airbnb在KDD 2018上开放了它们的方法:《Real-time Personalization using Embeddings for Search Ranking at Airbnb》, 我们来看下:
介绍
在过去十年的搜索体系中(通常基于经典的IR),已经出现了许多机器学习技术,尤其是在搜索排序领域。
任何搜索算法的目标(objective)都依赖于自身的平台。其中,一些平台的目标是增加网站参与度(engagement:比如在搜索之后的新闻文章上的点击、消费),还有的目标是最大化转化率(conversions: 比如:在搜索后的商品或服务的购买),还有的目标是需要为双边市场主体(比如:购买者和零售商)优化搜索结果。这种双边市场会合成一个可行的商业模型。特别的,我们会从社交网络范式转移到一个关于不同供需类型参与者组成的网络中。工业界的示例有:住房(airbnb),出行共享(Uber, Lyft),在线电商(Etsy)等。为这种类型的市场进行内容发现和搜索排序,需要满足供需双方,从而保持增长和繁荣。
在Airbnb中,需要对主人(hosts)和客人(guests)进行最优化搜索,这意味着,给定一个输入query,它带有位置(location)和旅行日期(trip dates),我们必须为客人带有位置、价格、风格、评论等出现给客户排序高的listings,同时,它又能很好地匹配主人关于旅行日期(trip dates)和交付期(lead days)的偏好。也就是说,我们需要发现这样的listings:它可能因为差评、宠物、逗留时间、group size或其它因素而拒绝客户,并将这些listings排的序更低。为了达到该目的,我们会使用L2R进行重排序。特别的,我们会将该问题公式化成pairwise regression问题(正向:预订bookings,负向:拒绝rejections)。
由于客户通常会在预测前浏览多个搜索结构,例如:点击多个listing,并在它们的搜索session内联系多个主人,我们可以使用这些in-session信号(例如,点击(clicks)、与主人的联系(host contacts)等)进行实时个性化,目标是给用户展示与search session相似的多个listings。同时,我们可以使用负向信号(比如,高排名listings的跳过次数),从而展示给客人尽可能少的不喜欢列表。
3.方法
下面,我们引入了listing推荐、以及listing在搜索的中ranking。我们会描述两个不同的方法,例如:对于短期实时个性化的listing embeddings、以及用于长期个性化 user-type & listing-type embeddings。
3.1 Listing embeddings
假设,给定从N个用户中获取的S个点击sessions的一个集合S,其中每个session \(s = (l_1, ..., l_M) \in S\)被定义成:一个关于该用户点击的M个listing ids连续序列。当在两个连续的用户点击之间超过30分钟的时间间隔时,启动一个新的session。给定该数据集,目标是为每个唯一的listing \(l_i\)学习一个d维的real-valued表示: \(v_{l_i} \in R^d\),以使相似的listing在该embedding空间中更接近。
更正式的,该模型的目标函数是使用skip-gram模型,通过最大化搜索sessions的集合S的目标函数L来学习listing表示,L定义如下:
\[L = \sum\limits_{s \in S} \sum\limits_{l_i \in s} (\sum\limits_{-m \leq j \leq m, i \neq 0} log P(l_{i+j} | l_i))\]…(1)
从被点击的listing \(l_i\)的上下文邻居上观察一个listing \(l_{i+j}\)的概率\(P(l_{i+j} \mid l_{i})\),使用softmax定义:
\[P(l_{i+j} | l_i) = \frac{exp(v_{l_i}^T v_{l_{i+j}}')} {\sum\limits_{l=1}^{|V|} exp(v_{l_i}^T v_l')}\]…(2)
其中\(v_l\)和\(v_l'\)是关于listing l的输入和输出的向量表示,超参数m被定义成对于一个点击listing的forward looking和backward looking上下文长度,V被定义成在数据集中唯一listings的词汇表。从(1)和(2)中可以看到提出的方法会对listing点击序列建模时序上下文,其中具有相似上下文的listing,将具有相似的表示。
计算(1)中目标函数的梯度\(\Delta L\)的时间,与词汇表size \(\mid V \mid\)成正比,对于大词汇表来说,通常有好几百万listing ids,是不可行的任务。做为替代,我们会使用negative-sampling方法,它能极大减小计算复杂度。Negative-sampling可以如下所述。我们会生成一个positive pairs (l, c)的集合\(D_p\),其中l表示点击的listings,c表示它的上下文,然后从整个词典V中随机抽取n个listings来组成negative pairs (l, c)的集合\(D_n\)。优化的目标函数变为:
\[argmax_{\theta} \sum\limits_{(l,c) \in D_p} log \frac{1}{1+e^{-v_c'v_l}} + \sum\limits_{(l,c) \in D_n} log \frac{1}{1+e^{v_c'v_l}}\]…(3)
其中要学的参数\(\theta\)是:\(v_l\)和\(v_c\), \(l, c \in V\). 优化通过随机梯度上升法(SGA)完成。
将预订Listing看成全局上下文。 我们将点击session集合S划分为:
- 1) 预订型sessions(booked sessions), 例如,点击sessions会以用户在某一listing上进行预订而结束
- 2) 探索型session(exploratory session),例如,点击sessions最后不会以预订结束,用户仅仅只是浏览.
对于捕获上下文相似度的角度来说两者都有用,然而,预订型sessions可以被用于适配以下的最优化:在每个step上,我们不仅仅只预测邻居clicked listing,也会预测booked listing。这种适配可以通过将预测的listing作为全局上下文(global context)来完成,从而能总是被预测,不管是否在上下文窗口内部。因此,对于预订型sessions来说,embedding的更新规则变为:
\[argmax_{\theta} \sum\limits_{(l,c) \in D_p} log \frac{1}{1+e^{-v_c'v_l}} + \sum\limits_{(l,c) \in D_n} log \frac{1}{1+e^{v_c'v_l}} + log \frac{1}{1+ e^{-v_{l_b}' v_l}}\]…(4)
其中,\(v_{l_b}\)是booked listing \(l_b\)的embedding。对于 探索型session来说,更新仍会由(3)的最优化进行管理。
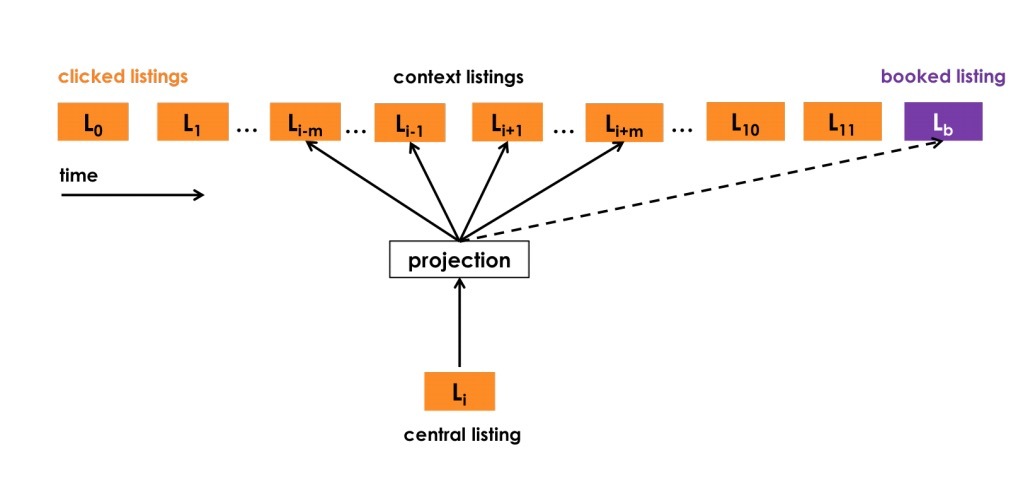
图1
图1展示了listing embeddings是如何从预定型sessions中进行学习的,它会使用一个滑动窗口size=2n+1, 从第一个clicked listing到最后的booked listing滑动。在每一步,central listing \(v_l\)的embedding会被更新,以便它能预测context listing \(v_c\)的embedding、以及booked listing \(v_{l_b}\)的embedding。随着窗口滑入和滑出上下文集合,booked listing总是会作为全局上下文存在。
自适应训练. 在线旅行预定网站的用户通常会在单个market(例如,他们想逗留的地理位置)内进行搜索。因此,\(D_p\)会有较高的概率包含了相同market中的listings。在另一方面,归因于negative sampling,\(D_n\)包含的大多数listings与\(D_p\)包含的listings很大可能不会是相同的markets。在每一步,对于一个给定的central listing l,positive上下文几乎由与l相同market的listings所组成,而negative上下文几乎由与l不同market的listings组成。为了解决该问题,我们提议添加一个随机负样本集合\(D_{m_n}\),它从中心listing l的market上抽样得到:
\[argmax_{\theta} \sum\limits_{(l,c) \in D_p} log \frac{1}{1+e^{-v_c'v_l}} + \sum\limits_{(l,c) \in D_n} log \frac{1}{1+e^{v_c'v_l}} + log \frac{1}{1+ e^{-v_{l_b}' v_l}} + \sum\limits_{(l,m_n) \in D_{m_n}} log \frac{1}{1+e^{v_{m_n}'}v_l}\]…(5)
其中要学习的参数\(\theta\)有:\(v_l\)和\(v_c\), \(l,c \in V\)。
冷启动listing的embeddings. 每天都有新的listings被主人创建,并在Airbnb上提供出租。这时候,这些listings不会有一个embedding,因为他们在训练数据中没有对应的点击sessions。为了为这些新的listings创建embeddings,我们打算利用其它listings的embeddings。
在listing创建时,需要提供listing的信息,比如:位置,价格,listing type等。我们利用这些关于listing的meta-data来发现3个地理位置上接近的listings(在10公里内),这些listings具有embeddings,并且具有与新listing相同的listing-type,并与新listing属于相同的价格区间(比如:每晚20-25美刀)。接着,我们使用3个embeddings计算平均向量,来构成新的listing embedding。使用该技术,我们可以覆盖98%的新listings。
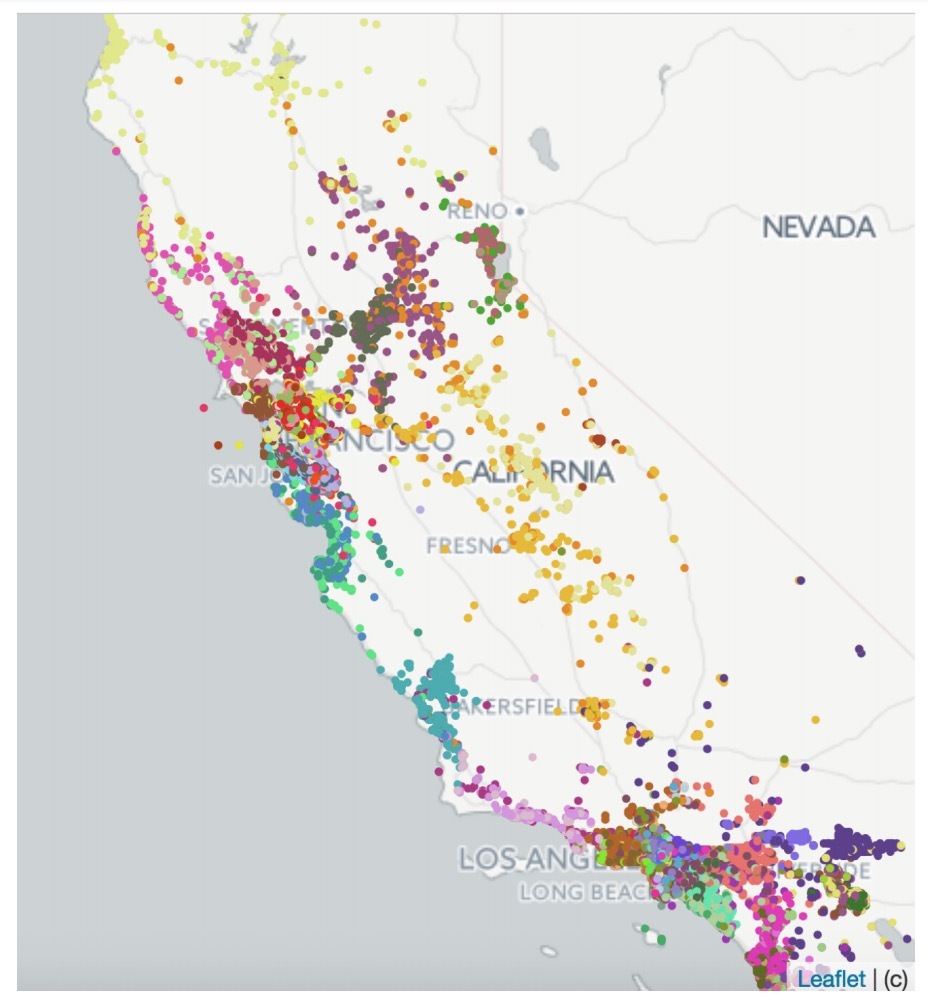
图2

表1:
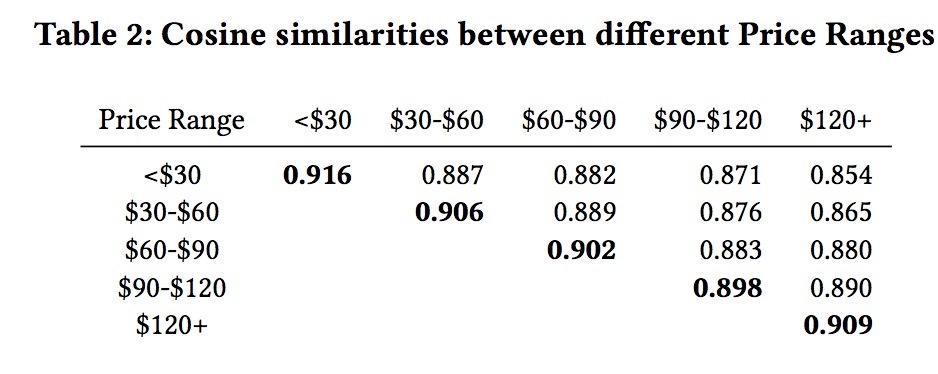
表2
检查listing embeddings.。为了评估由embeddings所捕获的listings的特性,我们检查了d=32维的embeddings,它使用公式(5)在800w点击sessions上进行训练。首先,通过在学到的embeddings上执行k-means聚类,我们对地理相似度进行评估。图2展示了生成的在加州的100个聚类,证实相似位置的listing会聚在一起。我们发现这些聚类对于重新评估我们的travel markets的定义非常有用。接着,我们评估了来自洛杉矶的不同listing-type间(表1)、以及不同价格区间(表2)间的listings的平均cosine相似度。从这些表中可以观察到,相同type和相同价格区间间的cosine相似度,要比不同type和不同价格区间间的相似度要高很多。因此,我们可以下结论,两个listing特性在被学到的embeddings中可以很好地编码。
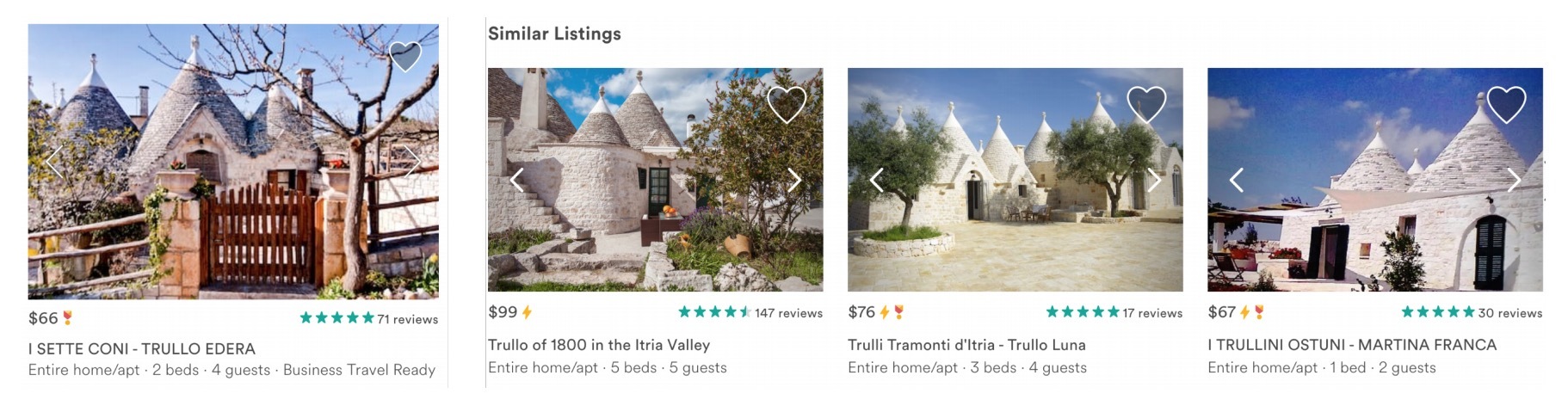
图3
有一些listing特性(比如价格)不需要学习,因为他们会直接从listing的meta-data中被抽取;而其它类型的listing特性(比如:房屋结构:architecture、装修风格:style、感受:feel),很难以listing features的形式进行抽取。为了评估这些特性是否由embeddings捕获,我们检查了在listing embedding空间中单一房屋结构的listings的k近邻。图3展示了这个case,对于左侧的一个单一architecture的listing来说,最相似的listings具有相同的style和architecture。为了能在listing embedding空间上进行快速和方便的探索,我们开发了一个内部的相似度探索工具,如图4所示。
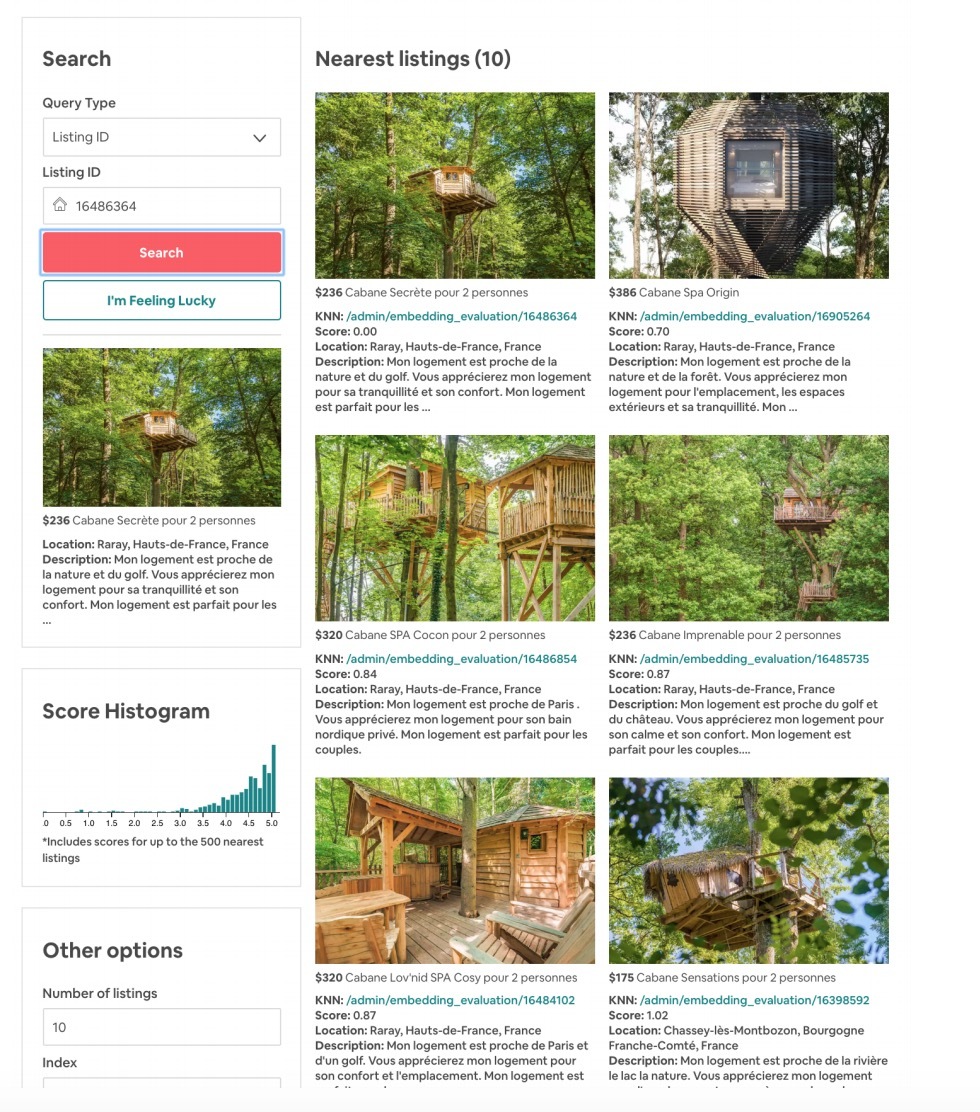
图4
该工具的演示在https://youtu.be/1kJSAG91TrI, 展示了可以发现相同architecture(包括:houseboats, treehouses, castles, chalets, beachfront apartments)的相似listings。
3.2 User-type & Listing-type embeddings
在3.1节描述的是Listing embeddings。它使用clicked sessions进行训练,能很好地发现相同market间的listings相似度。同样的,他们更适合短期(short-term)、session内(insession)、个性化的需求,它们的目标是给用户展示与在搜索session期间点击的listing相似的listings。
然而,除了in-session personalization,(它基于在相同session内发生的信号构建),基于用户长期历史的信号对于个性化搜索来说很有用。例如,给定一个用户,他当前在搜索洛杉矶内的一个listing,过去他在纽约、伦敦预定过,给他推荐之前预定过的listings相似的listings是很有用的。
当在由点击训练得到的listing embeddings中捕获一些cross-market相似度时,学习这种cross-market相似度一个原则性方法是,从由listings构成的sessions中学习。特别的,假设,我们给定一个从N个用户中获取的booking sessions的集合\(S_b\),其中每个booking session \(s_b = (l_{b1}, ..., l_{b_M})\)被定义成:由用户j按预定(booking)的时间顺序排列的一个listings序列。为了使用该类型数据来为每个listing_id,学习embeddings \(v_{l_{id}}\),会有以下多方面挑战:
- 1.booking sessions数据\(S_b\)比click sessions数据S要小很多,因为预定是低频事件。
- 2.许多用户在过去只预定单个listing,我们不能从session length=1中进行学习
- 3.为了上下文信息中的任意实体学习一个有意义的embeddings,至少需要该实体出现5-10次,然而在平台中的许多listing_ids会低于5-10次。
- 4.最后,由同用户的两个连续预定可能会有很长时间的间隔,这时候,用户偏好( 比如:价格点)可能会随职业发展而变化。
为了解决这些非常常见的问题,我们提出了在listing_type级别学习embeddings,而非listing_id级别。给定一个特定listing_id的meta-data,比如:位置,价格,listing-type,空间,床数等,我们使用一个在表3中定义的基于规则的映射,来决定listing_type。
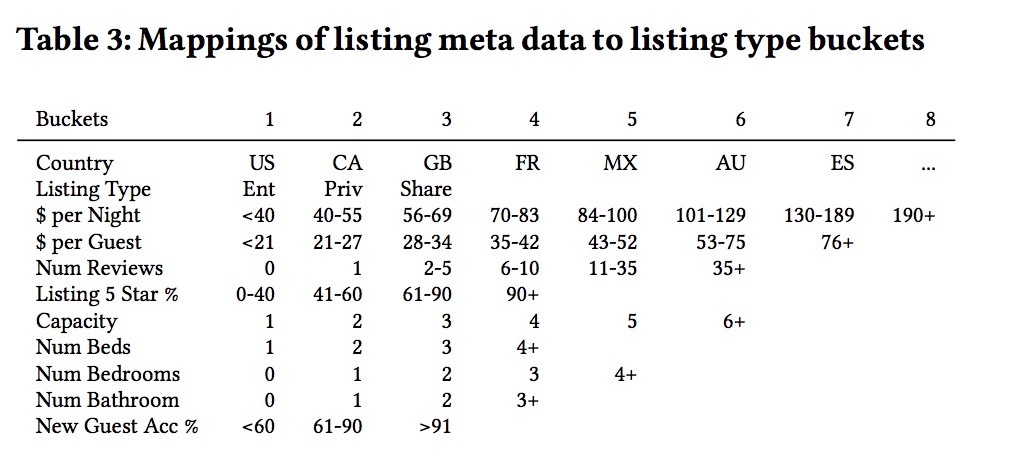
表3
**例如,一个来自US的Entire Home listing(lt1),它是一个二人间(c2),1床(b1),一个卧室(bd2) & 1个浴室(bt2),每晚平均价格为60.8美刀(pn3),每晚每个客人的平均价格为29.3美刀(pg3),5个评价(r3),所有均5星好评(5s4),100%的新客接受率(nu3),可以映射为:listing_type = U S_lt1_pn3_pg3_r3_5s4_c2_b1_bd2_bt2_nu3. **分桶以一个数据驱动的方式决定,在每个listing_type分桶中最大化覆盖。从listing_id到一个 listing_type的映射是一个多对一的映射,这意味着许多listings会被映射到相同的listing_type。
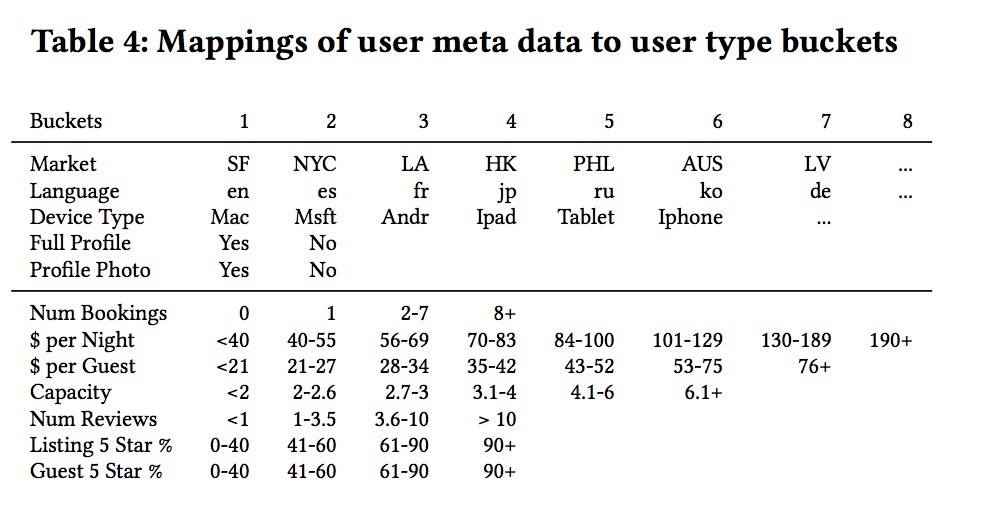
表4:
为了解释用户随时间变化的偏好,我们提出在与listing_type embedding相同的向量空间中学习user_type embeddings。user_type使用一个与listings相似的过程来决定,例如,利用关于user和它之前预订记录的metadata,如表4定义。例如,对于一个用户,他来自San Francisco(SF)、带有MacBook笔记本(dt1)、说英文(lg1)、具有用户照片资料(pp1)、83.4%平均5星率(l5s3)、他在过去有3个预订(nb1)、其中关于订单(booked listings)的平均消费统计为:52.52美刀 (每晚平均价格: Price Per Night), 31.85美刀 (每晚单客户平均价格:Price Per Night Per Guest), 2.33(Capacity), 8.24(平均浏览数:Reviews)、76.1%(5星好评单:Listing 5 star rating)。对于该用户所生成的user_type是:SF_lg1_dt1_fp1_pp1_nb1_ppn2_ppg3_c2_nr3_l5s3_g5s3. 当为训练embeddings生成booking sessions时,我们会一直计算user_type直到最近的预定。对于那些首次做出预定的user_type的用户,可以基于表4的第5行进行计算,因为预测时我们没有关于过去预定的先验信息。这很便利,因为对于为user_types的embeddings,它基于前5行,可以用于对登出用户或者没有过往预定记录的新用户进行冷启动个性化。
训练过程. 为了学习在相同向量空间中的user_type和listing_type的embeddings,我们将user_type插入到booking sessions中。特别的,我们形成了一个\(S_b\)集合,它由N个用户的\(N_b\)个booking sessions组成, 其中每个session \(s_b = (u_{type_1} l_{type_1}, ..., u_{type_M} l_{type_M}) \in S_b\)被定义成一个关于booking事件的序列,例如:按时间顺序排列的(user_type, listing_type)元组。注意,每个session由相同user_id的bookings组成,然而,对于单个user_id来说,他们的user_types可以随时间变化,这一点与下述情况相似:相同listing的listing_types会随着他们接受越来越多的bookings按时间变化。
目标函数与(3)相似,会替换listing l,中心项需要使用\(user\_type(u_t)\)或者\(listing\_type(l_t)\)进行更新,取决于在滑动窗口中捕获的项。例如,为了更新中心项\(user\_type(u_t)\),我们使用:
\[argmax_{\theta} \sum\limits_{(u_t,c) \in D_{book}} log \frac{1} {1+e^{-v_c'v_{u_t}}} + \sum\limits_{(u_t,c) \in D_{neg}} log \frac{1} {1 + e^{v_c'v_{u_t}}}\]…(6)
其中\(D_{book}\)包含了来自最近用户历史的user_type和listing_type,特别是与中心项接近的用户预定记录,其中\(D_{neg}\)包含了使用随机的user_type或listing_type实例作为负例。相似的,如果中心项是一个\(listing\_type(l_t)\),我们可以对下式最优化:
\[argmax_{\theta} \sum\limits_{(l_t,c) \in D_{book}} log \frac{1} {1+e^{-v_c'v_{l_t}}} + \sum\limits_{(l_t,c) \in D_{neg}} log \frac{1} {1 + e^{v_c'v_{l_t}}}\]…(7)
图5a展示了一个该模型的图形表示,其中,中心项表示\(user\_type(u_t)\)用于执行(6)中的更新。
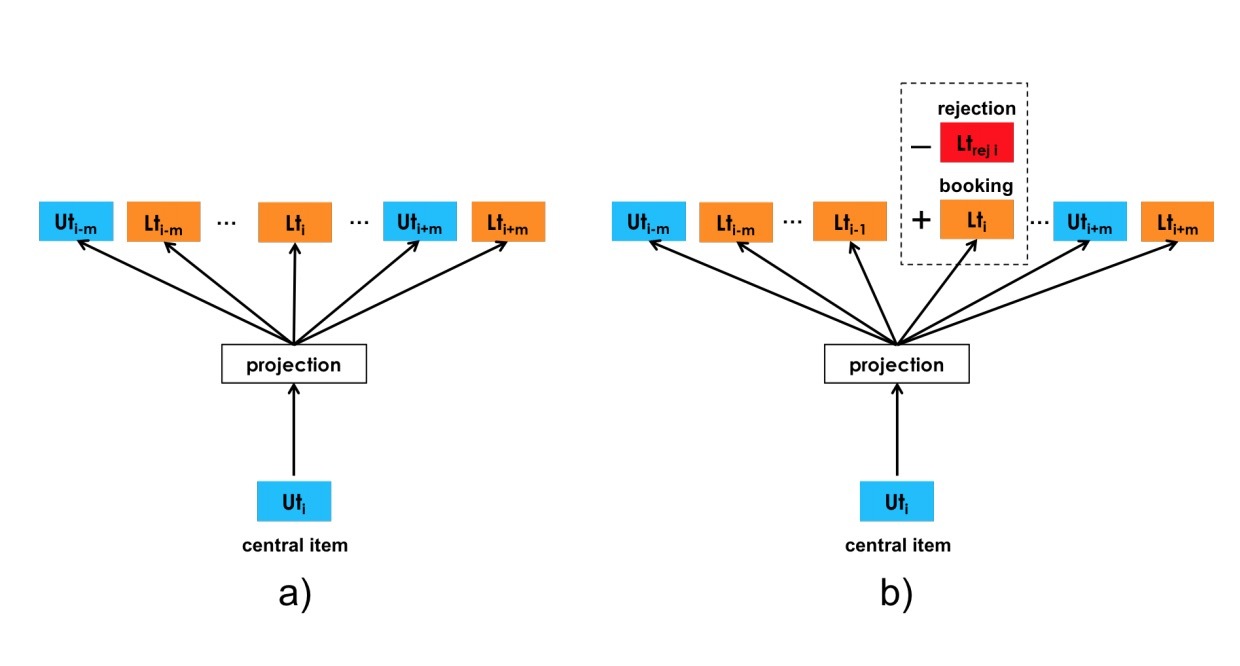
图5
由于定义中的booking sessions几乎包含了来自不同markets的listings,没有必要从相同market中抽样额外的负样本作为booked listing。
拒绝订单(rejection)的显式负样本。不同于点击只影响guest端的偏好,bookings也会影响host端的偏好,也存在着来自host的一个显式反馈,形式表现为:接受guest的请求进行预定,或者拒绝guest的预订请求。对于host来说,拒绝的一些原因可能是:客户较差的guest star ratings、用户资料不完整或空白、没有资料图等等。这些特性有一部分存在表4中的user_type定义中。
来自主人的拒绝(Host rejections),可以在训练期间被用来编码主人(host)在向量空间中的偏好。合并这些拒绝信号的目的是:一些listing_types比没有预定记录的、不完整的资料、以及较低的评星率的user_types敏感度更小。我们希望,这些listing_types和user_types在向量空间的embedding更接近,这样基于embedding相似度的推荐可以减小拒绝率,最大化预订机会。
我们对rejections看成是显式负样本,以如下方式公式化。除了集合\(D_{booking}\)和\(D_{neg}\),我们会生成一个集合\(D_{rej}\),它由涉及到rejection事件的user_type和listing_type的pairs(\(u_t, l_t\))组成。如图5b所示,我们特别关注,对于同一用户,当在对于另一个listing的成功预定(通过一个正号标记)之后主人拒绝(通过一个负号-标记)。新的目标函数可以为:
更新一个\(user\_type(u_t)\)的中心item:
\[argmax_{\theta} \sum_{(u_t,c) \in D_{book}} log \frac{1} {1+e^{-v_c'v_{u_t}}} + \sum_{(u_t,c) \in D_{neg}} log \frac{1} {1 + e^{v_c'v_{u_t}}} + \sum_{(u_t,l_t) \in D_{reject}} log \frac{1} {1+exp^{v_{l_t}' v_{u_t}}}\]…(8)
更新一个\(listing\_type(l_t)\)的中心item: \(argmax_{\theta} \sum\limits_{(l_t,c) \in D_{book}} log \frac{1} {1+e^{-v_c'v_{l_t}}} + \sum\limits_{(l_t,c) \in D_{neg}} log \frac{1} {1 + e^{v_c'v_{l_t}}} + \sum\limits_{(l_t,u_t) \in D_{reject}} log \frac{1}{1+exp(v_{u_t}' v_{l_t})}\)
…(9)

表5
对于所有user_types和listing_types所学到的embeddings,我们可以根据用户当前的user_type embedding和listing_type embedding,基于cosine相似度给用户推荐最相关的listings。例如,表5中,我们展示了cosine相似度:
user_type = SF_lg1_dt1_fp1_pp1_nb3_ppn5_ppg5_c4_nr3_l5s3_g5s3, 该用户通常会预定高质量、宽敞、好评率高、并且在美国有多个不同listing_types的listings。可以观察到,listing_types最匹配这些用户的偏好,例如,整租,好评多,大于平均价,具有较高cosine相似度;而其它不匹配用户偏好的,例如:空间少,低价,好评少,具有较低cosine相似度。
4.实验
4.1 Listing embeddings训练
对于listing embeddings的训练,我们从搜索中创建了8亿个点击sessions,通过使用从logged-in users所有searches,将它们通过user id进行分组,并在listing ids上按时间进行排序。
4.2 Listing Embeddings的离线评估
为了能快速根据不同最优化函数、训练数据构造、超参数、等做出快速决策,我们需要一种方式来快速对比不同的embeddings。
对训练出的embedding进行评估的一种方法是,基于用户最近点击行为,测试在用户推荐列表中将要预定的效果好坏。更特别的,假设我们给定了最常见的clicked listing和需要被排序的candidate listings(它包含了用户最终预定的listing)。通过计算在clicked listing和candidate listings间的cosine相似度,我们可以对候选进行排序,并观察booked listing的排序位置。
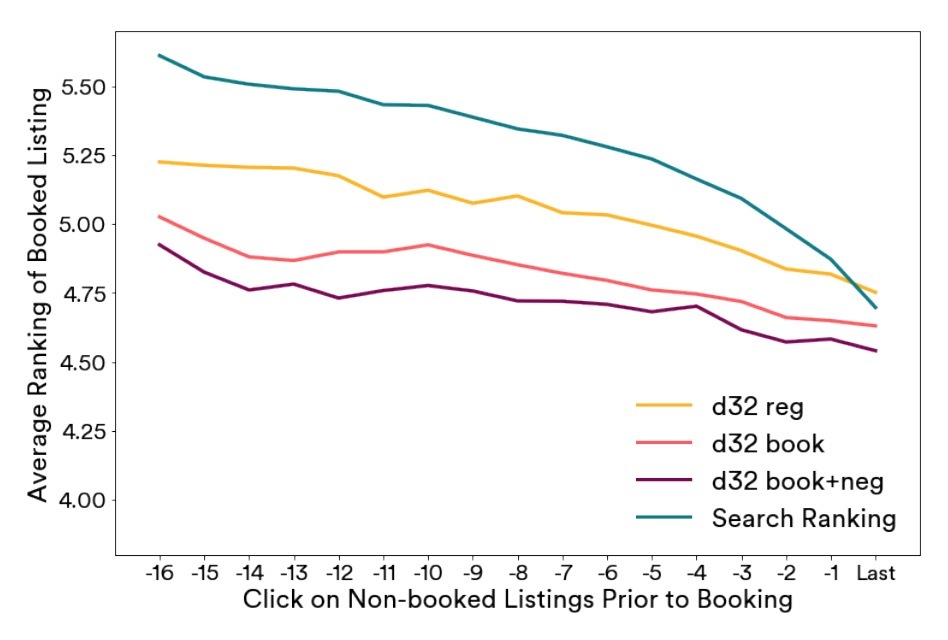
图6
为了评估,我们使用一个较大数目的这种search、click和booking事件,其中rankings通过我们的Search Ranking模型进行分派。在图6中,我们展示了离线评估的结果,我们比较了d=32的多个版本embeddings,并认为他们基于点击来对booked listing进行排序。booked listing的rankings对于每个产生预定的点击进行平均,在预定之前的17次点击,转到在预定之前的最后一次点击(Last click)。越低值意味着越高的ranking。我们要对比的embedding versions有:
- d32: 它使用(3)进行训练
- d32 book: 它使用bookings做为全局上下文 (4)
- d32 book + neg: 它使用bookings做为全局上下文,并对于相同的market采用展式负样本(5)
可以观察到,Search Ranking模型会随着它使用记忆型特征(memorization features)而获得更好更多的点击。可以观查到基于embedding相似度的re-ranking listings是有用的,特别是在search漏斗的早期阶段。最后,我们可以断定:d32 book + neg的效果要好于其它两者。相同类型的图可以被用于对其它因素:(超参数、数据构建)做出决策。
4.3 使用Embeddings的相似listing
每个Airbnb的home listing page页包含了Similar Listings(类似房源)这个 carousel控件,它会为home listing推荐与它相似的listings,并在相近的时间集合是可入住的。在我们的测试中,对于“Similar Listing” carousel控件的已存在算法,会调用主要的Search Ranking模型,给出通过给定listing过滤出与它相近位置、是否可入住、价格区间、listing type的listing。
我们进行了A/B test,其中会对比已存在算法与embedding-based的算法,其中,相似listings通过在listing embedding空间中寻找k个最近邻得到。给定学到的listing embeddings,对于一个给定的listing l,相似listings可以在时间上吻合(check-in和check-out的dates设置相同)的相同market上所有listings,通过计算\(v_l\)和\(v_j\)间的cosine相似度找到。具有最高相似度的K listings会被检索为相似listings。计算可以在线执行,使用我们共享架构来并行得到,其中,embeddings的部分存储在每个search机器上。
A/B test展示了,embedding-based解决方案在Similar Listing carousel上会产生一个21%的ctr提升(当listing page有entered dates时为23%,无date时为20%)。在Similar Listing carousel上发现listing并进行预定的客户,4.9%提升。从而部署到生产环境中。
4.4 使用Embeddings在Search Ranking上实时个性化
背景。为了正式描述我们的搜索排序模型(Search Ranking Model),我们假设,给定关于每个搜索\(D_s = (x_i, y_i), i=1, ..., K\)的训练数据,其中K是通过search返回的listings数目,\(x_i\)是一个向量,它包含了第i个listing结果的features,\(y_i \in \lbrace 0, 0.01, 0.25, 1, -0.4 \rbrace\)是分配给第i个listing结果的label。为了给一个特定的listing分配label。…