#
tmall在《Multi-Interest Network with Dynamic Routing for Recommendation at Tmall》开放了它们的召回算法。在matching stage上,提出了Multi-Interest Network with Dynamic routing (MIND)来处理用户的多样化兴趣。特别的,还基于capsule routing机制设计了一个multi-interest extractor layer,用于聚类历史行为和抽取多样化兴趣。另外,我们还开发了一种称为”label-aware attention”的技术来帮助学习具有多个向量的用户表示 。目前的效果要好于state-of-the-art的其它推荐方法。并在天猫APP的移动端主页上部署,会处理主要的在线流量。
1.介绍
tmall APP的主页如图1(左)所示,它占据着tmall APP的半数流量,并会部署RS来展示个性化的商品来满足客户个性化需求。

图1
由于数十亿规模的users和items,tmall的推荐过程设计包括两部分:matching stage和ranking stage。对于这两阶段,建模用户兴趣和发现可以捕获用户兴趣的用户表示(user representation)非常重要,以便能支持对items的高效检索来满足用户兴趣。然而,由于用户的多样化兴趣的存在,在tmall上建模用户兴趣是很有意义的(non-trivial)。平均上,数十亿用户访问tmall,每个用户每天会与成百上千个商品交互。交互的商品趋向于属于不同类目,可以表示用户兴趣的多样性。例如,如图1(右)所示,不同用户根据它们的兴趣来说是不同的,相同的用户也可能对不同类型的items感兴趣。因此,捕获用户的多样化兴趣的能力变得十分重要。
已经存在的推荐算法会以不同方式建模和表示用户兴趣。CF-based方法可以通过历史交互items[22]或隐因子[17]来表示用户兴趣,可以承受稀疏性问题或计算需要。deep learning-based方法通常以低维embedding vectors来表示用户兴趣。例如,youtube DNN[7]从用户过往行为中转换得到固定长度的vector,它对于建模多样化兴趣可能是个瓶颈,因为在tmall上,它的维度必须很大,以便能表示海量的interest profiles。DIN[31]使用attention机制,使得单个用户对于不同的items会有不同用户表示,这样可以捕获多样化的用户兴趣。然而,采用attention机制也使得它对于海量items的大规模应用来说是在计算上是不可行的,因为它需要为每个item重新计算用户表示(user representation),这使得DIN只适用于ranking stage。
在本paper中,我们主要关注在matching stage上为用户建模多样化兴趣的问题。为了克服已存在方法的限制,我们提出了MIND来学习用户表示,它可以在matching stage上影响用户的多样化兴趣。为了infer用户表示向量,我们设计了一个新的layer,它称为“multi-interest extract layer”,该layer会利用“dynamic routing”[21]机制来自适应地将用户历史行为聚合成用户表示(user repesentation)。dynamic routing的过程被看成是软聚类(soft-clustering),它会将用户的历史行为聚合成许多聚类(clusters)。每个历史行为的cluster会进一步根据一个特定兴趣,被用于infer用户表示的向量。这种方式下,对于一个特定用户,MIND会输出多个表示向量,它们表示共同表示用户的多样化的兴趣。用户表示向量只会被计算一次,并被用于matching stage来从海量items中检索相关items。该方法的主要贡献有:
- 1.为了捕获用户行为的多样化兴趣,我们设计了multi-interest extractor layer,它可以利用dyniamic routing来自适应地将用户历史行为聚合成用户表示向量。
- 2.通过使用由multi-interest extractor layer和一个新提出的label-aware attention layer生成的用户表示向量(vectors),我们构建一个DNN来做个性化推荐。对比已存在的方法,MIND在多个公开数据集上和天猫上的效果要好一些。
- 3.为了在tmall上部署MIND,我们构建了一个系统来实现整个pipline,包括:data collecting、model training和online serving。部署的系统可以极大提升Tmall APP的ctr。
2.相关工作
深度学习推荐。受CV和 NLP的deep learning的成功启发,我们尝试了许多deep learning-based的推荐算法。除了[7,31],还有许多其它deep模型。NCF[11]、DeepFM[9]、DMF[27]会构建由许多MLP组成的神经网络来建模users和items间的交互。[23]提供一种可捕获许多特征的united and flexible network来解决top-N序列推荐。
User Representation。在推荐系统中,将users表示为vectors很常见。传统的方法会将用户偏好组合成由感兴趣的items[4,12,22]、keywords[5,8]和topics[29]的vectors。随着分布式表示学习的出现,user embeddings可以通过NN获得。[6]使用RNN-GRU来从时序阅读文档中学习user embeddings。[30]从word embedding vectors中学习user embedding vectors,并将它们应用于推荐学术微博上。[2]提出了一种新的CNN-based模型来显式学习和利用user embeddings。
Capsule Network。“胶囊(Capsule)”的概念,对一小部分neurons组合输出一整个vector,首次由2011年Hinton[13]提出。用于替代BP,dynamic routing[21]被用于学习capsules间连接的权重,通过利用EM算法[14]来克服多种缺陷并达到较好的accuracy。它与CNN有两个主要不同之处,使得capsule networks可以编码在part和whole间的关系,这在CV和NLP中是很先进的。SegCaps[18]证明,capsules可以成功建模目标的局部关系(spatial),比传统CNNs要好。[28]研究了文本分类的capsule网络,并提出了3种策略来增强效果。
3.方法
3.1 问题公式化
工业界RS的matching stage的目标,从海量item池子I中,为每个用户\(u \in U\)检索一个items子集,使得该子集包含数千个items,每个item与用户兴趣相关。为了达到该目标,由RS生成的历史数据收集来构建一个matching模型。特别的,每个实例可以通过一个tuple \((I_u, P_u, F_i)\)进行表示,其中:
- \(I_u\)表示与用户u交互的items集合(也称为:用户行为(user behavior))
- \(P_u\)是用户u的基础profiles(比如:gender和age)
- \(F_i\)是target item的特征(比如:item id和category id)
MIND的核心任务是,学习一个函数,来将原始特征(raw features)映射到用户表示上,它可以公式化为:
\[V_u = f_{user}(I_u, P_u)\]…(1)
其中,\(V_u = (\vec{v}_u^1, \cdots, \vec{v}_u^K) \in R^{d \times K}\)表示用户u的表示向量,d是维度,K是表示向量的数目。当K=1时,只使用一个表示向量,如同Youtube DNN一样。另外,target item i的表示向量通过一个embedding function获取:
\[\vec{e}_i = f_{item}(F_i)\]…(2)
其中,\(\vec{e}_i \in R^{d \times 1}\)表示item i的表示向量,\(f_{item}\)的细节会在”Embedding &Pooling Layer”这节详述。
当学习到用户表示向量和item表示向量,top N候选items会根据打分函数进行检索:
\[f_{score}(V_u, \vec{e}_i) = \underset{1 \leq k \leq K}{max} \vec{e}_i^T \vec{e}_u^k\]…(3)
其中,N是在matching stage中检索出的items的预定义数目。
3.2 Embedding & Pooling Layer
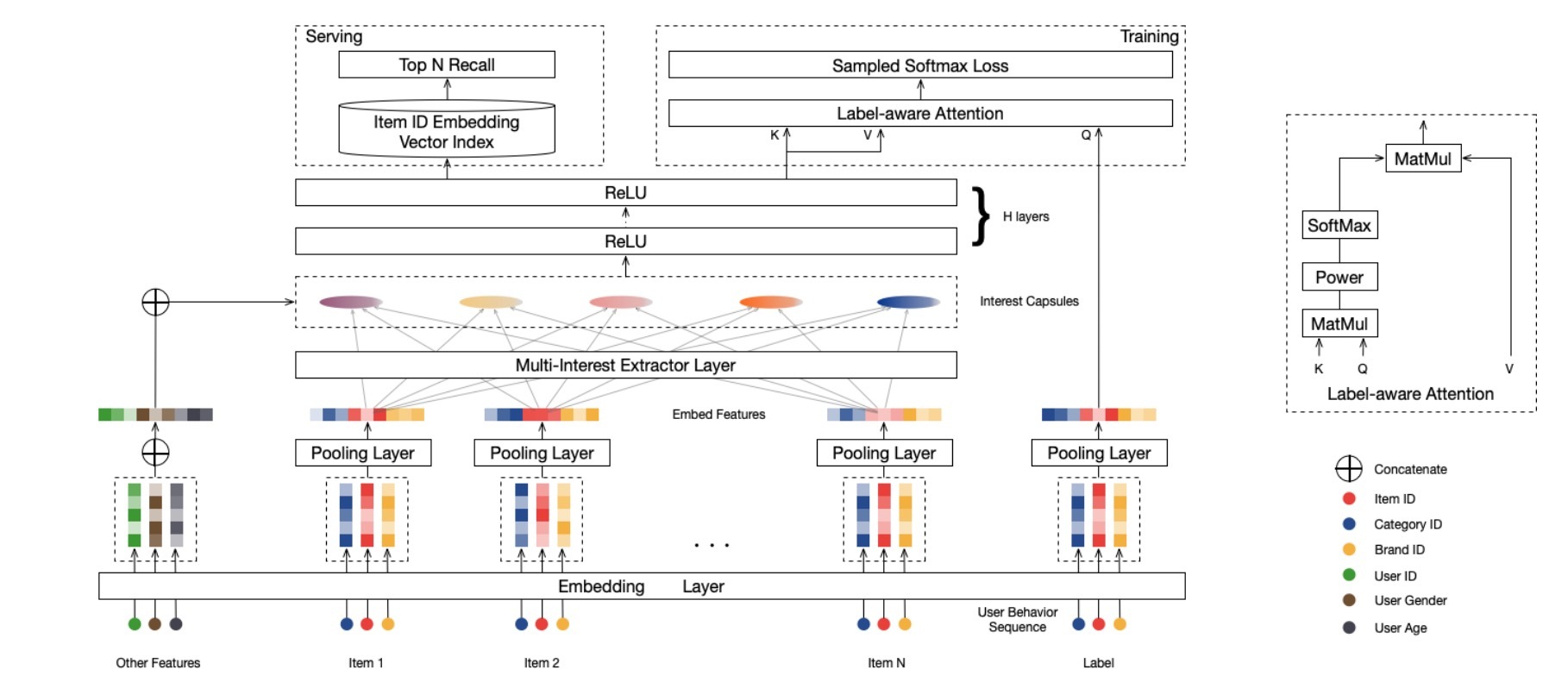
图2 MIND总览。MIND会使用用户行为、用户profile特征作为输入,输出用户表示向量(vectors)以便在matching stage时做item检索。input layer的ID特征通过embedding layer被转换成embeddings,每个item的embeddings(item_id, cat_id, brand_id都会有embedding)会进一步通过一个pooling layer进行平均。用户行为embeddings被feed给multi-interest extractor layer,它会生成interest capsules。通过将interest capsules与user profile embedding进行拼接,并通过一些ReLU layers将concatenated capsules进行转换,可以获得用户表示向量(vectors)。在训练期间,一个额外的label-aware attention layer被引入到指导训练过程。在serving时,多个用户表示向量通过一个ANN查询方式被用于检索items。
如图2所示,MIND的输入包含了三个groups:user profile \(P_u\),user behavior \(I_u\),label item \(F_i\)。每个group包含了许多类别型特征(categorical id features),这些id features具有极高的维度。例如,item ids的数目是数十亿的,因而,我们会采用广泛使用的embedding技术来将这些id features嵌入到低维dense vectors(a.k.a embeddings)中,这会极大减小参数数目,并减缓学习过程。对于来自\(P_u\)的id features(gender、age等),相应的embeddings会进行拼接(concatenated)来形成user profile embedding \(\vec{p}_u\)。对于item ids、以及其它类别型ids(brand id, shop id等),对于来自\(F_1\)的冷启动items[25],它已经被证明是有用的[25],相应的embeddings会进一步通过一个average pooling layer来形成label item embedding \(\vec{e}_i\)。最后,对于来自user behavior \(I_u\)的items,相应的item embeddings被组合来形成user behavior embedding \(E_u = \lbrace \vec{e}_j, j \in I_u \rbrace\)。
3.3 Multi-Interest Extractor Layer
我们认为,通过一个表示向量来表示用户兴趣,这对于捕获用户多样化兴趣是个瓶颈,因为我们必须将与用户的多样化兴趣相关的所有信息压缩到一个表示向量中。因而,关于用户的多样化兴趣的所有信息,是混合在一起的,对于matching stage来说这会造成错误的item检索。作为替代,我们采用多个表示向量来单独表示用户的不同兴趣。通过该方法,用户的多样化兴趣在matching stage中会被单独对待,对于每个方面的兴趣,使得item检索更精准。
为了学习多种表示向量,我们会使用聚类过程来将用户的历史行为group成一些clusters。在一个cluster中的items被认为是相互更接近的,可以表示用户兴趣的某个特定方面。这里,我们会设计multi-interest extractor layer来对历史行为进行聚类和并对生成的聚类进行inferring表示向量。由于multi-interest extractor layer的设计受最近提出的dynamic routing[13,14,21]的启发,我们首先回顾必要的基础,以便使该paper可以自圆其说。
3.3.1 Dynamic Routing
我们简短介绍capsules表征学习的dynamic routing[21],这是表示向量的一种新的neural units形式。假设我们有两层capsules,我们将第一层看成是low-level capsules,将第二层的capsules看成是high-level capsules。dynamic routing的目标是,给定low-level capsules,以迭代方式计算high-level capsules的值。在每轮迭代中,给定的low-level capsules \(i \in \lbrace 1, \cdots, m \rbrace\),它相应的向量为:
\[\vec{c}_i^l \in R^{N_l \times 1}, i \in \lbrace 1,\cdots,m \rbrace\]high-level capsules \(j \in \lbrace 1, \cdots, n \rbrace\),它相应的向量为:
\[\vec{c}_j^h \in R^{N_h \times 1}, j \in \lbrace 1, ..., n \rbrace\]在low-level capsule i和high level capsule j之间的routing logit \(b_{ij}\),可以通过以下公式计算(注:hinton paper中的\(\hat{u}_{j \mid i}\)在此处被展开,\(S_{ij}\)即hinton paper中的\(W_{ij}\)):
\[b_{ij} = (\vec{c}_j^h)^T S_{ij} \vec{c}_i^l\]…(4)
其中,\(S_{ij} \in R^{N_h \times N_l}\)表示要学习的bilinear mapping matrix。T表示transpose。
有了routing logits,对于high-level capsule j的候选向量(candidate vector),可以(注:\(w_{ij}\)即hinton paper中的\(c_{ij}\)耦合系数):
\[\vec{z}_j^h = \sum\limits_{i=1}^m w_{ij} S_{ij} \vec{c}_i^l\]…(5)
其中,\(w_{ij}\)表示连接low-level capsule i和high-level capsule j的权重,可以通过在routing logits上执行softmax计算得到:
\[w_{ij} = \frac{exp (b_{ij})}{ \sum\limits_{k=1}^m exp (b_{ik})}\]…(6)
最后,使用一个非线性”squash”函数来获得high-level capsules的vectors:
\[\vec{c}_j^h = squash(\vec{z}_j^h) = \frac{\| \vec{z}_j^h \|^2}{ 1 + \| \vec{z}_j^h \|^2} \frac{\vec{z}_j^h}{ \| \vec{z}_j^h \|}\]…(7)
\(b_{ij}\)的值被初始化为0, routing process通常会重复三次以便收敛。当routing完成时,high-level capsule的值\(\vec{c}_j^h\)是确定的,可以被当作是next layers的inputs。
3.3.2 B2I Dynamic Routing
简单来说,capsule是一种新型neuron,它由一个vector表示,而非在普通神经网络中使用的一个标量(scalar)。vector-based capsule被认为是能够表示一个实体的不同属性,在其中,一个capsule的方向(orientation)可以表示一个属性(property),capsule的长度被用于表示该属性存在的概率(probability)。相应的,multi-interest extractor layer的目标是,为用户兴趣的属性(properties)通过学习得到表示(representations)以及学习是否存在相应的兴趣(representations)。在胶囊(capsules)和兴趣表示(interest representations)间的语义关联启发我们将行为/兴趣表示(behavior/interest representations)看成是行为/兴趣胶囊(behavior/interest capsules),并使用dynamic routing来从behavior capsules中学习interest capsules。然而,原始routing算法是为图像数据而提出的,并不能直接应用到处理用户行为数据上。因此,我们提出了Behavior-to-Interest(B2I) dynamic routing来自适应地将用户行为聚合到兴趣表示向量(interest representation vectors)中,它与原始的routing算法有三个不同之处:
1.Shared bilinear mapping matrix.
在原始版本的dynimic routing中,每个(low-level capsules, high-level capsules) pair,会使用一个单独的bilinear mapping matrix;我们的版本则会使用固定(fixed)的bilinear mapping matrix S来替换,这是由于两方面的考虑:
- 一方面,用户行为是变长的,对tmall用户来说,范围从几十到几百不等,因而,使用固定的bilinear mapping matrix是可泛化推广(generalizable)的
- 另一方面,我们希望interest capsules位于相同的向量空间中,但不同的bilinear mapping matrice会将interest capsules映射到不同的向量空间上。从而,routing logit可以通过以下公式计算:
…(8)
其中:
- \(\vec{e}_i \in R^d\)表示behavior item i的embedding
- \(\vec{u}_j \in R^d\)表示interest capsule j的向量。
- bilinear mapping matrix \(S \in R^{d \times d}\)是跨每个(behavior capsules, interest capsules) pairs间共享的。
2.随机初始化routing logits
由于使用共享的bilinear mapping matrix S,将routing logits初始化到0可能会导致相同初始化的interest capsules。接着,后续的迭代可能会陷入这样的情形,不同的interest capsules在所有时刻都会相同。为了消除该现象,我们会使用高斯分布\(N(0, \sigma^2)\)来抽样一个random matrix来初始化routing logits,使得初始的interest capsules相互间都不同,这与K-means聚类算法相类似。
3.动态兴趣数(Dynamic interest number)
由于不同用户的interest capsules的数目会有不同,我们引入一个启发式规则来为不同用户自适应调整K值。特别的,用户u的K值可以通过下式进行计算(注:\(\mid I_u \mid\)表示用户行为item数):
\[K_u' = max(1, min(K, log_2(|I_u|)))\]…(9)
对于那些具有更少兴趣的users,调整interest capsules数目的策略,可以节省一些资源(包括计算资源和内存资源)。
整个dynamic routing过程如算法1所示。

算法1
3.4 Label-aware Attention Layer
通过多兴趣抽取层(multi-interest extractor layer),从用户的行为embeddings可以生成许多的interest capsules。不同的interest capsules表示用户兴趣的不同方面,相关的interest capsule被用于评估在指定items上的用户偏好。因而,在训练期间,我们设计了一个label-aware attention layer,它基于缩放点积注意力(scaled dot-product attention)[24]机制,可以让target item选择要使用哪个interest capsule。特别的,对于一个target item,我们会计算每个interest capsule和target item embedding间的兼容性(compatibilities),并计算一个关于interest capsules的加权求和来作为该target item的用户表示向量,其中,一个interest capsule的权重由相应的兼容性(compatibility)所决定。在label-aware attention中,label是query,interest capsules是keys和values,如图2所示。user u对于item i的output vector,可以计算如下:
\[\begin{align} \vec{v}_u & = Attention (\vec{e}_i, V_u, V_u) \\ & = V_u softmax(pow(V_u^T \vec{e}_i, p)) \end{align}\]其中:
- pow表示element-wise指数操作符(exponentiation oprator),pow(x,y)表示x的y次幂;
- p是一个可调参数,用于调节attention分布。当p接近0时,每个interest capsule趋向于接收偶数(even)attention。当p大于1时,随着p的增加,该值会大于点乘,会接受越来越多的权重。考虑到极限的情况,当p无穷大时,attention机制会变成一种hard attention,它会选中具有最大attention的值,并忽略其它。在我们的实验中,我们发现:使用hard attention会导致更快的收敛。
其它:
- \(\vec{e}_i\)表示target item i的embedding
- \(V_u\):用户u的表示向量,共由K个interest capsules组成
- \(\vec{v}_u\):user u对于item i的output vector
3.5 Training & Serving
有了user vector \(\vec{v}_u\)和label item embedding \(\vec{e}_i\),我们可以计算user u和label item i间的概率:
\[Pr(i | u) = Pr(\vec{e}_i | \vec{v}_u) = \frac{exp(\vec{v}_u^T \vec{e}_i)}{ \sum_{j \in I} exp(\vec{v}_u^T \vec{e}_j)}\]…(10)
接着,对于训练MIND的整个目标函数为:
\[L = \sum\limits_{(u,i) \in D} log Pr(i|u)\]…(11)
其中,D是包含user-item交互的训练数据集。由于items数目的规模为数十亿,(10)的分母的sum操作在计算上是不可行的。因而,我们使用sampled softmax技术[7]来使目标函数可追踪,并使用Adam optimizer来训练MIND。
在训练后,除了label-aware attention layer外的MIND网络可以被用于user representation mapping函数:\(f_{user}\)。在serving时,用户的行为序列和user profile会feed给\(f_{user}\)函数,为用户生成多个表示向量。接着,这些表示向量通过一个近似最近邻(ANN)方法[15]被用于检索top N个items。对于matching stage,具有与user representation vectors最高相似度的那些items,可以被检索并组合候选items的最终集合。请注意,当一个用户具有新动作时,他的行为序列、以及相应的user representation vectors也会被更改,因而,MIND可以在matching stage上用于实时个性化召回。
3.6 与已存在方法的联系
这里,我们比较了MIND与其它两种已存在方法的关系,展示了相似之处和不同之处。
Youtube DNN. MIND和Youtube DNN都使用深度神经网络来建模用户行为数据并生成用户表示,都被用于在matching stage上检索海量item。然而,Youtube DNN只使用一个vector来表示一个用户,而MIND使用多个vectors。当在算法1中K的值为1时,MIND退化成Youtube DNN,而MIND可以看成是Youtube DNN的泛化(generalization)。
DIN. DIN可以捕获用户的多样化兴趣,MIND和DIN具有相似的目标。然而,这两种方法在达成该目标以及应用上各不相同。为了处理多样化兴趣,DIN会在item级别使用一个attention机制,而MIND使用dynamic routing来生成interest capsules,并在interest level考虑多样性。再者,DIN关注在ranking stage处理上千的items,而MIND会解耦inferring用户表示和衡量user-item兼容性,使它应用于在matching stage上海量items的召回。
4.实验
4.1 离线评估
4.2 超参数分析
在本节中,我们在Amazon Books数据集上做了关于multi-interest extractor layer和label-aware attention layer的超参数的实验。
routing logits的初始化
对于在multi-interest extractor layer中的routing logits,我们采用随机初始化,它与K-means中心点的初始化类型,其中,初始簇心的分布对于最终的聚类结果有很强的影响。由于routing logits是根据高斯分布\(N(0, \sigma^2)\)进行初始化的,我们会关于\(\sigma\)的不同值是否会导致不同的收敛,从而影响效果。为了研究\(\sigma\)的影响,我们使用3个不同的\(\sigma\)值:0.1, 1, 5来初始化routing logits \(b_{ij}\). 结果如图3所示,3个值的每条曲线几乎重叠。该观察表明MIND是对\(\sigma\)值是健壮的。对于实际应用,我们使用\(\sigma=1\)。
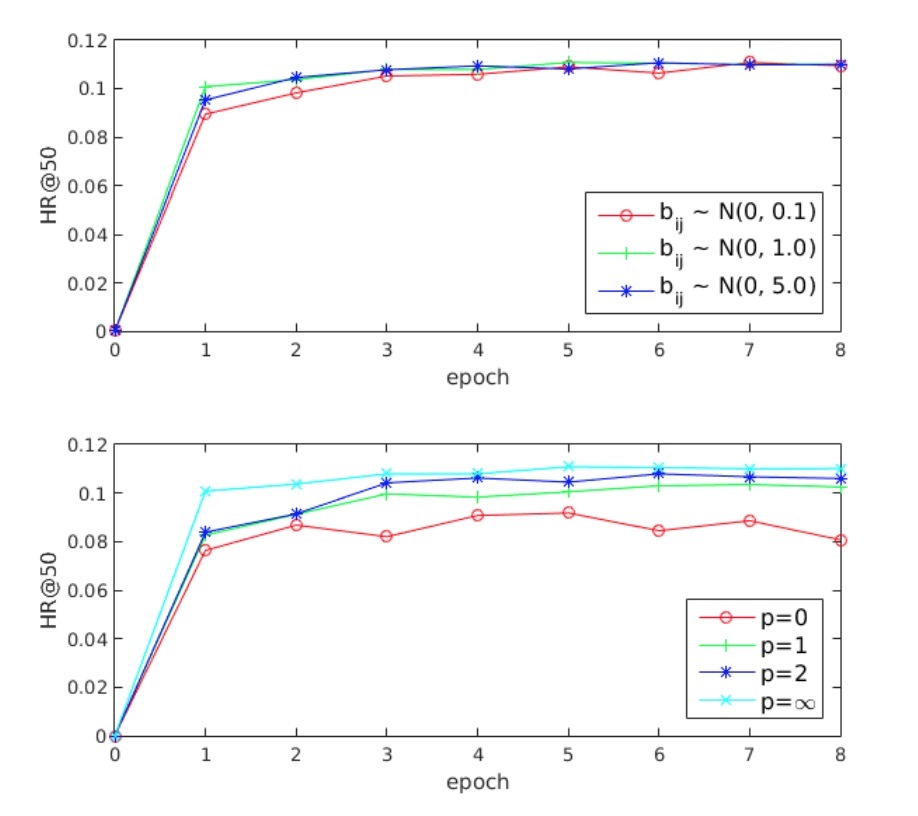
图3 超参数的影响。上部展示了MIND使用不同\(\sigma\)的结果;下部展示了MIND中p越大,效果越好
在label-aware attention中的power数。正如前所述,在label-aware attention中的power number p控制着每个兴趣在组合的label-aware interest representation中的的比例。我们对p从0到\(\infty\)做了比较,结果如图3所示。很明显,p=0的效果要比其它要差。原因是,当采用p=0时,每个兴趣具有相同的attention,因而,组合起来的兴趣表示(interest representation)等到兴趣的平均,与label无关。如果\(p \ge 1\),attention scores与兴趣表示向量和target item embeddings间的相似度成比例,这使得组合兴趣表示是一个关于兴趣的加权求和。结果表明,随着p的增大,效果会越好,因为与target item更相似的兴趣的表示向量会获得更大的attention。当\(p = \infty\)时,它会变为一个hard attention scheme。通过该scheme,与target item接近的兴趣表示会主导着组合兴趣表示,从而使得MIND收敛更快,效果更好。
4.3 在线实验
通过部署MIND在tmall主页上处理真实流量持续一周,我们开展在线实验。为了公平比较,所有方法在matching stage阶段进行部署,并采用相同的ranking过程。我们使用CTR来衡量online serving流量的效果。
有两种baseline方法进行在线实验。一个是item-based CF,它服务在线流量中的matching算法占居主要地位。另一个是Youtube DNN。我们在一个A/B test框架中部署了所有要比较的方法,它们feed给ranking stage并给出最终推荐。
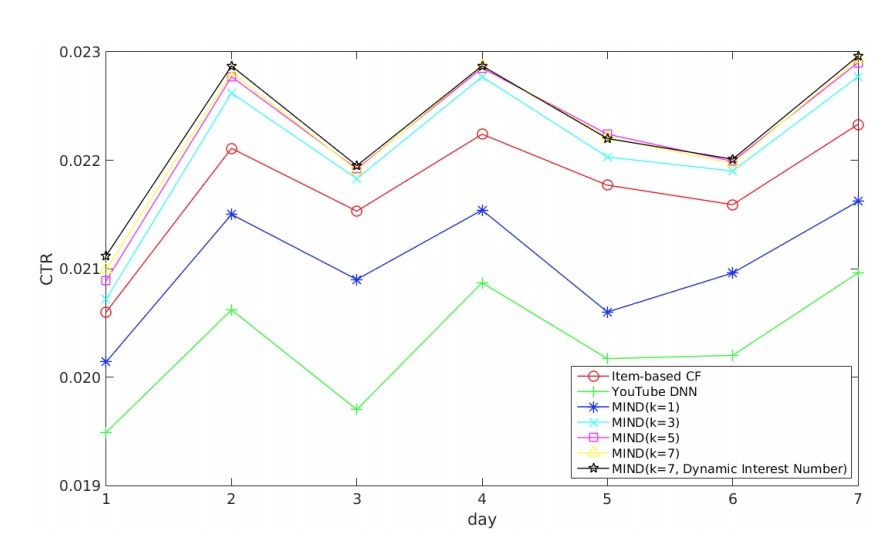
图4
实验结果如图4所示。很明显MIND的效果要好于item-based CF和youtube DNN,这表示MIND生成了一个更好的user representation。另外,我们做出了以下观察:
- 1) 通过长期实践的优化,item-based CF的效果要好于YouTube DNN,它也超过具有单个兴趣的MIND算法。
- 2) 另一个显著的趋势是,MIND的效果会随着抽取的兴趣数的增加而变好(从1到5)。
- 3) 当抽取的兴趣数为5时,MIND的效果达到峰值,这之后,CTR保持数据,兴趣数达到7的提升可以忽略。
- 4) 使用动态兴趣数(dynamic interest number)的MIND与具有7个兴趣的MIND效果相当。
从上述观察来看,我们可以做出一些结论。
- 首先,对于Tmall,用户兴趣的最优数目是5-7, 这可以表示用户兴趣的平均多样性(diversity)。
- 第二,动态兴趣数机制并不能带来CTR增益,但在实验期间,我们意识到该scheme可以减少serving的开销,这有利于tmall这样的大规模服务,在实际上更易接受。
总之,在线实验验证了MIND对于建模多样化兴趣的效果,并能极大提升整体RS。
4.4 案例研究
4.4.1 耦合系数
在behavior capsules和interest capsules间的耦合系数,可以量化行为和兴趣级的等级关系。在这一节,我们将这些耦合系数可视化,来展示兴趣抽取过程的可解释性。
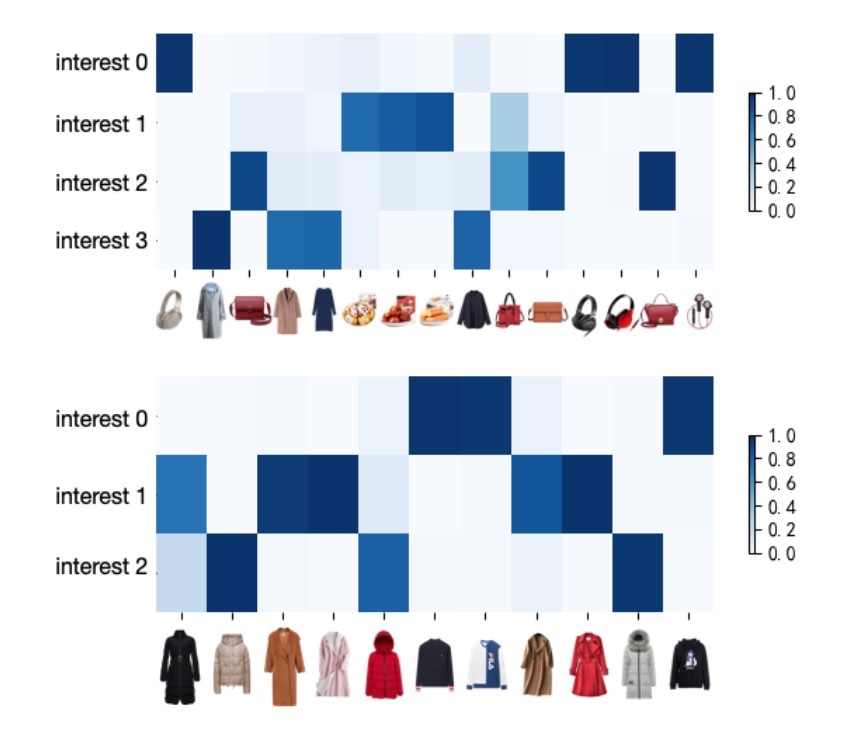
图5
图5展示了从tmall日活用户中随机抽取的两个用户相关的耦合系数,每一行对应于一个interest capsule,每一列对应于一个behavior。它展示了用户C(上)与4个类别的商品(耳机(headphones)、小吃(snacks)、手提包(handbags)、衣服(clothes))有交互,每个商品都在一个interest capsule上具有最大解耦系数,并形成了相应的兴趣。而用户D(下)只在衣服上(clothes)有兴趣,因而,从行为中看到该用户具有3个细粒度的兴趣(毛衣(sweaters)、大衣(overcoats)、羽绒衣(down jackets))。关于该结果,我们证实了user behaviors的每个类都可以聚类在一起,并形成相应的兴趣表示向量。
4.4.2 item分布
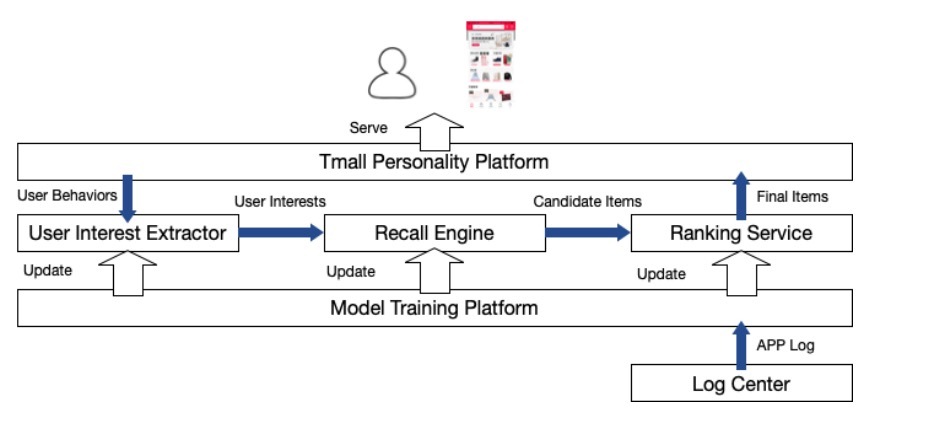
图6
在serving时,与user兴趣相似的items通过最近邻搜索进行检索。我们基于相应兴趣的相似度,对这些通过单个兴趣召回的items的分布进行可视化。图6展示了图5中提到的相同用户(user C)的item分布。该分布分别通过两种方法获取,其中上面的轴4展示了基于MIND通过4个兴趣召回的items,而最下面的轴展示了基于Youtube DNN的结果。items根据它们与兴趣的相似度分散在轴上,通过最大最小归一化法归一化到0~1, 并围绕在0.5附近。上面的一个点指的是在一定范围内的组成的items,因而每个点的大小(size)表示了在相应相似度中items数目。我们也展示了从所有候选中随机选中的一些items。正如所预料的,通过MIND召回的items与对应的兴趣强相关,而Youtube DNN则会与items的类目更宽泛些,它们与用户行为具有较低相似度。
5.系统部署
图7
当用户加载Tmall APP时,推荐请求会被发送给Tmall Personality Platform,该server集群会将一大堆插件式模块进行集成,并作为在线推荐进行服务。用户最近的行为会通过Tmall Personality Platform进行检索到,并将它发送给User Interest Extractor,它是实现MIND的主模块,用于将用户行为转换成多个user interests。接着,Recall Engine会搜索与user interests最近的embedding vectors相关的items。由不同兴趣触发的items会被合成候选items,并通过用户兴趣的相似度进行排序。从海量item池中选择上千个候选items的整个过程通过User Interest Extractor和Recall Engine来完成,整个过程小于15ms,由于基于MIND的serving的高效性,在items范围和系统响应时间间的tradeoff,这些候选items的top 1000可以通过Ranking Service(它会使用一堆特征来预测ctr)进行打分。最终,Tmall个性化平台会完成最终展示给用户的推荐结果item列表。User Interest Extractor和Ranking Service在Model Training Platform上会使用100 GPUs进行训练,训练过程会执行8个小时。受益于Model Training Platform的高性能,用于预测服务的深度网络会每天更新一次,可以保证最新的商品被计算和被曝光。