阿里在paper《Deep Session Interest Network for Click-Through Rate Prediction》中提出了基于session的ctr预测模型,我们可以借鉴一下:
0.
大多数已经存在的研究会忽略序列内在的结构:序列由sessions组成,其中sessions是发生时间内独立的用户行为。我们可以观察到:在每个session中的用户行为是同度同质的,不同sessions间差异很大。基于此观察,提出了新的CTR模型:DSIN,它可以利用在行为序列中的用户多个历史sessions。我们首先使用self-attention机制以及bias encoding来抽取每个sessions的用户兴趣。接着,我们应用Bi-LSTM来建模:用户兴趣是如何在sessions间演化和交互的。最后,我们使用local activation unit来自适应学习多个session interests对target item的影响。实验表明:DSIN效果要好于state-of-the-art模型。
1.介绍
如图1所示,从真实工业界应用中抽样得到的一个用户,我们将它的行为序列分为3个sessions。sessions按如下原则进行划分:时间间隔超过30分钟[Grbovic and Cheng, 2018]。该用户在session 1内主要浏览长裤(trousers),在session 2中浏览戒指(finger rings),在sessions 3内浏览大衣(coats)。图1的现像很普遍。它表明:一个用户通常在一个session内有一个明确唯一的意图,而该用户开启另一个session时会发生剧烈变化。

图1 真实应用中的一个关于sessions的demo。图片下的数字表示当前item上点击时间与首个item点击时间之间的时间间隔,以秒计。原则上,Sessions以超过30分钟进行划分.
受上述观察的启发,我们提出了DSIN(Deep Session Interest Network)来在CTR预测任务上,通过利用多个历史sessions来建模用户序列行为。DSIN有三个关键部分。
- 首先,将用户序列行为划分成sessions。
- 接着,使用self-attention network以及bias encoding来建模每个session。Self-attention可以捕获session行为(s)的内在交互/相关,接着抽取每个session的用户兴趣(s)。这些不同的session interests可能相互间相关,接着遵循一个序列模式。
- 最后,我们使用Bi-LSTM来捕获交互、以及用户多个历史session interests的演进。由于不同session interests对于target item具有不同的影响,最终我们设计了local activation unit根据target item来聚合他们,形成该行为序列的最终表示。
主要贡献:
- 我们强调用户行为在每个session中高度同质,不同sessions差异很大。
- 设计了一个self-attention network以及bias encoding来获得每个session的精准兴趣表示。接着我们使用Bi-LSTM来捕获历史sessions间的顺序关系(sequential relationship)。最后,考虑到不同session interest在target item上的影响,我们使用local activation unit来聚合。
- 两组比较实验。表明DSIN效果更好。
2.相关工作
2.1 CTR
略
2.2 Session-based推荐
session的概率常被序列化推荐提及,但很少出现在CTR预测任务中。Session-based推荐受益于用户兴趣在sessions上动态演化的启发。GFF使用关于items的sum pooling来表示一个session。每个item具有两种表示,一个表示自身,另一个表示session的上下文(context)。最近,RNN-based方法被应用于session-based推荐中来捕获在一个session中的顺序关系。基于此,Li 2017提出了一个新的NARM(attentive neural networks framework)来建模用户的序列化行为,并能捕获用户在当前session中的主要目的。Quadrana 2017提出的Hierarchical RNN依赖于RNNs的latent hidden states跨用户历史sessions的演化。另外,Liu 2018 的RNNs使用self-attention based模型来有效捕获一个session的long-term和short-term兴趣。Tang 2018使用CNN、Chen 2018使用user memory network来增强序列模型的表现力。
3.DSIN
3.1 BaseModel
本节主要介绍BaseModel所使用的:
- feature representation,
- embedding,
- MLP以及loss function。
特征表示
CTR预测任务中统计了大量信息特征。总共使用了三大组:User profile、item profile、User Behavior。每组包含了一些稀疏特征:
- User Profile包含了gender、city等;
- Item Profile包含了:seller id、brand id等;
- User Behavior包含了用户最近点击的item ids等
注意,item的side information可以进行拼接来表示自身。
Embedding
MLP
Loss Function
3.2 模型总览
在推荐系统中,用户行为序列包含了多个历史sessions。用户在不同sessions上兴趣不同。另外,用户的session interests相互间有顺序关联。DSIN提出了在每个session上抽取用户的session interest,并捕获session interests间的顺序关系。
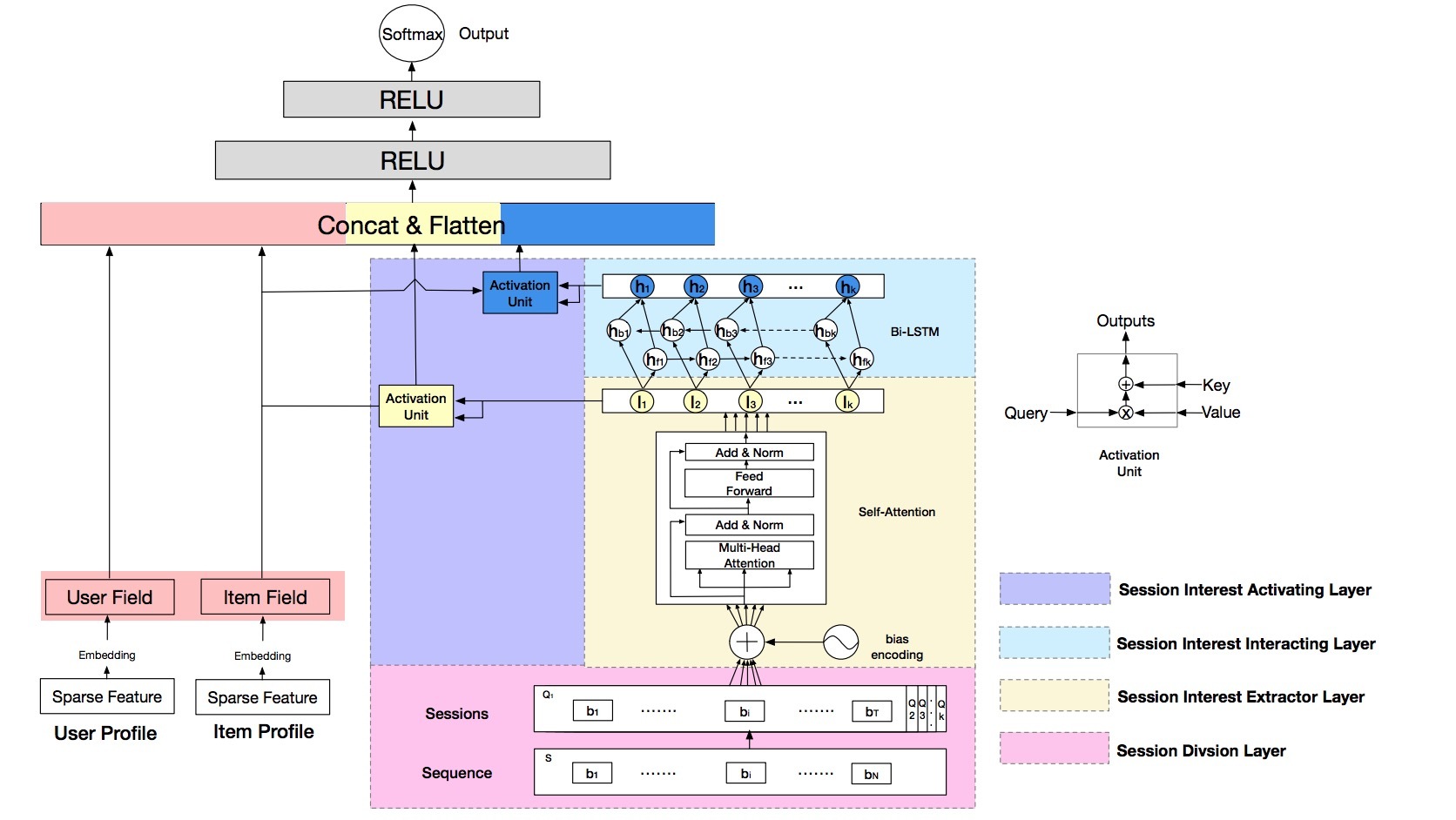
图2 DSIN模型总览。在MLP layers前,DSIN主要由两部分组成。一部分是sparse features,另一部分处理用户行为序列。自顶向上,用户行为序列S首先被划分成sessions Q,它接着会加上bias encoding,并使用self-attention来抽取session interests I。有了Bi-LSTM,我们将session interests I和上下文信息进行混合作为hidden states H。session interests I和hidden states H的Vectors受target item的激活,User profile和item profile的embedding vectors被拼接在一起,进行flatten并被feed到MLP layers中进行最终预测
如图2所示,DSIN在MLP前包含了两部分。一部分是从User Profile和Item Profile转向后的embedding vectors。另一部分是对User Behavior进行建模,自顶向上具有4个layers:
- 1) session division layer,会将用户行为序列划分为sessions
- 2) session interest extractor layer:会抽取用户的session interests
- 3) session interest interacting layer:会捕获session interests间的顺序关系
- 4) session interest activating layer:会对与target item有关的session interests使用local activation unit
最后,session interest activating layer的最终输出、以及User Profile和Item Profile的embedding vectors被feed给MLP做最终预测。以下述章节中,我们会引入这4个layers。
1.Session Division Layer
为了抽取更精准的用户的session interests,我们将用户行为序列S划分成sessions Q,其中第k个session为:
\[Q_k = [b_1; \cdots; b_i; \cdots; b_T] \in R^{T \times d_{model}}\]其中:
- T是我们在该session中的行为数
- \(b_i\)是在该session中的用户第i个行为
相邻行为间存在的user sessions的划分,会遵循该原则:时间间隔超过30分钟。
2.Session Interest Extractor Layer
在相同session中的行为,相互之间强相关。另外,用户在session中的偶然行为会使得该session interest偏离它的原始表示(original expression)。为了捕获在相同session中的行为间的内在关系,并减少这些不相关行为的效果,我们在每个session中使用multi-head self-attention机制。我们也对self-attention机制做了一些改进来更好地达到我们的目的。
2-1 Bias Encoding
为了利用sequence的顺序关系,self-attention机制会应用positional encoding到input embeddings中。另外,sessions的顺序关系,以及在不同表示子空间中存在的bias需要被捕获。因而,我们在position encoding的基础上提出了bias encoding(BE):
\[BE \in R^{K \times T \times d_{model}}\]其中BE中的每个元素被如下定义:
\[BE_{(k,t,c)} = w_k^K + w_t^T + w_c^C\]…(2)
其中:
- \(w^K \in R^K\):是session的bias vector
- k:是sessions的索引
- \(w^T \in R^T\):是在session中position的bias vector
- t:是在sessions中行为的索引
- \(w^C \in R^{d_{model}}\):是在behavior embedding中unit position的bias vector
- c:是在behavior embedding中unit的index
在加上bias encoding后,用户的behavior sessions Q按如下方式更新:
\[Q = Q + BE\]…(3)
2-2 Multi-head Self-attention
在推荐系统中,用户的点击行为受许多因素(颜色、风格、价格等)的影响。Multi-head self-attention可以捕获不同表示子空间的表示。数学上,假设:
\[Q_k = [Q_{k1}; \cdots; Q_{kh}; \cdots; Q_{kH}]\]其中:
- \(Q_{kh} \in R^{T \times d_h}\):是\(Q_k\)的第h个head
- H是heads的数目
- \[d_h = \frac{1}{h} d_{model}\]
\(head_h\)的输出如下计算:
\[head_h = Attention(Q_{kh} W^Q, Q_{kh} W^K, Q_{kh} W^V) \\ =softmax(\frac{Q_{kh} W^Q W^{K^T} Q_{kh}^T}{\sqrt{d_{model}}}) Q_{kh} W^V\]…(4)
其中,\(W^Q, W^K, W^Q\)是线性矩阵。
接着不同heads的vectors被拼接到一起被feed到一个feed-forward network中:
\[I_k^Q = FFN(Concat(head_1, \cdots, head_H) W^O)\]…(5)
其中,\(FFN(\cdot)\)是feed-forward network,\(W^O\)是线性矩阵。我们也在相继使用了residual connections和layer normalization。用户的第k个session的兴趣\(I_k\)按如下方式计算:
\[I_k = Avg(I_k^Q)\]…(6)
其中,\(Avg(\cdot)\)是average pooling。注意,在不同sessions间self-attention机制中的weights是共享的。
3.Session Interest Interacting Layer
用户的session interests会持有带上下文的顺序关系。建模动态变化会增强session interests的表示。Bi-LSTM在捕获顺序关系是很优秀的(此处有疑问?? self-attention也能捕获顺序关系,感觉有些多此一举),很天然地可应用于在DSIN中建模session interest的交互。LSTM cell的实现如下:
\[i_t = \sigma(W_{xi} I_t + W_{hi} h_{t-1} + W_{ci} c_{t-1} + b_i) \\ f_t = \sigma(W_{xf} I_t + W_{hf} h_{t-1} + W_{cf} c_{t-1} + b_f) \\ c_t = f_t c_{t-1} + i_t tanh(W_{xc}I_t + W_{hc} h_{t-1} + b_c) \\ o_t = \sigma(W_{xo} I_t + W_{ho} h_{t-1} + W_{co}c_t + b_o) \\ h_t = o_t tanh(c_h)\]…(7)
其中,\(\sigma(\cdot)\)是logistic function,其中: i,f,o,c分别是:input gate、forget gate、output gate、cell vector,它们具有与\(I_t\)相同的size。权重矩阵的shapes可以通过下标来表示。Bi-direction意味着存在forward和backward RNNs,hidden states H按如下方式计算:
\[H_t = \overrightarrow {h_{ft}} \oplus \overleftarrow {h_{bt}}\]…(8)
其中,\(\overrightarrow {h_{ft}}\)是forward LSTM的hidden state,\(\overleftarrow {h_{bt}}\)是backward LSTM的hidden state。
4.Session Interest Activating Layer
与target item更相关的用户的session interests,对于用户是否点击该target item的影响更大。用户的session interests的weights需要根据target item进行重新分配。Attention机制(再做一次attention)会使用在source和target间的soft alignment,被证明是一个很有效的weight allocation机制。与target item相关的session interests的自适应表示可以如下计算得到:
\[a_k^I = \frac{exp(I_k W^I X^I)}{\sum\limits_k^K exp(I_k W^I X^I)} \\ U^I = \sum\limits_k^K a_k^I I_k\]…(9)
其中\(W_I\)具有相应的shape。相似的,session interests的自适应表示会混杂着与target item相关的上下文信息,如下计算:
\[a_k^H = \frac{exp(H_k W^H X^I)}{\sum\limits_k^K exp(H_k W^H X^I)} \\ U^H = \sum\limits_k^K a_k^H H_k\]…(10)
其中\(W_H\)具有相应的shape。User Profile和Item Profile的Embedding vectors,\(U^I\)和\(U^H\)会被拼接到一起,flatten,然后feed给MLP layer。
4.实验
略.