hinton在《Dynamic Routing Between Capsules》中提出了“dynamic routing”的概念。我们来看下这篇paper:
abstract
一个capsule是一组neurons,它的activity vector表示了一个特定类型的实体(entity)(比如:一个object或一个object part)的实例参数()。我们使用activity vector的长度(length)来表示实体存在的概率,使用它的方向(orientation)表示实体参数。在一个层级上的Active capsules通过转移矩阵为高级capsules的实例参数做出预测。当多个预测达到一致时,一个更高级别的capsule会变成active态。我们会展示:当训练完后,多层capsule系统会在MNIST上达到state-of-art的效果,它在识别高度重叠的数字上要比CNN要好。为了达到这样的结果,我们使用了一个迭代式routing-by-agreement机制:一个更低层级的capsule会偏向于将它的output发送到更高层级的capsules上,它的activity vectors会与来自低层级capsule的预测做一个大的点积。
1.介绍
人类视觉会通过使用一个关于注视点(fixation points)的细致判别序列,忽略掉不相关细节,来确保只有一小部分的光学阵列(optic array)在最高分辨率上被处理。内省(Introspection)对于理解以下情况效果很差:关于某个场景的知识有多少是来自该注视点序列,以及我们从单个fixation能得到多少知识。但在本paper中,我们将假设,比起单个已被识别的目标和它的属性,单个fixation会带给我们更多。我们假设,我们的multi-layer可视化系统会在每个fixation上创建一个类parse tree结构,我们会忽略:这些单个fixation parse trees是如何协调的。
parse trees通常会通过动态内存分配即时构建。然而,根据【hinton 2000】,我们假设:对于单个fixation,一个parse tree可以从一个确定的multi-layer神经网络(比如: 雕塑从一块岩石中中雕刻出)中雕刻出。每个layer将被划分成许多被称为“capsules”的neurons小分组,在parse tree中每个node会对应一个active capsule。通过使用一个迭代路由过程(iterative routing process),每个active capsule会选择在layer中的一个capsule,作为它在树中的父节点(parent)。对于一个可视化系统中越高层级,该迭代过程会解决将部件分配到整体(assigning parts to wholes)的问题。
在一个active capsule中的neurons的activities,可以表示出现在该图片中一个特定实体(entity)的多种属性。这些属性可能包含许多不同类型的实例参数,比如:pose(位置、大小、方向),deformation(变型)、velocity(速率)、albedo(反射率)、hue(色彩)、texture(纹理)等。一个非常特别的属性是,在图片中实例化实体(instantiated entity)的存在(existence)。表示存在的一个很明显的方式是,通过使用一个独立的logistic unit,它的输出是该实体存在的概率。在本paper中,我们会探索一个有意思的方法,它会使用实例参数向量的整体长度(overall length)来表示实体的存在,并强制向量的方向(orientation)来表示实体的属性。我们会确保:一个capsule的向量输出(vector output)的长度不能超过1,通过使用一个非线性(non-linearity)函数来确保向量在方向保持不变、在幅值上进行缩放。
事实上,一个capsule的输出就是一个向量,使得它可以使用一个很强大的dynamic routing机制,来确保capsule的输出发送到上层(layer above)的一个合适的父胶囊(parent)上。首先,该output会被路由到所有可能的父胶囊上,但它会通过总和为1的耦合系数进行缩减。对于某个capsule的每个可能的父胶囊,该capsule通过将它的output乘以一个权重矩阵计算得到一个“预测向量(prediction vector)”。如果该预测向量与某一父胶囊的输出具有一个大的点积(scalar product,注:标量积、点积、内积、向量的积 dot product = scalar product),那么这就存在一个自顶向下的反馈(top-down feedback):该feedback会增大与该父胶囊的耦合系数(coupling coefficient),而对于其它父胶囊该系数则会降低。这样就增大了该capsule对该父胶囊的贡献,并进一步增大该capsule的预测向量与父胶囊的输出间的点积。这种类型的”routing-by-agreement”远比原始版本的通过max-pooling实现的routing机制要更有效的多。我们会进一步展示,我们的dynamic routing机制是实现该“解释消除(explaining away)”的一种有效方法,解释消除对于将高度重叠的目标进行分割是必须的。
CNN会使用所学到的特征检测器的平移副本(translated replicas)。这允许他们将在一个图片中某一位置获得的较好权重值(good weight values)的知识平移到另一位置上。这在图片解释中被证明是相当有用的。尽管我们使用vector-output capsules来替换CNNs的scalar-output feature detectors、以及使用routing-by-agreement来替代max-pooling,我们仍希望跨空间的复用学到的知识。为了达到该目标,我们让除了capsules的最后一层之外的所有层都是conv的。有了CNNs,我们可以让更高层级的capsules覆盖该图片的更大区域。不同于max-pooling,我们不会丢掉关于该实体在该区域内的准确位置信息。对于低级别的capsules,位置信息是由active capsule所进行“基于位置的编码(place-coded)”。随着结构的上升,在某个capsule的output vector的实值元素(real-valued components)中,越来越多的位置信息是”rate-coded”。从place-coding到rate-coding的转换,加上更高层capsules可以以更多自由度来表示更复杂实体,表明capsules的维度应随着结构的上升而增加。
2.一个capsule的inputs和outputs向量是如何计算的
有许多可能的方式来实现capsules的通用思想。该paper的目的并不是探索整个实现空间,而是提供一种可以运转良好的简单实现,并且能用上dynamic routing。
我们希望:一个capsule的output vector的长度用来表示:通过该capsule表示的实体在当前输入中出现的概率。因此,我们使用一个非线性的“压扁(squashing)”函数,来确保短向量长度收缩到几乎为0,长向量收缩到长度在1以下。我们将它留给判别式学习,以便充分利用这种非线性。
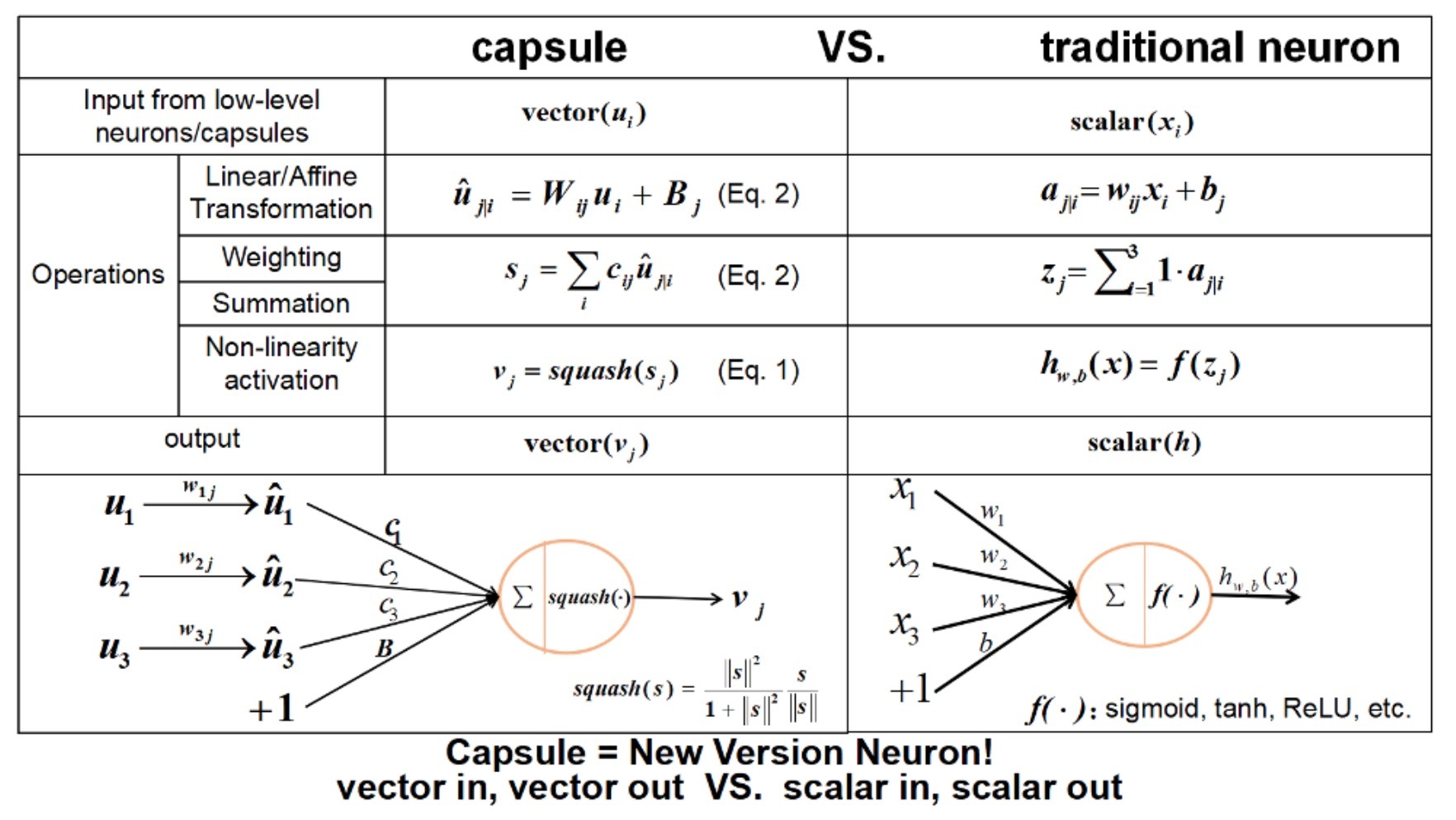
\[v_j = \frac{\| s_j \|^2}{ 1+ \| s_j \|^2} \frac{s_j}{\|s_j\|}\]…(1)
其中:
- \(v_j\)是capsule j的向量输出
- \(s_j\)是它的总输入(total input)
对于除了第一层外的其它层capsules,一个capsule的总输入\(s_j\)是一个在所有“预测向量(prediction vectors)”\(\hat{u}_{j \mid i}\)的加权求和。这些预测向量来自于下层(layer below)的capsules,通过将在下层(layer below)中的一个capsule的输出\(u_i\)乘以一个加权矩阵\(W_{ij}\)得到:
\[s_j = \sum\limits_i c_{ij} \hat{u}_{j \mid i}, \hat{u}_{j|i} = W_{ij} u_i\]…(2)
其中,\(c_{ij}\)是耦和系数,它通过迭代式dynamic routing过程决定。
在capsule i和在上层(layer above)中的所有capsules间的耦和系数,总和为1, 通过一个”routing softmax”来决定,该softmax的intial logits \(b_{ij}\)是关于capsule i与capsule j相耦合的log先验概率。
\[c_{ij} = \frac{exp(b_{ij})}{\sum_k exp(b_{ik})}\]…(3)
该log先验(priors)可以同时与所有其它权重一起通过判别式学习学到。他们取决于两个capsules的位置(location)和类型(type),但不会依赖于当前输入图片。接着通过对每个在上层(layer above)中capsule j的当前输出\(v_j\),以及由capsule i做出的预测\(\hat{u}_{j \mid i}\)的一致性(agreement)进行measure,以对初始化的耦合系数进行迭代式地提升。
该agreement就是简单的点积\(a_{ij}=v_j \cdot \hat{u}_{j \mid i}\)。该agreement就好像被看成是:它是一个log似然,并且在为capsule i连接到更高层级capsules上的所有耦合系数计算新值之前,被添加到initial logit \(b_{ij}\)中。
在conv capsule layers上,每个capsule会将一个关于向量的local grid,并为grid中每个成员、以及对于每种类型的capsule使用不同的转换矩阵,输出到上层(layer above)中每种类型的capsule。

算法1 routing算法
3.数字存在性的margin loss
我们正使用实例向量的长度来表示一个capsule实体存在的概率。我们希望,对于数字类别k,当且仅当该数字出现在该图片上时,顶层(top-level) capsule会具有一个长的实例向量。为了允许多个数字,对于每个数字胶囊(digit capsule)k,我们使用一个独立的margin loss,\(L_k\):
\[L_k = T_k max(0, m^+ - \| v_k \|)^2 + \lambda(1-T_k) max(0, \|v_k \| - m^-)^2\]…(4)
其中:
- \(T_k=1\)表示某个数字分类k出现
- \(m^+=0.9\)和\(m^-=0.1\)
- \(\lambda\)会对于没出现的数字类别会降权(down-weighting) loss,从所有digit capsules的activity vectors的长度进行收缩(shrinking),从而停止初始化学习(initial learning)。 我们使用\(\lambda=0.5\)。
total loss可以简单认为是所有数字胶囊的losses求和。
4.CapsNet架构
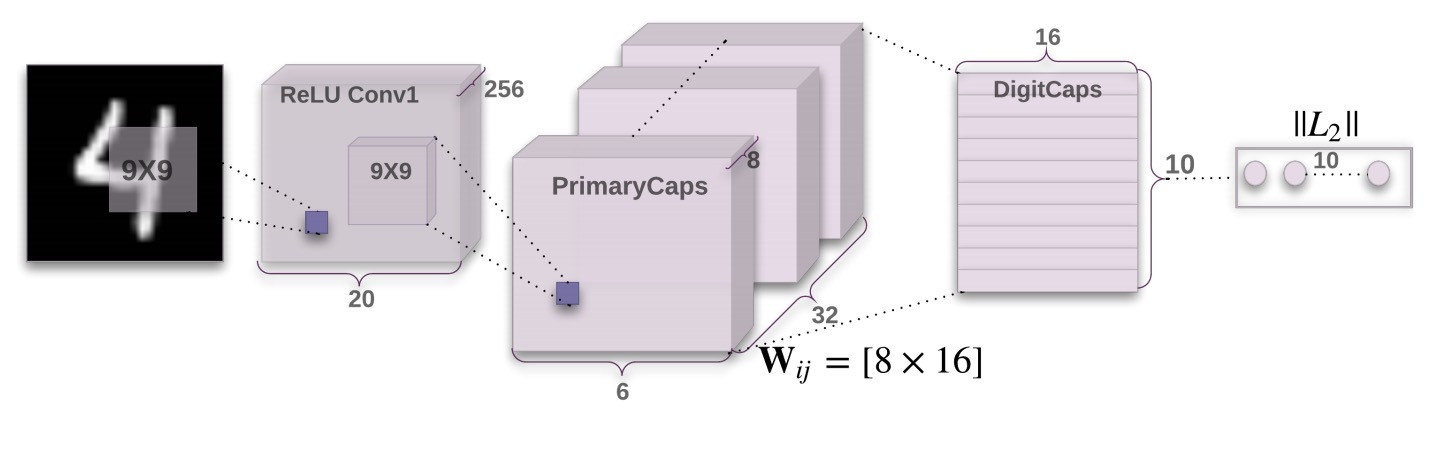
图1 一个具有3 layers的简单CapsNet。该模型会与CNN (Chang 2015)进行比较。在DigitCaps中的每个capsule的activity vector的长度,表示每个数字类别(class)的一个实例的出现,并被用于计算分类loss。\(W_{ij}\)是一个在PrimaryCapsules中每个\(u_i, i \in (1, 32 \times 32 \times 6)\)和\(v_j, j\in (1, 10)\)间的权重矩阵。
一个简单的CapsNet结构如图1所示。该结构是浅层的,只有两个卷积层和一个FC layer。
第一层Conv1
具有256个9x9的conv kernels,它的stride=1, 并使用ReLU activation。该layer会将像素强度转化到局部特征检测器的activities,接着被用于primary capsules的输入。
primary capsules是最低层的多维实体,从一个倒转图的角度看,将primary capsules激活(activating)对应于将渲染过程进行反转(inverting)。比起将实例部件(instantiated parts)组装成熟悉的整体的方式,这是一种非常不同类型的计算,capsules的设计很擅长这种计算。
第二层(PrimaryCapsules)
它是一个convolutional capsule layer,它使用:
- 32 channels的conv 8D capsules(例如:每个primary capsule包含了8个conv units,它具有9x9 kernel以及stride=2)。
- 每个primary capsule的输出会看到所有256 x 81 Conv units,它们的receptive fields与capsule中心位置重叠。
- 在总的PrimaryCapsules中,有\([32 \times 6 \times 6]\)个capsule outputs(每个output是一个8D vector),在\([6 \times 6]\) grid中的每个capsule会相互共享它们的权重。
你可以将PrimaryCapsules看成是Conv layer,其中等式1看成是它的block非线性函数。
最后一层(DigitsCaps)
对于每个digit类具有一个16D的capsule,这些capsules的每一个会接受来自在layer below中的所有capsules的输入。
我们会在两个连续的capsule layers间(比如:PrimaryCapsules和DigitCaps)进行路由(routing),由于Conv1的输出是1维的,在它的空间上没有方向取得一致(agree)。因此,在Conv1和PrimaryCapsules间不会使用routing。所有的routing logits(\(b_{ij}\))被初始化为0。因此,初始化时,一个capsule的output(\(u_i\))会被等概率的(\(c_{ij}\))发送到所有的父胶囊(parent capsules(\(v_0 \cdots v_9\)))上,我们会使用Adam optimizer及tensorflow中的初始参数,包含exponentially decaying learning rate来最小化等式(4)的margin losses的和。
4.1 重构成一个正则方法
我们使用一个额外的reconstruction loss来支持digit capsules将输入数字的实例参数进行编码(encode)。在训练期间,除了正确digit capsule的activity vector外,我们会遮住所有其它digit capsule的vector。接着,我们使用该activity vector来重构输入图片。digit capsule的输出被feed给一个decoder(它由3个FC layer组成,会如图2所示建模像素强度)。我们会对logitsic units的输出和像素强度间的微分平方和做最小化。我们使用乘0.0005将该reconstruction loss缩放,以便它在训练期间不会主导着margin loss。如图3所示,来自CapsNet的16D output的reconstructions是健壮的,它只保留重要细节。
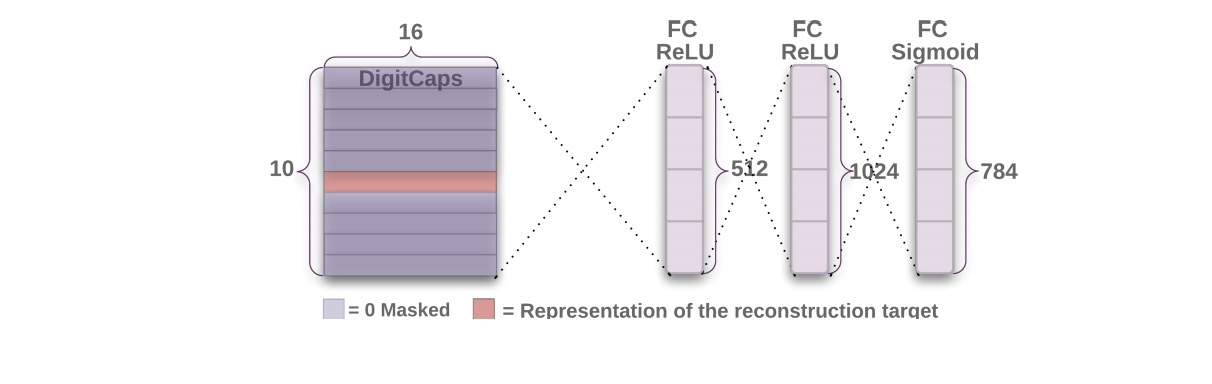
图2 Decoder结构,用于将来自DigitCaps layer的representation重构成一个数字. 图片和Sigmoid layer的output间的欧氏矩离(euclidean distance),在训练期间最小化。在训练期间,我们使用true label来重构target。
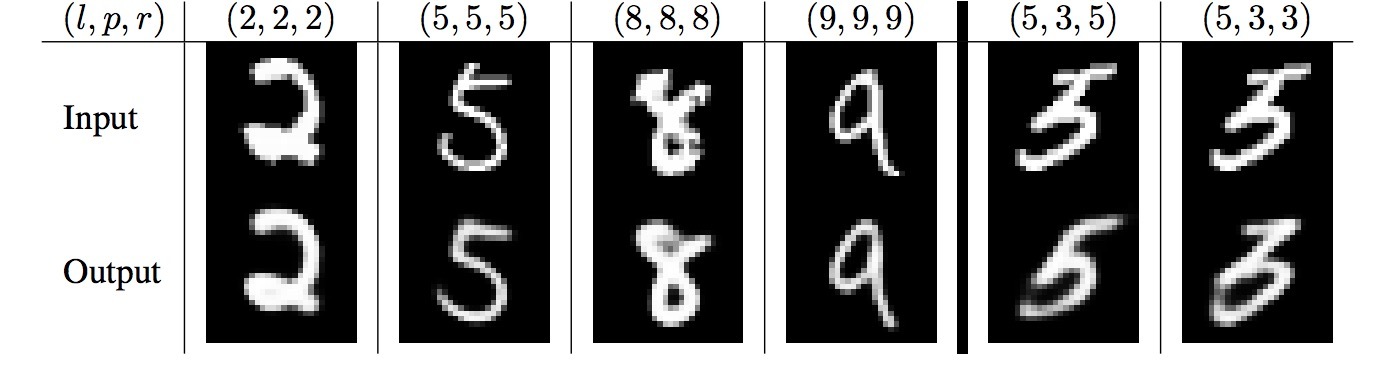
图3 一个使用3个routing迭代的CapsNet的样本MNIST test重构。(l,p,r)表示label,prediction和reconstruction。
5.Capsules on MNIST
我们在28x28 MNIST图片集上(它们会在每个方向上shift两个像素,并使用zero padding)执行训练。没有使用其它的数据扩增/变形(augmentation/deformation)。对于训练集和测试集,dataset分别具有60K和10K的图片。
我们使用单一模型进行测试,没有使用任何模型平均方法(model averaging)。Wan 2013使用ensembling、并将数据进行旋转和缩放进行数据扩充,达到了0.21%的test error。如果不使用这两者,仅能达到0.39%。我们在一个3 layer网络上获得了一个较低的test error (0.25%), 该结果之前只能在更深的网络上才能达到。表1展示了不同CapsNet设置在MNIST上的test error,并展示了routing和reconstruction regularizer的重要性。通过增强在capsule vector中的pose encoding,添加reconstruction regularizer可以增强routing的效果。
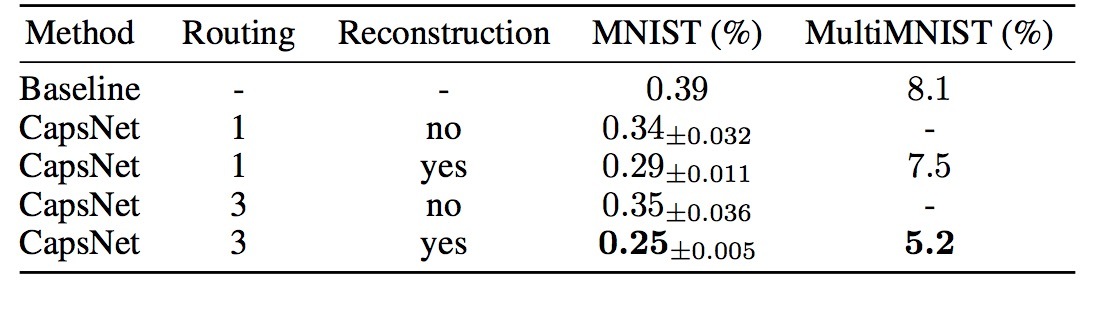
表1 CapsNet分类的test arruracy。
baseline是一个标准的CNN,它具有(256, 256, 128)三通道的三层conv layer。每个具有5x5 kernels,stride=1。最后的conv layers会通过size为328、129的两个FC layers。最后的FC layer会使用dropout、连接到一个10分类的softmax layer上,并使用cross entropy loss。baseline也会使用Adam optimizer在2-pixel shifted MNIST上训练。baseline被设计成:计算开销接近CapsNet,在MNIST上达到最好的效果。在参数数目上,baseline具有35.4M,而CapsNet具有8.2M参数,不使用reconstruction subnetwork会有6.8M参数。
5.1 一个capsule表示的独立维度(individual dimensions)
由于我们会将单个数字的encoding进行传递,并将其它数字置为0, 一个digit capsule的维度应学到:以该类的数字被实例化的方式跨越变种空间。这些变种(variations)包括笔划粗细、倾斜、宽度。他们也包含了特定数字的变种,比如:数字2的尾部长度. 我们可以看到,可以使用decoder网络来表示独立维度(individual dimensions)。在为正确的digit capsule计算activity后,我们可以feed一个该activity vector的扰动版本给decoder网络,并观察扰动是如何影响reconstruction的。这些扰动的示例如图4所示。我们发现,该capsule的某一维度(out of 16)几乎总是表示该数字的宽度。一些维度表示全局变种的组合,而其它维度则表示在该数字的一个局部上的变种。例如,对于数字6的上半部的长度,以及下半部圈的size,使用不同维度。
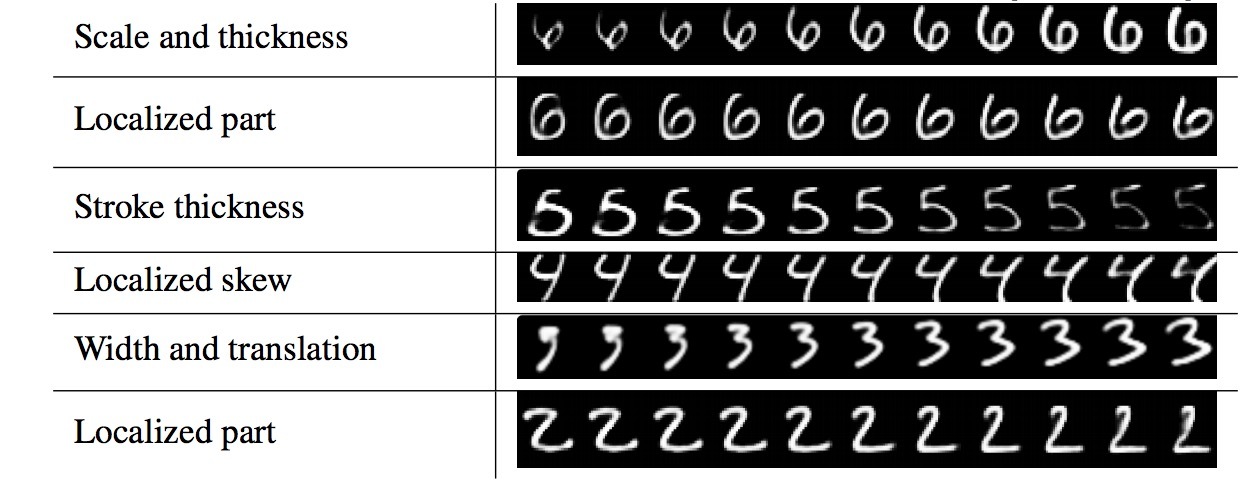
图4
5.2 仿射变换的健壮性
实验表明,对比一个传统的卷积网络,对于每个类,每个DigitCaps capsule会学到一个更健壮的表示。由于在手写数字上的倾斜、旋转、样式等上存在天然的变种,训练好的CapsNet必须对于训练数据的仿射变换有一定的健壮性。
为了测试CapsNet对于仿射变换的健壮性,我们在一个padded和translated MNIST训练集上训练了一个CapsNet和一个传统的CNN(maxpooling和dropout)。在该数据集上,每个样本是一个MNIST数字,随机放置在一个40x40像素的黑色背景上。我们接着在affNIST数据集上测试该网络,在该数据集上每个样本是一个随机进行小的仿射变换的MNIST数字。我们的模型不会使用仿射变换进行训练,而是使用在标准MNIST中可见的平移和自然变换。一个使用early stopping并且训练不够的CapsNet,可以在expanded MNIST测试集上达到99.23% accuracy,并在affNIST测试集上达到79%的accuracy。一个传统的CNN可以在expanded MNIST达到99.22%相近的accuracy,在affnist测试集上达到66%。
6.高度重叠数字的分割
dynamic routing可以被看成是一个并行注意力(parallel attention)机制,它允许在一个level上的每个capsule会留意一些在level below上的active capsules, 并忽略其它。这使得该模型可以识别在图片中的多个物体(objects),即使物体(objects)有重叠。Hinton 2000提出了分割和识别高度重叠数字的任务,其它的(Goodfellow 2013等)已经在相同领域测试了他们的网络。routing-by-aggrement使它可以使用一个关于物体形状的先验来帮助分割(segmentation)。
6.1 MultiMNIST数据集
我们通过将一个数字置于另一个不同数字之上,来生成了MultiMNIST训练集和测试集。每个数字会在每个方向上shift最多4个像素生成一张36x36的图片。考虑到在28x28图片中的一个数字被限定在一个20x20的box中,两个数字的bounding box平均有80%部分有重合。对于在MNIST数据集中的每个数字,我们生成了1K的MultiMNIST样本。因此,训练集的size是60M,测试集size为10M。
6.2 MultiMNIST结果
我们的3 layer CapsNet模型,重新使用MultiMNIST训练数据进行训练,它会比我们的baseline CNN模型达到更高的测试分类accuracy。我们在高度重合数字对上达到相同的分类错误率5%,而Ba 2014的sequential attention模型在一个更简单的任务上(更低重合度)才能达到。在测试图片上,它由来自测试集的成对图片组成,我们将由capsules网络生成的两个最可能active digit capsules作为分类。在reconstruction期间,我们一次选中一个数字,并使用所选数字对应的capsule的activity vector来重构所选数字的图片(我们知道该图片,因为我们使用它来生成组合图片)。与我们的MNIST模型唯一的不同之处是,对于learning rate,我们增加了decay step的周期大于10x,因为训练数据集更大。

图5
重构(reconstructions)如图5所示,它展示了CapsNet可以将该图片划分成两个原始的数字。由于该分割(segmentation)并不在像素级别,我们观察到:模型可以正确处理重合(同时出现在两个数字中的一个像素),从而解释所有的像素。每个数字的position和style在DigitCaps中被编码。decoder已经学到了给定该encoding,来重构一个数字。事实上,尽管有重叠它仍能够重构数字,展示了每个digit capsule可以从PrimaryCapsules layer接收到的投票中选择style和position。
我们将两个最可能的active DigitCaps capsules进行编码,一次一个,来获取两个图片。接着,通过使用非零强度给每个数字来分配像素,我们可以为每个数字获得segmentation的结果。
7.其它数据集
我们使用7个模型的ensemble,每个模型通过在24x24 patches的图片上进行3个routing迭代,还在CIFAR10上测试了我们的capsule模型,并达到了10.6%的error。每个模型具有和MNIST上的简单模型相同的架构,除了使用三种颜色channels、以及使用64个不同类型的primary capsule外。我们也发现,它可以为routing softmaxes帮助引入一个“none-of-the-above”类型,因为我们不能期望具有10个capsules的最后一层来解释图片中的everything。当首次应用到CIFAR10时(zeiler 2013),标准CNN达到10.6% test error。
Capsules与生成模型存在同样的一个缺点是,它可能解释在图片中的任何东西,因此,对比起在dynamic routing中使用一个额外的“孤类(opphan category)”时,当建模杂乱东西(clutter)时它会更好。在CIFAR-10中,背景更多变化,从而不能以一个合理size的网络来建模,这可以帮助解释为什么会有更差的效果。
我们也在smallNORB上测试了与MNIST相同的网络构架,它可以达到2.7%的test error rate,这基本上是state-of-the-art的效果。
另外,我们也在SVHN上训练了一个更小的网络。达到4.3%的test error。