
#GloVe: Global Vectors for Word Representation
介绍
GloVe是一个非监督学习算法,用来获取词向量表示. 它会对语料进行词与词的共现统计聚类,生成一个词向量空间的线性子结构。
1.准备
- 下载代码
- 解压
- 编译
- ./demo.sh
- 查看下readme.
2.语料
3.核心
1.最近邻
两个词向量的欧氏距离(或cosine相似度),可以有效计算相应词汇的语义相似度。有时候,按照语义得到的最近邻相当少,但是在人们的词汇表中,这种相关的词语却是存在的。比如,下面有一些和青蛙(frog)相近的词:
- 0.frog
- 1.frogs
- 2.toad
- 3.litoria
- 4.leptodactylidae
- 5.rana
- 6.lizard
- 7.eleutherodactylus




2.线性结构
用于计算最近邻的语义相似性,产生了另一个标量,来衡量两词间的相关性。这种简化还有点问题,因为两个结定词经常展示出更难理解的关系,它们可以由一个数字来表示。例如,’man’可以被认为是与’woman’相关,因为这两个词都用来描述人类;另外,两个词可以被认为是反义词。
为了以定量的方式来捕获差异来区分’man’和’woman’,模型需要关联更多的词对。一种简单通用的方法是,glove必须,与两个词向量间不同的向量。glove的设计目的是,这种向量差异尽可能通过两个词的并列位置指定的意义来捕获。
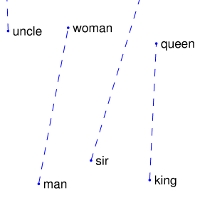
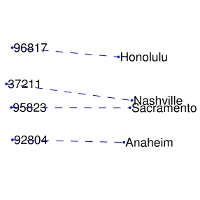
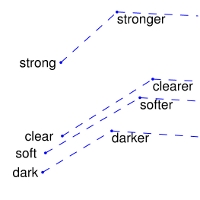
‘man’和’woman’间区分的相关概念,有:性别(sex or gender),还有可能是近义词对:比如:’king’和’queen’,或者’brother’和’sister’。为了从数学上很明显地对:man-wowan,king-queen,brother-sister的向量进行区别,这种合适的以及其它感兴趣的模式可以通过上述可视化的集合进行观察。

3.训练
GloVe模型,会训练全局的词与词的共现矩阵中的非零实体。该矩阵展示了在一个给定语料中词共现的频度。对该矩阵进行操作,需要一个pass通过整个语料来收集统计数据。对于大语料,该pass的计算很耗时,但这是一个一次性的up-front开销。子序列的训练迭代更快,因为大量非零矩阵实体的数据通常比语料中的总词汇数更小。
4.模型展望
GloVe 是一个log-bilinear模型,它使用了一个权生化的least-square对象。该模型的主要目标是,观察词与词的共现率,来衡量对应的含义。例如,目标词’ice’和’steam’和其它词的一个共现率,这里有一个6亿词汇的语料的实际示例:
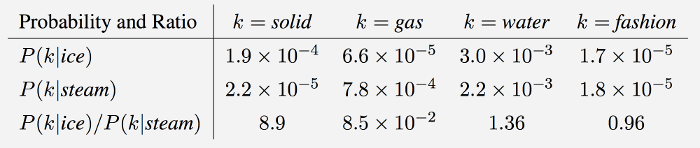
如上所示,’ice’与’solid’的共现率比与’gas’的更高,而’steam’与’gas’的共现率比’solid’的更高。这几个词之间的共现,都有共有的属性词:水。而非相关的词汇:fashion。两概率的比率,区分度不明显的词汇有:water和fashion,大值(比1大)的可以指定给’ice’更相关些,而小值(小于1)则赋给与steam更相关一些。这种方式的比率可以结合热力学上的概念进行理解。
GloVe的训练目的是,为了学习词相量,以及两者之间的点积等于两词共现的log对数。实际上,该比率的log与两者的log差相等,因而,共现率之比(log)与词向量空间的差异相关联。因为,该比率可以通过一些特定形式进行编码。因而,生成的词向量可以在一些词分析任务上很好地运行,比如:word2vec工具包。
可视化
GloVe生成的词向量,可以用一个标记化频谱结构进行:

水平带标识了该模型的乘法交互,而相应的加法交互则通过点积来完成。另外,对于某些个别维度来说,有少量地方是交差的。
水平带随机词频增加变得更加明显。确实,它们跟着词频有明显地长范转变化趋势,另外它们不可能存在一个词义上的起点。该特征并非是glove独有的--事实上,任何模型的词向量都试图在回避这个问题。
垂直带,比如:230k-233k的那个,可以归因于相关词的密度(数目)有一个相近的频度。