阿里在KDD 2018上开放了它们的方法:《Deep Interest Network for Click-Through Rate Prediction》, 我们来看下:
背景
在电商网站上,比如:阿里巴巴,广告是天然的商品。在本paper的剩余部分,如果没有特别声明,我们会将广告(ads)看成是商品。图1展示了在Alibaba的展示广告系统的运行过程,它包含了两个主要stages:
- i) 匹配阶段(matching):它会通过类似CF的方法生成与正访问用户相关的候选广告列表
- ii) 排序阶段(ranking):它会为每个给定广告预测ctr,接着选择topN个排序后广告
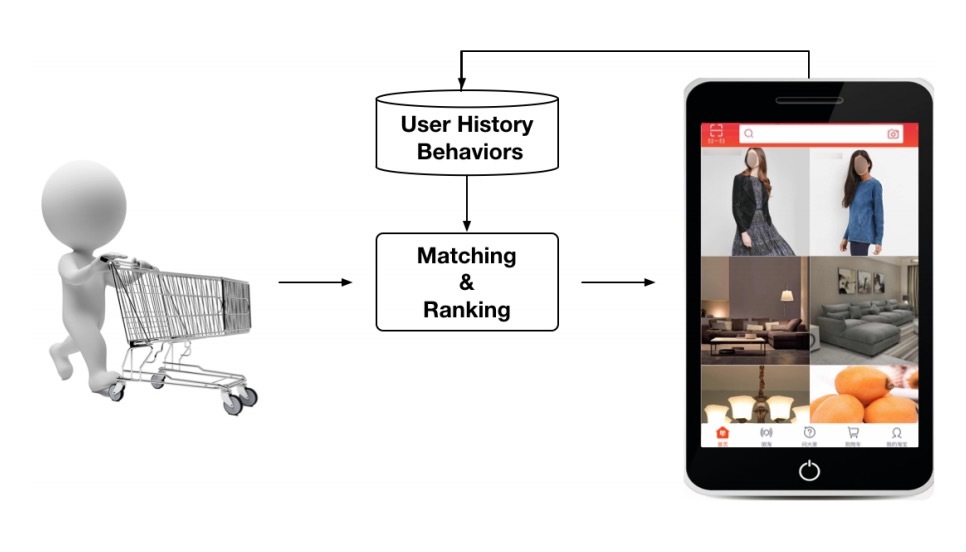
图1
每天,有上亿用户访问是电商网络,留给我们大量用户行为数据。值得一提是,带有丰富历史行为的用户包含了多样化的兴趣。例如,一个年轻母亲最近浏览的商品包含:羊毛大衣、T恤、耳环、大手提包、皮手袋、婴儿衣。这些行为数据给了我们一些关于它的购物兴趣的线索。当她访问电商网站时,系统会将合适的广告展示给她,例如,一个新的手提包。很明显,展示广告只会匹配(matches)或者激活(activates)她的部分兴趣。总之,具有丰富用户行为数据的用户兴趣很多样(diverse),可能会受特定广告的局部影响(locally activated)。我们会在paper后展示利用这些特性来构建ctr模型。
4. DIN
不同于竞价排名搜索(sponsored search),用户进入展示广告系统无需显式的意愿。当构建ctr模型时,需要有效方法来从历史行为中抽取用户兴趣。描述users和ads的特征是在CTR模型中的基本元素。合理充分利用这些特征,以及从它们中挖掘信息很关键。
4.1 特征表示
在工业界CTR预测任务中的数据大多数以多分组类别型(multi-group catgorial)形式存在,例如: [weekday=Friday, gender=Female,visited_cate_ids={Bag,Book}, ad_cate_id=Book], 它通常通过encoding[4,19,21]被转换成高级稀疏二值特征。数学上,第i个特征组(feature group)的编码向量可以使用公式化表示:\(t_i \in R^{K_i}\)。\(K_i\)表示特征组i的维度,这意味着特征组i包含了\(K_i\)个唯一的ids。\(t_i[j]\)是\(t_i\)第j个元素,并且满足\(t_i[j] \in \lbrace 0, 1 \rbrace\)。\(\sum\limits_{j=1}^{K_i} t_i[j]=k\)。k=1的向量\(t_i\)指的是one-hot encoding,而k>1表示multi-hot encoding。接着,一个实例可以以group-wise的形式被表示成:\(x = [t_1^T,t_2^T,, ..., t_M^T]^T\),其中M是特征组的数目,\(\sum\limits_{i=1}^M K_i = K\),其中K是整个特征空间的维度。在该方法下,上述实例会有4个分组的特征,如下所示:
\[\underbrace{[0,0,0,0,1,0,0]}_{weekday=Friday} \underbrace{[0,1]}_{gender=Female} \underbrace{[0, .., 1, ..., 1,...,0]}_{visited\_cate\_ids=\lbrace Bag,Book \rbrace} \underbrace{[0,..,1,..,0]}_{ad\_cate\_id=Book}\]我们系统中用到的整个特征集在表1中描述。它由4个类别组成,用户行为特征通常使用multi-hot encoding向量并包含了关于用户兴趣的丰富的信息。注意,在我们的setting中,没有组合特征(combination features)。我们会使用DNN来捕捉特征的交叉。
4.2 Base Model (Embedding & MLP)
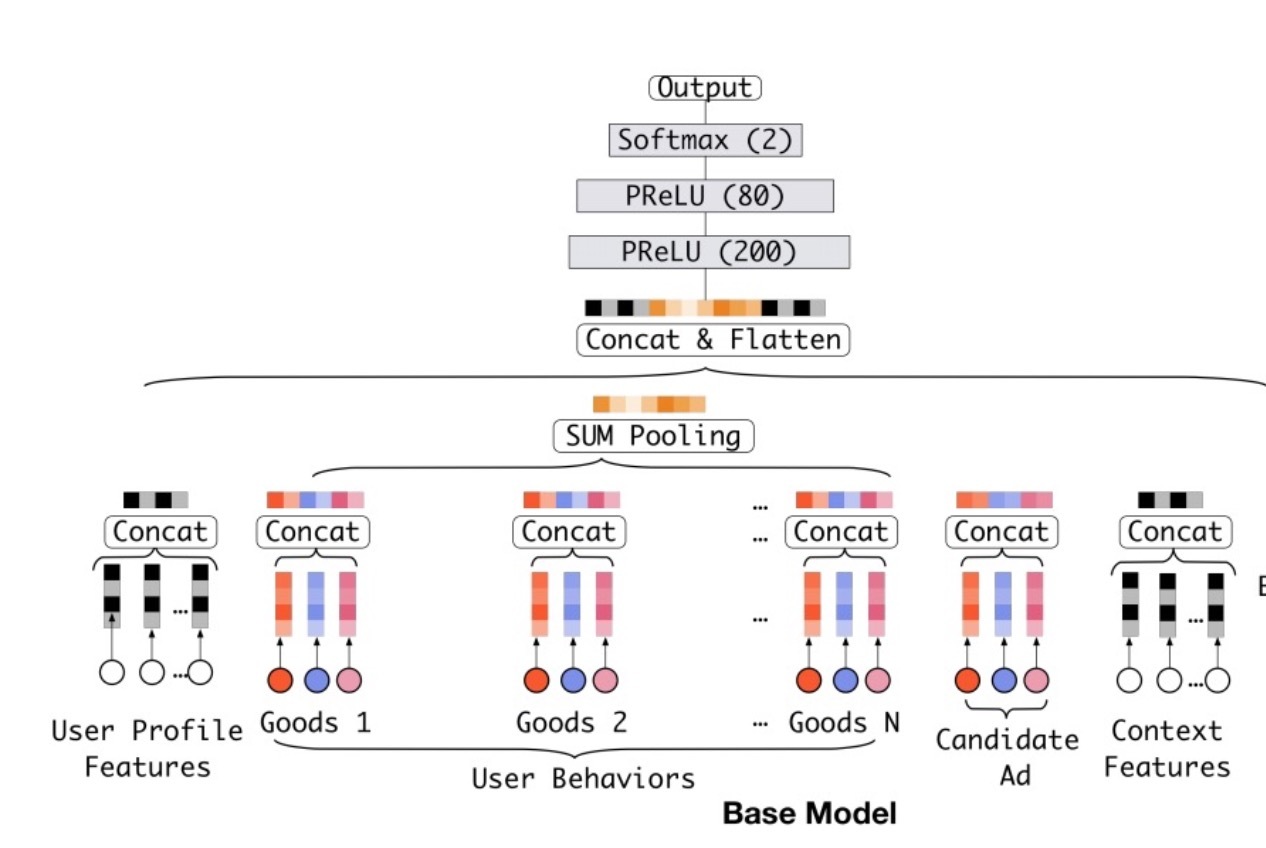
图2a
大多数流行的模型结构[3,4,21]共享一个相似的Embedding&MLP范式,我们称之为base model,如图2左侧所示。它包含了许多部件:
Embedding layer。由于输入是高维二值向量,embedding layer被用于将他们转换成低维dense表示。对于\(t_i\)第i个feature group,假设 \(W_i = [w_1^i, ..., w_j^i, ..., w_{K_i}^i,] \in R^{D \times K_i}\)表示第i个embedding字典,其中\(w_j^i \in R^D\)是一个具有维度为D的embedding vector。Embedding操作会遵循查表机制,如图2所示。
- 如果\(t_i\)是one-hot vector,其中第j个元素\(t_i[j]=1\),\(t_i\)的embedded表示是一个单一embedding vector \(v_i = w_j^i\)
- 如果\(t_i\)是multi-hot vector,其中对于\(j \in \lbrace i_1,i_2, ..., i_k \rbrace\)有\(t_i[j]=1\),\(t_i\)的embedded表示是一个embedding vectors列表:\(\lbrace e_{i=1}, e_{i=2}, ..., e_{i_k} \rbrace= \lbrace w_{i_1}^i, w_{i_2}^i, ... w_{i_k}^i \rbrace\)。
Pooling layer和Concat layer。注意,不同用户具有不同数目的行为。因而对于multi-hot行为特征向量\(t_i\),它的非零值数目会各有不同,从而造成相应的embedding vectors的长度是个变量。由于Fully-connected网络只能处理定长输入。常见的做法[3,4]是将embedding vectors的列表通过一个pooling layer来获得一个固定长度的向量:
\[e_i = pooling(e_{i_1}, e_{i_2}, ..., e_{i_k})\]…(1)
两种最常用的pooling layers是:sum pooling和average pooling。它可以使用element-wise sum/average操作到embedding vectors列表中。
embedding和pooling layers操作两者都会以group-wise方式将原始稀疏特征映射到多个固定长度表示向量中。接着所有向量被拼接(concatenated)在一起来获得该样本的整个表示向量(overall representation vector)。
MLP。给定拼接后的dense representation vector,FC layers会被用于自动学习特征组合。最近开发的方法[4,5,10]集中于设计MLP的结构来更好的进行信息抽取。
Loss。base model的目标函数为负log似然函数:
\[L = - \frac{1}{N} \sum\limits_{(x,y)\in S} (y logp(x) + (1-y) log(1-p(x)))\]…(2)
其中S是size N的训练集,x是网络输入,\(y \in \lbrace 0, 1 \rbrace\)是label,p(x)是在softmax layer后的网络输出,它表示样本x被点击的预测概率。
4.3 DIN结构
在表1的所有这些特征中,用户行为特征十分重要,它在电商应用场景中对于建模用户兴趣时扮演重要角色。
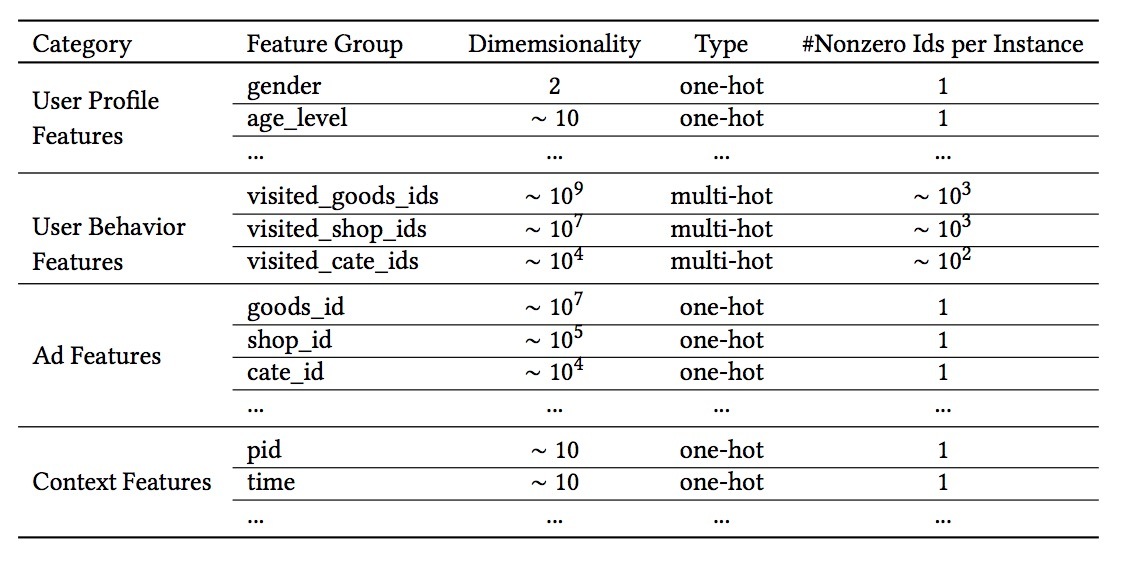
表1
Base model可以获取关于用户兴趣的固定长度的表示向量,它通过将所有embedding vectors在用户行为feature group上进行pooling,如等式(1)所示。该表示向量对于一个给定的用户来说保持相同,具有有限维度的用户表示向量在表现用户的多样化兴趣时会是一个瓶颈。为了让它可行,一种简单的方法是扩展embedding vector的维度,但很不幸的是这将极剧地增加学习参数的size。这会导致在有限数据下的overfitting,并增加了计算和存储的负担,这对于一个工业界在线系统是不可接受的。
是否存在一种更优雅的方式,在一个向量中使用有限维来表示用户的多样化兴趣?用户兴趣的局部活跃性(local activation characteristic)给了我们启发,我们设计了一个新模型,称为DIN(Deep interest network)。想像下,当一个年轻母亲访问了电商网站,她找到了展示的新手提包,并点击了它。我们仔细分析下点击行为的驱动力。通过对这位年轻母亲的历史行为进行软搜索(soft-searching),并发现她最近浏览过手提袋(tote bag)和皮手袋(leather handbag)相似的商品,展示广告点刚好与她的兴趣相关。换句话说,行为相关的展示广告可以对点击行为做出重大贡献。DIN在局部活跃兴趣对于给定广告的表示(representation)上有一定注意力(pay attention to),来模仿该过程。DIN不需要使用相同的向量来表示所有用户的多样化兴趣,它会考虑到历史行为与候选广告间的相关度,自适应地计算用户兴趣的向量表示。这种representation vector会随广告的不同而改变。
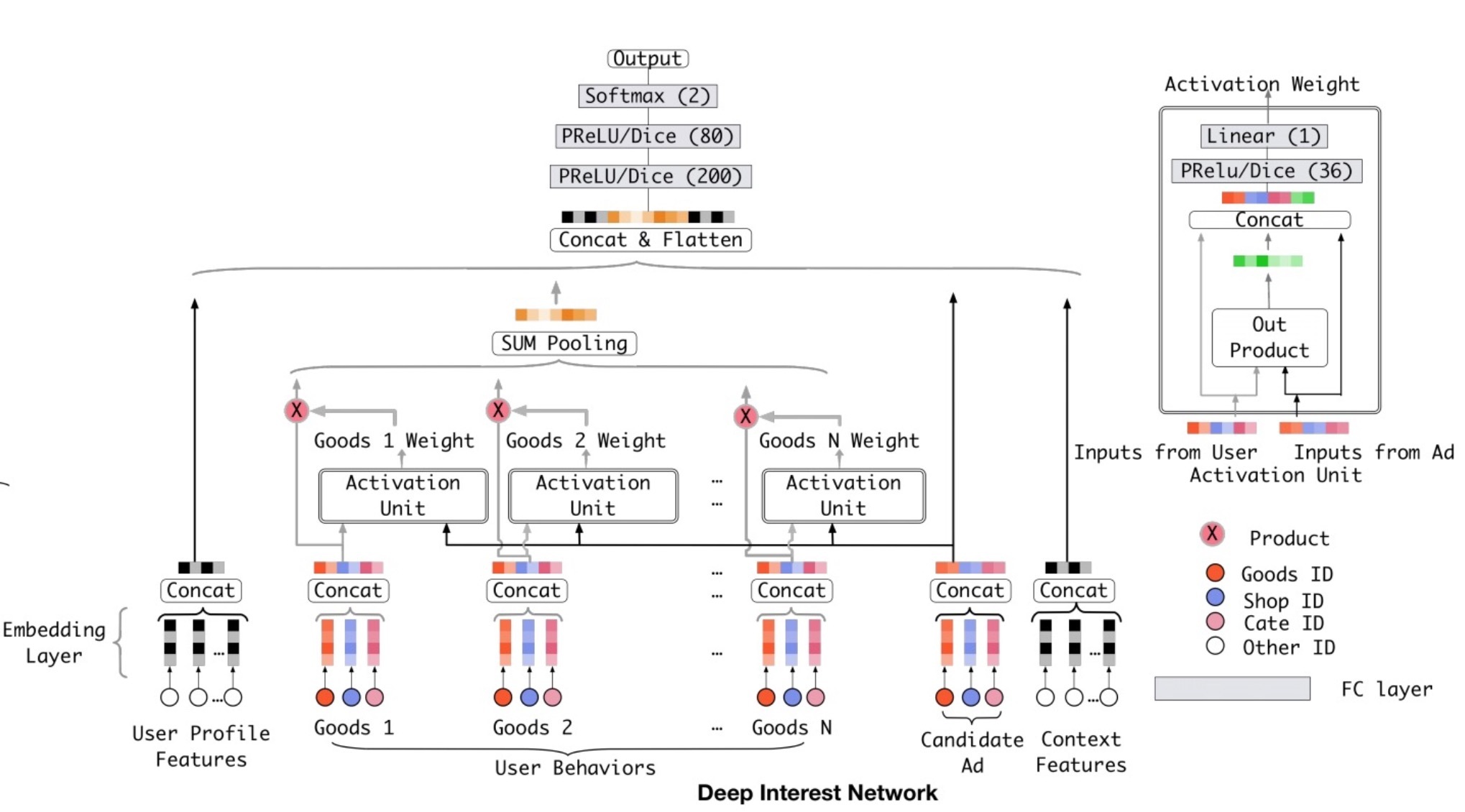
图2b
图2的右侧展示了DIN的结构。对比起base model,DIN引入了新设计和局部激活单元(local activation unit),其它的结构完全相同。特别的,activation units可以应用到用户行为特征上,它会执行一个加权求和平均(weighted sum pooling)来自适应地计算:在给定一个候选广告A时的用户表示(user representation \(v_U\)),如公式(3):
\[v_U(A) = f(v_A, e_1, e_2, ..., e_H) = \sum\limits_{j=1}^{H} a(e_j, v_A) e_j = \sum\limits_{j=1}^H w_j e_j\]…(3)
其中:
- \(\lbrace e_1, e_2, ..., e_H\rbrace\)是用户u的行为的embedding vectors列表,它的长度为H
- \(v_A\)是广告A的embedding vector。
- \(v_U(A)\)会随着不同的广告而变化。
- \(a(\cdot)\)是一个feed-forward网络,它的输出作为activation weight,如图2所示。
除了两个input embedding vectors外,\(a(\cdot)\)会添加它们的外积(output product)来feed到后续网络中,这对于帮助相关度建模来说是显式可知的。
等式(3)的局部激活单元与NMT任务[1]中的attention方法的思想一致。然而,不同于传统的attention方法,在等式(3)中没有\(\sum\limits_i w_i=1\)的限制,从而可以存储用户兴趣的强度(intensity)。也就是说,在\(a(\cdot)\)的output上进行softmax归一化会被取消。做为替代,\(\sum_i w_i\)的值被看成是:在某种程度上,对活跃用户兴趣的强度的一个近似。例如,如果一个用户的历史行为包含了90%的衣服类,10%电子类。给定两个候选广告(T-shirt和phone),T-shirt会激活大多数那些属于衣服(clothes)的历史行为,并可能给出一个比手机(phone)的\(v_U\)更大值。传统的attention方法通过对 \(a(\cdot)\)的output进行归一化会丢掉在\(v_U\)在数值范围上的辩识度。
我们以序列的方式尝试了LSTM来建模用户历史行为数据,但结果展示并没有提升。不同于在NLP任务中语法限制下的文本,我们的用户历史行为序列可能包含多个并发兴趣(concurrent interests)。在这些兴趣上快速跳过和突然结束,会造成用户行为序列数据看起来有噪声。一个可能的方向是,设计特殊结构来以序列方式建模这样的数据。我们会在后续进行研究。
5.训练技术
在Alibaba的广告系统中,商品和用户的数目规模达到上亿。实际上,训练具有大规模稀疏输入特征的工业界深度网络,十分具有挑战性。在本部分,我们引入了两个实际中很有用的重要技术。
5.1 Mini-batch Aware正则化
训练工业界网络,overfitting是很严峻的挑战。例如,除了细粒度特征外,比如:商品id(goods_ids)这样的特征维度有60亿维(包含了表1描述的关于用户的visited_goods_ids,以及关于ad的goods_id),在训练期间,如果没有正则化(regularization),模型性能在第一个epoch之后会快速下降,如6.5节的图4的黑绿线所示。在训练具有稀疏输入和数亿参数的网络时,直接使用传统的正则化方法(l2和l1正则化)并不实际。以l2正则为例:只有出现在每个mini-batch上的非零稀疏特征,需要在SGD的场景下基于无需正则化的最优化方法被更新。然而,当添加l2正则时,它需要为每个mini-batch的所有参数之上计算l2-norm,这会导致严重的计算开销,当参数扩展至数亿时是不可接受的。
在本paper中,我们引入了一种有效的mini-batch aware regularizer,它只需要计算出现在每个mini-batch上的稀疏特征参数的l2-norm,这使得计算是可行的。事实上,对于CTR预测模型来说,embedding字典贡献了大多数参数,并带来了严重的计算开销。假设\(W \in R^{D \times K}\)表示整个embedding字典的参数,其中D是embedding vector的维度,K是feature space的维度。我们通过抽样(samples)扩展了在W上的l2正则:
\[L_2(W) = \|W\|_2^2 = \sum\limits_{j=1}^K \|w_j\|_2^2 = \sum\limits_{(x,y) \in S} \sum\limits_{j=1}^{K} \frac{I(x_j \neq 0 )}{n_j} \|W_j\|_2^2\]…(4)
其中:
- \(w_j \in R^D\)是第j维的embedding vector
- \(I(x_j \neq 0)\)表示实例x是否具有特征id j
- \(n_j\)表示特征id j在所有样本中的出现次数
等式(4)可以以mini-batch aware的方式被转换成公式(5):
\[L_2(W) = \sum\limits_{j=1}^{K} \sum\limits_{m=1}^{B} \sum\limits_{(x,y) \in B_m} \frac{I(x_j \neq 0)}{n_j} \|W_j \|_2^2\]…(5)
其中:
- B表示mini-batch的数目
- \(B_m\)表示第m个mini-batch
假设\(\alpha_{mj} = \max\limits_{(x,y) \in B_m} I(x_j \neq 0)\)表示是否存在至少一个实例在mini-batch \(B_m\)上具有特征id j。那么等式(5)可以近似为:
\[L_2(W) \approx \sum\limits_{j=1}^K \sum\limits_{m=1}^B \frac{\alpha_{mj}}{n_j} \| w_j \|_2^2\]…(6)
这种方式下,我们对一个近似的mini-batch aware版本的l2正则进行求导。对于第m个mini-batch,对于特征j的各embedding weights的梯度:
\[w_j \leftarrow w_j - \eta [ \frac{1}{|B_m| }\sum\limits_{(x,y) \in B_m} \frac{\partial L(p(x),y)}{\partial w_j} + \lambda \frac{\alpha_{mj}}{n_j} w_j]\]…(7)
其中,只有出现在第m个mini-batch特征参数参与正则计算。
5.2 数据自适应激活函数(Data Adaptive Activation Function)
PReLU[12]是一种常用的activation函数:
\[f(s) = \begin{cases} s, & \text{if s > 0} \\ \alpha s, & \text{if s $\leq$ 0} \end{cases} = p(s) \cdot s + (1-p(s)) \cdot \alpha s\]…(8)
其中,s是activation函数\(f(\cdot)\)输入的某一维,\(p(s)=I(s>0)\)是一个指示函数(indicator function),它控制着\(f(s)\)在两个通道\(f(s)=s\)和\(f(s)=\alpha s\)间的切换。\(\alpha\)是一个可学习参数。这里我们将\(p(s)\)看成是控制函数。
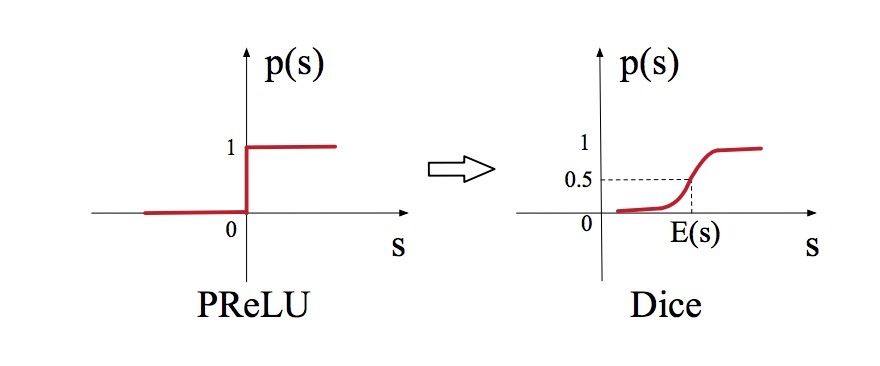
图3
图3的左侧画出了关于PReLU的控制函数。PReLU会采用一个在0值处的硬修正点(hard rectified point),当每个layer的输入遵循不同的分布时它可能并不适合。考虑这一点,我们设计了一种新的data adaptive activation function,称为Dice:
\[f(s) = p(s) \cdot s + (1-p(s)) \cdot \alpha s, p(s)= \frac{1} {1 + e^{-\frac{s-E[s]}{\sqrt{Var[s]+\epsilon}}}}\]…(9)
控制函数会在图3的右键进行绘制。在训练阶段,\(E[s]\)和\(Var[s]\)是在每个mini-batch中输入的均值(mean)和方差(variance)。在测试阶段,\(E[s]\)和\(Var[s]\)通过在数据上E[s]和Var[s]的移动平均来计算。\(\epsilon\)是一个小的常数,在我们的实践中可以被设置成\(10^{-8}\)。
Dice可以被看成是PReLu的一种泛化。Dice的关键思想是,会根据输入数据的分布自适应调整修正点(rectified point),它们的值被置成输入的平均(mean)。另外,Dice会平滑控制着在两个通道间的切换。当\(E[s]=0\)和\(Var[s]=0\)时,Dice会退化成PReLU.
6. 实验
在本节中,我们进行实验,包含数据集、评估指标、实验设置、模型比较、以及对应的分析。实验会在关于用户行为的两个公共数据集上进行,同时也会在alibaba的展示广告系统中收集到的数据集上进行,效果会与state-of-the-art的CTR预估方法进行比较。两个公共数据集和实验代码在github上有提供。
6.1 数据集和实验设定
Amazon数据集: Amazon数据集包含了产品评论和元数据,可以用于benchmark数据集[13,18,23]。我们在一个称为“电子产品(electronics)”的子集上展开实验,它包含了192403个用户,63001个商品,801个类目,以及1689188个样本。在该数据集上的用户行为很丰富,对于每个用户和每个商品超过5个评论。特征包含:goods_id, cate_id, 用户评论的goods_id_list和cate_id_list。假设一个用户的所有行为是\((b_1, b_2, ..., b_k, ..., b_n)\),任务是:通过利用前k个评论的商品,预测第(k+1)个评论的商品。会为每个用户使用k=1,2,…,n-2来生成训练数据集。在测试集上,我们给定前n-1个评论的商品预测最后一个。对于所有模型,我们使用SGD作为optimizier,使用指数衰减,它的learning rate从1开始,衰减率设置为0.1.mini-batch设置为32.
MovieLens Dataset:MovieLens数据[11]包含了138493个用户,27278个电影,21个类目和20000263个样本。为了让ctr预测任务更合适,我们将它转成一个二分类数据。原始的用户对电影评分是[0,5]间的连续值,我们将4和5以上的样本标记为正样本(positive),其余为负样本。我们基于userID将数据划分成训练和测试数据集。在138493个用户中,其中10w被随机选到训练集上,其余38493为测试集。任务是基于用户行为预测用户是否会对一个给定的电影给出3以上的评分。特征包括:movie_id, movie_cate_id以及用户评分列表movie_id_list,movie_cate_id_list。我们使用与Amazon数据集相同的optimizer,learning rate和mini-batch size。
Alibaba数据集:我们从Alibaba的在线展示广告系统中收集了真实流量日志,两种的样本用于训练集、其余用户测试集。训练集和测试集的size各自大约为20亿、0.14亿。 对于所有deep模型,所有16个组的特征的embedding vector的维度为12. MLP的Layers设置为 192 x 200 x 80 x 2. 由于数据量很大,我们将mini-batch size设置为5000,并使用Adam作为Optimizier。我们使用指数衰减,它的learning rate初始为0.001,接着decay rate设置为 0.9.
上述数据集相关的统计数据如表2所示。
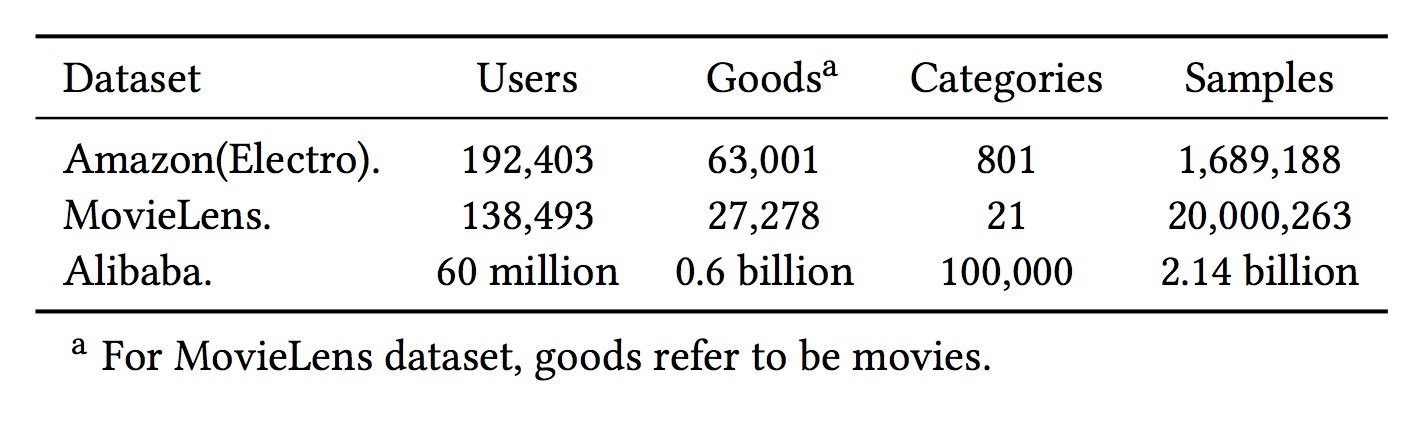
表2
6.2 算法比较
- LR: 较弱baseline
- BaseModel: 如第4.2节所示,BaseModel采用Embedding&MLP架构。作为较强baseline
- WideDeep:
- PNN:
- DeepFM:
6.3 指标
在CTR预测领域,AUC是广泛使用的指标。它可以测量使用预估CTR对所有ads排序的好坏(包括intra-user和inter-user顺序)。用户加权AUC在[7,13]中引入,它通过在用户上对AUC进行平均,来测量intra-user序的好坏,在展示广告系统中会展示出与在线效果更相关。在实验中我们采用该指标。出于简洁性,我们仍将它看成是AUC。计算如下:
\(AUC = \frac{\sum\limits_{i=1}^n \#impression_i \times AUC_i}{ \sum\limits_{i=1}^n \#impression_i}\) …(10)
其中n是用户数,\(\#impression_i\)和\(AUC_i\)是impression数,AUC对应于第i个用户。
另外,我们根据[25]来介绍RelaImpr指标来测量模型的相对提升。对于一个随机猜测器(random guesser),AUC的值为0.5. 因此,RelaImpr按如下定义:
\[RelaImpr = (\frac{AUC(measured model) - 0.5} {AUC(base model) - 0.5}) \times 100%\]…(11)
6.4 在Amazon数据集和MovieLens数据集上的结果比较
6.7
6.8 DIN可视化
最后,我们结合案例研究来展示DIN在Alibaba数据集上的内部结果。我们首先确认了局部激活单元(local activation unit)的有效性。图5展示了用户行为各自对应一个候选广告上的激活强度(activation intensity)。正如我们所预料到的,与候选广告具有高相关性的权重更高。
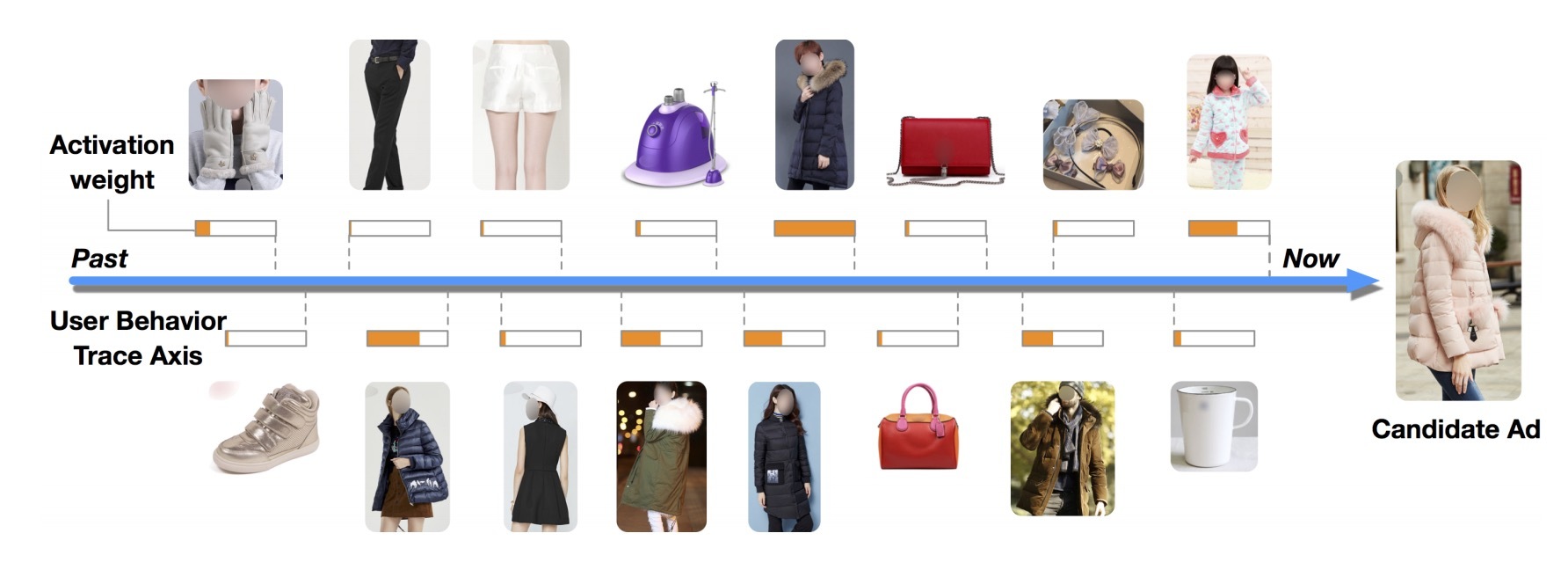
图5
我们接着将学到的embedding vectors进行可视化。还是以之前的年轻母亲为例,我们为该用户随机选择9个类型(dress、sport shoes、bags、等)以及每个类目下的100个商品作为候选广告。图6展示了通过DIN学到的商品embedding vectors的可视化,它使用t-SNE进行表示,相同形状对应相同的类目。我们可以看到,相同类目的商品几乎属于一个聚类,这很明显展示了DIN embeddings的聚类特性。另外,我们通过预测值对候选广告进行着色。图6是这位妈妈在embedding空间上的兴趣密度分布的一个热度图。它展示了DIN可以在候选集的embedding space上,为一个特定用户捕获它的多样化兴趣,从而构成一个多模态兴趣密度分布。
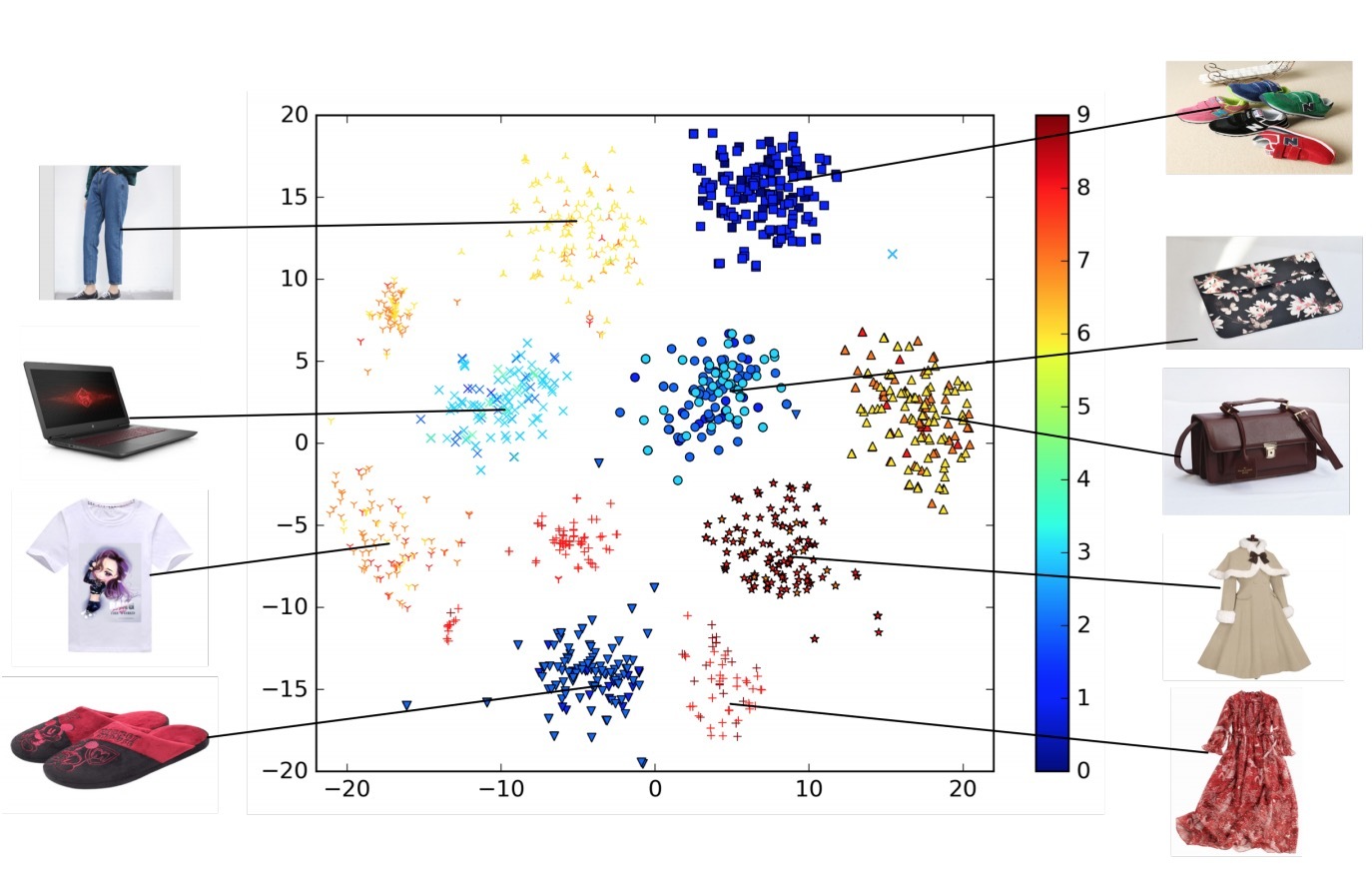
图6
7.结论
在本paper中,我们关注CTR预测任务在电商展示广告场景下的建模。在传统deep CTR模型上使用固定长度的表示(representation)对于捕获用户兴趣多样性(diversity)来说是个瓶颈。为了提升模型的表现力,设计了一种称为DIN的新方法,来激活相关的用户行为,从而为用户兴趣在不同的广告上获取一个自适应表示向量。另外,我们引入了两种新技术来帮助训练工业界深度网络,从而进一步提升DIN的效果。他们可以很方便地泛到到其它工业界deep learning任务上。DIN现在已经在Alibaba中在线展示广告系统上部署。