Y Bengio在2003年发布了paper《A Neural Probabilistic Language Model》,即NNLM。我们来看一下这篇10多年前的paper中的主要内容:
1.介绍
语言建模和其它学习问题很难,因为存在一个基础问题:维度灾难(curse of dimensionality)。当你想建模许多离散随机变量间(比如:一个句子中的词,或者在一个数据挖掘任务中的离散变量)的联合分布时,这个现象特别明显。例如,如果你想建模自然语言中在一个size=10w的词汇表V的10个连续词的联合分布,潜在会有\(100000^{10}-1=10^{50}-1\)个自由参数(free parameters)。当建模连续变量时,我们可以更轻易地获得泛化(例如:使用多层神经网络或高斯混合模型的平滑分类函数),因为学到的函数可以具有一些局部平滑属性。对于离散空间,泛化结果并不明显:这些离散变量的任何变化,都可能对要估计的函数值具有一个剧烈的影响;当离散变量的值可取的数目很大时,大多数观察到的目标相互之间在hamming距离上差距很大。
受非参数化密度估计的启发,对不同学习算法如何泛化进行可视化的一种有效方法是,认为将初始集中在training points(例如:训练句子)上的概率质量(probability mass)在一个更大的空间(volume)中分散是的(distributed)。在高维中,将概率质量(probability mass)进行分散(distribute)很重要,而非围绕在每个training point周围的所有方向上均匀。我们在本paper会展示提出的这种方法与state-of-art统计语言建模方法的不同。
统计语言模型可以通过下面的公式进行表示,给定所有之前出现的词,对下一个词的条件概率:
\[\hat{P}(W_1^T) = \prod\limits_{1}^{T} \hat{P}(w_t | w_t^{t-1})\]其中,\(w_t\)是第t个词,子序列可以写成:\(w_i^j = (w_i, w_{i+1}, \cdots, w_{j-1}, w_j)\)。这样的统计语言模型在许多应用中很有用,比如:语音识别,语言翻译,信息检索。统计语言模型对这样的应用有极大影响。
当构建自然语言的统计模型时,可以通过使用词序(word order)来减小建模问题的难度,实际上在词序列中时序更接近的词在统计学上相互依赖更强。因而,对于一个大数目的上下文(比如:最近n-1个词的组合)中的每个词,可以近似使用n-gram模型来构建对于下一个词的条件概率表:
\[\hat{P}(w_t | w_1^{t-1}) \approx \hat{P}(w_t | w_{t-n+1}^{t-1})\]我们只考虑这些在训练语料中实际出现、或者发生足够频繁的连续词的组合。当n个词的一个新组合出现在训练语料中,会发生什么?我们不想分配零概率到这样cases中,因为这些新组合很可能会出现,而且他们可能对于更大的上下文size会出现的更频繁。一个简单的答案是,使用一个更小的上下文size来看下预测概率,比如:back-off trigram模型、或者smoothed trigram模型。在这样的模型中,从在训练语料中的词序列获取的的模型如何泛化到新的词序列上呢?一种方式是,给这样的插值或back-off ngram模型对应一个生成模型。本质上,一个新的词序列可以通过“粘合(gluning)”在训练语料中频繁出现的非常短或长度为1,2…,n的重叠块来生成。在特别的back-off或插值n-gram算法中,获得下一块(piece)的概率的规则是隐式的。通常,研究者们使用n=3(比如:trigrams),并获取state-of-art结果。。。。
1.1 使用分布式表示来解决维度灾难
简单的,提出的方法可以如下进行总结:
- 1.将词表中的每个词与一个distributed word feature vector(在\(R^m中\)一个real-valued vector)进行关联。
- 2.采用在序列中的词的feature vectors来表示词序列的联合概率函数.
- 3.同时学习word vectors和概率函数的参数
feature vector可以表示词的不同方面:每个词与一个向量空间中的一个点(point)相关联。features的数目(比如:实验中采用m=30, 60或100)比词汇表的size要小很多。概率函数被表示成:给定之前的词,一个关于下一个词的条件概率乘积(例如:使用一个multi-layer NN来预测)。该函数具有这样的参数,它以最大化训练数据的log似然来进行迭代调参。feature vectors是通过学习得到的,但它们可以使用语义特征的先验知识进行初始化。
为什么会有效?在之前的示例中,如果我们知道,dog和cat扮演着相似的角色(语义上和结构上),对于(the,a), (bedroom, room), (is, was), (running, walking)是相似的,我们可以很自然地对下面的句子进行泛化:
The cat is walking in the bedroom
泛化成:
A dog was running in a room
或者:
The cat is running in a room
A dog is walking in a bedroom
The dog was walking in the room
…
以及许多其它组合。在我们提出的模型中,它是可以泛化的,因为“相似”的词被认为是具有一个相似的feature vector,因为概率函数是一个关于这些feature values的平滑函数,在特征上的微小变化在概率上只会引入很小的变化。因些,在训练数据中上述句子之一的出现将会增加概率,不仅仅是那些句子,而且包括在句子空间中它们的“邻居”的组合数目。
1.2 之前工作
略。
2.一个神经模型
训练集是关于\(w_t \in V\)的一个序列\(w_1, \cdots, w_T\),其中词汇表V是一个有限的大集合。学习目标是学习一个好的模型,使得:
\[f(w_t, \cdots, w_{t-n+1}) = \hat{P}(w_t \mid w_1^{t-1})\]也就是说给出很高的out-of-sample likelihood。下面,我们会上报关于\(1/\hat{P}(w_t \mid w_1^{t-1})\)的几何平均,它被称为“困惑度(perplexity)”,它也是平均负log似然的指数。模型的唯一限制是,对于\(w_1^{t-1}\)的任意选择,\(\sum\limits_{i=1}^{\mid V\mid} f(i, w_{t-1}, \cdots, w_{t-n+1}) = 1\),其中\(f>0\)。通过将这些条件概率相乘,可以获得一个关于这些词序列的联合概率的模型。
我们将函数\(f(w_t, \cdots, w_{t-n+1})= \hat{P}(w_1^{t-1})\)解耦成两部分:
- 1.一个映射函数C,它将V的任意元素i映射到一个真实向量\(C(i) \in R^m\)。它表示与词典中每个词相关的分布式特征向量(distributed feature vectors)。实际上,C被表示成一个关于自由参数的\(\mid V \mid \times m\)的矩阵。
- 2.词上的概率函数,由C进行表示:对于在上下文中的词,\((C(w_{t-n+1}), \cdots, C(w_{t-1}))\),会使用一个函数g将一个关于feature vectors的输入序列映射到一个关于下一个词\(w_t \in V\)的条件概率分布上。g的输出是一个vector,它的第i个元素可以估计概率\(\hat{P}(w_t = i \mid w_1^{t-1})\),如图1所示。
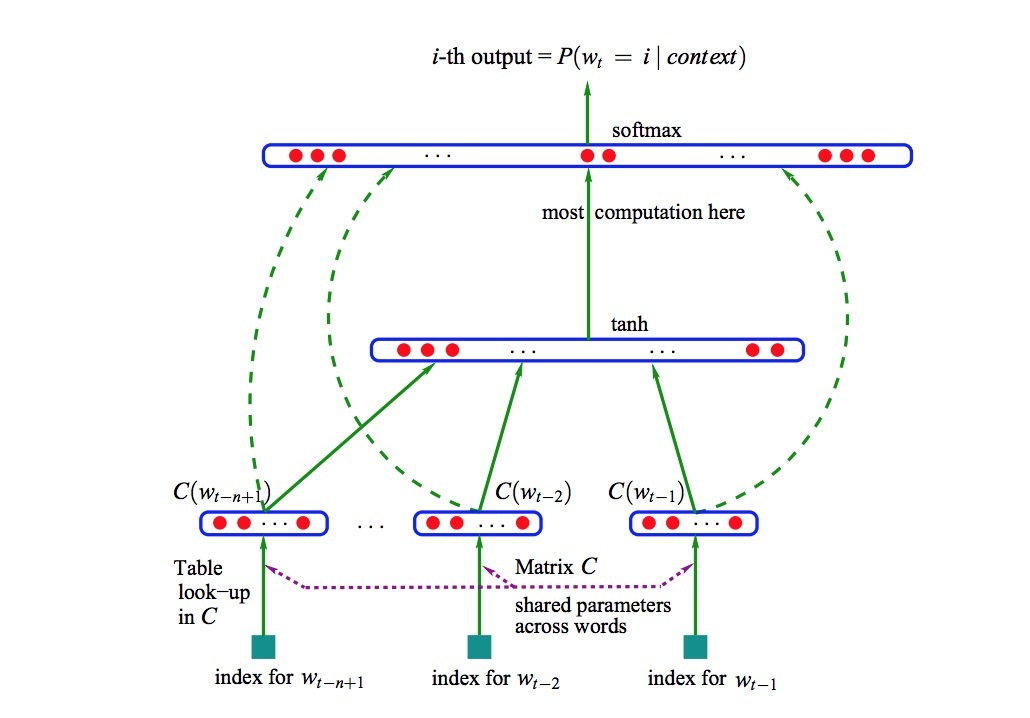
图1: 神经网络结构:\(f(i, w_{t-1}, \cdots, w_{t-n+1}) = g(i, C(w_{t-1}), \cdots, C(W_{t-n+1}))\),其中g是神经网络,C(i)是第i个word feature vector。
函数f是这两个mappings(C和g)的一个组合,其中C对于在上下文中所有词是共享的(shared)。这两部分每一个都与一些参数有关。mapping C的参数就简单的是feature vectors自身,通过一个\(\mid V\mid \times m\)的矩阵C进行表示,其中第i行表示第i个词的feature vector C(i)。函数g通过一个feed-forward或RNN或其它参数化函数(parametrized function)来实现,它使用参数\(\mathcal{W}\)。
训练通过搜索\(\theta\)来完成,它会在训练语料上最大化penalized log-likelihood:
\[L = \frac{1}{T} \sum\limits_{t} log f(w_t, w_{t-1}, \cdots, w_{t-n+1}; \theta) + R(\theta)\]其中\(R(\theta)\)是一个正则项。例如,在我们的实验中,R是一个权重衰减项(weight cecay penalty),它只应用于神经网络的weights和矩阵C上,而非应用在biases上。
在上述模型中,自由参数(free parameters)的数目与词汇表中词数目V成线性比例。它也只与阶数n成线性比例:如果介入更多共享结构,例如,使用一个time-decay神经网络或一个RNN(或者一个关于两种网络的组合),比例因子可以被减小到sub-linear。
在以下大多数实验上,除word features mapping外,神经网络具有一个hidden layer,可选的,还有从word features到output上的直接连接(direct connections)。因此,实际有两个hidden layers:
- 1.shared word features layer C:它是线性的
- 2.普通的双曲正切( hyperbolic tangent) hidden layer
更精准的,神经网络会计算如下的函数,它使用一个softmax output layer,它会保证正例概率(positive probabilities)求和为1:
\[\hat{P}(w_t | w_{t-1}, \cdots, w_{t-n+1}) = \frac{e^{y_{w_t}}}{\sum\limits_{i} e^{y_i}}\]其中,\(y_i\)是对于每个output word i的未归一化log概率,它会使用参数b, W, U, d和H,具体计算如下:
\[y = b + W x + U tanh(d+Hx)\]…(1)
其中,双曲正切tanh以element-by-element的方式进行应用,W可选为0(即没有直接连接),x是word features layer activation vector,它是从矩阵C的input word features的拼接(concatenation):
\[x = (C(w_{t-1}), C(W_{t-2}), \cdots, C(W_{t-n+1}))\]假设h是hidden units的数目,m是与每个词相关的features的数目。当从word features到outputs上没有直接连接(direct connections)时,矩阵W被设置为0。该模型的自由参数是output biases b(具有\(\mid V \mid\)个元素),hidden layer biases d(具有h个元素),hidden-to-output weights U(一个\(\mid V \mid \times h\)的矩阵),word features到output weights W(一个\(\mid V\mid \times (n-1) m\)的矩阵),hidden layer weights H(一个 \(h \times (n-1) m\)的矩阵),word features C(一个\(\mid V\mid \times m\)的矩阵):
\[\theta = (b,d,W,U,H,C)\]自由参数的数目是 \(\mid V\mid (1 + nm + h) + h(1 + (n-1) m)\)。主导因子是\(\mid V\mid (nm+h)\)。注意,在理论上,如果在weights W和H上存在一个weight decay(C上没有),那么W和H可以收敛到0,而C将会增长。实际上,当使用SGA(随机梯度上升)训练时,我们不会观察到这样的行为。
在神经网络上进行SGA包含,包含在执行以下的在训练语料的第t个词之后的迭代更新中:
\[\theta \leftarrow \theta + \epsilon \frac{\partial log \hat{P}(w_t | w_{t-1}, \cdots, w_{t-n+1})}{\partial \theta}\]其中,\(\epsilon\)是learning rate。注意,大部分参数不需要更新、或者在每个样本之后训练:\(C(j)\)的word features,不会出现在input window中。
混合模型。在我们的实验中,我们已经发现,通过将神经网络的概率预测与一个interpolated trigram model相组合,可以提升效果,使用一个固定的权重0.5,一个可学习权重(在验证集上达到最大似然),或者一个weights集合,是基于在context的频率为条件的(使用相似的过程:在interpolated trigram上组合trigram, bigram, and unigram)。
其它
略.
参考: