关于itemcf的topk问题,我们看下较老的一篇paper《Evaluation of Item-Based Top-N Recommendation Algorithms》中提到的:
3
在本paper中,我们研究了一种item-based topN推荐算法,它使用item-to-item相似度来计算items间的关系。在模型构建期间,对于每个item j,它具有k个计算好的最相似的items:\(\lbrace j_1,j_2,...,j_k \rbrace\),它们对应的相似度分值为:\(\lbrace s_{j_1}, s_{j_2}, ..., s_{j_k} \rbrace\)。接着,对于已经购买了商品集合U(购物篮:basket)的每个客户,可以使用上述信息来计算top-N items进行推荐。首先,我们通过对每个item \(j \in U\)上对应的k个最相似items的联集(union),并移除已在U中存在的items,来标识候选推荐items集合C。接着,对于每个item \(c \in C\),我们会计算它与集合U的相似度,来作为在所有item \(j \in U\)和c之间相似度的求和,使用只有j的k个最相似items。最终,在C中的items根据各自相似度以降序排序,选择前N个items作为top-N的推荐集合。
3.1 相似度选择
- cosine-based
- Conditional Probality-based
3.2 相似度归一化
第3节中,给定一个items集合(basket) U,通过以下的item-based top-N推荐算法决定着要推荐的items:通过计算不在U中的每个item和U中所有items间的相似度,并选择N个最相似的items作为推荐集合。集合U和一个item \(v \notin U\)间的相似度,通过在每个item \(u \in U\)和v间添加相似度来决定(如果v不在u的k个最相似items中)
该方法的一个潜在缺点是,在每个item u和它的k个最相似items间的原始相似度(raw similarity)可能相当不同。也就是说,item的邻近点具有不同的密度。购买了那些不常购的items来说这是特别正确的,由于一个,这对于其它不常购买的items间存在一定适度的重合,可以产生相当高的相似度值。结果是,这些items在top-N items的选择时可以发挥相当强的影响力,有时会导致产生差的推荐。出于该原因,需要通过别的方法来替代3.1节描述的那些真实相似度,对于每个item u,我们首先会归一化相似度以便它们合计为1(add-up to one)。如第4节的实验所示,这通常会在top-N的推荐质量上产生明显提升。
4.实验
4.3 相似度归一化的效果
我们的第一个实验被设计成用来评估3.2节中相似度归一化的效果。图1展示了。由4种不同的item-based推荐算法的accuracy对比。其中两者使用cosine做为相似度函数,另两者使用条件概率(conditional probability)。每个算法对间的不同之处是,一个不会归一化相似度(被标记为“Cos-Sraw”和”CProb-Sraw”),另一个会进行归一化(被标记为”Cos-Snorm”和”CProb-Snorm”)。对于所有这4种算法,矩阵的行都会进行归一化,以便它们具有一致的长度,k(模型中最近邻items的数目)设置为10, “CProb-Sraw”和”CProb-Snorm”的\(\alpha\)设置为0.5.
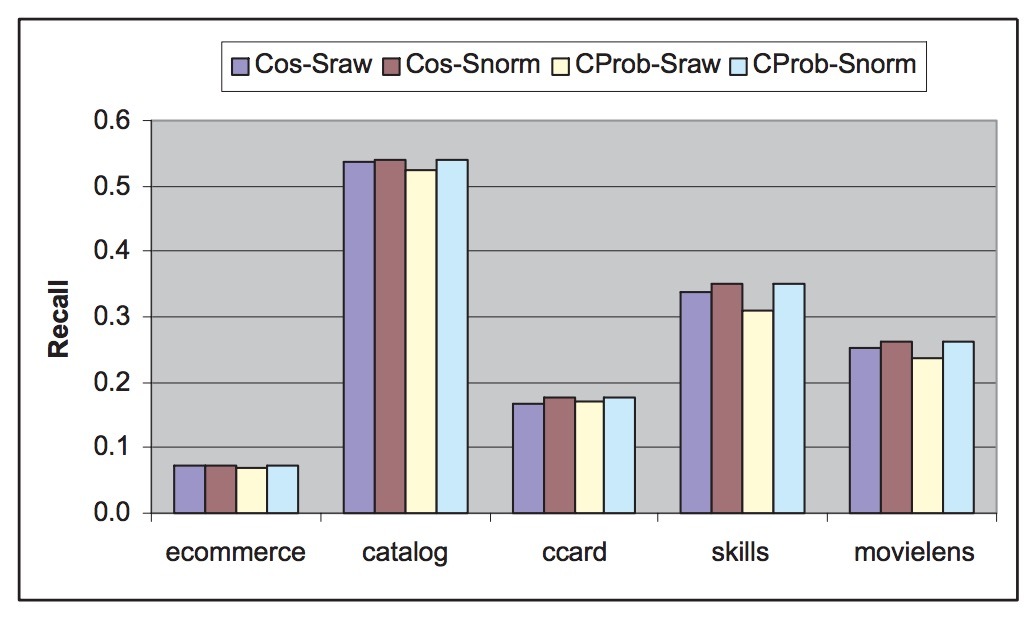
图1: 相似度归一化在推荐质量上的效果
如图1所示,我们可以看到,使用相似度归一化的算法可以达到更高的推荐accuracies,对比起其它不使用的。实际的提升与数据库和算法有关。总之,基于条件概率的scheme相对提升要比cosine-based scheme要高。cosine-based scheme的效果提升有0%~ 6.5%,平均提升有3.1%,conditional probability-based scheme的提升会有3%-12%,平均提升7%。由于这个优点,在实验的其它地方总会使用相似度归一化。