我们来看下intel提出的《Parallelizing Word2Vec in Multi-Core and Many-Core Architectures》。
介绍
word2vec是用于抽取词的低维向量表示的常用算法。包含Mikolov原版在内的state-of-art算法,都已经为多核CPU架构提供了并行化实现,但都基于使用”Hogwild” updates的vector-vector操作,它是内存使用密集型的(memory-bandwidth intensive),并且不能有效使用计算资源。在本paper中,我们提出了“HogBatch”,通过使用minibatching和negative sample sharing来改善在该算法中多种数据结构的复用,从而允许我们使用矩阵乘法操作来表示该问题。我们也探索了不同的技术来将word2vec在同一计算集群上的跨节点分布式计算,并演示了扩展至32个节点上很强的可扩展性。这种新算法特别适合于现代双核/多核架构,特别是intel最新的Knights Landing处理器,并允许我们以接近线性的方式跨多核和多节点扩展计算,并可以达到每秒处理数百万个词,这是目前已知的最快的word2vec实现。
1.从Hogwild到HogBatch
我们提到[5,6]有对word2vec和它的最优化问题的一个介绍。原始的Mikolov的word2vec实现使用Hogwild来并行化SGD。Hogwild是一个并行SGD算法,它会忽略在不同线程上模型更新间的冲突,并允许即使在发生冲突时也能更新处理。使用Hogwild SGD的word2vec的伪代码如图1所示。算法会采用一个矩阵\(M_{in}^{V \times D}\),它包含了每个输入词的词表示;以及一个矩阵\(M_{out}^{V \times D}\),它包含了每个输出词的词表示。每个词被表示为一个D维浮点数组,对应于两个矩阵的某一行。这些矩阵会在训练期间被更新。在图1中,我们选取一个目标词,以及围绕该目标词的N个输入上下文词组成的集合来做示例描述。该算法会在第2-3行上迭代N个输入词。在第6行的循环中,我们选取正样本(第8行的target word),以及一个随机负样本(第10行)。第13-15行为对应选中的输入词和正/负样本计算目标函数的梯度。第17-20行会对\(M_{out}[正/负样本]\)和\(M_{in}[输入上下文]\)中的条目进行更新。伪代码只展示了单个线程;在Hogwild中,第2行的loop会进行线程并行化,在代码中无需任何额外的修改。

算法1
算法1会读取和更新对应于在第6行loop中每轮迭代上的input context和pos/neg words的矩阵M的条目(entries)。这意味着,在连续的迭代间存在一个潜在依赖——他们会发生碰到相同的词表示,从前一轮迭代到该轮迭代完成时,每轮迭代必须潜在等待更新。Hogwild会忽略这样的依赖,并忽略冲突以继续更新。理论上,对比起顺序运行,这会让算法的收敛率下降。然而,对于跨多线程更新不可能会是相同的词的这种情况,Hogwild方法已经得到验证能运行良好;对于大词汇表size,冲突相对较少发生,收敛通常不受影响。
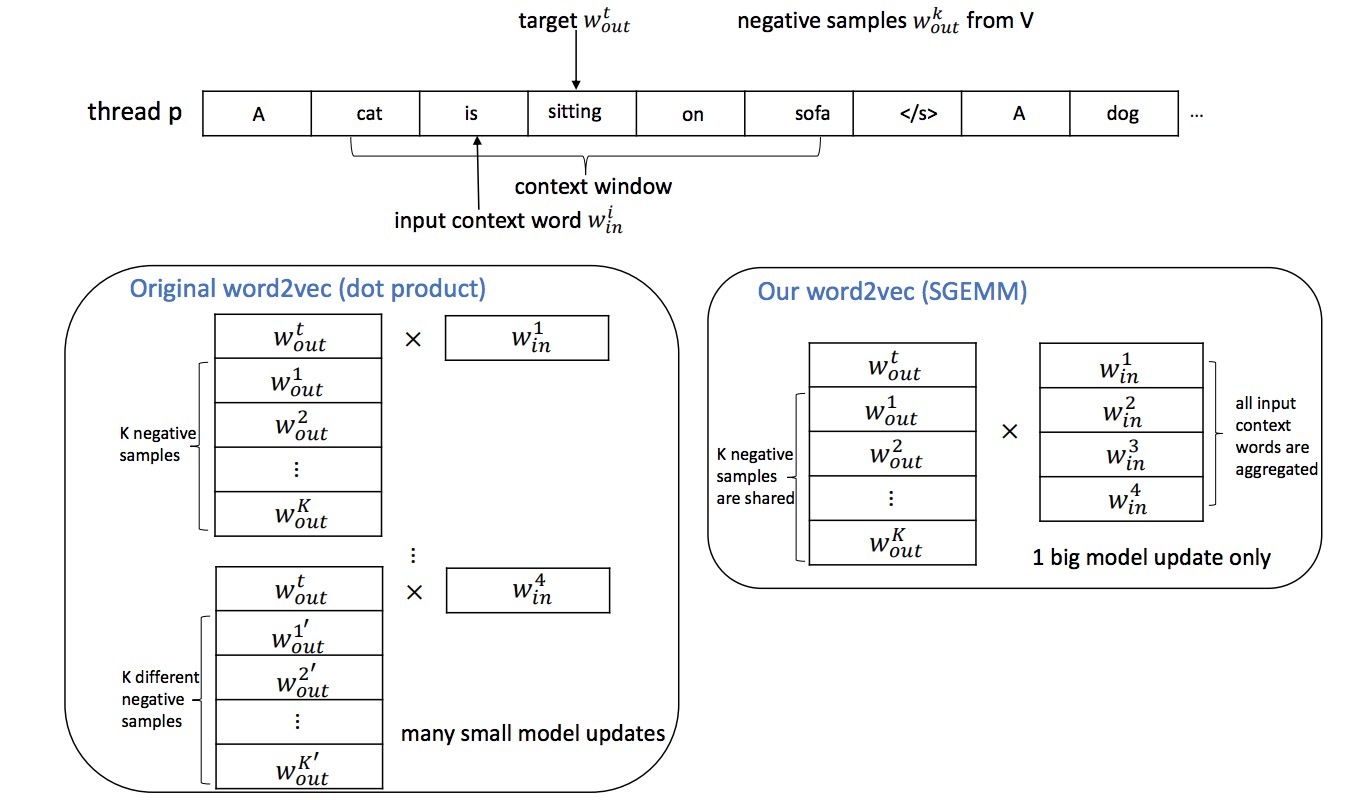
图1: 原始word2vec(左)和我们的实现(右)的并行化schemes
1.1 共享内存并行:HogBatch
然而,原始的word2vec算法主要有两个缺点,极大影响运行时长(runtimes)。第一个是,由于多个线程可以更新相同缓存行(cache line): 它包含了一个特定的模型条目(model entry),这可能在跨多核时会有极大的cache lines冲突。这会导致较高的访问延时和在扩展性上极大的下降。第2个也是更重要的,模型中的大部分位置的更新在Hogwild算法中没有被利用。例如,我们可以很容易看到,对于多个输入词的更新,在模型中会使用相同目标词\(W_out^t\)。通过一次只进行单个更新,该位置信息会丢失,该算法会执行一系列level-1 BLAS操作[1]的点乘(dot-products),它受内存量(memory-bandwidth)限制。下面我们会展示,将这些操作batch成一个level-3 BLAS调用[1],可以有效地利用计算能力和现代多核架构的指令集。
我们以2-steps的形式利用位置(locality)信息。受图1的启发,该图左侧展示了原始word2vec的并行化scheme。注意,我们通过给定输入词\(w_{in}^i\)、以及目标词\(w_{out}^t\)、同时还有K个负样本\(\lbrace w_{out}^1, ..., w_{out}^K\rbrace\)来计算词向量。我们不再一次只计算一个更新,而是将这些点乘batch成一个矩阵向量乘法,一个level-2的BLAS操作[1],如图1左侧所示。然而,这不会带来巨大的性能提升。确实,共享输入词向量最可能来自于cache。为了将该操作转化成一个level-3 BLAS操作,我们也需要将(input context words)进行batch。这样做是有意义的(non-trivial),因为在原始word2vec实现中每个input word的负样本可能是不同的。我们因此提出“负样本共享(negative sample sharing)”作为策略,其中,我们跨一个关于input words的较小batch进行共享负样本。这样做允许我们将原始的基于乘法的点乘转换成一个matrix-matrix乘法调用(GEMM),如图1的右侧所示。在GEMM的终点,关于所有输入词、目标/样本词的所有词向量的模型更新,必须被写回。执行matrix-matrix乘法(GEMM)而非点乘,可以利用现代架构的所有计算资源,包含向量单元(vector units)和指令集(instruction set)特性,比如:在Intel AVX2指令集上的multiply-add指令。它允许我们极大地利用优化版的线性代数库。
对于跨GEMM调用的多线程,我们可以遵循”Hogwild”-style哲学——每个线程会执行它们在各自线程上独立的GEMM调用,我们允许线程间潜在的冲突——当在GEMM操作结速更新模型时。我们因此将该新的并行scheme命名为“HogBatch”。
其中,原始的word2vec会在每次点乘后执行模型更新(model updates),我们的HogBatch schema则会在执行模型更新前在单个GEMM调用中做多个点乘运算。需要重点关注的是,位置优化(locality optimization)是次要的,但很有用——我们可以降低模型的更新次数。这是因为GEMM操作会对在输出矩阵的单个条目上的更新做一个reduction(在registers/local cache级别);而在原始的word2vec sche中,这样对于相同条目的更新(例如,相同的输入词表示)会在不同时期发生,会有潜在的冲突发生。在第2节中,我们可以看到相应的结果,它展示了HogBatch比原始word2vec有一个更好的扩展。
1.2 分布式内存并行化
为了扩展word2vec,我们也探索了不同的技术来在同一计算集群的不同节点上将计算分布式化。必要的,我们为分布式计算采用数据并行化。由于篇幅受限,这里跳过细节,可以在完整paper中看到。
2.实验
我们比较了三种不同word2vec实现的性能:
- 1) 原始google word2vec实现:它基于在共享内存系统上的Hogwild SGD https://code.google.com/archive/p/word2vec
- 2) BIDMach:它在Nvidia GPU上word2vec的已经最佳性能实现 https://github.com/BIDData/BIDMach
- 3) 我们的基于Intel架构的实现:包括:1.36-core Intel Xeon E5-2697 v4 Broadwell(BDW) CPUS 2.最新的Intel Xeon Phi 68-core Knights Landing(KNL)处理器。
我们在10亿词的bechmark[3]上训练,使用与BIDMatch相同的参数设置(dim=300, negative samples=5, window=5, sample=1e-4, vocab size=111,5011词)。我们在标准的词相似度bechmark WS-353[4]以及google word analogy benchmark[5]上评估了模型的accuracy。所有的实现都能达到相同的accuracy,由于篇幅限制,我们只展示了在吞吐量上的性能,测试单位:百万words/sec。更多实验细节可以完整paper上介绍。我们的实现:https://github.com/IntelLabs/pWord2Vec
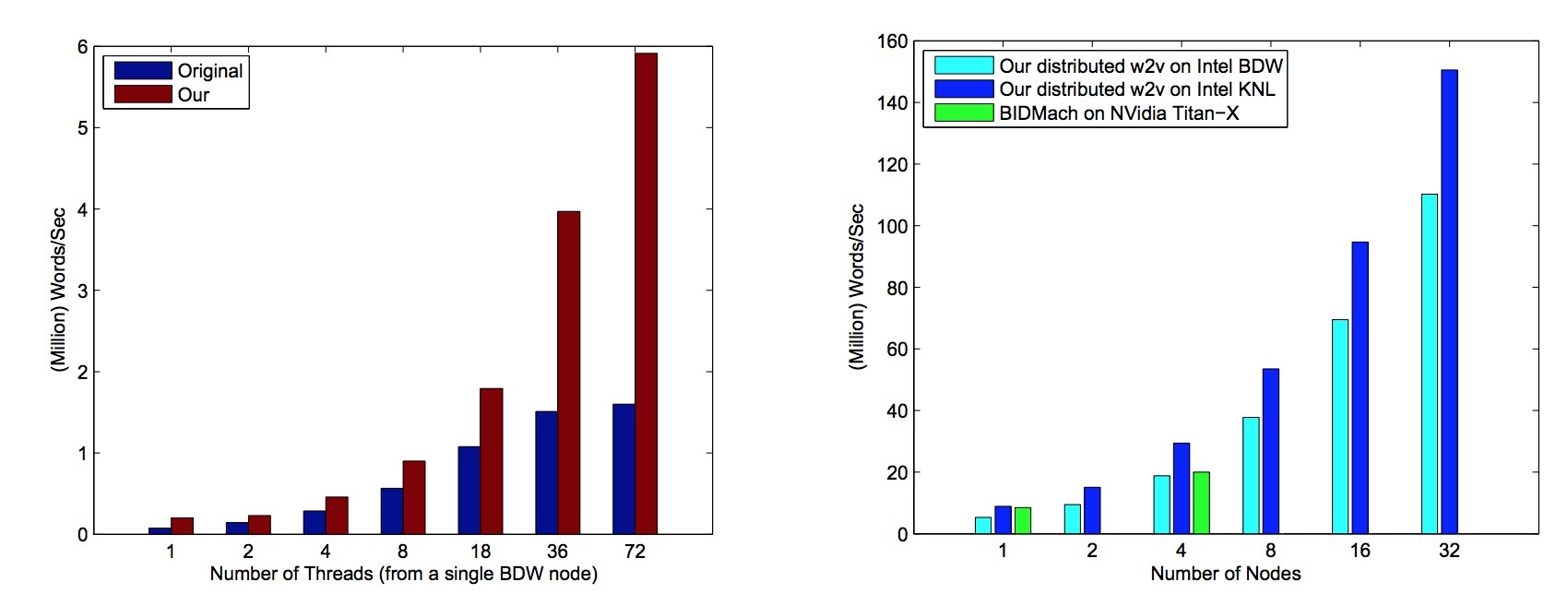
图2:(a)原始word2vec和我们实现在一个Intel Broadwell CPU的所有线程上的可扩展性对比 (b) 在多台Intel Broadwell和Knights Landing节点上,我们的分布式word2vec;与BIDMach在N=1, 4个Nvidia Titan-X节点上的对比
图2展示了我们的算法与原始word2vec,在intel BDW和KNL处理器上跨多核扩展的吞吐量,单位:百万 words/sec。当扩展到多线程时(图2a),我们的算法达到接近线性加速,直到36个线程。作为对比,原始word2vec只能线性扩展到8个线程,接下去会慢很多。结果就是,原始word2vec接近1600w words/sec,而我们的实现接近5800w words/sec,这是原始word2vec的3.6X倍加速。更优的性能可以加强我们最优化的效果,有效利用多核计算资源,降低不必要的线程间通讯。当在多节点上扩展时(图2b),我们的分布式word2vec可以线性扩展到16个BDW节点或者8个KNL节点,并且能维持和原始word2vec相同的accuracy。随着节点数的增加,为了维持一个相当的accuracy,我们需要增加模型的同步频率(synchronization frequency)来消除收敛率的损失。然而,这会在扩展性上造成损失,并在32 BDW节点或16 KNL节点上导致一个次线性扩展(sub-linear scaling)。忽略这一点,我们的分布式word2vec可以达到1亿 words/sec的吞吐,只有1% accuracy的损失。据我所已,这是目前在该benchmark上最佳的性能。最终,表1总结了在不同架构上state-of-art实现的最佳表现。
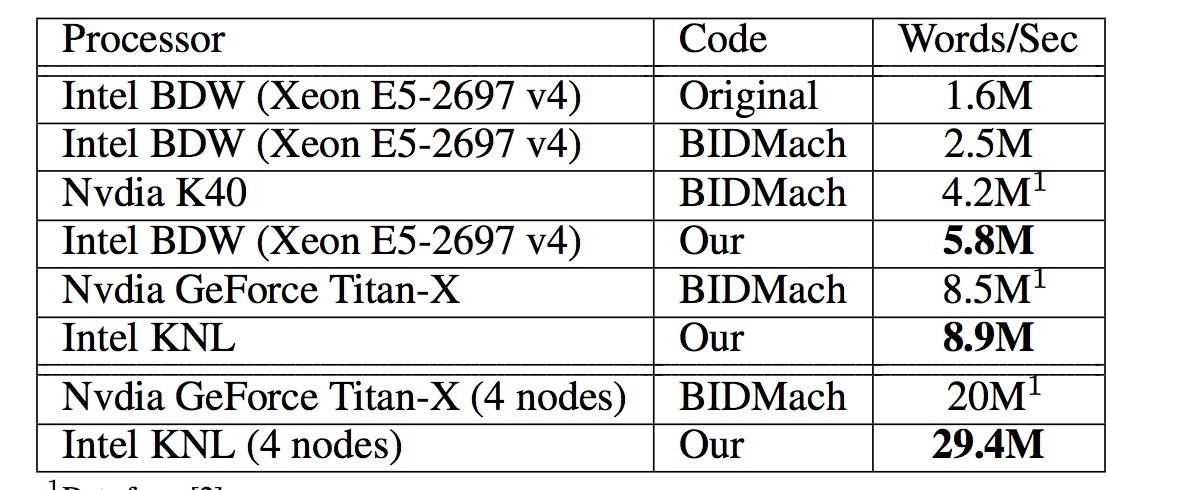
表1 在不同架构上state-of-art实现的性能对比
3.结论
我们提出了一个高性能的word2vec算法”HogBatch”,它基于共享内存和分布式内存系统。该算法特别适合现代多核架构,尤其是Intel的KNL,在它之上我们发现了目前已知的最佳性能。我们的实现是公开并且通用的。
参考
- 0.