2.前置
首先,我们将使用隐式反馈的CF问题进行公式化。接着,简短介绍下广泛使用的MF模型,以及重点介绍使用内积的缺陷。
2.1 使用隐式数据进行学习
假设M和N表示users和items的数目。我们使用用户的隐式反馈来定义user-item交互矩阵\(Y \in R^{M \times N}\):
\[y_{ui} = \begin{cases} 1, \\ 0 \end{cases}\]…(1)
\(y_{ui}\)为1表示:user u和item i间有交互;然而,它并不意味着u实际会喜欢i。相似的,该值为0也并不表示用户u不喜欢item i。对隐式数据的学习存在着许多挑战,因为它存在许多关于用户偏好的噪声数据。而已观察条目至少反映了用户在这些items上的兴趣,未观察条目可能只是缺失数据(missing data),它天然缺少负反馈。
隐式反馈的推荐问题,可以公式化为:对在Y中未观察条目的得分(score)的估计问题,这些得分可以被用于进行ranking。Model-based方法假设,数据可以通过一个底层模型进行生成。正式的,他们可以被抽象成:学习\(\hat{y}_{ui}=f(u,i \mid \theta)\),其中\(\hat{y}_{ui}\)可以表示交叉项\(y_{ui}\)的预测得分,\(\theta\)表示模型参数,f表示将模型参数映射到预测得分的函数(我们称之为“interaction function”)。
为了估计参数\(\theta\),已经存在的机器学习方法会优化一个目标函数。有两种类型的目标函数最为常用——pointwise loss以及pairwise loss:
- 作为在显式反馈上的一个天然扩展,pointwise learning方法通常会使用一个回归框架,对\(\hat{y}_{ui}\)与它的目标值\(y_{ui}\)间的平方loss(squared loss)进行最小化。为了处理缺失的negative数据,会将所有未观察条目当成是负反馈,或者从未观察条目中进行抽样。
- pairwise learning的思想是:已观察条目应比未观察条目排序更靠前。pairwise learning会最大化已观察条目\(\hat{y}_{ui}\)与未观察条目\(\hat{y}_{uj}\)间的间隔。
更近一步,我们的NCF框架会使用神经网络的方法对交叉函数f进行\(\hat{y}_{ui}\)的参数估计。这样,它能天然支持pointwise和pairwise的两种学习方法。
2.2 矩阵分解(MF)
MF会分别将每个user和item使用一个关于隐特征的real-valued vector进行关联。假设:
- \(p_u\)和\(q_i\)表示user u和item i的隐向量;
MF会将对\(y_{ui}\)的估计表示成\(p_u\)和\(q_i\)的内积:
\[\hat{y}_{ui}=f(u,i|p_u,q_i) = p_u^T q_i = \sum\limits_{k=1}^{K} p_{uk} q_{ik}\]…(2)
其中:K表示隐空间的维度。
MF会建模关于user和item隐因子的two-way interaction,假设隐空间的每个维度相互独立,并使用相同的权重进行线性组合。这样,MF可以被看成是一个关于隐因子的线性模型。
图1展示了内积函数如何限制了MF的表达力。有两个设置需要明确声明:
- 首先,由于MF会将users和items映射到相同的隐空间上,两个用户间的相似度可以通过一个内积、或者隐向量间夹角的cosine来进行度量。
- 第二,不失一般性,我们可以使用jaccard系数作为MF所需要去恢复的两个用户间的ground truth相似度。
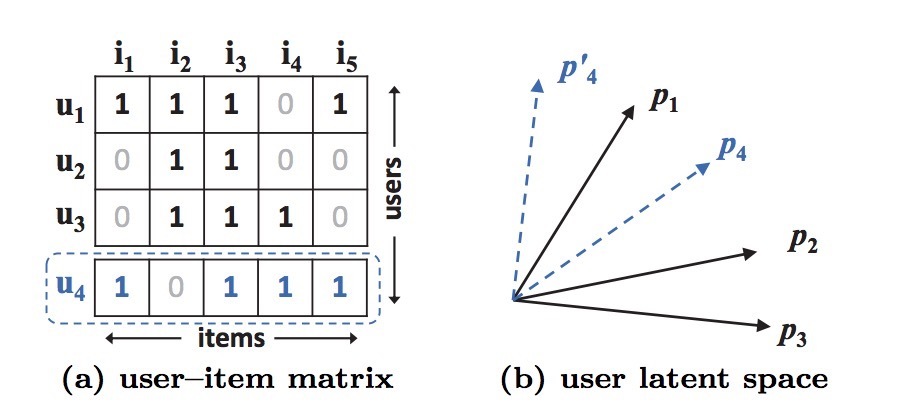
图1
假设,我们首先关注在图1a中的前三行(users)。很容易有:\(s_{23}(0.66) > s_{12}(0.5) > s_{13}(0.4)\)。 这样,\(p_1, p_2, p_3\)在隐空间中的几何关系可以如图1b所示。现在,假设我们考虑一个新的用户\(u_4\),它的输入可以如图1a中的虚线表示。我们有:\(s_{41}(0.6) > s_{43}(0.4) > s_{42}(0.2)\),这意味着,\(u_4\)与\(u_1\)最接近,接着是\(u_3\),最后是\(u_2\)。然而,如果一个MF模型将\(p_4\)挨着\(p_1\)(如图1b虚线的两种选择),它会产生\(p_4\)与\(p_2\)(比起\(p_3\))更接近,它很不幸会产生一个大的ranking loss。
以上示例展示了MF的可能限制(使用简单的、确定内积来估计在低维空间中(上图就是个2维的..)的复杂的user-item interactions)。我们注意到,解决该问题的一种方法是:使用更大数目的隐因子K。然而,它会伤害模型的泛化能力(例如:overfitting),特别是在数据稀疏的情况下。在该工作中,我们通过使用DNN来学习交叉函数来解决该限制。
3. neural CF
我们首先描述通用的NCF框架,详述如何使用一个概率模型学习NCF,它会利用隐式数据的二元性质。我们接着展示MF在NCF下是如何表示和泛化的。为了利用DNN进行CF,我们接着提出一个NCF的实例,使用一个多层感知器(MLP)来学习user-item因子模型,它会在NCF框架下对MF和MLP进行ensembles;它会利用MF的线性能力和MLP的非线性能力来建模user-item的隐结构。
3.1 通用框架
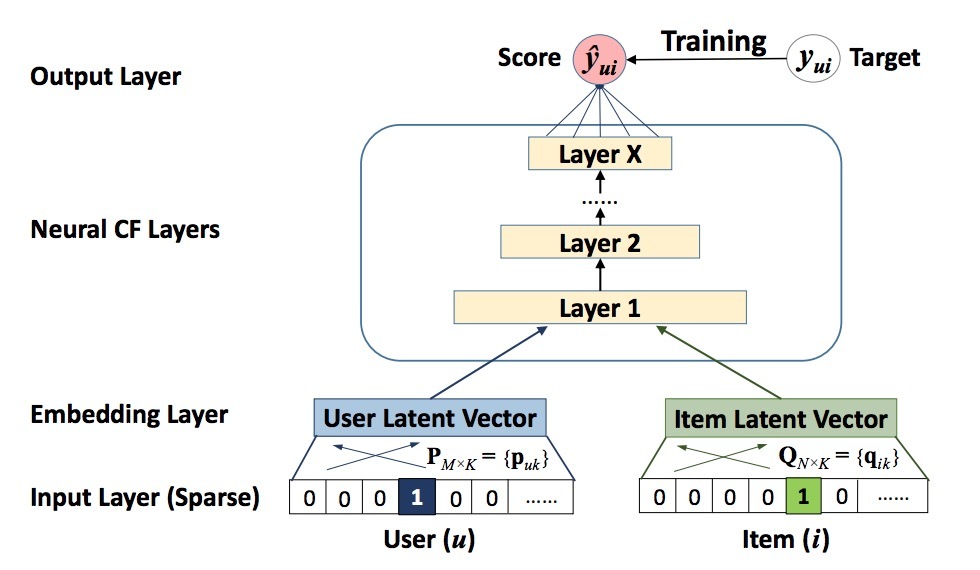
图2
为了启用CF的神经网络方法,我们采用multi-layer表示来建模一个user-item interaction \(y_{ui}\),如图2所示,其中,一个layer的output会看成是下一layer的input。底部的input layer包含了两个特征向量\(v_u^U\)和\(v_i^I\),它们可以被定制化成支持更宽范围的users和items的建模,比如:context-aware和content-based,neighbor-based。由于本paper主要关注在纯粹的CF设置中,我们只使用了一个user和一个item的单位矩阵(identity)作为输入特征,并使用one-hot编码将它转成成一个关于输入的二值化稀疏特征表示。注意,这样的一个关于inputs的泛化特征表示,我们的方法可以进行简单的调整:通过使用content features来表示users和items来解决冷启动问题。
上面的input layer是embedding layer;它是一个fully connected layer,可以将稀疏表示投影到一个dense vector上。获得的user(item) embedding可以看成是,在隐因子模型的上下文中关于user(item)的隐向量。user embedding和item embedding接着被feed到一个multi-layer的神经结构中,我们将它称之为neural CF layers,它们会将隐向量映射到预测得分上。neural CF layers的每个layer可以被定制化以发现user-item interactions的特定隐结构。最终的output layer就是预测得分\(\hat{y}_{ui}\),训练的执行会最小化在\(\hat{y}_{ui}\)和目标值\(y_{ui}\)间的pointwise loss。我们注意到,训练该模型的另一种方式是执行pairwise学习,比如,使用Bayesian Personalized Ranking和margin-based loss。该paper只关注neural network建模部分,NCF的pairwise learning的扩展是将来的工作。
我们将NCF的预测建模成:
\[\hat{y}_{ui} = f(P^T v_u^U, Q^T v_i^I | P, Q, \theta_f)\]…(3)
其中,\(P \in R^{M \times K}\)以及\(Q \in R^{N \times K}\),表示users和items的隐因子矩阵,\(\theta_f\)表示交叉函数f的模型参数。由于函数f被定义成一个多层神经网络,它可以被公式化为:
\[f(P^T v_u^U, Q^T v_i^I) = \phi_{out} (\phi_X (...\phi_2(\phi_1(P^T v_u^U, Q^T v_i^I))...))\]…(4)
其中\(\phi_{out}\)和\(\phi_x\)各自表示output layer和第x个neural CF layer的映射函数,它们总共有X个neural CF layers。
3.1.1 NCF学习
为了学习模型参数,已经存在的pointwise方法大多数会使用squared loss来执行回归:
\[L_{sqr} = \sum_{(u,i) \in y \cup y^-} w_{ui}(y_{ui} - \hat{y}_{ui})^2\]…(5)
其中,\(Y\)表示在Y中可观察到的interactions集合,而\(Y^-\)表示负例的集合,它可以是所有(或从中抽样)未观察到的interactions;其中\(w_{ui}\)是一个超参数,它表示训练实例(u,i)的权重。其中squared loss可以通过假设observations从一个高斯分布中生成来解释,我们指出,它与使用隐式数据并不十分稳合。这是因为对于隐式数据,目标值\(y_{ui}\)是一个二值化(1或0)的值,它表示u是否与i有交互。在下文中,我们会描述一个概率化方法来学习pointwise NCF,它会关注隐式数据的二元特性。
考虑到隐式反馈的一元性质(one-class),我们将\(y_{ui}\)的值看成是一个label——1表示item i与y相关,否则不相关。预测得分\(\hat{y}_{ui}\)接着会表示i如何与u相关的可能性。为了赋于NCF这样的一个概率化解释,我们需要限制output \(\hat{y}_{ui}\)的范围为[0,1],它可以轻易地通过使用一个概率化函数(例如:logistic or Probit function)作为output layer \(\phi_{out}\)的activation function来达到该目的。使用上述设定,我们可以定义likelihood function为:
\[p(Y, Y^- | P, Q, \theta_f) = \prod_{(u,i) \in Y} \hat{y}_{ui} \prod_{(u,j) \in Y^-} (1 - \hat{y}_{uj})\]…(6)
采用负log似然,我们可以达到:
\[L = - \sum_{(u,i) \in Y} log (1-\hat{y}_{ui}) \\ = - \sum_{(u,i) \in Y \cup Y^-} y_{ui} log \hat{y}_{ui} + (1-y_{ui}) log(1-\hat{y}_{ui})\]…(7)
这是用于最小化NCF方法的目标函数,它的最优化通过执行SGD来完成。你可以注意到,该实现与二元cross-entropy loss相同,这也被称为logloss。通过对NCF采用一个概率化方法,我们可以将使用隐式反馈的推荐看成是一个二元分类问题。classification-aware log loss很少在推荐文献中被研究,我们在本工作中使用它,并在4.3节展示它的有效性。对于负样本\(Y^-\),我们会在每个迭代中控制采样率(例如:观察到交叉的数目),从未观察到的交互中均匀对它们抽样。而非均匀采样策略(例如:item流行度偏差(item popularity-biased))可能会提升效果,我们会在后续工作中探索。
3.2 Generalized MF(GMF)
我们现在已经展示了MF是如何被解释成NCF框架的一个特征case。由于MF是推荐中最流行的方法,已经在许多文献中广泛研究,可以恢复它来允许NCF来模仿一个因子分解模型的大家族。
由于输入层(input layers)会使用user(item) ID的one-hot编码,获得的embedding vector可以看成是user(item)的隐向量。假设:
- 用户隐向量\(p_u\)是\(P^T v_u^U\),
- item隐向量\(q_i\)是\(Q^T v_i^I\)。
我们定义第一个neural CF layer的映射函数是:
\[\phi_1(p_u, q_i) = p_u \odot q_i\]..(8)
其中:\(\odot\)表示向量的element-wise product。我们接着将该向量投影到output layer上:
\[\hat{y}_{ui} = a_{out}(h^T (p_u \odot q_i))\]…(9)
其中:\(a_{out}\)和h分别表示output layer的activation function和edge weights。直觉上,如果我们为\(a_{out}\)使用一个identity function,并强制h是一个关于1的均匀向量,我们就可以准确恢复成MF模型。
在NCF框架下,MF可以很轻易地进行泛化和扩展。例如,如果我们允许h是从数据中学到,并没有均匀限制,它可以产生一个MF变种:允许隐维度的重要性区分。如果我们为\(a_{out}\)使用一个非线性函数,它会将MF泛化成一个非线性设置,这会比线性MF模型更具表现力。在本工作中,我们实现了一个在NCF框架下的泛化版本的MF,它会使用sigmoid function \(\sigma(x)=1/(1+e^{-x})\)作为\(a_{out}\),并使用log loss来从数据中学习h。我们称它为GMF,即Generalized Matrix Factorization的简称。
3.3 多层感知器(MLP)
由于NCF采用两路来建模users和items,它直觉上会通过将它们两路进行拼接来组合特征。该设计在多模态深度学习中被广泛使用(multimodal deep learning)。然而,简单的向量拼接不能解释在user和item隐特征间的任意interactions,它对于建模CF效果来说是不够的。为了解决该问题,我们提出了在concated vector上添加hidden layers,并使用一个标准的MLP来学习user和item隐特征间的interaction。在某种意义上,我们可以赋予该模型一个很大的灵活性和非线性来学习\(p_u\)和\(q_i\)间的交互,而非\(GMF\)的方式只能使用一个固定的element-wise product。更精准的,在NCF框架下的MLP模型被定义成:
\[z_1 = \phi_1(p_u,q_i) = \begin{bmatrix} p_u \\ q_i \end{bmatrix}, \\ \phi_2(z_1) = a_2 (W_2^T z_1 + b_2), \\ \cdots \\ \phi_L(z_{L-1}) = a_L (W_L^T z_{L-1} + b_L), \\ \hat{y}_{ui} = \sigma(h^T \phi_L(z_{L-1}))\]…(10)
其中,\(W_x, b_x, a_x\)表示权重矩阵,bias向量以及第x层perceptron的activation function。对于MLP layers的激活函数,我们可以自由选择sigmoid、tanh、ReLU等。我们可以分析分个函数:
- 1) sigmoid函数会限制每个neuron到(0,1)间,这可以限制模型的效果;它会饱和(saturation),当其它output接近0或1时,其中neurons会停止学习
- 2) 尽管tanh是一个更好的选择,已经被广泛采用,它只能缓和sigmoid的问题到一定程度,因为它可以看成是sigmoid的归一化版本:\(tanh(x/2) = 2\sigma(x) - 1)\)
- 3) 我们会采用ReLU,它更加生物上可信,并且被证明是未饱和的(non-saturated)。
再者,它鼓励稀疏激活,更适合稀疏数据,使得模型更不会overfitting。经验上ReLU会比tanh有稍微更好的效果,比sigmoid有显著更好的效果。
为了设计网络结构,一个常见解法是采用塔式结构(tower pattern),其中底层(bottom layer)是最宽的,每个后续layer会有更少的neurons数目(如图2所示)。前提是,对于更高layers通过使用更少数目的hidden units,它们可以学到更抽象的数据特征。经验上实现了塔式结构,每个后续的layer size会是前一layer size的二分之一。
3.4 GMF和MLP的Fusion
至今,已经开发了两个NCF的实例——GMF会使用一个线性kernel来建模隐特征交叉,MLP会使用一个非线性kernel来学习interaction function。那么问题来了:如何将GMF和MLP在NCF框架下进行混合,以便能利用更多者来达到对复杂的user-item interactions的更好建模。
一个简单解决方案是,让GMF和MLP共享相同的embedding layer,接着将它们的interaction function的输出进行组合。这种方法与Neural Tensor Network(NTN)的方法相近。特别的,将GMF与一个单层MLP进行组合的建模,可以公式化成:
\[\hat{y}_{ui} = \sigma(h^T a(p_u \odot q_i + W \begin{bmatrix} p_u \\ q_i \end{bmatrix} + b))\]…(11)
然而,共享GMF和MLP的embedding会限制混合模型的效果。例如,它意味着,GMF和MLP必须使用相同size的embeddings;对于那些两个模型的最优embedding size不同的数据集,这种解决方法对于获取最优ensemble会失败。
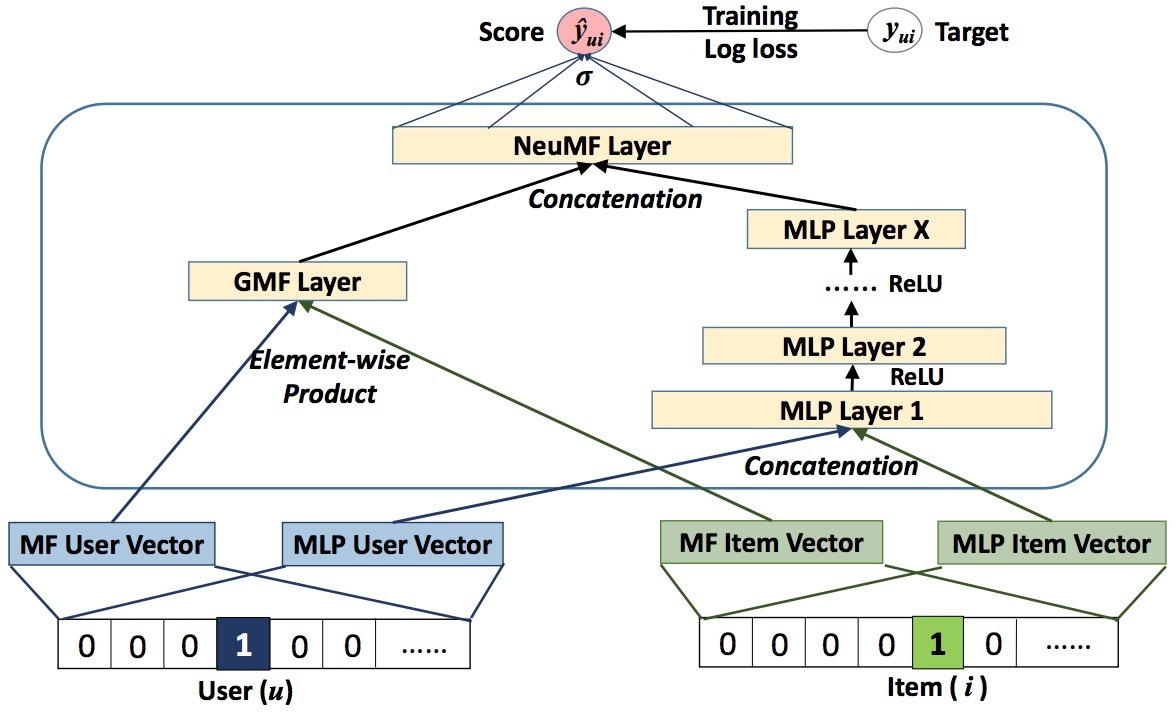
图3
为了提供对于混合模型的更多灵活性,我们允许GMF和MLP来学习单独的embeddings,并通过将它们最后的hidden layer进行拼接来将两模型进行组合。图3展示了我们的解法,可以公式化为:
\[\phi^{GMF} = p_u^G \odot q_i^G \\\ \phi^{MLP} = a_L(W_L^T (a_{L-1} (... a_2(W_2^T \begin{bmatrix} p_u^M \\ q_i^M \end{bmatrix} + b_2)...)) + b_L) \\\ \hat{y}_{ui} = \sigma(h^T \begin{bmatrix} \phi^{GMF} \\ \phi^{MLP} \end{bmatrix}\]…(12)
其中,\(p_u^G\)和\(p_u^M\)可以表示成GMF和MLP部分的user embedding;而\(q_i^G\)和\(q_i^M\)可以表示是item embeddings。如前所述,我们会使用ReLU作为MLP layers的激活。该模型会组合MF的线性的DNN的非线性来建模user-item的隐结构。我们将该模型称为“NeuMF”,即Neural Matrix Factorization的简称。该模型对于每个模型参数的导数可以通过标准的BP算法进行计算,由于篇幅限制这里忽略不讲。
3.4.1 预训练
由于NeuMF的目标函数的non-convexity特性,基于梯度的最优化方法只能找到局部最优解。因此初始化对于模型收敛和效果来说扮演着重要角色。由于NeuMF是GMF和MLP的ensemble,我们建议使用预训练好的GMF和MLP模型来初始化NeuMF。
我们首先使用随机初始化训练GMF和MLP,直到收敛。接着使用它们的模型参数作为NeuMF各自部分的初始化。output layer上的唯一缺点是,我们会拼接两个模型的权重:
\[h \leftarrow \begin{bmatrix} \alpha h^{GMF} \\ (1-\alpha)h^{MLP} \end{bmatrix}\]…(13)
其中,\(h^{GMF}\)和\(h^{MLP}\)表示预训练好的GMF和MLP模型的h向量,\(\alpha\)是超参数,它决定义两个预训练模型间的trade-off。
为了从头到尾训练GMF和MLP,我们采用Adam。Adam方法比vanilla SGD收敛更快。在将预训练参数feed给NeuMF后,我们使用vanilla SGD进行最优化,而非Adam。这是因为Adam需要保存momentum信息来更新参数。而我们只使用预训练模型参数来初始化NeuMF,必须放弃momentum信息,momentum-based方法并不适合进一步的NeuMF的最优化。
4.实验
实验的目的是为了回答以下的研究问题:
- RQ1: 我们的NCF方法效果是否比state-of-art的隐式协同过滤方法效果要好?
- RQ2: 我们的最优化框架(负采样的log loss)是否适合推荐任务?
- RQ3: 更深layers的hidden units是否对学习user-item interaction数据更有用?