theta_{ij}\)是从聚类\(c_i\)中进行一次购买后、接着从聚类\(c_j\)中进行一次购买的概率。为了估计参数\(\theta_{ij}\),对于每个i和j,我们采用一个最大似然方法:
\(\hat {\theta_{ij}} = \frac{c_i购买后跟c_j的次数}{c_i购买的总数}\) …(3.4)
- count of ci purchases: c_i购买的数目
- # of times ci purchase was followed by cj: c_i购买后跟c_j的次数
为了给一个购买过的商品p推荐一个新商品,我们首先标识了p属于哪个聚类(例如: \(p \in c_i\))。接着,我们会对所有聚类\(c_j\),通过\(\theta_{ij}\)值进行排序,然后考虑取与聚类\(c_i\)top相关的聚类中的top个商品。最后,从top聚类中的商品通过与p计算cosine相似度进行重排序,取top K进行推荐。
3.3 User-to-product预测模型
除了prod2prod预测外,大多数推荐引擎允许user-to-product方式的预测,为一个用户进行推荐通常会考虑历史购买、或(和)兴趣,使用其它数据源:用户在线行为、社交行为等。在本节中,我们提出了一个新方法来同时学习商品的向量表示、以及给定一个用户,发现在joint embedding space发现K个最近商品的用户推荐。
user2vec:受paragraph2vec算法的启发,user2vec模型会同时学习商品和用户的特征表示,它会将用户当成是一个“全局上下文”。这样的模型如图4所示。训练数据集来自于用户购买序列S,它会包含\(u_n\)和其它已购商品(通过购买时间序排列),\(u_n = (p_{n1}, p_{n2}, ..., p_{nU_n})\),其中\(U_n\)表示用户\(u_n\)购买的items数目。在训练期间,用户向量会被更新,来预测从他的email receipts中的商品,其中,学到的product vectors会预测在上下文中的其它商品。出于表示的简洁性,在下面,我们会表示no-bagged版本的模型,注意,使用bagged版本进行扩展也很方便。
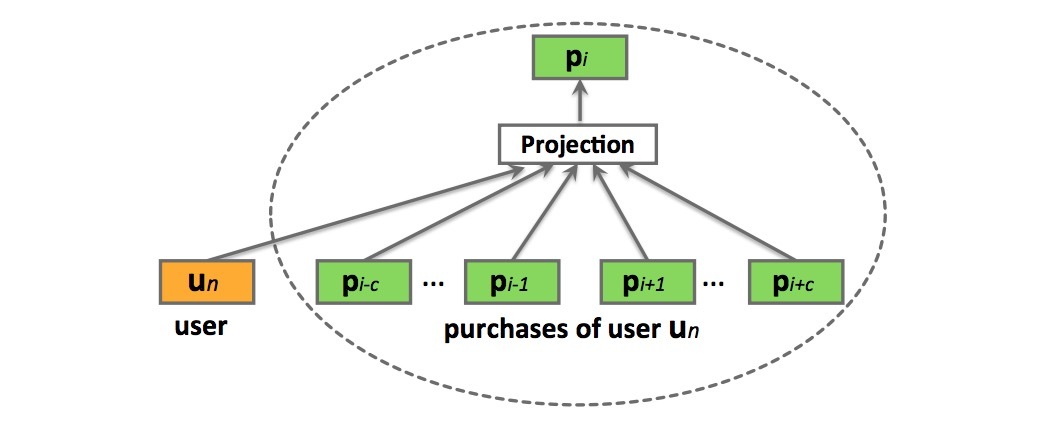
图4: 对用户的User embeddings,进行产品预测
更特殊的,user2vec的目标函数是,最大化所有购买序列的集合S上的似然:
\[L = \sum_{s \in S} (\sum_{u_n \in s} log P(u_n | p_{n1}: p_{nU_n}) + \sum_{p_{n_i} \in u_n} log P(p_{ni}| p_{n,i-c}: p_{n,i+c,u_n}))\]…(3.5)
其中,c是第n个用户的购买序列上下文长度。\(P(p_{ni} \mid p_{n,i-c}:p_{n,i+c,u_n})\)被定义为使用一个softmax函数:
\(P(p_{ni}|p_{n,i-c}: p_{n,i+c}, u_n) = \frac{e^{\bar{v}^T v_{p_{ni}}'}}{ \sum_{p=1}^{V} e^{\bar{v}^T v_p'}}\) …(3.6)
其中\(v_{p_{ni}}'\)是\(p_{ni}\)的输出向量表示,\(\bar{v}\)是商品上下文的平均向量表示,包含了相应的\(u_n\),定义如下:
\(\bar{v} = \frac{1}{2c+1} (v_{u_n} + \sum_{-c \leq j \leq c ,j \neq 0} v_{p_{n,i+j}})\) …(3.7)
其中,\(v_p\)是p的输入向量表示。相似的,概率\(P(u_n \mid p_{n1}: p_{n U_n})\)定义如下:
\(P(u_n | p_{n1}: p_{nU_n}) = \frac{e^{\bar{v}_n^T v_{u_n}'}} {\sum_{p=1}^V e^{\bar{v}_n^T v_p'}}\) …(3.8)
其中\(v_{u_n}'\)是\(u_n\)的输出向量表示,\(\bar{v}_n\)是用户\(u_n\)的所有商品平均输入向量表示的平均:
\[\bar{v}_n = \frac{1}{U_n} \sum_{i=1}^{U_n} v_{p_{ni}}\]…(3.9)
user2vec模型的一个主要优点是,商品推荐是基于该用户的购买历史进行量身定制的。然而,缺点是,该需要需要非常频繁地进行更新,不同于product-to-product方法,它可以长期是相关的,而user-to-product推荐需要经常变化来对最近购买行为做出解释。
4.实验及其它
略,详见paper.
4.4 推荐预测商品
我们对推荐商品给用户进行实验,比较以下算法:
- 1) prod2vec-topK:使用数据集\(D_p\)进行训练,其中,商品向量通过对购买序列s通过极大似然估计进行学习。给定一个商品\(p_i\),通过向量空间计算cosine相似度选择topK个相似商品。
- 2) bagged-prod2vec-topK:使用\(D_p\)进行训练,其中商品向量通过email序列s通过极大似然估计进行学习。对于给定商品\(p_i\),通过选择在结合向量空间计算cosine相似度选择topK个相似商品。
- 3) bagged-prod2vec-cluster: 与bagged-prod2vec模型的训练类似,接着将商品向量聚类成C个聚类,并计算它们间的转移概率。接着标识出\(p_i\)属于哪个聚类(例如:\(p_i \in c_i\)),我们根据\(c_i\)的转移概率对各聚类进行排序,取出top个聚类,然后聚出这些top聚类的商品通过计算与\(p_i\)的cosine相似度进行排序,其中每个聚类的top \(K_c\)被用于推荐(\(\sum {K_c} = K\))。 bagged-prod2vec-cluster与 bagged-prod2vec的预测结果如表2所示。可以看到聚类方法多样性更好。
- 4) user2vec:使用\(D_p\)进行训练,其中商品向量和用户向量通过极大似然估计进行学习。给定一个用户\(u_n\),通过计算\(u_n\)用户向量与所有商品向量的cosine相似度,检索出top K近邻商品。
- 5) co-purchase:对于每个购买pair:\((p_i, p_j)\),计算频率\(F_{(p_i,p_j)}\),其中\(i=1,...,P, j=1,...,P\),商品\(p_j\)在商品\(p_i\)之后立即购买。接着,给商品\(p_i\)的推荐通过频率\(F_{(p_i,p_j)}, j=1,...,P\)进行排序,取topK商品。

表2: 潜水呼吸管(cressi supernova dry snorkel)的商品推荐
在第\(t_d\)天之前,由于用户\(u_n\)具有多个商品的购买行为,为了在这一天选择最好的K个商品,各种独立的预测( separate predictions)必须达成一致。为了达到该目的,我们提出了时间衰减的推荐评分scoring,在根据最高得分选择top K个商品之后使用。更特别的,给定用户在\(t_d\)天前的商品购买行为以及它们的时间戳(timestamps):\(\lbrace (p_1,t_1), ..., (p_{U_n}, t_{U_n}) \rbrace\),对于每个商品,我们会根据相似得分检索top K个推荐,产生集合\(\brace (p_j, sim_j), j=1, ..., K U_n \rbrace\),其中sim表示cosine相似度。接着,我们为每个推荐商品计算一个衰减得分(decayed score):
\[d_j = sim_j \cdot \alpha^{t_d - t_i}\]其中\((t_d - t_i)\)是当前天\(t_d\)与产生推荐\(p_j\)的商品购买时间的差,其中\(\alpha\)是衰减因子。最终,按照衰减评分降序,并取topK个商品作为第\(t_d\)天的推荐。

表1:通过bagged-prod2vec模型生成的商品推荐示例
训练细节:神经语言模型会使用一台96GB RAM内存的24core机器。embedding space的维度被设置成d=300, 上下文neighborhood size为5. 最后每个向量更新中使用10 negative samples。与[24]的方法相似,最频繁的商品和用户在训练期间会进行子抽样(subsampled)。为了展示该语言模型的效果,表1给出了使用bagged-prod2vec推荐的样例,可以看到邻居商品与query商品高度相关。(例如:“despicable me 卑鄙的我(动画电影)”,该模型会检索到相似卡通片)
评估细节: 与流行商品的accruracy如何测量类似,我们假设每个用户有一个K=20不同商品推荐。对于\(t_d\)天的预测,会基于先前天的购买进行预测,我们不会考虑在该天期间发生的购买行为来更新第\(t_d\)天的预测。
结果:我们评估了decay factors不同值所对应的prod2vec表现。 在图9中,我们展示了在测试数据\(D_p^{ts}\)(往前看1,3,7,15,30天)上的预测准确率。初始的prod2vec预测会基于在训练数据集\(D_p\)最后用户购买。该结果展示了不同预测对于产生推荐准确率提升的预测的折扣,decay factor=0.9是一个最优选择。
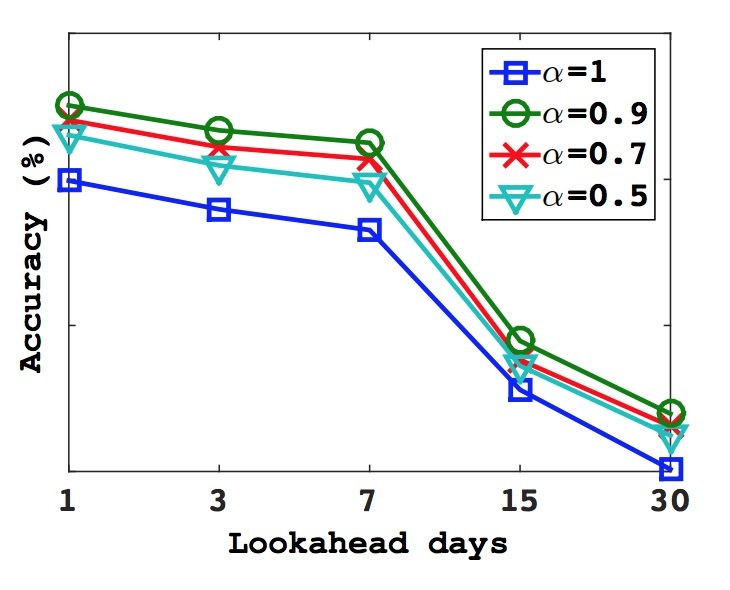
图9: 不同decay值的prod2vec accuracy