yahoo在2010年在《A contextual-bandit approach to personalized news article recommendation》中介绍了contextual bandit算法。
2.公式&相关工作
在本节,我们定义了K-armed contextual bandit问题,作为示例,展示了如何用它来建模个性化新闻推荐问题。
2.1 Multi-armed Bandit公式
个性化新闻推荐的问题可以天然建模成:带context信息的multi-armded bandit问题。根据[18],我们称之为”contextual bandit”。正式的,一个contextual-bandit算法A会以离散方式处理实验(trials) t=1,2,3,…,在试验t上,有:
- 1.该算法会观察当前用户\(u_t\)和一个关于arms或actions的\(A_t\)集合,以及对于arm \(a \in A_t\)的它们的特征向量(feature vectors) \(x_{t,a}\)。 vector \(x_{t,a}\)会同时总结用户\(u_t\)和arm a的信息,被称为context。
- 2.基于在之前实验中的已观察收益(observed payoffs),算法A会选择一个arm \(a_t \in A_t\),并得到新的收益(payoffs): \(r_{t,a_t}\),它的期望取决于user \(u_t\)和arm \(a_t\)两者
- 3.算法接着使用新的observation \((x_{t,a_t}, a_t, r_{t,a_t})\)提升它的arm-selection策略。这里需要重点强调的是:对于未选中的arms \(a \neq a_t\),此处没有观察到feedback(也就是:payoff \(r_{t,a}\))。
上述过程中,算法A的total T-trial payoff被定义成:\(\sum_{t=1}^T r_{t,a_t}\)。相似的,我们将它的最优期望定义为:\(E[\sum_{t=1}^T r_{t,a_t^*}]\),其中\(a_t^*\)是在实验t中具有最大期望payoff的arm。我们的目标是:设计一个算法A以便total payoff期望最大化。也相当于:我们会发现一个算法,以便对应各最优的arm-selection策略的regret最小化。这里,T-trail regret \(R_A(T)\)被定义为:
\[R_A(T) \equiv E[\sum\limits_{t=1}^T r_{t,a_t^*}] - E[\sum\limits_{t=1}^T r_{t,a_t}]\]…(1)
一般的contextual bandit问题的一个重要特例是:著名的K-armed bandit,其中:
- (i) arm set \(A_t\)保持不变,对于所有t都包含K个arms
- (ii) user \(u_t\)(或者相等的,context \(x_{t,1}, \cdots, x_{t,K}\))对于所有t都相同
因此,在每个实验中的arm set和contexts两者都是常数,对于一个bandit算法来说没啥区别,因此我们可以将该类型的bandit称为是一个context-free bandit。
在文章推荐的场景中(context),我们将池子中的文章(articles)看成是arms。当一篇曝光的文章被点击时,会带来一个等于1的payoff;否则payoff为0。有了关于payoff的该定义,一篇文章的期望(expected)payoff就是它的点击率(ctr),使用最大CTR来选择一篇文章等价于从最大化用户点击数目的期望,这与在我们的bandit公式中最大化总期望payoff(total expected payoff)相同。
再者,在网络服务中,我们通常会访问用户信息,它们被用于推断一个用户的兴趣,并用来选择他可能感兴趣的新闻文章。例如,对于一个男青年来说,他很可能对iPod产品的文章感兴趣,而非对退休计划的文章感兴趣。因此,我们会通过一个可以密切描述它们的关于信息特征的集合来“总结(summarize)”用户(users)和文章(articles)。通过这样做,一个bandit算法可以从一个 文章/用户 泛化(generalize) CTR信息给另一个文章/用户,并能学到更快地选择好的文章,特别是对于新用户和新文章。
2.2 已存在的Bandit算法
bandit problems的基本挑战是,需要对exploration和exploitation做平衡。为了最小化等式(1)中的regret(越小表示两者越接近),一个算法A会利用(exploits)它的过往经验来选择看起来最好的arm。另一方面,看起来最优的arm可能在实际上是次优的,因为在算法A的知识(knowledge)中是不精准的(imprecision)。为了避免这种不希望的情况,算法A必须通过实际选择看起来次优的arms来进行explore,以便收集关于它们的更多信息(在bandit过程中的step 3在之前的章节已定义)。Exploration可以增加short-term regret,因为会选到一些次优的arms。然而,获得关于arms的平均payoffs信息(例如:exploration)可以重新定义(refine)算法A的arms payoffs,从而减小long-term regret。通常,即不会存在一个纯粹的exploring,也不会存在一个纯粹的exploiting算法,需要对两者做平衡。
context-free K-armed bandit问题已经被统计学家研究过许多。一种最简单和最直接的算法是ε-greedy。在每个实验t中,该算法会首先估计每个arm a的平均payoff \(\hat{\mu}_{t,a}\)。接着使用概率\(1 - e\)来选择greedy arm(例如:具有最高payoff估计的arm);使用概率e来选择一个random arm。在极限上,每个arm会尝试无限次,以便payoff估计\(\hat{\mu_{t,a}}\)会收敛到具有概率为1的真值(true value)\(\mu_a\)。另外,通过对e进行适当的衰减(decaying),每一step的regret \(R_A(T)/T\)会收敛到0, 概率为1.
对比于ε-greedy所采用的无向导(unguided)的exploration策略,另一类算法通常被称为UCB算法(upper confidence bound算法),它使用一个更聪明的方式来对E&E进行平衡。特别的,在实验t中,这些算法会同时估计:每个arm a的平均payoff \(\hat{\mu}_{t,a}\)、以及一个相应的置信区间\(c_{t,a}\),以便\(\mid \hat{\mu}_{t,a} - \mu_a\mid < c_{t,a}\)具有较高的概率。它们接着选接arm来达到一个最高的上限置信边界(UCB):\(a_t = argmax_a (\hat{\mu}_{t,a} + c_{t,a})\)。由于合理地定义了置信区间,这样的算法具有一个较小的total T-trail regret,它是trials T的总数的log倍,看起来是最优的。
而context-free K-armed bandits最近被广泛研究,最通用的contextual bandit问题仍然充满挑战。EXP4算法[8]使用指数加权技术来达到一个\(\hat{O}(\sqrt{T})\)的regret,但计算复杂度是特征数的指数倍。另一个常用的contextual bandit算法是epoch-greedy算法[18],它与使用shrinking ε的ε-greedy相似。该算法计算更高效,给定一个oracle optimizer,但具有更弱的regret guarantee:\(O(T^{2/3})\)。
具有更强regret guarantees的算法可以在关于bandit的许多建模假设下被设计。假设一个arm的期望payoff在它的特征中是线性的,Auer[6]描述了LinRel算法,它本质上是一种UCB-type方法,并展示了它的变种之一具有一个regret:\(\hat{O}(\sqrt{T})\),比其它算法有极大提升。
最终,我们注意到,存在另一种基于Bayes rule的bandit算法,比如:Gittins index方法。由于合理定义了先验分布,Bayesian方法具有良好的效果。这些方法需要大量离线工程来获得较好的先验模型.
3.算法
对于context-free bandit算法,给定了渐定最优性(asymptotic optimality)以及较强的regret bound UCB方法;我们可以为contextual bandit问题尝试设计相似的算法。给定关于payoff函数的参数形式,存在许多方法来从数据中估计参数的置信区间,从而我们可以计算估计后的arm payoff的一个UCB。然而,通常这样的方法代价高。
在该工作中,我们展示了:当payoff模型是线性时,一个置信区间可以以closed form的形式高效计算,我们称该算法为LinUCB。出于表述(exposition)的需要,我们首先描述了disjoint线性模型的更简单形式,接着将在3.2节中考虑hybird模型的一般形式。我们注意到:LinUCB是一个通用的contextual bandit算法,它可以应用到其它应用中,而非个性化新闻推荐上。
3.1 不相交(disjoint)线性模型的LinUCB
使用2.1节的概念,我们假设:一个arm a的期望payoff在d维特征\(x_{t,a}\)上是线性的,它具有一些未知系数向量(coefficient vector)\(\theta_a^*\);对于所有t:
\[E[r_{t,a} | X_{t,a}] = X_{t,a}^T \theta_a^*\]…(2)
该模型称为disjoint的原因是:不同arms间的参数不共享(每个arm各有一组权重,与d维特征存在加权关系得到期望payoff)。假设:
- \(D_a\)是在实验t上的一个m x d维的设计矩阵(design matrix),它的行对应于m个训练输入(例如:对于文章a,之前已经观察到的m个contexts)
- \(c_a \in R^m\)是相应的响应向量(corresponding response vector) (例如:相应的m个 点击/未点击 user feedback) (注:paper写的是\(b_a\)而非\(c_a\),应该是笔误)
我们将岭回归(ridge regression)应用到训练数据\((D_a, c_a)\)上,给定了系数的一个估计(即伪逆):
\[\hat{\theta}_a = (D_a^T D_a + I_d)^{-1} D_a^T c_a\]…(3)
其中:\(I_d\)是d x d的identity matrix。当在\(c_a\)中的元素(components)与\(D_a\)中相应行是条件独立时,它至少具有\(1 - \delta\)的概率:
\[| x_{t,a}^T \hat{\theta}_a - E[r_{t,a} | x_{t,a}] | \leq \alpha \sqrt{x_{t,a}^T (D_a^T D_a + I_d)^{-1} x_{t,a}}\]…(4)
对于任意的\(\delta > 0\)以及\(x_{t,a} \in R^d\),其中\(\alpha = 1 + \sqrt{ln(2/\delta) / 2}\)是一个常数。换句话说,上述不等式为arm a的期望payoff给出了一个合理的紧凑的UCB,从中生成一个UCB-type arm-selection策略,在每个实验t上,选择:
\[a_t \equiv argmax_{a \in A_t} (x_{t,a}^T \hat{\theta}_a + \alpha \sqrt{x_{t,a}^T A_a^{-1} x_{t-a}})\]…(5)
其中:\(A_a \equiv D_a^T D_a + I_d\)。
在等式(4)中的置信区间可以受其它准则的启发。例如, ridge regression可以被解释成一个Bayesian点估计,其中系数向量的后验分布被表示成:\(p(\theta_a)\),它是一个关于(mean=\(\hat{\theta}_a, covariance=A_a^{-1})\))的高斯分布。给定当前模型,期望payoff \(x_{t,a}^T \theta_a^*\)的预测变量被评估成\(x_{t,a}^T A_a^{-1} x_{t,a}\),接着\(\sqrt{x_{t,a}^T A_a^{-1} x_{t,a}}\)变为标准差。接着,在信息论中,\(p(\theta_a)\)的微分熵被定义成:\(-\frac{1}{2} ln((2 \pi)^d det A_a)\)。当\(p(\theta_a)\)的熵由new point \(x_{t,a}\)的杂质(inclusion)更新时,接着变为:\(-\frac{1}{2} ln((2 \pi)^d det (A_a + x_{t,a} x_{t,a}^T))\)。模型后验的熵减(entropy reduction)是\(\frac{1}{2} ln(1 + x_{t,a}^T A_a^{-1} x_{t,a}\)。该质量(quatity)通常被用于估计来自\(x_{t,a}\)的模型提升。因此,在等式(5)中的arm selection的准则可以被认为是在payoff估计和model uncertianty reduction间的一个额外的trade-off。

算法1
算法1给出了一个关于整个LinUCB算法的详细描述。只有输入参数\(\alpha\)。注意,在等式(4)中给定的\(\alpha\)值在一些应用中会比较大,因此对这些参数最优化实际可能会产生更高的total payoffs。不同于所有的UCB方法,LinUCB总是会选择具有最高UCB的arm(正如等式(5)中).
该算法具有一些良好的性质。
- 1.它的计算复杂度对于arms的数量来说是线性的,对于特征数目最多是三次方。为了减少计算量,我们可以在每一step中更新\(A_{a_t}\),周期性计算和缓存\(Q_a \equiv A_a^{-1}\),而非实时。
- 2.该算法对于一个动态的arm set来说工作良好,仍能高效运行,只要\(A_t\)的size不能太大。该case在许多应用中是true的。例如,在新闻文章推荐中,编辑会从一个池子中添加/移除文章,池子的size本质上是个常数。
- 3.尽管不会该paper的重点,我们仍会采用[6]的分析来展示:如果arm set \(A_t\)是确定的,包含了K个arms,接着置信区间(比如:等式(4)的右手边)会随着越来越多的数据快速减小,接着证明\(\hat{O}(\sqrt{KdT})\)的强regret bound,匹配满足等式(2)的bandits的state-of-art结果[6]。这些理论结果预示着算法的基础牢固以及高效性。
最后,我们注意到,在该假设下,输入特征\(x_{t,a}\)会从一个正态分布中i.i.d的方式抽出,Pavlidis[22]提出了一个相似的算法,它使用一个最小二乘解\(\hat{\theta_a}\)来替代我们的ridge-regression解 (等式(3)中的\(\hat{\theta_a}\))来计算UCB。然而,我们的方法更通用,当输入特征不稳定时仍合量(valid)。更重要的是,我们在下一节中讨论了,如何将算法1展开到一个更有意思的case。
3.2 Hybrid线性模型的LinUCB
算法1计算了矩阵的逆,\(D_a^T D_a + I_d\)(或者:\(D_a^T D_a\)),其中\(D_a\)是design matrix,它的行对应于训练数据中的特征。所有arms的这些矩阵具有固定维度d x d,可以高效地进行增量更新。另外,它们的逆( inverses)可以通过算法1的disjoint参数很方便地进行计算:在等式(3)中的解\(\hat{\theta}_a\)不会被其它arms的数据数据所影响,因为计算是独立的。我们现在考虑使用hybrid模型的case。
在许多应用中(包含新闻推荐),除了arm-specific情况之外,所有arms都会使用共享特征。例如,在新闻文章推荐中,一个用户可能只偏爱于政治文章,因而可以提供这样的一种机制。因此,同时具有共享和非共享components的特征非常有用。正式的,我们采用如下的hybrid模型来额外添加其它的线性项到等式(2)的右侧:
\[E[r_{t,a} | x_{t,a}] = z_{t,a}^T \beta^* + x_{t,a}^T \theta_a^*\]…(6)
其中:
- \(z_{t,a} \in R^k\)是当前user/article组合的特征
- \(\beta^*\)是一个未知的系数向量(coefficient vector),它对所有arms是共享的
该模型是hybrid的,广义上系数\(\beta^*\)的一些参数是会被所有arms共享的,而其它\(\theta_a^*\)则不会。

算法2
对于hybrid模型,我们不再使用算法1作为多个不相互独立的arms的置信区间,因为它们共享特征。幸运的是,有一种高效方式来计算一个UCB,与之前章节相似。该导数(derivation)严重依赖于块矩阵转置技术。由于空间限制,我们给出了算法2的伪码(第5行和第12行会计算关于系数的redge-regression的解,第13行会计算置信区间),详细导数见完整paper。这里我们只指出了重要的事实:
- 1.由于算法中使用的构建块(\(A_0, b_0, A_a, B_a, b_a\))具有固定的维度,可以进行增量更新,该算法计算十分高效。
- 2.另外,与arms相关联的质量(quatities)在\(A_t\)中并不存在,因而在计算量上不再相关。
- 3.最后,我们也周期性地计算和缓存了逆(\(A_0^{-1}\)和\(A_a^{-1}\)),而非在每个实验尾部来将每个实验的计算复杂度\(O(d^2 + k^2)\)。
4.评估技术
对比在一些标准监督机器学习setting,contextual bandit setting的评估是相当难的。我们的目标是评估一个bandit算法\(\pi\)的效果,也就是说,在每个time step上选择一个arm的规则会基于之前的交互来完成(比如:上述算法描述的)。由于该问题的天然相交特性,看起来只能在真实数据上运行该算法。然而,实际上,该方法可能不可行,因为严重的logistical挑战。更确切的说,我们只具有离线数据提供,它们使用一整个不同的日志策略(logging policy)在之前收集得到。由于payoffs只会被logging policy选中的arms所观察到,它们很可能通常与被评估的算法\(\pi\)所选中的不同。该评估问题可以看成是在增强学习中“off-policy evaluation problem”的一个特例。
一种解决方案是:构建一个模拟器(simulator)来从日志数据中建模bandit过程,接着使用该simulator来估计\(\pi\)。然而,modeling step会引入在simulator中的bias,使它很难满足这种simulator-based评估方法的可靠性。作为对比,我们提出了一种方法:它很容易实现,基于日志数据,并且是无偏的(unbiased)。
在该节中,我们描述了一种被证明可靠的技术来执行这样的评估。假设,单独事件是i.i.d的,被用于收集日志数据的logging policy会在每个time step上随机均匀的方式选中任一arm。尽管我们会忽略细节,后面的假设会变弱,以便任何随机的logging policy会被允许,我们的解决方案可以根据使用rejection sampling来进行修改,但代价是降低了效果。
更精确的是,我们假设:一些已知分布D,从中进行i.i.d.抽取tuples:\((x_1, \cdots, x_K, r_1, \cdots, r_K)\),每个tuple包含了已观察到的特征向量和对于所有arms的hidden payoffs。我们也可以访问关于日志事件的大序列,它从logging policy的交互产生。每个这样的事件包含了:context vectors:\(x_1, \cdots, x_K\)、一个被选中的arm a、以及产生的observed payoff \(r_a\)。关键的,只有payoff \(r_a\)被随机均匀选中的单个arm a所观察到。出于简洁性,我们将日志事件序列看成是一个无限长的流;然而,我们也在实际有限数目的事件(评估方法所需)上给出了显式的边界。
我们的目标是:使用该数据来评估一个bandit算法\(\pi\)。正式的,\(\pi\)是一个mapping(可能随机化)来在时间t上基于历史行为\(h_{t-1}\)和t-1个之前的事件,结合上当前的context vectors \(x_{t1}, \cdots, x_{tK}\)来选择arm \(a_t\)。

算法3
我们提出的policy评估器如算法3所示。该方法会将输入一个policy \(\pi\)以及一个基于该评估之上的关于“good”事件(event)T的期望值。我们接着沿着日志事件的流(stream)一个接一个地前行。给定当前历史\(h_{t-1}\),有:
- 如果policy \(\pi\)选择了与logging policy所选arm的相同的arm a,那么:event仍被添加到历史中,total payoff \(R_t\)会被更新。
- 如果policy \(\pi\)选择了与logging policy所选arm所不同的arm,那么:event会被完全忽略,该算法会处理下一event,在该state上无需任何变化。
注意,由于logging policy会随机均匀地选择每个arm,被该算法所维持(retain)的每个event会具有1/K的概率,相互独立。这意味着这些events仍保留与被D选中的相同的分布。作为结果,我们可以证明两种方式是相等价的:第一种采用来自D的T个真实events对policy进行评估,第二种会在日志事件流上使用policy evaluator进行评估。
定理1: 对于contexts的所有分布D、所有policies \(\pi\)、所有T、以及所有事件序列\(h_T\),有:
\[\underset{policy\_evalutar(\pi,S)}{Pr} (h_T) = Pr_{\pi, D} (h_T)\]其中S是从一个均匀随机的logging policy和D中i.i.d.的方式抽取出的一个事件流。另外,从流中获得的事件的期望数目(会收集到一个长度为T的历史\(h_t\))是KT。
该定理说明,每一个在真实世界中的历史\(h_T\)与在policy evaluator中具有相同的概率(比如:返回由算法3的平均payoff \(R_T / T\)),即:算法\(\pi\)的值无偏估计。另外,该定理表明:KT个日志事件对于维持一个size=T的抽样来说是必需的。
证明:该证明通过引入\(t=1, \cdots, T\),以一个t=0时在所有评估方法下概率为1的空历史作为base case开始。在归纳法下,假设我们对于所有t-1:
\[\underset{policy\_evaluator(\pi,S)}{Pr} (h_{t-1}) = Pr_{\pi,D}(h_{t-1})\]并希望证明对于任意历史\(h_t\)都有相同的声明。由于该数据是i.i.d.的,任何在policy中的随机化(randomization)与世界中的随机化相互独立,我们只需要证明在基于历史\(h_{t-1}\)条件,在第t个事件(event)上的分布与每个过程(process)相同。换句话说,我们必须展示:
\[\underset{Policy\_evaluator(\pi,S)}{Pr} ((x_{t,1}, \cdots, x_{t,K}, a, r_{t,a}) | h_{t-1}) = Pr_D(x_{t,1}, \cdots, x_{t,K}, r_{t,a}) Pr_{\pi(h_{t-1})} (a | x_{t,1}, \cdots, x_{t,K})\]由于该arm a在logging policy中被随机均匀选中,对于任意policy、任意history、任意features、以及任意arm,policy evaluator退出内循环的概率是相同的, 这意味着对于最近的event,它的概率为\(Pr_D(x_{t,1}, \cdots, x_{t,K}, r_{t,a})\)。相似的,由于该policy \(\pi\)在arms上的分布与基于history \(h_{t-1}\)和features \((x_{t,1}, \cdots, x_{t,K})\)的条件是相互独立的,arm a的概率就是\(Pr_{\pi(h_{t-1}} (a \mid x_{t,1}, \cdots, x_{t,K})\)。
最后,由于来自该stream的每个event仍会保持概率1/K,需要保持T个event的期望数值是KT。
5.实验
在本节中,我们在一个真实应用中使用第4节中的offline评估法来验证提出的LinUCB的能力(capacity)。我们在Yahoo! Today模块上开始该问题setting的介绍,接着描述在实验中所使用的user/item属性。最终,我们定义了performance metrics,并上报了与一些标准(contextual)bandit算法的实验比较结果。
5.1 Yahoo! Today模块
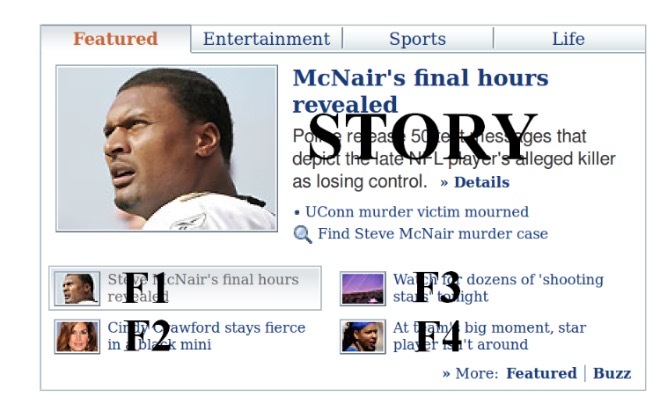
图1
Today模块是在Yahoo! Front Page(流量最大)的最显著位置的panel,详见图1. 在Today Module上缺省的”Featured” tab会对高质量文章(主要新闻)的1/4进行高亮(highlight), 而4篇文章通过一个小时级别更新的由人工编辑的文章池中进行选择。如图1所示,在底部存在4篇文章,索引为F1-F4. 每篇文章由一张小图和一个标题进行表示。其中之一会在story位置进行着重展示,它由一个大图、一个标题、一个简介、以及相关链接进行着重(featured)。缺省的,在F1的文章会在story位置强调。一个用户可以点击在story位置上的highlightd文章,如果她对文章感兴趣会读取更多的详情。event被看成是一次story click。为了吸引访问者的注意力,我们想根据个人的兴趣对提供的文章进行排序,对于每个visitor在story位置上highlight最有吸引力的文章。
5.2 实验设置
这部分会详细描述实验设置,包括:数据收集,特征构建,效果评估,算法比较。
5.2.1 数据收集
我们收集了在2009年五朋的一个随机bucket上的events。在该bucket上的用户会被随机选中,每个visiting view都有一定的概率。在该bucket中,文章会从池子中随机被选中来服务给用户。为了避免在footer位置处的曝光偏差(exposure bias),我们只关注在story位置处的F1文章的用户交互。每个用户交互event包含了三个部分:
- (i) 提供给用户随机选中的文章
- (ii) user/article信息
- (iii) 在story位置处用户是否对该文章有点击
第4部分展示了这些随机events可以被用于依赖估计一个bandit算法的期望payoff。
在5月1号的随机bucket中有4700W的events。我们使用该天的events(称为:tuning data)来进行模型验以决定最优的参数来对比每个bandit算法。接着,我们使用调过的参数在一周的event-set(称为:evaluation data,从5月03-09号)上运行这些算法,它包含了3600w的events。
5.2.2 特征构建
我们现在描述user/article的特征构建。对于disjoint和hybrid模型分别有两个集合的特征,用于测试在第3节中LinUCB的两种形式,以验证我们的猜想:hybrid模型可以提升学习速率。
我们从原始user features开始,它们通过“support”被选中。一个feature的support指的是,用户具有该feature的比例。为了减少数据中的噪声,我们只选取了具有较高值support的features。特别的,当它的support至少为0.1时,我们才使用该feature。接着,每个user最初通过一个在1000个类别型特征(categorical components)上的原始特征向量(raw feature vector)进行表示,包含了:
- (i) 人口属性信息(demographic information):性别(2个分类)、年龄(离散化成10个分段)
- (ii)地理特征(geographic features):包含世界范围和美国的大约200个大都市;
- (iii)行为类别(behavioral categories):大约1000个二分类别(binary categories),它们总结了用户在Yahoo!内的消费历史。
除了这些特征之外,不会使用其它信息来标识一个用户。
相似的,每篇文章通过一个原始的feature vector进行表示,它以相同的方式构建了100个类别型特征。这些特征包括:
- (i) URL类别:数十个分类,从文章资源的URL中推断得到
- (ii) editor类别:数十个主题,由人工编辑打标签总结得到
我们使用一个之前的过程[12]来将类别型user/article特征编码成二分类向量(binary vectors),接着将每个feature vector归一化成单位长度(unit length)。我们也会使用一个值为1的常数特征来增加每个feature vector。现在,每个article和user都可以分别表示成一个关于83个条目和1193个条目的特征向量。
为了进一步减小维度,以及捕获在这些原始特征中的非线性关系,我们会基于在2008年九月收集的随机曝光数据来执行关联分布。根据之前的降维方法[13],我们将用户特征投影到文章类目上,接着使用相似偏好将用户聚类成分组(groups)。更特别的:
- 我们首先通过原始的user/article features,来使用LR来拟合一个关于点击率(click probability)的bilinear model,以便\(\phi_u^T W \phi_a\)来近似用户u点击文章a的概率,其中\(\phi_u\)和\(\phi_a\)是相应的feature vectors,W是由LR最优化得到的权重矩阵。
- 通过计算\(\psi_u = \phi_u^T W\),原始的user features接着被投影到一个induced space上。这里,用于user u,在\(\psi_u\)的第i个元素可以被解释成:用户喜欢文章的第i个类别的度(degree)。在induced的\(\psi_u\) space中使用K-means算法将用户聚类成5个clusters。
- 最终的user feature是一个6向量(six-vector):5个条目对应于在这5个clusters中的成员(使用一个Gaussian kernel计算,接着归一化以便他们总和一致),第6个是一个常数特征1.
在实验t中,每篇文章a具有一个独立的6维特征\(x_{t,a}\)(包含一个常数特征1)。与一个user feature的外积(outer product)给出了6x6=36个特征,表示为\(z_{t,a} \in R^{36}\),对应于等式(6)的共享特征,这样\((z_{t,a}, x_{t,a})\)可以被用于在hybrid线性模型中。注意,特征\(z_{t,a}\)包含了user-article交互信息,而\(x_{t,a}\)只包含了用户信息。
这里,我们故意使用5个用户/文章分组(users group),在分段分析中具有代表性[13]。使用一个相对小的feature space的另一个原因是,在在线服务中,存储和检索大量user/article信息在实际上代价高。
5.3 算法比较
我们的实验中评估的算法有三组:
I.不使用特征的算法
这对应于context-free K-armed bandit算法,它们会忽略所有contexts(例如:user/article信息)
- random: random policy总是会以等概率的方式从池子中选中候选文章之一。该算法无需参数,不会一直学习
- ε-greedy:在第2.2节所述,它会估计每篇文章的CTR;接着,它会选择具有概率e的一篇随机文章,接着选择具有概率1-e的最高CTR估计的文章。该policy只有一个参数e。
- ucb: 如2.2节所述,policy会估计每篇文章的CTR,也会估计它的置信区间,总是会选择具有最高UCB的文章。特别的,根据UCB1[7],我们会通过\(c_{t,a} = \frac{a}{\sqrt{n_{t,a}}}\)来计算一篇文章a的置信区间,其中\(n_{t,a}\)是在实验t之前a被选中的次数,\(\alpha>0\)是一个参数
- omniscient(无所不知的): 这样的一个policy会从后见之明(from hindsight)达到最好的经验型的context-free CTR。它首先会从日志事件(logged events)中计算每篇文章的经验CTR,当使用相同的logged events评估时,接着总是选择具有最高经验CTR的文章。该算法无需参数,不需要学习。
II.热启动(warm start)算法
个性化服务的一种中间步骤。它的思想是,在文章的整个流量上的context-free CTR提供一种offline估计的特定用户的调整。该offset会为新内容对CTR估计的实始化,也称为:“warm start”。我们在2008九月的随机流量数据上,使用特征\(z_{t,a}\)重新训练了bilinear LR模型。选择原则接着变成context-free CTR估计与一个user-specific CTR adujstment的bilinear项的和。在训练中,CTR估计使用context-free ε-greedy,其中e=1.
- ε-greedy(warm):
- ucb(warm):
III.在线学习user-specific CTR的算法